数据处理方法、装置、计算机设备、存储介质与流程
1.本技术涉及寄存器技术领域,特别是涉及一种数据处理方法、装置、计算机设备、存储介质和计算机程序产品。
背景技术:
2.图形处理器gpu(graphics processing unit)是一种由大量的计算单元组成的大规模并行计算架构。gpu并行程序的核心是线程(wave),一个线程就是程序中的一个单一指令流,多个线程组合在一起形成了并行计算网络,进而形成了并行程序。
3.线程执行指令时,支持不同长度的数据计算,其中有半精度数据(half precision,hp)、单精度数据(full precision,fp)和双精度数据(dual precision,dp),每种数据均可存储整型和浮点型数据。在执行指令时,会遇到输入、输出数据类型混合使用的情况,这就意味着寄存器需要对hp、fp、dp数据混合管理,这对寄存器存储数据带来了不小的挑战。
4.传统技术中,是将寄存器空间分割成三份,分别独立存储hp、fp、dp类型的数据,但是由于未被指令调用的数据类型空间不会被使用,造成寄存器存储空间的浪费。
技术实现要素:
5.基于此,有必要针对上述技术问题,提供一种能够提高寄存器存储空间利用率的数据处理方法、装置、计算机设备、计算机可读存储介质和计算机程序产品。
6.第一方面,本技术提供了一种数据处理方法。所述方法包括:
7.接收数据操作指令;所述数据操作指令是线程调度单元对初始指令进行译码后得到的;所述数据操作指令携带寄存器类型以及指令变量;
8.根据所述寄存器类型以及所述指令变量进行计算,得到与所述数据操作指令对应的映射地址;所述映射地址包括行地址、数据块地址以及偏移量;
9.基于所述映射地址中的所述行地址、所述数据块地址以及所述偏移量,在内存中进行数据操作
10.在其中一个实施例中,上述根据所述寄存器类型以及所述指令变量进行计算,得到不同数据类型对应的映射地址,包括:
11.当所述寄存器类型为矢量寄存器时,根据所述指令变量以及矢量计算规则得到矢量数据映射地址;
12.当所述寄存器类型为标量寄存器时,根据所述指令变量以及标量规则计算得到标量数据映射地址。
13.在其中一个实施例中,当所述寄存器类型为矢量寄存器时,所述指令变量包括线程编号、执行模式、单元位置、数据类型、矢量逻辑地址、数据块数目以及行数;当所述寄存器类型为标量寄存器时,所述指令变量包括所述线程编号、所述数据类型以及标量逻辑地址。
14.在其中一个实施例中,上述当所述寄存器类型为矢量寄存器时,根据所述指令变量以及矢量计算规则得到矢量数据映射地址,包括:
15.根据所述行数、所述线程编号、所述单元位置以及数据类型、所述执行模式以及所述矢量逻辑地址进行计算,得到矢量行地址;
16.根据所述单元位置、所述数据类型以及所述数据块数目进行计算,得到矢量数据块地址;
17.根据所述单元位置、所述数据类型以及所述矢量数据块地址进行计算,得到矢量偏移量。
18.在其中一个实施例中,上述当所述寄存器类型为标量寄存器时,根据所述指令变量以及标量规则计算得到标量数据映射地址,包括:
19.根据所述线程编号,得到标量行地址;
20.根据所述标量逻辑地址以及所述数据类型,得到标量数据块地址;
21.根据所述标量逻辑地址、所述数据类型以及所述标量数据块地址,得到标量偏移量。
22.在其中一个实施例中,上述方法还包括:
23.获取进行数据操作所得到的目标数据;
24.将所述目标数据发送至计算单元,所述计算单元用于根据所述目标数据以单指令流多数据流的方式进行计算操作得到计算数据。
25.第二方面,本技术还提供了一种数据处理装置。所述装置包括:
26.接收模块,用于接收数据操作指令;所述数据操作指令是线程调度单元对初始指令进行译码后得到的;所述数据操作指令携带寄存器类型以及指令变量;
27.映射模块,用于根据所述寄存器类型以及所述指令变量进行计算,得到与所述数据操作指令对应的映射地址;所述映射地址包括行地址、数据块地址以及偏移量;
28.操作模块,用于基于所述映射地址中的所述行地址、所述数据块地址以及所述偏移量,在内存中进行数据操作。
29.第三方面,本技术还提供了一种计算机设备。所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述任意一个实施例中的方法的步骤。
30.第四方面,本技术还提供了一种计算机可读存储介质。所述计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任意一个实施例中的方法的步骤。
31.第五方面,本技术还提供了一种计算机程序产品。所述计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述任意一个实施例中的方法的步骤。
32.上述数据处理方法、装置、计算机设备、存储介质和计算机程序产品,wvr(wave register unit,线程寄存单元)接收数据操作指令,并对数据操作指令进行译码,得到寄存器类型以及指令变量,然后wvr就可以根据寄存器类型以及指令变量进行计算,得到与数据操作指令对应的映射地址;其中,映射地址包括行地址、数据块地址以及偏移量。这样,wvr就可以根据映射地址中的行地址、数据块地址以及偏移量,在内存中进行数据操作。由于根据映射地址中的行地址、数据块地址以及偏移量可以确定数据在寄存器中的具体位置,因
此在对数据存储的时候可以进行混合存储,不必为不同类型的数据开辟单独的存储地址,进而提高寄存机的存储空间利用率。
附图说明
33.图1为一个实施例中数据处理方法的流程示意图;
34.图2为一个实施例中数据块内部结构示意图;
35.图3为一个实施例中vrf的共享空间示意图;
36.图4为一个实施例中的srf的共享空间示意图;
37.图5为一个实施例中寄存器地址映射示意图;
38.图6为一个实施例中的simd32模式示意图;
39.图7为另一个实施例中的simd32模式示意图;
40.图8为一个实施例中的simd64模式示意图;
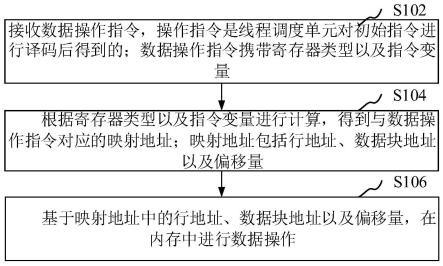
41.图9为一个数据处理方法的流程示意图;
42.图10为一个实施例中数据处理装置的结构框图。
具体实施方式
43.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
44.在一个实施例中,如图1所示,提供了一种数据处理方法,应用于线程寄存单元(wvr,wave register unit),包括以下步骤:
45.s102,接收数据操作指令,操作指令是线程调度单元对初始指令进行译码后得到的;数据操作指令携带寄存器类型以及指令变量。
46.其中,数据操作指令是指对数据进行读或者写的指令,是由线程调度单元(wave controller,wvc)单元对初始指令进行译码后得到的指令,当wvc单元进行译码得到数据操作指令之后,将数据操作指令发送至wvr单元,进行地址映射并进行相应的数据操作;其中,初始指令是wvc选择线程wave,向ic(instruction cache,指令缓存)发送取址指令后,ic根据取指指令的指令偏移为每个线程wave读取的指令。
47.其中,指令变量是指wvc根据初始指令进行译码得到的变量,用于计算与数据操作指令对应的映射地址,指令变量可以是线程编号、执行模式、单元位置、数据类型等。
48.可选地,不同的寄存器类型对应不同的指令变量。示例性的,当寄存器类型为矢量寄存器时,指令变量包括线程编号、执行模式、单元位置、数据类型、矢量逻辑地址、数据块数目以及行数;当寄存器类型为标量寄存器时,指令变量包括线程编号、数据类型以及标量逻辑地址。
49.s104,根据寄存器类型以及指令变量进行计算,得到与数据操作指令对应的映射地址;映射地址包括行地址、数据块地址以及偏移量。
50.具体地,wvr根据寄存器类型以及指令变量进行计算,可以得到与数据操作指令对应的映射地址,通过映射地址可以在内存中进行相应的数据操作。
51.可选地,wvr可以根据映射地址中的行地址确定数据在寄存器中的行位置,然后根
据数据块地址确定具体的block(数据块),最后根据偏移量得到具体的地址。
52.可选地,可以预先将寄存器的共享空间进行划分。进一步地,可以根据不同的寄存器类型对寄存器的共享空间进行划分。
53.可选地,可以预先将寄存器共享空间中的数据块根据不同数据类型进行空间分割,得到不同数据类型的存储空间,如图2所示,图2为一个实施例中数据块内部结构示意图,图2中一个block有64bits存储空间,因此它可以存储1个dp(双精度数据,dual precision,dp)或2个fp(单精度数据,full precision,fp)或4个hp(半精度数据,half precision,hp)数据,图中右上角的数字代表这当前vrf的起始bit数,即偏移量offset。
54.可选地,可以根据线程数量、每一个线程的行数以及每一行的数据块将矢量寄存器(vector register file,vrf)划为为k
×n×m×
64bits大小的存储空间。具体结合图3所示,图3为一个实施例中vrf的共享空间示意图,矢量寄存器(vector register file,vrf)是用来存储矢量数据的共享寄存器地址空间。vrf可同时驱动k个wave(线程),每个wave有n行的存储空间,每行有m个block(数据块),block的内部结构如图2所示。因此根据映射地址中的行地址、数据块地址以及偏移量可以得到当前调用的数据在vrf内的具体位置。
55.可选地,可以根据线程数量、每一个线程的行数以及每一行的数据块将标量寄存器(scalar register file,srf)划为为k
×
p
×
64bits大小的存储空间。具体结合图4,图4为一个实施例中的srf的共享空间示意图,标量寄存器(scalar register file,srf)是用来存储标量数据的共享寄存器地址空间。从图4可知,srf内共有k个wave,与vrf不同的是每个wave里只有一行的存储空间,一行有p个block,block内的构成和vrf相同(参考图2)。同样的,根据映射地址中的行地址、数据块地址以及偏移量可以得到当前调用的数据在srf内的具体位置。
56.结合图5所示,图5为传统技术中的地址映射方法,是把寄存器存储空间分割成三份,分别独立存储hp、fp、dp类型的数据。在运行指令时,首先寄存器接收到数据的读/写操作,然后从地址映射区拿到当前类型数据在存储空间的起始地址(hp/fp/dp_)base和地址范围(hp/fp/dp_)range,接着按照base和range规定的区域,在静态随机存储器sram构造的寄存器中读/写数据。
57.因此,vrf和srf相较于传统技术,可以实现不同数据的混合存储,进而减少存储空间的浪费。并且,在读取数据时根据行地址、数据块地址以及偏移量就可以得到数据在vrf或srf中的具体位置。
58.需要说明的一点是,由于vrf和srf的结构不同,因此需要不同的计算规则来计算其对应的映射地址。
59.s106,基于映射地址中的行地址、数据块地址以及偏移量,在内存中进行数据操作。
60.可选地,当数据操作指令为读指令时,wvr则根据映射地址中的行地址、数据块地址以及偏移量,在内存中进行提取目标数据。
61.可选地,当数据操作指令为写指令时,wvr则根据映射地址中的行地址、数据块地址以及偏移量,在内存中写入目标数据。
62.上述数据处理方法中,wvr接收数据操作指令,并对数据操作指令进行译码,得到寄存器类型以及指令变量,然后wvr就可以根据寄存器类型以及指令变量进行计算,得到与
数据操作指令对应的映射地址;其中,映射地址包括行地址、数据块地址以及偏移量。这样,wvr就可以根据映射地址中的行地址、数据块地址以及偏移量,在内存中进行数据操作。由于根据映射地址中的行地址、数据块地址以及偏移量可以确定数据在寄存器中的具体位置,因此在对数据存储的时候可以进行混合存储,不必为不同类型的数据开辟单独的存储地址,进而提高寄存机的存储空间利用率。
63.在一个实施例中,上述根据寄存器类型以及指令变量进行计算,得到不同数据类型对应的映射地址,包括:当寄存器类型为矢量寄存器时,根据指令变量以及矢量计算规则得到矢量数据映射地址;当寄存器类型为标量寄存器时,根据指令变量以及标量规则计算得到标量数据映射地址。
64.其中,矢量计算规则是指用于计算矢量寄存器映射地址的方法,通过矢量计算规则可以得到矢量数据映射地址;标量计算规则是指用于计算标量寄存器映射地址的方法,通过标量计算规则可以得到标量数据映射地址。
65.具体地,wvr会判断寄存器类型,然后根据寄存器类型选择对应的计算规则,再根据计算规则以及指令变量得到映射地址。示例性的,当寄存器类型为矢量寄存器时,wvr根据指令变量以及矢量计算规则得到矢量数据映射地址;当寄存器类型为标量寄存器时,wvr根据指令变量以及标量计算规则得到标量数据映射地址。
66.在上述实施例中,wvr根据寄存器类型对应的计算规则得到对应的映射地址,这样可以根据不同寄存器的结构准确得到数据在不同类型寄存器中对应的映射地址。
67.在其中一个实施例中,当寄存器类型为矢量寄存器时,指令变量包括线程编号、执行模式、单元位置、数据类型、矢量逻辑地址、数据块数目以及行数;当寄存器类型为标量寄存器时,指令变量包括线程编号、数据类型以及标量逻辑地址。
68.其中,线程编号(wave id,w),代表着当前指令正在执行哪个wave,w∈[0,k-1];指令模式(simd mode,s)代表着一个wave中并行执行单元lane的数量,执行模式有simd32和simd64两种,s的取值分别为32和64;单元位置(lane id,l),表示线程内执行单元所在位置,是线程内执行单元lane的编号,simd32时i∈[0,31],simd64时i∈[0,63];数据类型,记为d,由指令编码规定,代表着当前数据类型vrf的bit数,dp时d=64,fp时d=32,hp时d=16;矢量逻辑地址代表vrf的逻辑地址(vrf index),记为x,由指令编码规定,是当前输入src/输出dst vrf的地址,在各数据类型下可表示为:dp-vrf:dr
x
,fp-vrf:r
x
,hp-vrf:hr
x
;数据块数目是一行寄存器含有数据块的数量;标量逻辑地址代表srf的逻辑地址(srf index):记为y,由指令编码规定,是当前输入src/输出dst srf的地址,在各数据类型下可表示为:dp-srf:dsry,fp-srf:sry,hp-srf:hsry。
[0069]
结合图3,由于vrf包括k个wave,每个wave有n行的存储空间,每行有m个block,因此当寄存器类型为矢量寄存器时,指令变量包括线程编号、执行模式、单元位置、数据类型、矢量逻辑地址、数据块数目以及行数。
[0070]
结合图4,由于srf包括有k个wave,与vrf不同的是每个wave里只有一行的存储空间,一行有p个block,因此当寄存器类型为标量寄存器时,指令变量包括线程编号、数据类型以及标量逻辑地址。
[0071]
在其他实施例中,当寄存器类型为矢量寄存器时,根据指令变量以及矢量计算规则得到矢量数据映射地址,包括:根据行数、线程编号、单元位置以及数据类型、执行模式以
及矢量逻辑地址进行计算,得到矢量行地址;根据单元位置、数据类型以及数据块数目进行计算,得到矢量数据块地址;根据单元位置、数据类型以及矢量数据块地址进行计算,得到矢量偏移量。
[0072]
示例性的,wvr可以根据公式(1),对行数、线程编号、单元位置以及数据类型、执行模式以及矢量逻辑地址进行计算,得到矢量行地址,其中计算公式如公式(1)所示:
[0073][0074]
其中,lineid1表示矢量行地址,floor为向下取整函数。
[0075]
示例性的,wvr可以根据公式(2),对单元位置、数据类型以及数据块数目进行计算,得到矢量数据块地址进行计算,得到矢量数据块地址,其中计算公式如公式(2)所示:
[0076][0077]
其中,blockid1表示矢量数据块地址,floor为向下取整函数。
[0078]
示例性的,wvr可以根据公式(3),对单元位置、数据类型以及矢量数据块地址进行计算,得到矢量偏移量,其中计算公式如公式(3)所示:
[0079][0080]
其中,offset1表示为矢量偏移量,floor为向下取整函数。
[0081]
在上述实施例中,wvr可以根据矢量计算规则以及指令变量精确计算得到矢量行地址、矢量数据块地址以及矢量偏移量,进而准确地对数据进行读写。
[0082]
在其中一个实施例中,当寄存器类型为标量寄存器时,根据指令变量以及标量规则计算得到标量数据映射地址,包括:根据线程编号,得到标量行地址;根据标量逻辑地址以及数据类型,得到标量数据块地址;根据标量逻辑地址、数据类型以及标量数据块地址,得到标量偏移量。
[0083]
示例性的,wvr可以直接将线程编号作为标量行地址,其中计算公式如公式(4)所示:
[0084]
lineid2=w
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(4)
[0085]
其中,lineid2表示标量行地址。
[0086]
示例性的,wvr可以根据公式(5),对标量逻辑地址以及数据类型进行计算,得到标量数据块地址,其中计算公式如公式(5)所示:
[0087][0088]
其中,blockid2表示标量数据块地址,floor为向下取整函数。
[0089]
示例性的,wvr可以根据公式(6),对标量逻辑地址、数据类型以及标量数据块地址进行计算,得到标量偏移量,其中计算公式如公式(6)所示:
[0090]
offset2=y
×
d-64
×
blockid2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(6)
[0091]
其中,offset2表示为矢量偏移量,floor为向下取整函数。
[0092]
在上述实施例中,wvr可以根据标量计算规则以及指令变量精确计算得到标量行地址、标量数据块地址以及标量偏移量,进而准确地对数据进行读写。
[0093]
在其他实施例中,上述方法还包括:获取进行数据操作所得到的目标数据;将目标数据发送至计算单元,计算单元用于根据目标数据以单指令流多数据流的方式进行计算操作得到计算数据。
[0094]
其中,目标数据是指wvr根据映射地址进行数据操作得到的数据;计算数据是指由计算单元对目标数据进行计算后得到的数据。
[0095]
可选地,alu在得到计算数据之后,还需要将计算数据发送至inout(输入输出单元),inout判断alu的计算数据是写入wvr还是发送给其他模块。
[0096]
其中,单指令流多数据流(single instruction multiple data,simd)是gpu中常采用的线程数据计算处理模式。它采用一个控制器控制多个处理器的管理方式,可同时对一组数据中的每一个分别执行相同的操作,从而实现空间上的并行技术。
[0097]
示例性的,结合图6,图6为一个实施例中的simd32模式示意图,数据操作指令:fp16tdp dr0,hr16,fp16tdp指令是把hp类型数据转化为dp类型数据的指令,本实施例中的含义是把hr16中数据写入到dr0中。设当前指令的线程编号w=2,vrf每个wave中有32行存储空间(n=32)。hr16:s=32,d=16,x=16,m=8,设l=20,带入公式(1)~(3)中可知hr16的三元组(lineid1,blockid1,offset1)=(80,5,0),即hr16的lane20在vrf中的第80行第5个block,offset为0。dr0:s=32,d=64,x=0,m=8,设l=5,带入公式(1)~(3)可知dr0的三元组(lineid1,blockid1,offset1)=(64,5,0)。
[0098]
示例性的,结合图7,图7为另一个实施例中的simd32模式示意图,其中图7(a)为hsr6在srf中的分布情况;图7(b)为hr2和hr15在vrf中的分布情况。数据操作指令为fadd hr15,hr2,hsr6,fadd指令是计算乘积的指令,本实施例中的含义是把hsr6和hr2相乘,结果保存在hr15中。设当前指令的线程编号w=0,vrf每个wave中有32行存储空间(n=32)。hsr6:y=6,d=16,带入公式(4)~(6)可知hsr6的三元组(lineid2,blockid2,offset2)=(0,1,32),即hsr6在srf中的第0行第1个block,block内的offset为32bits。hr2:s=32,d=16,x=2,m=8,设l=30,带入公式(1)~(3)可知hr2的三元组(lineid1,blockid1,offset1)=(2,7,32)。hr15:s=32,d=16,x=15,m=8,设l=14,带入公式(1)~(3)可知hr15的三元组(lineid1,blockid1,offset1)=(15,3,32)。
[0099]
示例性的,结合图8,图8为一个实施例中的simd64模式示意图,其中图8(a)为r8和hr1在vrf中的分布情况;图8(b)为sr7在srf中的分布情况。数据操作指令为fmul sr7,hr1,r8,fmul指令是float型数据的乘法操作,例3的含义是把r8和hr1相乘,结果保存在sr7中。设当前指令的线程编号w=5,vrf每个wave中有64行存储空间(n=64)。r8:s=64,d=32,x=8,m=16,设l=2,带入公式(1)~(3)可知r8的三元组(lineid1,blockid1,offset1)=(336,1,0)。hr1:s=64,d=16,x=1,m=16,设l=42,带入公式(1)~(3)可知hr1的三元组(lineid1,blockid1,offset1)=(321,10,32)。sr7:y=7,d=32,带入公式(4)~(6)可知sr7的三元组(lineid2,blockid2,offset2)=(5,3,32)。
[0100]
在上述实施例中,对目标数据以simd模式进行计算可同时对一组数据中的每一个分别执行相同的操作。
[0101]
在一个示例性实施例中,结合图9所示,图9为一个数据处理方法的流程示意图,图
9包括线程寄存单元(wvr,wave register unit)、线程调度单元(wvc,wave controller)、计算单元(alu)、指令缓存(ic,instruction cache)以及输入输出单元(inout)。
[0102]
其中,wvr用于暂存线程wave的中间数据,每个wave包含多个子单元lane,能够以simd(single instruction multiple data,单指令流多数据流)模式进行读写和计算;每个wvr可存储8个wave的中间数据;vrf和srf中的数据就可以放在wvr中;wvc是管理和调度每个线程的控制单元,包括选择线程、取指、译码、发射等步骤;需要在每个时钟周期按照优先级从8个wave中选择一个合适的wave,发送取指指令、对返回的指令译码、发送指令到alu执行等过程;alu执行单元的核心部件,完成线程wave的计算功能,能够以simd的方式同时处理多个lane的计算,包括算术运算、逻辑运算、位运算、跳转判断、特殊函数等操作;计算结果将写入到wvr或者通过inout输出;其中,ic根据请求的指令偏移为每个线程wave读取指令,它是一种高速缓存,包含缓存空间、匹配控制逻辑、tag单元等部分,缓存空间组织为多个缓存行的形式进行管理。其中,inout用于线程wave通过inout从外部内存读取输入数据、采样纹理、存储计算结果等操作。
[0103]
由图9可知指令的执行步骤为:
[0104]
①
线程调度单元wvc选择线程wave,并向ic发送取址指令。
[0105]
②
wvc拿到ic发回的初始指令并对初始指令进行译码,得到数据操作指令,并将数据操作指令发送至wvr。wvr使用公式(1)~(6)的寄存器映射公式计算地址,从vrf/srf中得到需要的数据,即目标数据,并将目标数据发送至wvc;
[0106]
③
wvc发送指令到alu执行,alu使用上一步拿到的数据,以simd的方式执行计算操作,得到计算数据;
[0107]
④
alu将计算结果发送给inout,并判断alu的计算结果是写入wvr还是发送给其他模块;
[0108]
⑤
根据上一步的判断,执行wvr写入操作或通过inout将数据发送给其他模块。
[0109]
在指令执行步骤的步骤二中,寄存器地址映射具体过程如下:
[0110]
当wvr接收到wvc的读指令时,操作步骤如下:
[0111]
i.wvr接收到wvc的读取指令;
[0112]
ii.判断寄存器类型;
[0113]
iii.当寄存器为vrf时,调用公式(1)~(3)拿到vrf的地址;当寄存器为srf时,调用公式(4)~(6)拿到srf的地址;
[0114]
iv.根据上一步得到的vrf/srf地址,从sram构成地址空间中提取数据;
[0115]
v.将数据发送给wvr;
[0116]
当wvr接收到wvc的写指令时,操作和读指令时类似,同样需要判断寄存器类型并调用公式(1)~(6)得到寄存器数据,然后数据写入vrf/srf中。
[0117]
需要说明的一点是,因为此方法硬件不能检查vrf/srf是否超出范围(out-of-range),因此需要在软件执行时用编译器(compiler)判断vrf/srf的out-of-range问题。
[0118]
在上述实施例中,首先支持多种类型数据的混合管理,实现了寄存器内空间的共享使用;其次,节省了寄存器的存储空间,减少硬件开销;再次,对矢量和标量数据同时有效,可覆盖计算机内矢量和标量数据的存储。
[0119]
应该理解的是,虽然如上所述的各实施例所涉及的流程图中的各个步骤按照箭头
的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤会按照具体执行指令的要求进行顺序调整。而且,如上所述的各实施例所涉及的流程图中的至少一部分步骤可以包括多个步骤或者多个阶段,这些步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤中的步骤或者阶段的至少一部分轮流或者交替地执行。
[0120]
基于同样的发明构思,本技术实施例还提供了一种用于实现上述所涉及的数据处理方法的数据处理装置。该装置所提供的解决问题的实现方案与上述方法中所记载的实现方案相似,故下面所提供的一个或多个数据处理装置实施例中的具体限定可以参见上文中对于数据处理方法的限定,在此不再赘述。
[0121]
在一个实施例中,如图10所示,提供了一种数据处理装置,包括:接收模块100、映射模块200和操作模块300块,其中:
[0122]
接收模块100,用于接收数据操作指令;所述操作指令是线程调度单元对初始指令进行译码后得到的;所述数据操作指令携带寄存器类型以及指令变量;
[0123]
映射模块200,用于根据寄存器类型以及指令变量进行计算,得到与数据操作指令对应的映射地址;映射地址包括行地址、数据块地址以及偏移量;
[0124]
操作模块300,用于基于映射地址中的行地址、数据块地址以及偏移量,在内存中进行数据操作。
[0125]
在一个实施例中,上述映射模块包括:
[0126]
矢量单元,用于当所述寄存器类型为矢量寄存器时,根据所述指令变量以及矢量计算规则得到矢量数据映射地址。
[0127]
标量单元,用于当所述寄存器类型为标量寄存器时,根据所述指令变量以及标量规则计算得到标量数据映射地址。
[0128]
在一个实施例中,当所述寄存器类型为矢量寄存器时,所述指令变量包括线程编号、执行模式、单元位置、数据类型、矢量逻辑地址、数据块数目以及行数;当所述寄存器类型为标量寄存器时,所述指令变量包括所述线程编号、所述数据类型以及标量逻辑地址。
[0129]
在一个实施例中,上述矢量单元包括:
[0130]
矢量行子单元,用于根据所述行数、所述线程编号、所述单元位置以及数据类型、所述执行模式以及所述矢量逻辑地址进行计算,得到矢量行地址。
[0131]
矢量块子单元,用于根据所述单元位置、所述数据类型以及所述数据块数目进行计算,得到矢量数据块地址。
[0132]
矢量偏移子单元,用于根据所述单元位置、所述数据类型以及所述矢量数据块地址进行计算,得到矢量偏移量。
[0133]
在一个实施例中,上述标量单元包括:
[0134]
标量行子单元,用于根据所述线程编号,得到标量行地址。
[0135]
标量块子单元,用于根据所述标量逻辑地址以及所述数据类型,得到标量数据块地址。
[0136]
标量偏移子单元,用于根据所述标量逻辑地址、所述数据类型以及所述标量数据块地址,得到标量偏移量。
[0137]
在一个实施例中,上述装置还包括:
[0138]
目标获取模块,用于获取进行数据操作所得到的目标数据。
[0139]
计算模块,用于将所述目标数据发送至计算单元,所述计算单元用于根据所述目标数据以单指令流多数据流的方式进行计算操作得到计算数据。
[0140]
上述数据处理装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
[0141]
在一个实施例中,提供了一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,该处理器执行计算机程序时实现上述任意一个实施例中的方法的步骤。
[0142]
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述任意一个实施例中的方法的步骤。
[0143]
在一个实施例中,提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述任意一个实施例中的方法的步骤。
[0144]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0145]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本技术专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1