用于在线学习平台的多任务注意力知识追踪方法及系统
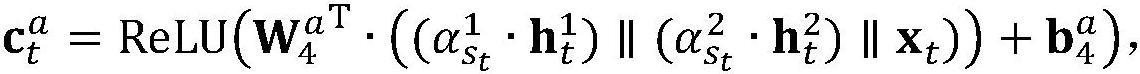
本发明涉及在线学习(e-learning)平台,具体涉及一种用于在线学习平台的多任务注意力知识追踪方法及系统。
背景技术:
1、随着电子学习的普及,学习者可以在不离开家的情况下通过自学来获取知识。为了为学习者制定个性化的学习计划,在线学习平台需要准确了解和掌握学习者各个阶段的知识水平。知识追踪(kt)是在线学习中的一项重要任务,其目标是通过分析学习者的学习历史数据来建模学习者的知识状态(ks),即学习者对技能(或概念/知识成分)的掌握程度。在在线学习平台上,学习者可以通过完成特定的练习来学习相关技能(例如,如果“加法”是一项技能,那么“1+1”就是它的练习),平台基于知识追踪模型追踪学习者关于学习技能的知识状态ks。最后,该平台通过何时停止策略来确定学习者是否掌握了这些技能。
2、近年来,基于深度学习的知识追踪方法(deep learning-based knowledgetracing,dlkt)凭借其更强的表示能力,表现出优于传统模型的性能,如贝叶斯知识追踪,潜在因素模型和项目响应理论。例如,深度知识追踪(deep knowledge tracing,dkt),动态键值记忆网络(dynamic key-value memory networks,dkvmn),自注意知识追踪(sakt)。为了提高dlkt预测未来学习者响应的能力,我们挖掘了多个与学习相关的因素(如表现、遗忘、练习文本等),并将其整合到具体模型中,如练习感知知识追踪框架,情境感知的注意性知识追踪(attentive knowledge tracing,akt),关系感知的自注意力知识追踪(relation-aware self-attention for knowledge tracing,rkt)。由于练习数据的稀疏性问题,早期的dlkt模型使用技能代替练习作为模型输入以避免模型的过度参数化。为了进一步提高dlkt的性能,多种与学习相关因素(例如:练习、表现、遗忘和练习文本等)被挖掘并集成到具体模型中。然而,现有的知识追踪模型通常只利用了提交练习答案后一刀切(正确或错误)的响应反馈,从而使得这些模型无法更加精准地捕捉每次交互后的知识增长。
3、学习记录是学习者知识水平的被动反映。相反,学习者的反馈提供了学习者对自己的知识状态的主动了解,这反过来又为学习者的学习情况提供了直接和真实的指标。然而,利用与学习者反馈相关的训练数据的知识追踪模型很少,尽管它可以在修正知识追踪结果中发挥重要作用。wang等人指出,反馈在学习中起着积极的作用,它可以促进在基于练习的学习中的迁移和记忆。直觉上,精准的反馈可以帮助模型更好地捕捉学习者在每次学习交互后的知识增长,以及更准确地区分练习的难易程度,而这些正是知识追踪模型之所以取得优异表现的关键。
4、在交互式在线学习平台中,学习者尝试一些练习,但甚至不需要看其他练习。每个学习者可以多次尝试一个练习,并且可以在连续尝试之间学习。当学习者经过多次尝试仍无法解决某项练习时,他们通常会寻求帮助。许多交互式在线学习平台中的一个常见学习辅助工具是在交互过程中获取提示的选项]。通过对学习活动的抽象化和简化,本文注意到两种更能直观反映练习困难度的行为反馈:提示使用次数和尝试次数。图1结合对在线学习数据的分析给出了这两种反馈的可视化描述,其中子图(a)是简化后的学习交互过程,子图(b)显示了从真实数据中提取的部分练习记录。根据图1中的子图(a),一般的在线学习交互过程可以概括为以下三种情况:情况1(①):在一次交互过程中,无论练习的答案响应正确与否,只尝试一次就停止交互。这种情况可以从图1的右子图的练习标签:733和752所在记录中得到印证。在这种情况下,无论学习者关于练习的答案响应正确与否误,都只能说明他们知识状态与练习困难度之间的大概匹配程度。情况2(①…①):在一次交互过程中,第一次尝试做错了,然后多次尝试直到正确,或者始终错误,然后最终放弃。这种情况可以从图1的右子图的练习标签:821和826所在记录中得到印证。在这种情况下,学习者尝试的次数越多可能意味着练习对他们来说越困难。情况3(①②①…②①):在一次交互过程中,在情况2中的多次尝试中伴随着一次或多次提示使用动作(整个提示通常由一个或多个步骤组成)。这种情况可以从图1的右子图的练习标签:824、822和825所在记录中得到印证。在这种情况下,学习者尝试和提示使用的次数越多,可能意味着练习对他们来说越困难。
5、综上所述,尝试行为反馈和提示使用行为反馈比响应反馈更能捕捉学习者知识状态与练习困难度之间的关系。图2展示了assistments2017数据集中练习平均正确率(acr)分别在提示使用次数和尝试次数上的分布情况(黑色折线图),其中每个acr值对应的练习次数(#exercise)参考红色折线图。从图中可以观察到,随着尝试次数和提示使用次数的增加,练习的acr指标逐渐降低(忽略小样本引起的噪声),这无疑为本文的动机提供统计支持。虽然chaudhry等人试图通过多任务学习(multi-task learning,mtl)联合学习提示使用(提示使用与否,不考虑次数)预测(相关任务)与响应预测(主要任务),但他们的模型在学习者响应预测方面的性能提升有限。原因有三个:1)相关任务的反馈不够精细;2)主任务和相关任务之间的特征融合比较简单直接;3)由于练习数据稀疏性问题导致的练习样本不平衡问题也是制约知识追踪模型出色表现的客观挑战之一。如何将知识追踪模型应用于在线学习平台,以更加精准地捕捉每次交互后的知识增长,已成为一项亟待解决的关键技术问题。
技术实现思路
1、本发明要解决的技术问题:针对现有技术的上述问题,提供一种用于在线学习平台的多任务注意力知识追踪方法及系统,本发明能够实现在线学习平台的多任务注意力知识追踪,通过不平衡感知注意力机制为具有不同记录计数的练习分配个性化权重来解决模型训练过程中遇到的极端锻炼记录不平衡问题,并基于在多任务特征融合和多模型特征融合两个阶段实现技能个性化的软融合,具有优秀的知识追踪性能。
2、为了解决上述技术问题,本发明采用的技术方案为:
3、一种用于在线学习平台的多任务注意力知识追踪方法,包括:
4、s101,根据历史交互序列提取当前时间步t的不平衡感知注意力权重
5、s102,基于当前时间步t的练习标签et、技能标签st以及不平衡感知注意力权重编码得到练习嵌入xt;基于不平衡感知注意力权重以及当前时间步t响应标签rt、真实学习动作at编码得到知识嵌入yt;
6、s103,对练习嵌入xt、知识嵌入yt进行注意力知识追踪获得知识状态ht;
7、s104,根据时间步t的练习嵌入xt、知识状态ht进行多任务预测获得对应的预测结果,所述多任务预测包括主任务和至少一项相关任务,所述主任务用于预测获得学习者正确响应练习标签et的预测概率所述相关任务用于预测获得学习者针对练习标签et提交答案时的使用次数或尝试次数。
8、可选地,步骤s101包括:
9、s201,从历史交互序列中统计每个练习标签e的先验样本数#e;
10、s202,使用log2(#e+1)函数对#e进行离散化处理;
11、s203,将离散化处理后的先验样本数设置为练习标签e的不平衡因子;
12、s204,使用独热编码对每个练习标签e的不平衡因子编码,得到不平衡因子向量o#;
13、s205,用所有练习标签e中最大的不平衡因子值对不平衡感知嵌入向量i的维度diam进行初始化,并根据下式计算得到当前时间步t的不平衡感知注意力权重
14、
15、上式中,上标t表示不平衡感知嵌入向量i的转置操作,且不平衡感知嵌入向量i的数将在训练过程中通过梯度反向传播被自动学习。
16、可选地,步骤s102中编码得到练习嵌入xt的函数表达式为:
17、
18、上式中,softmax表示softmax激活函数,为技能标签st的原始嵌入,为当前时间步t的不平衡感知注意力权重,为练习标签et的标量困难度参数,为技能标签st下所有练习构成的向量,是对应的偏置向量,d表示嵌入的维度,且有:
19、
20、
21、
22、上式中,和分别表示技能和练习的独热编码向量;和分别为和的嵌入矩阵;为的嵌入向量,e表示练习总数,s表示在线学习平台中技能标签的数量,d为嵌入维度。
23、可选地,步骤s102中编码得到知识嵌入yt的函数表达式为:
24、
25、上式中,softmax表示softmax激活函数,为技能-响应-行动的双任务嵌入,为当前时间步t的不平衡感知注意力权重,为练习标签et的标量困难度参数,为技能-响应-行动的变量向量,是对应的偏置向量,d表示嵌入的维度,且有:
26、
27、
28、
29、
30、上式中,为主任务的技能-响应的原始嵌入,为相关任务的技能-行动的原始嵌入,为主任务的技能-响应变量嵌入向量,为相关任务的技能-行动变量嵌入向量,和分别表示主任务和相关任务的技能感知注意力权重,os为技能标签s的独热向量,和分别为用于获取主任务和相关任务的特征融合的权重向量,且有:
31、
32、
33、
34、
35、上式中,和分别表示技能-响应和技能-行动的多热编码向量;和分别为和的嵌入矩阵;和分别为和的嵌入矩阵,s表示在线学习平台中技能标签的数量,d为嵌入维度,技能-响应的多热编码向量是将技能独热编码和响应的一位二进制编码0或1进行拼接得到;技能-行动的多热编码向量是将技能独热编码和行动的二进制编码进行拼接,l为行动的二进制编码的位数是最大行动标签对应二进制编码的位数,对于位数小于l的在行动标签对应的二进制编码前补0。
36、可选地,步骤s104中根据时间步t的练习嵌入xt、知识状态ht进行多任务预测获得对应的预测结果时,进行的多任务预测包括主任务和一项相关任务,且主任务通过一训练好的三层响应预测网络预测获得学习者正确响应练习标签et的预测概率的,且所述三层响应预测网络的函数表达式为:
37、
38、
39、
40、上式中,relu和linear为激活函数,和是三层响应预测网络的中间变量,和分别为三层响应预测网络中各层的变换矩阵和偏置向量参数,||表示向量的拼接操作;相关任务通过一训练好的三层行动预测网络预测获得学习者针对练习标签et提交答案时的使用次数或尝试次数,且所述三层行动预测网络的函数表达式为:
41、
42、
43、
44、上式中,relu和linear为激活函数,和是三层行动预测网络的中间变量,和分别为三层响应行动网络中各层的变换矩阵和偏置向量参数,||表示向量的拼接操作。
45、可选地,所述三层响应预测网络和三层行动预测网络两者构成的双任务注意力知识追踪模型bakt,且双任务注意力知识追踪模型bakt在训练时采用的损失函数为:
46、
47、上式中,为损失函数,为主任务的交叉熵损失,为相关任务的交叉熵损失,σr为主任务的不确定性参数,σa为相关任务的不确定性参数。
48、可选地,步骤s104中根据时间步t的练习嵌入xt、知识状态ht进行多任务预测获得对应的预测结果时,进行的多任务预测包括主任务和两项相关任务,两项相关任分别用于获得学习者针对练习标签et提交答案时的使用次数或尝试次数,且主任务通过一训练好的三层响应预测网络预测获得学习者正确响应练习标签et的预测概率的,且所述三层响应预测网络的函数表达式为:
49、
50、
51、
52、上式中,relu和linear为激活函数,和是三层响应预测网络的中间变量,和分别为三层响应预测网络中各层的变换矩阵和偏置向量参数,||表示向量的拼接操作,和分别为两个相关任务的知识状态,和分别为两个相关任务的知识状态的权重;相关任务通过一训练好的三层行动预测网络预测获得学习者针对练习标签et提交答案时的使用次数或尝试次数,且所述三层行动预测网络的函数表达式为:
53、
54、
55、
56、上式中,relu和linear为激活函数,和是三层行动预测网络的中间变量,和分别为三层响应行动网络中各层的变换矩阵和偏置向量参数,||表示向量的拼接操作,和分别为两个相关任务的知识状态,和分别为两个相关任务的知识状态的权重,且两个相关任务的知识状态和的生成包括:基于当前时间步t的练习标签et、技能标签st以及不平衡感知注意力权重编码得到练习嵌入x;基于不平衡感知注意力权重以及当前时间步t响应标签rt、真实学习动作at分别采用两个相关任务对应的知识编码器对y1和y2进行编码得到知识嵌入和对练习嵌入x分别与知识嵌入和进行注意力知识追踪,从而分别获得两个相关任务对应的知识编码器对y1和y2。
57、可选地,所述三层响应预测网络和三层行动预测网络两者构成的三任务注意力知识追踪模型takt,且三任务注意力知识追踪模型takt在训练时采用的损失函数为:
58、
59、上式中,为损失函数,为主任务的交叉熵损失,为第一个相关任务的交叉熵损失,为第二个相关任务的交叉熵损失,σr为主任务的不确定性参数,为第一个相关任务的不确定性参数,为第二个相关任务的不确定性参数。
60、此外,本发明还提供一种用于在线学习平台的多任务注意力知识追踪系统,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行所述用于在线学习平台的多任务注意力知识追踪方法。
61、此外,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序用于被微处理器编程或配置以执行所述用于在线学习平台的多任务注意力知识追踪方法。
62、和现有技术相比,本发明主要具有下述优点:
63、1、本发明能够根据时间步t的练习嵌入xt、知识状态ht进行多任务预测获得对应的预测结果,所述多任务预测包括主任务和至少一项相关任务,首次将提示预测和尝试预测两个相关任务与原始知识追踪任务相结合,提出了多任务注意力知识追踪。
64、2、本发明包括根据历史交互序列提取当前时间步t的不平衡感知注意力权重基于当前时间步t的练习标签et、技能标签st以及不平衡感知注意力权重编码得到练习嵌入xt;基于不平衡感知注意力权重以及当前时间步t响应标签rt、真实学习动作at编码得到知识嵌入yt,以此实现了一种新颖的不平衡感知注意力机制,通过自动为具有不同记录计数的练习分配个性化权重来解决模型训练过程中遇到的极端锻炼记录不平衡问题。
65、3、本发明实现了一种基于技能相关注意权重的技能感知注意力机制,在多任务特征融合和多模型特征融合两个阶段实现技能个性化的软融合。
- 还没有人留言评论。精彩留言会获得点赞!