一种基于自适应调度的NSGA-III优化算法的制作方法
一种基于自适应调度的nsga-iii优化算法
技术领域
1.本发明涉及nsga-iii算法,具体涉及一种基于自适应调度的nsga-iii优化算法。
背景技术:
2.多目标优化问题(multiobiective optimization problem,mop)在我们日常生活中随处可见,物流配送问题要求花费成本最少和服务人口最大化;电力系统优化问题追求最低燃料成本和最小有功网损;投资组合优化问题追求最低投资风险和最高投资收益等。随着众多多目标问题的出现,其优化算法也在不断完善。deb等人于2002年基于pareto最优解讨论提出的nsga-ii算法,在保持解的多样性的同时引入精英策略,避免种群退化,使得算法性能大幅上升,大大降低了计算复杂度;有人于2007年基于分解思想提出moea/d算法,将数学规划方法和进化算法相结合,通过聚合函数把多目标优化问题转化为单目标优化,获得了高质量的解和较低的计算复杂度;有人于2014年提出nsga-iii算法,利用一组均匀的参考点分割目标空间指导种群的进化,维持了解的多样性的同时解决了nsga-ii算法在高维目标空间效果欠佳等问题。随后,研究者们在nsga-iii算法的基础上提出多种改进策略来进一步优化算法性能。
3.有人提出了一种改进的nsga-iii算法,称为elite nsga-iii,通过建立精英群体档案来提nsga-iii解的多样性和准确性;bi等人提出了一种改进的基于消元算子的nsga-iii算法,先用最大生态位计数来识别参考点,然后利用罚点法的交叉边界距离对与之相关的个体进行排序,以此来增强算法的性能;为有效处理多目标最优潮流问题,有人提出了一insga-iii算法,该算法采用传统nsga-iii方法优化的竞争解初值作为初始种群,结合新的自适应优势策略,最终得到分布更均匀的优选pareto前沿(pf)。有人提出了一种基于参考点选择策略的改进nsga-iii算法,该算法根据对参考点重要性的评估淘汰无用的参考点,加快了算法的收敛速度和优化效率,但未能具体设置参考点的尺度;有人提出基于参考点选择策略的改进型nsga-iii算法,根据对参考点重要性的评估来剔除无用参考点,加快了算法收敛及优化效率,但未能对参考点的规模做具体设定;有人提出了一种基于参考点拥挤度改进的nsga-iii算法,通过计算与参考点相关联后的种群成员之间的拥挤度来删除部分个体,从而改善pareto解集的收敛性和分布性,但在父代重组操作中产生了过多重复种群,降低了种群的多样性;有人提出自适应交叉算子的改进nsga-iii算法,采用多个交叉算子构建策略池,使算法自适应地选择优秀算子,从而提高了种群多样性和算法的收敛速度,但算法仅从初始化部分改进,未从选择机制上做过多改进。
4.nsga-iii算法及其改进
5.nsga-iii算法
6.nsga-iii算法在nsga-ii的基础上保留了nsga-ii算法原有的精英策略,在算法选择阶段使用参考点机制代替拥挤度进行排序,其在高维空间有较好的表现,同时维持了种群的多样性。
7.nsga-iii算法步骤如下表1如下:
8.表1nsga-iii算法步骤
[0009][0010][0011]
nsga-iii算法的缺点:
[0012]
随着维数的增加,其参考点的个数远大于种群数量,导致计算复杂度急剧增大;pareto选择压力减弱,导致收敛性降低。
[0013]
(2)nsga-iii中参考点的数目决定算法的运行时间,过多、过少的参考点都不利于临界非支配层的选择。过少,参考点筛选效果不好;过多,算法复杂度增加。
[0014]
(3)在种群进化阶段,人为设定的交叉变异算子不具有普遍性,在交叉变异过程中会导致概率不均,减小种群多样性等问题。
[0015]
ar-nsga-iii算法
[0016]
ar-nsga-iii算法主要在nsga-iii算法的基础上,对参考点的选择做了以下改进:
[0017]
(1)利用种群在决策空间四分位的信息,以熵的差值进行量化,判定种群进化阶段。
[0018]
(2)根据种群在目标空间的分布信息,关联参考点,评估各参考点的重要性,进行参考点筛选。
[0019]
该算法能有效减少无效参考点对种群个体选择的干扰,提升算法效率与性能,但
未能对进化阶段的判定进行具体讨论,采用更合理的阈值使得进化阶段划分更准确。
技术实现要素:
[0020]
本发明的主要目的在于提供一种基于自适应调度的nsga-iii优化算法,减少了多余参考点的产生,增加了种群的多样性,提高了pareto解集的收敛性和分布性。
[0021]
本发明采用的技术方案是:一种基于自适应调度的nsga-iii优化算法,包括:
[0022]
as-nsga-iii算法参考点设计;
[0023]
as-nsga-iii算法自适应交叉算子设计。
[0024]
进一步地,所述as-nsga-iii算法参考点设计包括:
[0025]
确定超平面上的参考点;
[0026]
关联种群参考点;
[0027]
参考点小生境数计算。
[0028]
更进一步地,所述确定超平面上的参考点包括:
[0029]
nsga-iii使用一组预定义的参考点来确保解的多样性,其参考点在一个m维的超平面上,m是目标空间的维度,若将每个目标划分为p份,均匀产生h(m,p)个参考点;假定维数m=3,划分份数p=4,则参考点在平面上的分布如下所示:
[0030]
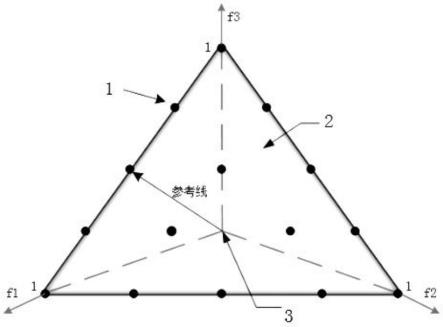
在参考点设定上,让参考点数目自适应种群规模n,假设划分份数p1p2,分别由式(2)求出参考点集w1,由式(3)求出参考点集w2,使得w1《n,w2》n,则有:
[0031][0032]
其中,w1是划分份数p1生成的参考点集,m和p在超平面空间经过排列组合生成均匀分布的参考点集w1;
[0033][0034]
其中,w2由划分份数p2与p1生成的参考点集的差值构成;
[0035][0036]
假设m=3,p1=11,p2=10,若目标数m=3,群规模n=100,根据式(2)、式(3)、式(4)可得,w1=105,w2=91,w=98,所以初始参考点数选择98;
[0037]
在此过程中,w2由w2与w1的差值构成。
[0038]
更进一步地,所述关联种群参考点包括:
[0039]
让种群中的k个个体分别关联到相应的参考线;
[0040]
首先定义参考线,即在目标空间中原点与参考点的连线;
[0041]
其次计算种群中的每个个体到与其最近参考线的垂直距离,最后将种群个体与和它最近的参考线关联起来。
[0042]
更进一步地,所述参考点小生境数计算包括:
[0043]
当没有参考点与种群个体关联时,直接删除参考点,减小计算复杂度;
[0044]
当有种群与参考点相连时,选择最小生境数最小的进入p
t+1
,此时,小生境数pj=p
j+1
,重复计算,直到p
t+1
=n时算法结束;
[0045]
当多个参考点关联种群数目相同时,任选一个参考点进入p
t+1
。
[0046]
更进一步地,所述as-nsga-iii算法自适应交叉算子设计包括:
[0047]
在种群进化阶段,遗传算子采用模拟二进制交叉和多项式变异来增加种群的多样性,让交叉参数t1,变异参数t2,交叉概率pc,变异概率pm均自适应种群大小n取值。
[0048]
本发明的优点:
[0049]
本发明的算法,首先在种群进化阶段通过设计交叉变异算子自适应种群数动态变化来增加解的多样性;其次在参考点的生成中,通过对划分份数的动态调整来控制参考点的数量,避免参考点过多造成算法的计算复杂度增大和参考点过少丧失种群个体的筛选功能等问题;最后在platemo平台上将本发明算法与经典nsga-ii、nsga-iii算法和现有的改进nsga-iii算法作对比实验,实验证明:本发明提出的算法在一定程度上减少了多余参考点的产生,增加了种群的多样性,提高了pareto解集的收敛性和分布性。
[0050]
除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照图,对本发明作进一步详细的说明。
附图说明
[0051]
构成本技术的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
[0052]
图1是图1as-nsga-iii算法流程图;
[0053]
图2是参考点在超平面的分布图;
[0054]
图3是本发明的gd指标结果迭代图;
[0055]
图4是本发明的sp指标结果迭代图;
[0056]
图5是本发明的igd指标结果迭代图。
[0057]
附图标记:
[0058]
1为参考点、2为规范化超平面、3为理想点。
具体实施方式
[0059]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0060]
自适应调度nsga-iii算法
[0061]
as-nsga-iii算法
[0062]
针对nsga-iii算法在种群多样性、算法收敛性及计算复杂度等方面存在的不足,本发明算法主要在参考点的生成和种群前期交叉变异中做了改进。在参考点生成设计中,为了使参考点数量合理减少计算复杂度,本发明提出了一种让参考点h自适应种群规模n生成,由公式(1)可知,当维数一定时,划分份数p的选择直接决定参考点的数量,因此通过对p的动态调整来控制参考点的数量,为了保证筛选效果,将求出的参考点数目设为约等于种群大小;在交叉变异算子中,为避免人为设定的交叉变异算子在进化过程中导致概率不均和种群多样性减少的问题,本发明在种群交叉变异时让其参数t
1 t2与概率pcpm依据种群规模n自适应取值。as-nsga-iii算法流程图如图1所示。
[0063]
as-nsga-iii算法参考点设计
[0064]
(1)确定超平面上的参考点
[0065]
nsga-iii使用一组预定义的参考点来确保解的多样性,其参考点在一个m维的超平面上,m是目标空间的维度,若将每个目标划分为p份,均匀产生h(m,p)个参考点。假定维数m=3,划分份数p=4,则参考点在平面上的分布如下所示:
[0066]
当维数一定,由式(1)可知,划分份数p的少量增加会导致参考点数急速上升,假设m=10,p=10时,将产生92378个参考点,这就使得无用参考点增多,导致算法计算复杂度增大且种群多样性降低。
[0067]
因此,本发明在参考点设定上,让参考点数目自适应种群规模n,假设划分份数p
1 p2,分别由式(2)求出参
[0068]
考点集w1,由式(3)求出参考点集w2,使得w1《n,w2》n,则有
[0069][0070]
其中,w1是划分份数p1生成的参考点集,m和p在超平面空间经过排列组合生成均匀分布的参考点集w1。
[0071][0072]
其中,w2由划分份数p2与p1生成的参考点集的差值构成,避免w2与w1有重复参考点产生,提高了算法的计算效率。
[0073][0074]
假设m=3,p1=11,p2=10,若目标数m=3,群规模n=100,根据式(2)(3)(4)可得,w1=105,w2=91,w=98,所以初始参考点数选择98。在此过程中,w1由das and dennis’s method产生,w2由w2与w1的差值构成,避免了选取的参考点重复、过大或者过小带来的弊端,也避免了逐一选择参考点花费的时间代价。
[0075]
(2)关联种群参考点
[0076]
让种群中的k个个体分别关联到相应的参考线。首先定义参考线,即在目标空间中原点与参考点的连线,其次计算种群中的每个个体到与其最近参考线的垂直距离,最后将种群个体与和它最近的参考线关联起来。
[0077]
(3)参考点小生境数计算
[0078]
当完成关联操作后,会出现以下三种情况:
[0079]
①
没有一个个体与参考点相关联。当没有参考点与种群个体关联时,直接删除参考点,减小计算复杂度;
[0080]
②
一个参考点关联一个或多个个体。当有种群与参考点相连时,选择最小生境数最小的进入p
t+1
,此时,小生境数pj=p
j+1
,重复计算,直到p
t+1
=n时算法结束。
[0081]
③
多个参考点关联种群数目相同。当多个参考点关联种群数目相同(即小生境数相等)时,任选一个参考点进入p
t+1
。
[0082]
as-nsga-iii算法参考点生成步骤如表2所示:
[0083]
表2 as-nsga-iii算法参考点生成步骤
[0084][0085]
as-nsga-iii算法自适应交叉算子设计
[0086]
由于人为设定的交叉变异参数不具备普遍性且容易导致概率不均等问题,最终使得种群多样性减少,pareto解陷入局部最优,因此本发明在种群进化阶段,遗传算子采用模拟二进制交叉和多项式变异来增加种群的多样性,让交叉参数t1,变异参数t2,交叉概率pc,变异概率pm均自适应种群大小n取值,避免认为设定的概率不均导致种群多样性下降,其伪代码如表3所示:
[0087]
表3交叉变异算子伪代码
[0088][0089][0090]
仿真实验
[0091]
为了验证本发明as-nsga-iii算法在高维多目标空间的各项性能,本发明在matlab上运行多目标优化平台platemo,选取dtlz测试集系列对其进行测试,为了保证实验的公平性,本发明设定种群大小为n=100,迭代次数为gmax=300次,最大评价次数maxfe=n*gmax=30000,平台每个算法针对每一个测试函数独立运行30次并记录其平均值。
[0092]
测试函数
[0093]
为了测试本发明算法的有效性,采用由deb、thiele等人提出的dt z系列测试函数
对各类算法进行测试对比,dtlz部分测试函数性质如表4所示:
[0094]
表4dtlz部分测试函数性质
[0095][0096]
算法性能评价指标
[0097]
为了验证算法的有效性,本发明采用以下3个评价指标来对各类算法进行测试。
[0098]
1、收敛性指标gd:即世代距离,用来衡量算法求得的解集与真实pareto前沿之间的逼近程度,gd越小则说明所获前端收敛的效果越好。gd的数学表达式为:
[0099][0100]
式中p*为多目标进化算法得到的解集;p是在真实pareto前沿上采样的一组均匀分布的参考点;|p|表示点集p中的个体数量;dis(x,y)表示解集p*中的点y和参考集p中的点x之间的最小欧氏距离。
[0101]
2、均匀性指标sp:即空间评价方法,可衡量pareto前沿近似解集中个体在目标空间的分布情况。其值越小,说明解集分布越均匀。sp的数学表达式为:
[0102][0103]
式中,p为在实pareto前沿采样的均匀分布参考点集合,|p|表示p中解的个数,为解集中非支配边界上两个连续向量的欧氏距离,即di的平均距离。
[0104]
3、综合性指标igd:即反世代距离,它表示计算真实pareto面到最终解集的最小欧式距离,其值越小,收敛性和多样性表现越好。igd的数学表达式为:
[0105][0106]
式中p*为多目标进化算法得到的解集;p是在真实pareto前沿上采样的一组均匀分布的参考点;|p|表示点集p中的个体数量;dis(x,y)表示解集p*中的点y和参考集p中的点x之间的最小欧氏距离。
[0107]
实验结果及分析
[0108]
实验设计主要将本发明改进算法与传统经典算法nsga-ii,nsga-iii及文献中提出的ar-nsga-iii进行比较,验证算法的有效性。
[0109]
1、收敛性指标gd结果分析:表5为四个算法在dtlz测试函数上的gd结果。表中m为目标空间,d为决策空间,加粗字体表示各类算法中最优者。
[0110]
表5gd指标对比
[0111][0112]
注:表中m表示目标空间,d表示决策空间,加粗字体表示所有算法中效果最好的算法由表5可知,随着目标函数m的增大,参考点数随之增多,导致各算法的gd指标值均有所上升,所求解集的收敛性下降。但本发明算法在维数一定的条件下,通过控制参考点划分份数p的值来控制参考点的数量,使得算法所求得的pareto解集加快收敛。对比可以看出,本发明算法在16个测试函数上的igd指标值取得15个最优值和1个次优值,说明改进后的算法的收敛性效果要更好。由此可知,参考点的改进是提高算法收敛性的关键。
[0113]
2、多样性指标sp结果分析:表6为四个算法在dtlz测试函数上的sp结果
[0114]
表6sp指标对比
[0115][0116]
注:表中m表示目标空间,d表示决策空间,加粗字体表示所有算法中效果最好的算法
[0117]
由表6可知,本发明算法在整个测试函数上的sp指标值相较于其他算法绝大多数都比较小。虽然本发明算法的sp指标值在3-5维的dtlz2和dtlz4函数上相较于ar-nsga-iii算法有小幅度增大,但在16个测试函数上的sp指标值取得12个最优值和4个次优值,所以本发明算法相较于其它算法仍占有较大优势。由此可见,交叉变异算子自适应种群规模取值
很好地保持了种群多样性,使得解在空间均匀分布,避免了算法陷入局部最优。
[0118]
3、综合性指标igd结果分析:表7为四个算法在dtlz测试函数上的igd结果。
[0119]
表7igd指标对比
[0120][0121]
注:表中m表示目标空间,d表示决策空间,加粗字体表示所有算法中效果最好的算法
[0122]
由表7可以看出,在dtlz测试函数中,随着目标函数m的增大,虽然各类算法的igd指标值有所增大,但都在很小的范围内波动。对比可知,本发明算法在16个测试函数上的igd指标全部取得最优值,尤其对于dtlz4这个相对不易收敛的函数,本发明算法的igd指标值相较于其他算法明显减小,这说明本发明算法得到的pareto解集的收敛性和分布性效果最好,在寻找最优解时不易陷入局部最优且能够更有效地对解空间进行搜索。
[0123]
4、为了更直观的展示种群在高维空间的进化过程,将上表最优算法和次优算法的gd,sp及igd指标结果迭代图在任意选择的dtlz测试函数上绘制,横坐标为迭代次数,纵坐标为性能指标,本次测试选用测试函数dtlz1,m=8,d=12。
[0124]
由图3可知,在高维空间中随着迭代次数的增加,nsga-ii算法最终未达到收敛,虽然nsga-iii和ar-nsga-iii算法均逐渐收敛,但在收敛过程中gd指标曲线有所波动,只有本发明算法是平稳收敛到零。由此证明,本发明算法具有更好的收敛效果。
[0125]
由图4可知,随着迭代次数的增加,算法从r
t
中选出n个个体作为新的父代种群后,剩余的n个个体被删除,导致种群多样性减小,sp值增大。因此,四个算法的sp指标曲线均有波动,其中nsga-ii的sp指标曲线最大且最终未达到收敛,nsga-iii和ar-nsga-iii算法虽达到收敛但波动较大。由于本发明算法的交叉变异算子采用自适应种群变化的方式,从而保持了种群多样性,因此sp指标曲线的波动幅度较小且最早收敛,解的分布也最均匀。
[0126]
由图5可知,随着迭代次数的增加,as-nsga-iii算法在迭代初期igd指标值就低于其余各类算法,说明其得到的解的收敛性和分布性从迭代初期就处于最优状态,nsga-iii和ar-nsga-iii算法次之,nsga-ii算法性能最差且最终未达到收敛。从整个迭代过程来看,本发明算法的igd指标曲线最扁平,这也说明了算法具有良好的鲁棒性。
[0127]
结论
[0128]
本发明针对nsga-iii算法在交叉突变算子和参考点选择不佳两方面导致的种群多样性减少、计算复杂度增大、收敛速度缓慢等问题,提出as-nsga-iii算法,通过对遗传算子和参考点的重新设计,有效地解决了nsga-iii存在的问题。将本发明算法与经典算法和
现有改进算法进行比较,实验结果证明,本发明提出的算法在一定程度上减少了无用参考点的产生,提高了种群的多样性和pareto解集的收敛速度。
[0129]
本发明在nsga-iii算法改进的过程中,从算法选择机制和初始化两部分进行改进,主要工作有:
[0130]
(1)在参考点生成设定中,提出了一种控制参考点生成数量的方法,解决了算法选取参考点过多或者过少所带来的问题,提高了pareto解集的收敛性和分布性。
[0131]
(2)本发明在种群交叉变异时让其参数与概率依据种群规模n自适应取值,使得种群更具有普遍性的同时又增加了种群的多样性。
[0132]
本发明针对nsga-iii算法中存在的种群多样性低、算法计算复杂度高及收敛速度缓慢等问题,本发明提出了一种基于自适应调度的nsga-iii算法,该算法首先在种群进化阶段通过设计交叉变异算子自适应种群数动态变化来增加解的多样性;其次在参考点的生成中,通过对划分份数的动态调整来控制参考点的数量,避免参考点过多造成算法的计算复杂度增大和参考点过少丧失种群个体的筛选功能等问题;最后在platemo平台上将本发明算法与经典nsga-ii、nsga-iii算法和现有的改进nsga-iii算法作对比实验,实验证明:本发明提出的算法在一定程度上减少了多余参考点的产生,增加了种群的多样性,提高了pareto解集的收敛性和分布性。
[0133]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1