一种基于多智能体强化学习的公交智能调度方法与流程
本发明属于智能交通,特别是涉及一种基于多智能体强化学习的公交智能调度方法。
背景技术:
1、针对公交系统中时间表设计以及车辆排班的优化,国内外学者已经使用多种方法,包括精确算法、启发式算法、时空网络分析、仿真等研究方法,从载客率、乘客换乘、运营成本等方面对问题进行研究,但是现有研究还存在以下问题:
2、1.现有的研究产生的公交车调度时间表一旦确定之后在公交车的行驶过程中就不会在改变了,不能根据实时交通情况进行调节。
3、2.使用基于传统数学方法的算法进行公交车调度问题的求解不能很好的拟合问题,导致算法的效果欠佳。
4、基于以上问题,本发明提出一种基于多智能体强化学习的公交智能调度方法以解决现有技术中存在的问题。
技术实现思路
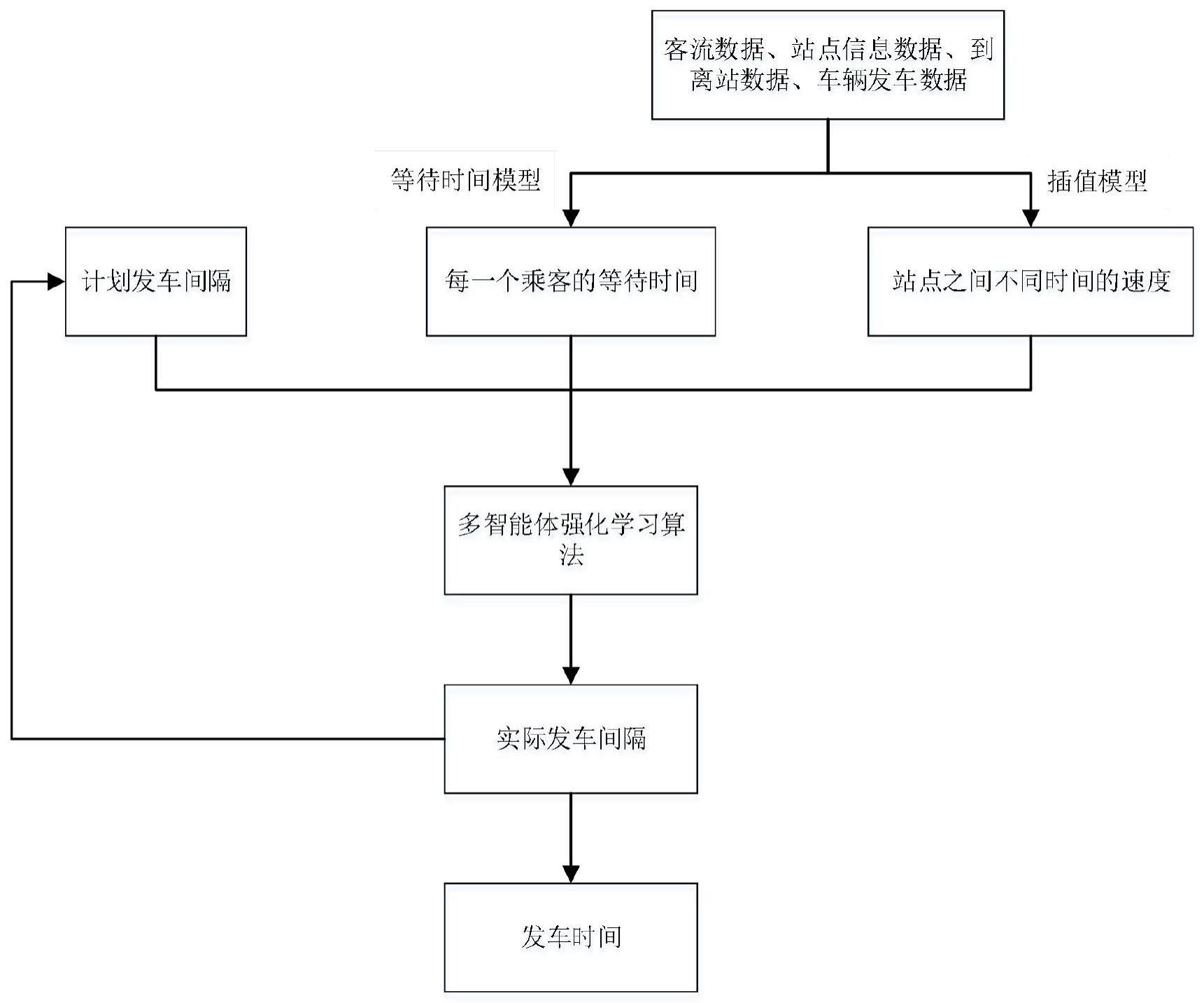
1、本发明的目的是提供一种基于多智能体强化学习的公交智能调度方法,该方法通过汇聚客流数据、站点信息数据、到离站数据、车辆发车数据,构建等待时间模型和插值模型,得到每一个乘客的等待时间和站点之间不同时间的速度,结合公交每条线路实际发车业务场景,对强化学习的状态空间以及奖励函数等进行设计,提出了多智能体强化学习算法,使用深度学习使得算法拥有更强的泛化能力,融入计划发车间隔数据去训练多智能体强化学习算法,最终给出最优的发车间隔,进而得到每条线路每辆车的发车时间,实现公交车辆调度目的,以解决上述现有技术存在的问题。
2、为实现上述目的,本发明提供了一种基于多智能体强化学习的公交智能调度方法,包括以下步骤:
3、基于客流数据、站点信息数据、到离站数据和车辆发车数据构建等待时间模型和插值模型;
4、基于所述等待时间模型,获得每个乘客的等待时间,基于所述插值模型,获得站点之间不同时间段的速度;
5、获取计划发车间隔,基于多智能体强化学习算法对所述每个乘客的等待时间、站点之间不同时间段的速度和计划发车间隔进行训练,获得最终发车间隔,进而获得每条线路每辆车的发车时间,实现公交车辆调度。
6、可选地,基于等待时间模型获得每个乘客的等待时间的过程包括:获取到站乘客之间的到站间隔,基于所述到站乘客之间的到站间隔获得每个乘客的到站时间;基于所述每个乘客的到站时间和每个乘客的上车时间,获得每个乘客的等待时间。
7、可选地,基于插值模型获得站点之间不同时间段的速度的过程包括:选取目标线路的任意两个站点,获取两个站点之间的路段距离以及所有公交车到达两个站点的到站时间;基于所述到站时间获取所有公交车在两个站点间不同时间段的时间间隔;基于所述路段距离和两个站点间不同时间段的时间间隔,获得所有公交车的两个站点间不同时间段的平均速度;基于所述不同时间段的平均速度,利用插值的方式获得两个站点间所有时间段的速度,进而获得所有公交线路的任意两个站点间所有时间段的速度。
8、可选地,所述多智能体包括若干个智能体,其中,每个智能体均表示一条公交线路,每条公交线路均包括上行智能体和下行智能体;若干条公交线路进行耦合处理组成了多智能体调度。
9、可选地,基于多智能体强化学习算法获得最终发车间隔的过程包括:基于每个智能体获取观察值,基于所述观察值对第一传入网络和第二传入网络进行训练,进而获得对应的第一发车间隔和第二发车间隔;若所述第一发车间隔和第二发车间隔的差值小于间隔阈值,则最终发车间隔为所述第一发车间隔和第二发车间隔的平均值,若所述发车间隔的差值大于间隔阈值,则最终发车间隔为间隔阈值,并继续对第一传入网络和第二传入网络进行训练;
10、所述观察值包括:路上行驶的公交车数量、当前的时间、计划发车间隔、每辆车在上一个路段的行驶时间、每辆车在上一个路段的路程、每辆车上的乘客数。
11、可选地,基于多智能体强化学习算法获得最终发车间隔的过程还包括:基于所述多智能体强化学习算法构建双目标函数,基于所述双目标函数获取车辆运营成本和乘客等待成本,并对所述车辆运营成本和乘客等待成本进行单目标优化。
12、可选地,基于多智能体强化学习算法获得最终发车间隔的过程还包括:基于所述双目标函数构建奖励函数,基于所述奖励函数获取所述第一传入网络和第二传入网络的奖励。
13、可选地,对第一传入网络进行训练,获得第一发车间隔的过程包括:以公交运营期间的每一次发车时间为决策点,基于所述第一传入网络与环境进行交互,获得均值和方差,基于所述均值和方差获得正态分布,并对所述正态分布进行采样;基于所述均值、方差、采样值、观察值和与环境进行交互获得的奖励,更新所述第一传入网络的网络参数,获得训练后的第一传入网络;基于所述训练后的第一传入网络、每个决策点的乘客实时需求以及交通状况,获取对应的第一发车间隔。
14、可选地,对第二传入网络进行训练,获得第二发车间隔的过程包括:基于所述第二传入网络与环境进行交互,获得环境观测值,基于所述环境观测值所做的决策为发车与不发车,根据当前的交互动作获得奖励;当所述奖励达到最大值时,获得最终的环境观测值;基于所述最终的环境观测值及对应的当前交互动作、对应的奖励和前一个环境观测值,更新所述第二传入网络的网络参数,获得训练后的第二传入网络;基于所述训练后的传入网络,获得对应的第二发车间隔。
15、可选地,所述环境观测值包括:当前时刻线路上正在运行的车辆数、当前时刻、计划发车间隔、上一个站到当前站的运行时间、上一个站到当前站的距离和上一个站到当前站期间车上的乘客数量。
16、本发明的技术效果为:
17、本发明实现了一种基于多智能体强化学习的公交智能调度方法,该方法可以实时对当前交通情况进行判断并给出最优的公交车调度策略,一方面能够满足乘客较少的等待时间,另一方面考虑公交公司的成本,进一步提升公交车运营效率,以及乘客的满意度,在智能公交领域具有较高的推广价值,为管理者提供高效智能的管理手段。
技术特征:
1.一种基于多智能体强化学习的公交智能调度方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于多智能体强化学习的公交智能调度方法,其特征在于,
3.根据权利要求1所述的基于多智能体强化学习的公交智能调度方法,其特征在于,
4.根据权利要求1所述的基于多智能体强化学习的公交智能调度方法,其特征在于,
5.根据权利要求4所述的基于多智能体强化学习的公交智能调度方法,其特征在于,
6.根据权利要求5所述的基于多智能体强化学习的公交智能调度方法,其特征在于,
7.根据权利要求6所述的基于多智能体强化学习的公交智能调度方法,其特征在于,
8.根据权利要求5所述的基于多智能体强化学习的公交智能调度方法,其特征在于,
9.根据权利要求5所述的基于多智能体强化学习的公交智能调度方法,其特征在于,
10.根据权利要求9所述的基于多智能体强化学习的公交智能调度方法,其特征在于,
技术总结
本发明公开了一种基于多智能体强化学习的公交智能调度方法,包括以下步骤:基于客流数据、站点信息数据、到离站数据和车辆发车数据构建等待时间模型和插值模型;基于所述等待时间模型,获得每个乘客的等待时间,基于所述插值模型,获得站点之间不同时间段的速度;基于多智能体强化学习算法对所述每个乘客的等待时间和站点之间不同时间段的速度、计划发车间隔进行训练,获得最终发车间隔,进而获得每条线路每辆车的发车时间,实现公交车辆调度。本发明一方面能够满足乘客较少的等待时间,另一方面考虑公交公司的成本,进一步提升公交车运营效率,以及乘客的满意度,在智能公交领域具有较高的推广价值,为管理者提供高效智能的管理手段。
技术研发人员:李俊俊,董皓,赵学东,陶黎明,梁超,张迎
受保护的技术使用者:航天物联网技术有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!