结合难分样本生成与学习的SAR图像目标开集识别方法
本发明属于雷达通信,更进一步涉及雷达自动目标识别中的一种结合难分样本生成与学习的合成孔径雷达sar(synthetic aperture radar)目标开集识别方法。本发明可用于雷达干扰环境为开放场景下识别sar图像目标的类型。
背景技术:
1、雷达自动目标识别技术ratr(radar automatic target recognition)是典型的开放场景识别任务,其面向的是合作目标与非合作目标,类别众多、型号繁杂,训练阶段很难建立完备的目标识别库,即测试阶段存在未知类目标。传统的模式识别技术是在闭集假设条件下设计的,即假定训练样本中出现的类别标记集合包含所有待识别样本的类别标记,不存在未知类目标。在真实的开放环境中,当库外未知类目标进入到模型时,闭集识别模型会强制将未知类目标错分为某一库内类别,这极大地限制了模型在开放环境中的应用。因此,期望一个能够识别/拒判未知类目标同时保持对已知类目标识别性能的分类器,在雷达自动目标识别中实现对输入的已知类样本,输出为具体的某个类别,对输入的未知类样本,拒判为未知类类别。在开放环境中感知未知类目标,正确且自适应地检测到未知类目标的存在并识别已知类目标是雷达开放环境下识别的前提和基础。
2、zeng zhiqiang等人在其发表的论文“unknown sar target identificationmethod based on feature extraction network and kld–rpa joint discrimination”(remote sensing,2021,7)中提出了一种结合相对熵与相对位置角度量的sar图像目标开集识别方法。该方法包含一个特征提取器和分类器。特征提取器输入训练集的图像,输出128维高维特征,分类器输入128维高维特征,输出特征对应的预测概率分布。该方法实现步骤是,第一步,将训练集的所有图像输入特征提取器得到高维特征,高维特征输入分类器得到预测概率分布,最小化预测概率分布与真实标签之间的交叉熵损失;第二步,计算训练集不同类别图像128维特征的均值以及测试集对应特征相较于训练集特征的相对角度范围。在测试阶段,将待识别图像目标输入到特征提取器,输出128维高维特征。当128维高维特征与训练集各类别特征均值的相对熵均大于预设相对熵阈值,或者特征相较于训练集特征的相对角度范围大于预设相对角度阈值时,模型将待识别图像目标拒判为未知目标类,否则送入分类器得到预测概率分布,识别为最大概率预测值对应的类别。该方法存在的不足之处是,训练阶段需要借助测试集图像信息预设两个合适的阈值,由于在工程实践中无法提前获取测试集图像类别,因此,该方法的拒判阈值设置策略敏感性高且数据适应性差,远不能满足真实开放场景下工程实践的要求。
3、西安电子科技大学在其申请的专利文献“一种雷达高分辨距离像开集识别方法及装置”(专利申请号:cn202111199838.4,申请公布号cn 114137518 a)中公开了一种雷达目标开集识别方法。该方法采用卷积神经网络技术构建各类别原型向量增强类内聚合性,同时组合各层的初级特征,从而得到更高层的特征进行目标识别,因此发明对已知目标类的识别率有显著性提高。在测试阶段,当待识别目标的最大预测概率值小于人为设定的阈值时,模型将待识别目标拒判为未知类目标,否则,识别为最大预测概率值对应的类别。该方法存在的不足之处是,训练阶段仅关注已知目标类的识别性能,无法有效地降低模型地开放空间风险,难以建立良好的拒判界面,直接应用于真实开放场景时会产生严重的混淆,远不能满足工程实践过程中识别性能的要求。
技术实现思路
1、本发明的目的在于针对上述现有技术存在的不足,提出了一种结合难分样本生成与学习的sar图像目标开集识别方法,旨在解决现有技术数据适应性差和拒判阈值设置敏感的问题。
2、实现本发明目的的思路是,本发明使用训练集图像和噪声序列,计算特征空间易混淆的难分样本特征,生成数据空间高质量的难分图像,组成能够表征实际开放空间中未知目标类统计特性的难分样本。网络对难分样本的学习增强了未知目标类的感知能力,缓解了现有技术无法降低开放空间风险而引起的数据适应性差的问题。本发明根据训练集图像的统计特性自动确立拒判阈值,缓解了现有技术人为设置拒判阈值而出现的敏感性高的问题。本发明设计的难分样本生成与学习方法克服了现有技术数据适应性差和拒判阈值设置敏感的问题,实现了库内已知目标类的准确识别和库外未知目标类的精准拒判。
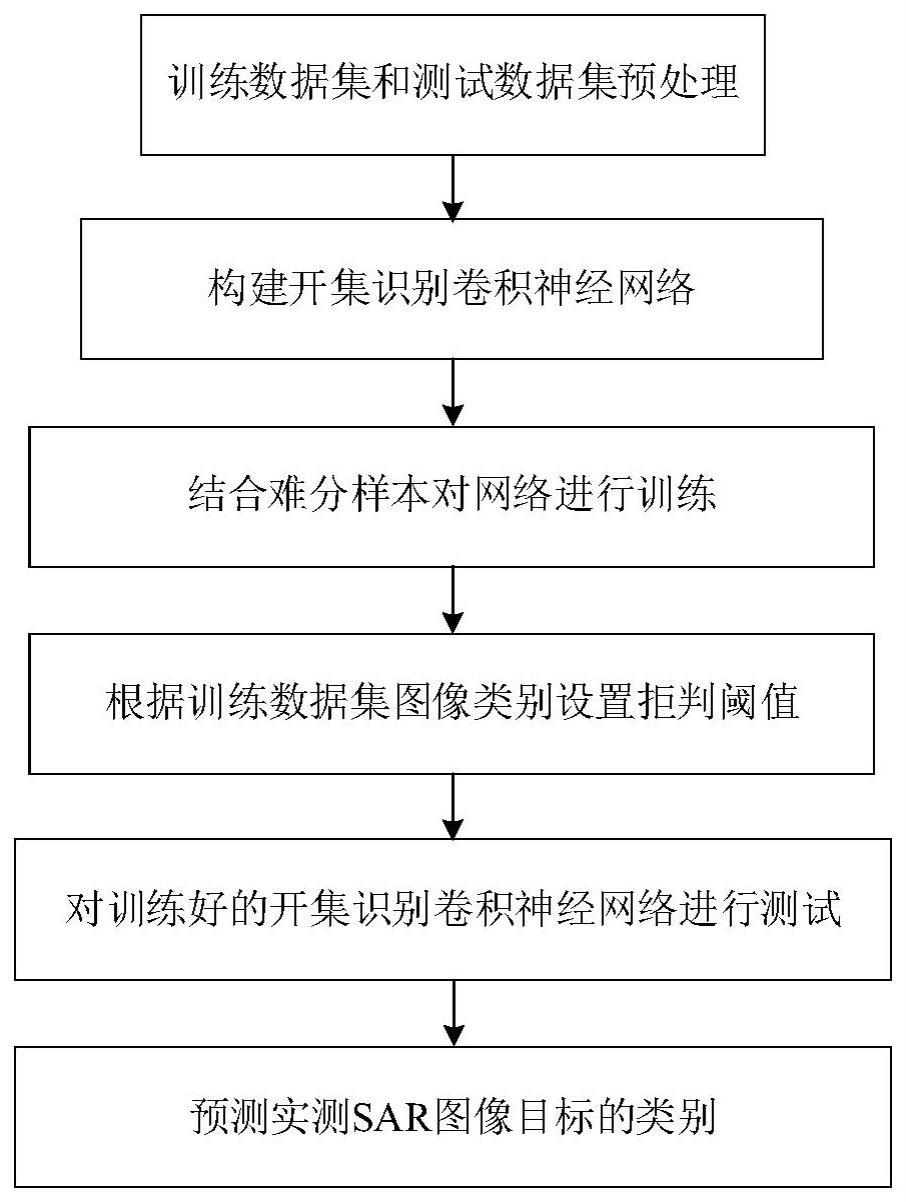
3、本发明采取的技术方案包括如下步骤:
4、步骤1,生成训练集:
5、将样本集中雷达工作俯仰角为17°共2746张图像中的每张图像均裁剪为64×64个像素的图像,所选取的所有图像包含10个类别,在类别标签[1,10]的范围内,对每张图像的目标类别进行标注,再将所有裁剪后的图像和对应类别标签组成训练集;
6、步骤2,构建开集识别卷积神经网络:
7、步骤2.1,构建生成器子网络:
8、搭建一个由五个反卷积层串联组成的生成器子网络。将第一至第四反卷积层的卷积核数量依次设置为1024、512、256、128和3,卷积核大小均设置为4×4,卷积核步长依次设置为1、2、2、2和2,填充方式均设置为等大填充方式,偏差置均设置为0;
9、步骤2.2,构建判别器子网络:
10、搭建一个由四个卷积层串联组成的生成器子网络。将第一至第四卷积层的卷积核数量依次设置为128、256、512和1024,卷积核大小均设置为4×4,卷积核步长依次设置为1、1、1和0,填充方式均设置为等大填充,偏差置均设置为0;
11、步骤2.3,构建分类器子网络:
12、构建一个由一组卷积层组和一个全连接层串联组成的分类器子网络,其中,一组卷积层组由九个卷积层串联组成;将第一至第九卷积层的卷积核数量依次设置为64、64、128、128、128、128、128、128和128,卷积核大小均设置为3×3,卷积核步长依次设置为1、1、2、1、1、2、1、1和2,填充方式均设置为等大填充,偏差置均设置为0;将全连接层参数设置为128×k,k表示训练样本的总类别数,偏差置均设置为0;
13、步骤2.4,将生成器子网络和判别器子网络并联后再与分类器子网络串联,构成开集识别卷积神经网络;
14、步骤3,结合难分样本训练开集识别卷积神经网络:
15、步骤3.1,将从标准正态分布中随机采样的噪声序列,输入到开集识别卷积神经网络中,经生成器子网络后输出的噪声生成图像,经判别器子网络后输出每张噪声生成图像的判别置信得分;将训练集的每张图像输入到开集识别卷积神经网络中,经判别器子网络后输出每张图像的判别置信得分。利用交叉熵损失函数,计算每张图像的判别置信得分与该图像对应的域标签之间的损失值,得到判别器子网络的总损失函数;使用adam优化算法,更新当前判别器子网络参数;
16、步骤3.2,将重新从标准正态分布中随机采样的噪声序列,输入到开集识别卷积神经网络中,经生成器子网络后输出的噪声生成图像,经判别器子网络后输出每张噪声生成图像的判别置信得分,经分类器子网络后输出每张噪声生成图像的预测概率分布;利用交叉熵损失函数,计算每张噪声生成图像的预测概率分布与该图像对应的类别标签之间的损失值,计算每张噪声生成图像的判别置信得分与域标签之间的损失值,得到生成器子网络的总损失函数;使用adam优化算法,更新当前生成器子网络参数;
17、步骤3.3,将训练集的每张图像输入到开集识别卷积神经网络中,经分类器子网络后输出每张图像的已知目标类特征,经梯度下降的难分样本特征生成算法计算每张图像对应的难分样本特征;
18、步骤3.4,将重新从标准正态分布中随机采样的噪声序列,输入到开集识别卷积神经网络中,经生成器子网络后输出噪声生成图像;噪声生成图像经过判别器子网络后,根据判别置信得分生成判别置信得分较高的难分图像;难分图像经过分类子网络后输出每张难分图像的难分图像特征。难分图像特征和难分样本特征共同组成难分特征集,已知目标类特征组成训练特征集;
19、步骤3.5,将训练特征集和难分特征集输入到开集识别卷积神经网络中,经分类器子网络后输出每个特征对应的预测概率分布。利用交叉熵损失函数,分别计算三个损失函数,计算训练特征集中每个特征与该特征对应的类别标签之间的损失值,计算训练特征集中每个特征与该特征对应的平滑标签之间的损失值,计算难分特征集中每个特征与均匀分布之间的损失值,得到分类器子网络的总损失函数;使用sgdm优化算法,更新当前分类器子网络参数;
20、步骤3.6,重复步骤3.1至3.5,迭代更新训练次数次开集识别卷积神经网络中生成器子网路、判别器子网络和分类器子网络的参数,得到训练好的开集识别卷积神经网络;
21、步骤4,设置开集识别卷积神经网络的拒判阈值;
22、步骤5,获取待识别sar图像目标的预测概率分布;
23、采用与步骤1相同的方式,对待识别的sar图像做裁剪,得到裁剪后的sar图像目标,将裁剪后的sar图像目标输入到开集识别卷积神经网络中,经分类器子网络后输出对应的预测概率分布;
24、步骤6,判断待识别sar图像目标预测概率分布中最大值是否大于拒判阈值,若是,则执行步骤7,否则,执行步骤8;
25、步骤7,选择sar图像目标预测概率分布中得分最大值对应的类别作为识别结果输出;
26、步骤8,将sar图像目标判定为未知目标类输出。
27、与现有技术相比,本发明具有以下优点:
28、第一,本发明计算和生成表征实际开放空间中难分未知目标类统计特性的难分样本,经网络的学习提高了未知目标类的感知能力,克服了现有技术数据适应性差的不足,使得本发明具有良好的泛化能力。
29、第二,本发明根据训练集图像的统计特性自动确立拒判阈值,克服了现有技术人为预设阈值带来的敏感性高的不足,使得本发明能够准确识别库内已知目标类的同时,精准拒判库外未知目标类。
- 还没有人留言评论。精彩留言会获得点赞!