MFCC提取的分布式流处理方法、系统、存储介质及计算机
mfcc提取的分布式流处理方法、系统、存储介质及计算机
技术领域
1.本发明涉及工业大数据和信号处理领域,用于机械设备振动信号、声音信号的实时处理,具体涉及mfcc提取的分布式流处理方法、系统、存储介质及计算机。
背景技术:
2.mfcc,全称为mel frequency cepstrum coefficient,即梅尔频率倒谱系数,mfcc常用于声音信号的处理,也用于振动信号处理。在机械设备运维场景下,振动监测和声音监听是常用的技术手段,通过提取信号的mfcc,用于机械设备的异常检测和故障诊断。
3.目前已知的mfcc提取方法和技术,都是在振动数据或声音数据采集完成后进行离线分析的,mfcc提取算法需要对采集的信号进行分帧处理。当被监测设备数量增多,振动、声音传感器数量变得越来越庞大时,信号经过分帧后将形成巨量的矩阵,给离线特征提取工作带来巨大压力,而且由于特征提取滞后,难以满足需要实时分析mfcc的在线故障诊断场景。
技术实现要素:
4.为了解决被监测设备数量较多时,振动、声音传感器数量变得越来越庞大时,信号经过分帧后将形成巨量的矩阵,给离线特征提取工作带来巨大压力,而且由于特征提取滞后,难以满足需要实时分析mfcc的在线故障诊断场景等技术问题,本发明提供mfcc提取的分布式流处理方法、系统、存储介质及计算机。
5.本发明解决上述技术问题的技术方案如下:
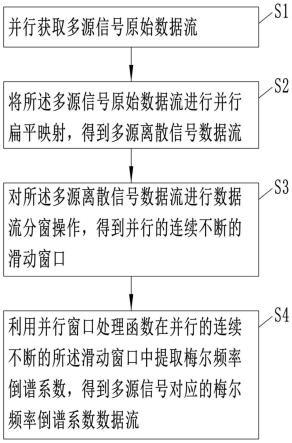
6.mfcc提取的分布式流处理方法,包括如下步骤:
7.并行获取多源信号原始数据流;其中,所述多源信号原始数据流的数据类型为string数据;
8.将所述多源信号原始数据流进行并行扁平映射,得到多源离散信号数据流;
9.对所述多源离散信号数据流进行数据流分窗操作,得到并行的连续不断的滑动窗口;
10.利用并行窗口处理函数在并行的连续不断的所述滑动窗口中提取梅尔频率倒谱系数,得到多源信号对应的梅尔频率倒谱系数数据流。
11.本发明的有益效果是:振动、声音等信号,每毫秒就产生很多个数据点,如果对数据点进行逐个发送,很有可能就会出现先发生的数据点后到达处理系统的情况,这样处理系统收到的数据就会出现乱序。所以本发明通过将多个毫秒采集的数据封装成一个string格式的片段来发送,片段内的信号数据点是按照原本发生顺序排列的,因此不会乱序,由于每个片段产生前后相差有多个毫秒,在网络传输正常时片段之间也不会产生乱序。当原始数据流的数据源有多个时,通过对数据流进行扁平映射以及分区分窗操作,让多源数据流的梅尔频率倒谱系数提取工作能够并行执行,提高梅尔频率倒谱系数的提取效率和及时性,避免了大批数据离线处理的滞后性以及数据处理量庞大而带来的数据处理压力。
12.在上述技术方案的基础上,本发明还可以做如下改进。
13.进一步,所述string数据至少包括时间戳、传感器id、信号值以及分隔符,其中,所述传感器id为所述原始数据流对应的传感器编号。
14.进一步,将所述多源原始数据流进行并行扁平映射,得到多源离散信号数据流,包括如下步骤:利用flink流处理方法将所述多源原始数据流进行并行扁平映射,得到多源离散信号数据流。
15.采用上述进一步方案的有益效果是,flink流处理具备的高吞吐、低延迟、分布式等特点,提高了数据处理效率。
16.进一步,对所述多源离散信号数据流进行数据流分窗操作,得到把并行的连续不断的滑动窗口,包括如下步骤:
17.将所述多源离散信号数据流按照传感器id进行keyby操作,得到键控数据流;其中,keyby操作具体为将传感器id相同的所述多源离散信号数据流发送到指定分区中;
18.对每一分区中的所述键控数据流进行数据流分窗操作,得到每个传感器对应的并行的连续不断的滑动窗口。
19.进一步,利用并行窗口处理函数在连续不断的所述滑动窗口中提取梅尔频率倒谱系数,得到梅尔频率倒谱系数数据流,包括如下步骤:
20.利用所述并行窗口处理函数将每个所述滑动窗口中的数据存储在一个对应的双精度数组中;
21.对每个所述双精度数组调用梅尔频率倒谱系数提取函数得到所述梅尔频率倒谱系数数据流。
22.进一步,所述梅尔频率倒谱系数提取函数包括主函数以及多个子函数,多个所述子函数分别为梅尔滤波器组函数、离散余弦变换函数、快速傅里叶变换函数以及海明窗口函数;
23.将所述双精度数组输入所述主函数,所述主函数通过调用多个所述子函数对所述双精度数组进行计算,得到梅尔频率倒谱系数。
24.为了解决上述技术问题,本发明还提供多源信号梅尔频率倒谱系数提取分布式流处理系统,其具体技术内容如下:
25.mfcc提取的分布式流处理系统,包括:
26.数据获取模块,用于并行获取多源信号原始数据流;其中,所述多源信号原始数据流的数据类型为string数据;
27.数据处理模块,用于将所述多源信号原始数据流进行并行扁平映射,得到多源离散信号数据流;对所述多源离散信号数据流进行数据流分窗操作,得到并行的连续不断的滑动窗口;利用并行窗口处理函数在连续不断的所述滑动窗口中提取梅尔频率倒谱系数,得到多源信号对应的梅尔频率倒谱系数数据流。
28.基于多源信号梅尔频率倒谱系数提取分布式流处理方法,本发明还提供一种存储介质,其技术内容如下:
29.一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被计算机的处理器执行时,实现上述多源信号梅尔频率倒谱系数提取分布式流处理方法。
30.基于多源信号梅尔频率倒谱系数分布式流处理提取方法,本发明还提供一种计算
机,其技术内容如下:
31.一种计算机,包括存储器以及处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,实现上述mfcc提取的分布式流处理方法。
附图说明
32.图1为本发明实施例1中一种mfcc提取的分布式流处理方法的流程框图;
33.图2为本发明实施例1中信号流扁平映射处理流程示意图;
34.图3为本发明实施例1中mfcc提取函数集的结构示意图;
35.图4为本发明实施例3中原始振动信号的曲线图;
36.图5为本发明实施例3中振动信号数据流记录图;
37.图6为本发明实施例3中flink mfcc提取任务程序执行框图。
具体实施方式
38.以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
39.实施例1
40.如图1所示,本实施例提供一种mfcc提取的分布式流处理方法,包括如下步骤:
41.s1、并行获取多源信号原始数据流;其中,所述原始数据流的数据类型为string数据;其中,所述string数据至少包括时间戳、传感器id、信号值以及分隔符,所述传感器id为所述原始数据流对应的传感器编号。对于振动信号和声音信号数据源而言,信号采集频率往往很高。以采集频率20khz为例说明,每毫秒将生成20个点,为了避免信号经过网络传输带来的乱序问题,kafka生产者采用循环打包若干毫秒的方式发送消息记录。kafka是由apache软件基金会开发的一个开源流处理平台,是一种高吞吐量的分布式发布订阅消息系统,由scala和java编写。
42.s2、将所述多源信号原始数据流进行并行扁平映射,得到多源离散信号数据流;具体为,利用flink流处理方法将所述多源信号原始数据流进行并行扁平映射,得到多源离散信号数据流;大数据场景下,采用kafka生产者作为数据源,flink程序则从kafka中拉取并消费数据。
43.s3、所述多源离散信号数据流对所述多源离散信号数据流进行数据流分窗操作,得到并行的连续不断的滑动窗口;具体步骤为:将所述多源离散信号数据流按照传感器id进行keyby操作,得到键控数据流;其中,keyby操作具体为将传感器id相同的所述多源离散信号数据流发送到指定的同一分区中;
44.对每一指定的分区中的所述键控数据流进行数据流分窗操作,得到并行的连续不断的滑动窗口。
45.s4、利用并行窗口处理函数在并行的连续不断的所述滑动窗口中提取梅尔频率倒谱系数,得到多源信号对应的梅尔频率倒谱系数数据流。具体步骤为:
46.利用并行窗口处理函数将每个所述滑动窗口中的数据存储在一个对应的双精度数组中;
47.对每个所述双精度数组调用梅尔频率倒谱系数提取函数得到所述梅尔频率倒谱
系数数据流;
48.其中,所述梅尔频率倒谱系数提取函数包括主函数以及多个子函数,多个所述子函数分别为梅尔滤波器组函数、离散余弦变换函数、快速傅里叶变换函数以及海明窗口函数;
49.将所述双精度数组输入所述主函数,所述主函数通过调用多个所述子函数对所述双精度数组进行计算,得到梅尔频率倒谱系数。调用mel滤波器组生成函数,构造出mel滤波器组;然后,调用dct系数矩阵生成函数,得到dct系数;接着对所述双精度数组进行快速傅里叶变换,得到频谱结果;最后,对频谱结果滤波,即用mel滤波器组乘以频谱结果后,求对数并乘以dct系数,得到梅尔频率倒谱系数。
50.如图2所示,多源信号原始数据由对应的kafka分区发送,这样利用flink流处理程序就能以并行的方式从数据源读取数据,数据读取后形成的原始数据流是一条条string格式的数据,然后需要将string格式的数据进行扁平映射。采用flink的flapmap算子来实现这一转换操作,核心是自定义的flatmapfunction。flapmap算子的主要步骤是:按照分隔符将string格式的记录划分成字符串数组array[string];循环遍历字符串数组array[string],从所述字符串数组array[string]的第3个元素即第1个信号值开始,每次循环都发送出包装成如下样例类(caseclass)格式的数据:
[0051]
case class vibelement(ts:long,sensorid:int,acc:double)
[0052]
其中,ts为原始记录的时间戳,sensorid为原始记录的传感器id,acc为离散的信号值。
[0053]
如图3所示,对扁平映射转换后得到的数据流,按照传感器id进行keyby操作,形成键控数据流keyedstream,后续分窗及窗口处理均针对不同的传感器数据流进行独立并行操作。其中,keyby主要作用是把具有相同key的数据发送到相同的分区中;数据本来是分布在不同的slot即分区中,keyby会把相同key的数据拉到相同的slot即分区中。
[0054]
分窗操作采取计数滑动窗口,窗口长度即数据元素个数、滑动步长为分窗操作的两个参数。在信号mfcc提取应用中,窗口长度一般设置为256,滑动步长设置为128。
[0055]
当每个窗口收集完成所有数据时,将数据存储在一个double类型的数组中,然后对这个double类型的数组调用mfcc提取函数,得到densevector[double]类型的mfcc。为了辨识该条mfcc数据所属的传感器id以及信号窗口的时间戳,将最终提取结果包装成如下类型的样例类输出:
[0056]
case class mfccresult(startts:long,endts:long,
[0057]
sensorid:int,mfcc:densevector[double])
[0058]
其中,startts从该窗口的第1条数据中提取,为窗口起始时间戳,endts从该窗口的最后1条数据中提取,为窗口截止时间戳,sensorid即键控数据流所带的key标记。这里时间戳均为事件时间,即传感器信号的采集时间。
[0059]
如图4所示,scala是大数据技术常用的开发语言,为了能供信号流特征提取的flink主程序直接调用,提供用scala开发的mfcc提取函数集,mfcc提取函数集包括主函数、mel滤波器组生成函数、dct函数、fft函数、hamming窗口函数。dct函数为上述的离散余弦变换系数矩阵生成函数,fft函数为快速傅里叶变换函数,hamming窗口函数为海明窗口函数,mel滤波器组生成函数为梅尔滤波器组生成函数,mel滤波器组为梅尔滤波器组。
[0060]
主函数的流程、输入输出以及函数调用关系如下:
[0061]
①
主函数的设计:
[0062]
主函数的输入为array[double]类型的数组x,此外还包括采样率fs、mel滤波器阶数p、fft变换长度n,这三个参数的数据类型均为i nt即整型数据类型,其中p一般设为24。fft表示快速傅里叶变换,数组x表示上述双精度数组。
[0063]
主函数的输出为mfcc,mfcc的格式为p/2的densevector[doub le]类型。
[0064]
主函数的主要流程是:首先,调用mel滤波器组生成函数,构造出mel滤波器组;然后,调用dct系数矩阵生成函数,得到dct系数;接着对数组x进行快速傅里叶变换,得到频谱结果;最后,对频谱结果滤波即用滤波器组乘以频谱,求对数并乘以dct系数,得到mfcc系数。
[0065]
②
me l滤波器组生成函数,把从主函数输入的三个参数fs、p、n传递给该函数,采用常规的mel滤波器组生成方法得到densematr ix[double]类型的me l滤波器组,该矩阵的尺寸为:
[0066]
p
×
(n/2+1)
[0067]
其中,dct系数矩阵生成函数用于把从主函数输入的参数p作为该函数的输入,采用常规的dct系数生成方法得到densematr ix[doub le]类型的dct系数矩阵,该矩阵的尺寸为p/2
×
p。其中,dct系数为离散余弦变换系数。
[0068]
fft函数用于把从主函数输入的数组x作为该函数的输入,采用常规的fft变换方法得到array[doubl e]类型的输出,在fft函数中,首先要对x进行hammi ng窗过滤。
[0069]
hamming窗口过滤函数用于把从fft函数中输入的数组x作为该函数的输入,采用常规的hamming窗口构建方法得到同样长度的数组,作为滤波后的结果。
[0070]
本发明实施例通过将原始数据流的数据设定为str ing数据,振动、声音等信号,每毫秒就产生很多个数据点,如果对数据点进行逐个发送,很有可能就会出现先发生的数据点后到达处理系统的情况,这样处理系统收到的数据就会出现乱序。所以本发明通过将多个毫秒采集的数据封装成一个string格式的片段来发送,片段内的信号数据点是按照原本发生顺序排列的,因此不会乱序,由于每个片段产生前后相差有多个毫秒,在网络传输正常时片段之间也不会产生乱序。当原始数据流的数据源有多个时,通过对数据流进行扁平映射以及分窗操作,让多源数据流的梅尔频率倒谱系数提取工作能够并行执行,提高梅尔频率倒谱系数的提取效率和及时性,避免了大批数据离线处理的滞后性以及数据处理量庞大而带来的数据处理压力。flink流处理具备的高吞吐、低延迟、分布式等特点,提高了数据处理效率。不同于现有技术中离线的梅尔频率倒谱系数特征提取,本发明实施例是在流式处理范式下提取梅尔频率倒谱系数,提取过程中不需要分帧操作。
[0071]
实施例2
[0072]
基于实施例1,本实施例提供一种mfcc提取的分布式流处理系统,包括数据获取模块以及数据处理模块;
[0073]
数据获取模块用于并行获取多源信号原始数据流;其中,所述原始数据流的数据类型为string数据;具体数据获取方式为:采用kafka生产者作为数据源,持续发送string格式的多源信号原始数据流,flink程序则从kafka中拉取并消费数据。
[0074]
数据处理模块,用于将所述多源信号原始数据流进行并行扁平映射,得到多源离
散信号数据流;对所述多源离散信号数据流进行数据流分窗操作,得到并行的连续不断的滑动窗口;利用并行窗口处理函数在并行的连续不断的所述滑动窗口中提取梅尔频率倒谱系数,得到多源信号对应的梅尔频率倒谱系数数据流。
[0075]
其中,将所述原始数据流进行并行扁平映射,得到多源离散信号数据流;具体为,利用flink流处理的flatmap算子将所述原始数据流进行并行扁平映射,得到多源离散信号数据流。
[0076]
所述多源离散信号数据流对所述多源离散信号数据流进行数据流分窗操作,得到并行的连续不断的滑动窗口;具体步骤为:将所述多源离散信号数据流按照传感器id进行keyby操作,得到键控数据流;其中,keyby操作具体为将传感器id相同的所述多源离散信号数据流发送到指定的同一分区中;
[0077]
对每一指定的分区中的所述键控数据流进行数据流分窗操作,得到并行的连续不断的滑动窗口。
[0078]
利用并行窗口处理函数在并行的连续不断的所述滑动窗口中提取梅尔频率倒谱系数,得到多源信号对应的梅尔频率倒谱系数数据流。具体步骤为:
[0079]
利用窗口函数将每个所述滑动窗口中的数据存储在一个对应的双精度数组中;
[0080]
对每个所述双精度数组调用梅尔频率倒谱系数提取函数得到所述梅尔频率倒谱系数数据流;
[0081]
其中,所述梅尔频率倒谱系数提取函数包括主函数以及多个子函数,多个所述子函数分别为梅尔滤波器组函数、离散余弦变换函数、快速傅里叶变换函数以及海明窗口函数;
[0082]
将所述双精度数组输入所述主函数,所述主函数通过调用多个所述子函数对所述双精度数组进行计算,得到梅尔频率倒谱系数。
[0083]
实施例3
[0084]
基于实施例1,本实施例提供一种mfcc提取的分布式流处理方法或一种mfcc提取的分布式流处理系统的实验验证过程以及验证结果。具体实验过程及验证结果如下:
[0085]
以振动传感器采集的加速度信号为实例来对本发明提出的方法和系统进行验证。在本实例中,一共布置了4个振动传感器来实时采集设备的振动信号,信号的采样频率为20khz,图4为1s内的振动信号曲线图。
[0086]
通过kafka生产者并行发布4个传感器的信号流,每8ms产生1条记录,该记录包含160个采样点,得到如图5所示的数据流记录。
[0087]
测试项与测试方法;
[0088]
采用4个振动信号数据源对mfcc提取流处理方法和系统进行测试,主要测试项及其测试方法见表1:
[0089]
表1测试项及测试方法
[0090][0091]
测试过程及结果;
[0092]
mfcc提取分布式流处理功能测试如下:
[0093]
运行kafka生产者程序,并行发送4个振动传感器采集的振动信号数据,每个传感器每8ms均发送160条采样点,将每个传感器每8ms发送的采样点表示为1次记录,持续发送20000次记录,数据流持续时长大约为2.7分钟,测试在此期间能否正常提取并输出mfcc提取结果数据流。
[0094]
按照256长度、128滑动步长的计数窗口,每个传感器的振动采样点为3200000个,提取的mfcc结果的个数累计为:
[0095][0096]
测试结果显示:
[0097]
数据流生成和mfcc特征提取保持同步,信号发送至处理系统的瞬间,mfcc特征提取计算任务就触发并完成了;经过反复多次测试,特征提取结果与离线处理结果完全一致,表明程序设计与运行的正确性;每个传感器mfcc提取结果的条数均为24999,证明数据处理的完整性为100%。
[0098]
mfcc特征提取延迟时间测试:
[0099]
为了测试特征提取延迟时间,在同一台主机上运行kafka生产者程序和flink特征提取流处理主程序,通过mfcc特征处理完成瞬时的计算机系统时间减去窗口截止的事件时间,得到每次生成mfcc的延迟时间,共得到四个传感器特征提取的延迟时间数据样本99996个,相关统计结果见表2。
[0100]
表2延迟时间测试结果
[0101][0102]
由于测试数据经历了从本地主机运行的kafka生产者程序发送到kafka集群,再由本地主机运行的flink主程序从kafka集群拉取数据。经过实测,每个窗口的特征提取本身的处理时间非常短,且小于1ms;因此,延迟时间大部分是网络传输所引入的,即便如此平均30多毫秒的整体延迟也充分证明通过流处理来提取mfcc特征是非常高效的,也就是说从多源信号原始数据产生到对应的mfcc特征输出之间延迟时间是极短的。
[0103]
特征提取程序在计算机集群中的测试:
[0104]
如图6所示,将flinkmfcc提取程序及其第三方依赖打包,部署至hadoop集群。通过“./bin/yarn-session.sh-nmmfccflinktest-d”命令,为执行flink任务开启一个yarn会话。然后通过“./bin/flinkrun-corg.atcsu.mfcc.vibmfccrealtime/opt/program/flinkmfcc-1.0.0.jar”命令,提交flink任务。运行kafka生产者程序,生成多源振动信号原始数据。在集群模式下,程序正常运行,mfcc实时提取结果正确。
[0105]
本发明实施例通过实验验证了测试结果和本地单机测试结果一致,表明计算机集群处理模式下能对多源信号原始数据流进行正确提取mfcc特征,数据产生即完成处理,且数据处理完整率也为100%。因此,本发明能够让多源数据流的梅尔频率倒谱系数提取工作能够实时且并行执行,提高梅尔频率倒谱系数的提取效率和及时性,避免了大批数据离线处理的滞后性以及数据处理量庞大而带来的数据处理压力。
[0106]
实施例4
[0107]
基于实施例1,本实施例提供一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被计算机的处理器执行时,实现上述mfcc提取的分布式流处理方法。存储介质指存储数据的载体。比如软盘、光盘、dvd、硬盘、闪存、u盘、cf卡、sd卡、mmc卡、sm卡、记忆棒(memory stick)、xd卡等。存储介质还可以是基于闪存即nandflash的,比如u盘、cf卡、sd卡、sdhc卡、mmc卡、sm卡、记忆棒、xd卡等。
[0108]
本发明实施通过将程序存储于存储介质中,能够通过处理器来执行程序实现上述mfcc提取的分布式流处理方法,提高数据处理效率。
[0109]
实施例5
[0110]
基于实施例1,本实施例提供一种计算机,包括存储器以及处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,实现上述所述的mfcc提取的分布式流处理方法。通过运行或执行存储在存储器内的软件程序和/或模块,以及调用存储在存储器内的数据,执行终端的各种功能和处理数据,从而对终端进行整体监控,例如实现上述mfcc提取的分布式流处理方法。处理器可以为一个或多个,处理器还可以被实现为计算设
备的组合。
[0111]
本发明实施例通过利用计算机实现上述mfcc提取的分布式流处理方法对应的程序或应用模块,提高数据处理效率。
[0112]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的构思和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1