基于多模态Transformer的虚假新闻检测方法
本发明涉及虚假新闻检测,具体为基于多模态transformer的虚假新闻检测方法。
背景技术:
1、近年来社交媒体已成为重要的新闻信息来源,人们逐渐习惯在社交媒体上获取最新的新闻并自由地发表自己的观点。然而,社交媒体的便利性和开放性也为虚假新闻的传播提供了极大的便利,造成了很多消极的社会影响。因此,能否利用技术手段对虚假新闻进行自动检测已经成为自媒体时代亟待解决的问题。文本作为新闻事件的主要描述载体,是传统虚假新闻检测方法的关注重点。最近,假新闻从传统的基于文本的新闻形式逐步向基于多模态内容的新闻形式演变。因此,基于多模态内容的检测方法,即多模态虚假新闻检测,成为当前的研究热点。
2、现有的多模态虚假新闻检测方法大多使用预训练的深度卷积神经网络来提取图像特征,如vgg16、vgg19、resnet。在实际训练过程中,充当图像特征提取器的预训练模型的参数会保持冻结,使得预训练模型并不完美,这会限制整个多模态模型的性能,为了减少特征提取时间,图像特征通常会被预先存储起来,往往会使得这些模型的缺点被忽略,由于不同模态数据之间可以相互补充,因此处理好跨模态特征融合是多模态模型成功的关键。现有多模态虚假新闻检测方法使用的特征融合方式大多十分简单,例如有些仅将图像特征和文本特征拼接在一起送入分类器中,没有充分考虑模态间的互补关系。
3、为此,提出基于多模态transformer的虚假新闻检测方法。
技术实现思路
1、本发明的目的在于提供基于多模态transformer的虚假新闻检测方法,以解决上述背景技术中提出的问题。
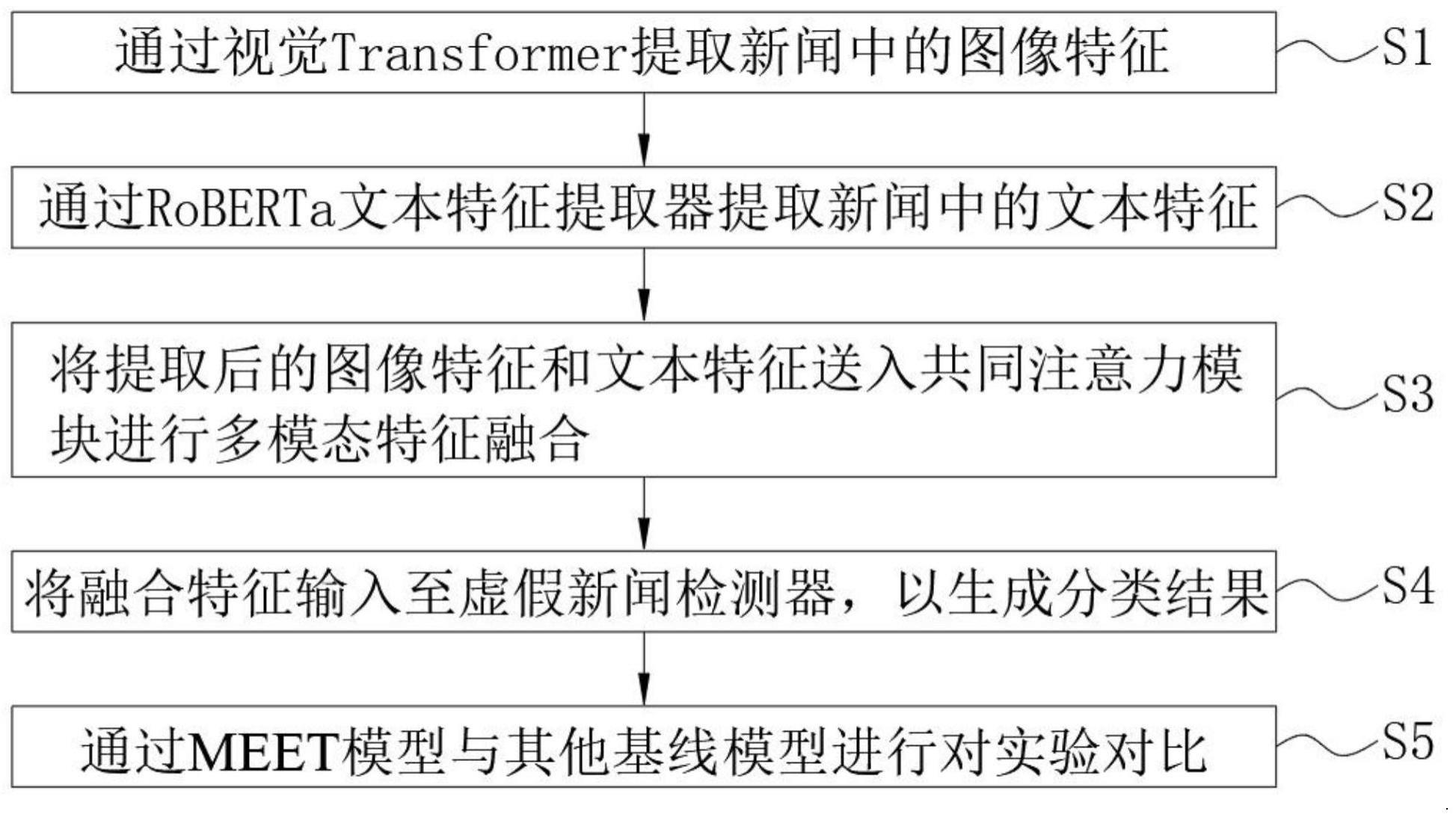
2、为实现上述目的,本发明提供如下技术方案:基于多模态transformer的虚假新闻检测方法,具体包括以下步骤:
3、步骤一:通过视觉transformer图像特征提取器提取新闻中的图像特征;
4、步骤二:通过roberta文本特征提取器提取新闻中的文本特征;
5、步骤三:将提取后的图像特征和文本特征送入共同注意力模块进行多模态特征融合;
6、步骤四:将融合特征输入至虚假新闻检测器,以生成预测新闻是真假新闻的概率;
7、步骤五:通过meet与其他基线模型进行对实验对比。
8、优选的,所述步骤一中视觉transformer图像特征提取器采用的是基于对比语言图像预训练(contrastive language-image pre-training,clip)的视觉transformer模型,简称clipvit,所述视觉transformer图像特征提取器在提取新闻中的图像特征时,要对新闻的图像进行序列化预处理。
9、优选的,所述序列化预处理包括使用卷积层将图像切分为n*n个patch,之后将所有patch展平成长度为n*n总和的序列,在序列前拼接分类标记嵌入再加上位置嵌入就得到了完整的图像嵌入矩阵,对于给定图像嵌入r,通过clipvit提取到的图像特征的导出公式如下:
10、v={vclass,v1,…,vn}=clipvit(r)
11、其中vclass表示分类标记的特征,dr表示图像嵌入维数。
12、优选的,所述步骤二中roberta文本特征提取器用transformer编码器作为网络主体,roberta文本特征提取器包括使用更大的文本嵌入词汇表、预训练任务中去除预测下一个句子和使用动态掩码策略。
13、优选的,所述步骤三中共同注意力模块是由两个交叉注意力网络构成,每个所述交叉注意力网络都是一个n层的transformer结构,与一般的transformer相比每层多了一个交叉注意力块,所述步骤三中多模态特征融合通过共同注意力模块的交叉注意力机制,得到更新后的图像特征和文本特征,并将图像分类特征与文本分类特征进行拼接。
14、优选的,所述步骤四中融合特征输入至虚假新闻检测器是指虚假新闻检测器以多模态融合特征作为输入,利用两层全连接层来预测新闻是真假新闻的概率,其计算公式如下:
15、h=σ1(w1c+b1)
16、p=σ2(w2h+b2)
17、式中σ1表示gelu激活函数,σ2表示softmax激活函数,h表示第一层全连接层的输出,p表示最终输出的分类预测概率,b1和b2均表示全连接层中的偏置系数,w1和w2均表示全连接层中的权重系数,c表示多模态融合特征。
18、优选的,所述meet是基于端到端训练的多模态transformer模型的英文缩写,所述其他基线模型包括单模态模型和多模态模型,所述单模态模型包括textual模型和visual模型,所述多模态模型包括eann模型、mvae模型、spotfake模型和hmcan模型。
19、为了解决上述问题,本发明还提供了一种基于多模态transformer的虚假新闻检测系统,包括:
20、提取模块,其被配置为提取待检测新闻的文本特征和图像特征,其中文本特征的提取采用roberta文本特征提取器,图像特征的提取采用视觉transformer图像特征提取器;
21、融合模块,其被配置为将提取后的图像特征和文本特征送入共同注意力模块进行多模态特征融合,得到多模态融合特征;
22、检测模块,其被配置为将多模态融合特征输入至虚假新闻检测器,利用两层全连接层来预测新闻是真假新闻的概率。
23、为了解决上述问题,本发明还提供了一种计算机可读存储介质,其上存储有程序,所述计算机程序被处理器执行时实现上述所述的基于多模态transformer的虚假新闻检测方法。
24、为了解决上述问题,本发明还提供了一种电子设备,包括处理器、与处理器通信连接的存储器及存储在存储器上并可在处理器上运行的程序,所述处理器执行所述程序时实现上述所述的基于多模态transformer的虚假新闻检测方法。
25、与现有技术相比,本发明的有益效果是:
26、1、本发明中提出了meet模型,使用视觉transfomer作为图像特征提取器,以相同的方式处理不同模态的输入,同时采用端到端的方式对模型进行了训练,通过使用视觉transformer图像特征提取器提取图像特征,将对图像输入的处理简化为与处理文本输入一致的无卷积方式,统一了不同模态的特征提取过程。
27、2、本发明中,首次在虚假新闻检测任务中使用共同注意力模块,共同注意力模块由两个交叉注意力网络构成,每个交叉注意力网络都是一个n层的transformer结构,与一般transformer相比每层多了一个交叉注意力块,通过在两个网络对应层的交叉注意力块之间交换键矩阵k和值矩阵v,使得图像对应的文本特征能够被纳入网络输出的图像表示中,同样文本对应的图像特征也会被纳入网络输出的文本表示中,并通过消融实验证明了共同注意力模块在虚假新闻检测中的有效性。
28、3、本发明中,本实施例第一次在虚假新闻检测任务中引入端到端预训练,并在twitter数据集上与没有经过预训练的meet模型进行了对比分析,实验结果验证了端到端预训练方法的优越性,meet模型可以通过图像输入补充信息,有助于提升模型检测性能。
- 还没有人留言评论。精彩留言会获得点赞!