基于Spark的离线数据处理系统、运行方法、设备及介质与流程
本发明涉及基于spark的离线数据处理,尤其涉及一种基于spark的离线数据处理系统、运行方法、设备及介质。
背景技术:
1、当前海量数据处理分析工具中,以apache flink和apache spark为代表的流、批混合计算引擎(平台)拥有较大的流行度。flink的批处理模型在很大程度上仅是对流处理模型的扩展,而spark为流处理系统采用批处理的方法,需要对进入系统的数据进行缓冲,等待缓冲区清空会导致延迟增高,不适合处理对延迟有较高要求的工作负载。因此,spark引擎(平台)更适合离线批处理需求下的数据处理任务。然而基于spark的数据处理分析应用在开发、测试、使用过程中,仍面临使用门槛普遍较高问题,例如使用者需要具备专业的数据处理知识、学习掌握工具的处理方法、要求具备一定的编码能力等。
技术实现思路
1、本发明实施例的目的是提供一种基于spark的离线数据处理系统、运行方法、设备及介质,通过对离线数据的计算处理可配置化,方便用户以较小的学习成本完成海量数据的处理分析,降低了海量数据处理操作的门槛。
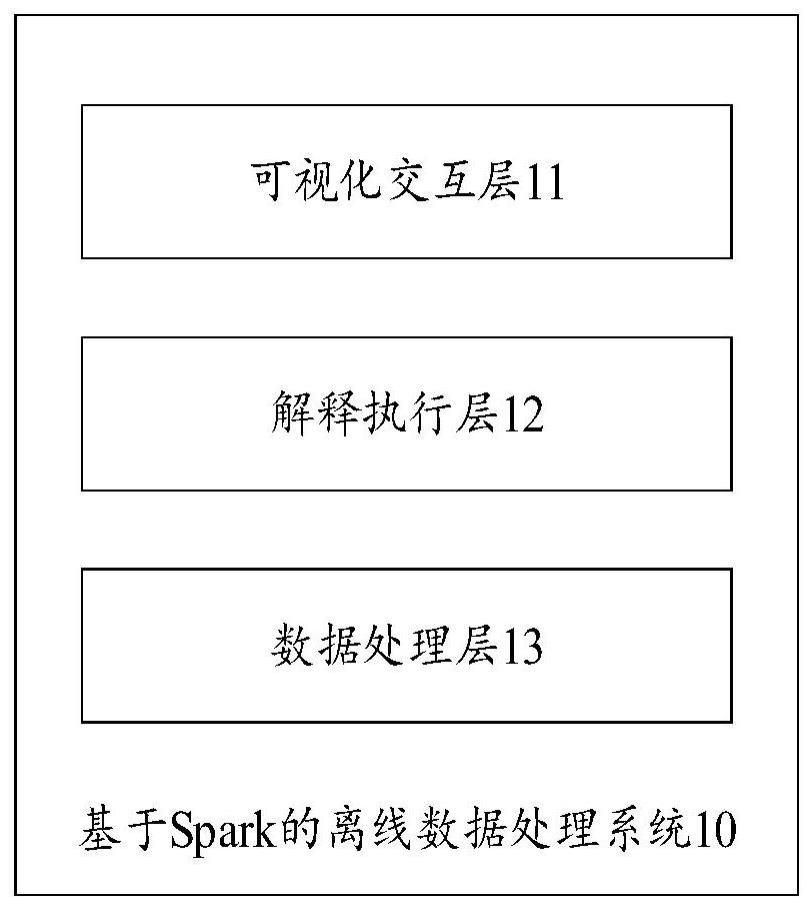
2、为实现上述目的,本发明实施例提供了一种基于spark的离线数据处理系统,包括:
3、可视化交互层,用于提供离线数据的任务节点配置界面和工作流配置界面,并将配置好的工作流发送至解释执行层;其中,所述工作流包括若干配置好的任务节点;
4、所述解释执行层,用于接收所述可视化交互层发送来的所述工作流,按照预设的调度执行策略,读取所述工作流中的任务节点并将经解释器处理后的所述任务节点发送至数据处理层;
5、所述数据处理层,用于接收经所述解释器处理过的任务节点,将spark作为计算引擎,运行所述任务节点,得到运行结果;
6、所述可视化交互层,用于提供结果显示界面,将接收到的所述运行结果展示在所述结果显示界面上。
7、作为上述方案的改进,所述任务节点配置界面包括:任务节点名称输入子界面、数据源字段输入子界面、计算程序类型选择子界面、spark应用名称输入子界面、spark运行参数输入子界面、输出返回值确定子界面和任务节点配置保存确定子界面。
8、作为上述方案的改进,所述工作流配置界面包括:工作流名称输入子界面、任务节点放置子界面、工作流调度执行策略选择界面、工作流数据共享确认界面和工作流配置保存子界面。
9、作为上述方案的改进,响应于用户的工作流数据共享确认指令,所述解释执行层还用于:
10、实例化任意一个org.apache.spark.repl.sparkiloop类的对象sparkiloop;
11、通过所述对象sparkiloop,调用getaddedjars()方法,加载org.apache.spark.repl.main所依赖的外部jar包环境,获取所述外部jar包环境的路径;
12、通过所述对象sparkiloop,实例化解释器类imain的对象intp;
13、由所述解释器类imain的对象intp,通过java的反射机制,获取repl class uri地址的属性值;
14、将预设的外部环境配置参数、所述属性值和所述路径传递到sparkconf中;
15、由repl包通过sparkconf生成一个新的sparkcontext对象;
16、将需要执行的任务节点交给所述解释器类imain的对象intp,并将得到的经所述解释器类imain的对象intp处理过的任务节点发送至所述数据处理层。
17、作为上述方案的改进,所述解释执行层还用于:
18、对所述任务节点和所述工作流进行校验,当校验到所述任务节点存在于节点库中,且所述工作流是合法的dag时,开始读取所述工作流中的任务节点。
19、为实现上述目的,本发明实施例提供了一种基于spark的离线数据处理系统的运行方法,应用上述的基于spark的离线数据处理系统,所述运行方法包括:
20、调用可视化交互层,提供离线数据的任务节点配置界面和工作流配置界面,并将配置好的工作流发送至解释执行层;其中,所述工作流包括若干配置好的任务节点;
21、调用所述解释执行层,接收所述可视化交互层发送来的所述工作流,按照预设的调度执行策略,读取所述工作流中的任务节点并将经解释器处理后的所述任务节点发送至数据处理层;
22、调用数据处理层,接收经所述解释器处理过的任务节点,将spark作为计算引擎,运行所述任务节点,得到运行结果;
23、调用可视化交互层,提供结果显示界面,将接收到的所述运行结果展示在所述结果显示界面上。
24、作为上述方案的改进,所述任务节点配置界面包括:任务节点名称输入子界面、数据源字段输入子界面、计算程序类型选择子界面、spark应用名称输入子界面、spark运行参数输入子界面、输出返回值确定子界面和任务节点配置保存确定子界面。
25、作为上述方案的改进,所述工作流配置界面包括:工作流名称输入子界面、任务节点放置子界面、工作流调度执行策略选择界面、工作流数据共享确认界面和工作流配置保存子界面。
26、为实现上述目的,本发明实施例提供了一种基于spark的离线数据处理系统的运行设备,包括:
27、存储器,用于存储可执行指令;
28、处理器,用于执行所述存储器中存储的可执行指令时,实现如上述的基于spark的离线数据处理方法。
29、为实现上述目的,本发明实施例提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序;其中,所述计算机程序在运行时控制所述计算机可读存储介质所在的设备执行如上述的基于spark的离线数据处理方法。
30、与现有技术相比,本发明实施例提供的一种基于spark的离线数据处理系统、运行方法、设备及介质,通过设置可视化交互层,实现对离线数据的任务节点配置和工作流配置,方便用户以较小的学习成本完成海量数据的处理分析,降低了海量数据处理操作的门槛,并且将运行结果进行展示,方便用户直观了解。
技术特征:
1.一种基于spark的离线数据处理系统,其特征在于,包括:
2.如权利要求1所述的基于spark的离线数据处理系统,其特征在于,所述任务节点配置界面包括:任务节点名称输入子界面、数据源字段输入子界面、计算程序类型选择子界面、spark应用名称输入子界面、spark运行参数输入子界面、输出返回值确定子界面和任务节点配置保存确定子界面。
3.如权利要求1所述的基于spark的离线数据处理系统,其特征在于,所述工作流配置界面包括:工作流名称输入子界面、任务节点放置子界面、工作流调度执行策略选择界面、工作流数据共享确认界面和工作流配置保存子界面。
4.如权利要求3所述的基于spark的离线数据处理系统,其特征在于,响应于用户的工作流数据共享确认指令,所述解释执行层还用于:
5.如权利要求1所述的基于spark的离线数据处理系统,其特征在于,所述解释执行层还用于:
6.一种基于spark的离线数据处理系统的运行方法,其特征在于,应用于如权利要求1所述的基于spark的离线数据处理系统,所述运行方法包括:
7.如权利要求6所述的基于spark的离线数据处理系统的运行方法,其特征在于,所述任务节点配置界面包括:任务节点名称输入子界面、数据源字段输入子界面、计算程序类型选择子界面、spark应用名称输入子界面、spark运行参数输入子界面、输出返回值确定子界面和任务节点配置保存确定子界面。
8.如权利要求6所述的基于spark的离线数据处理系统的运行方法,其特征在于,所述工作流配置界面包括:工作流名称输入子界面、任务节点放置子界面、工作流调度执行策略选择界面、工作流数据共享确认界面和工作流配置保存子界面。
9.一种基于spark的离线数据处理系统的运行设备,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质包括存储的计算机程序;其中,所述计算机程序在运行时控制所述计算机可读存储介质所在的设备执行如权利要求6-8任一项所述的基于spark的离线数据处理方法。
技术总结
本发明公开了一种基于Spark的离线数据处理系统、运行方法、设备及介质,包括:可视化交互层,用于提供离线数据的任务节点配置界面和工作流配置界面,并将配置好的工作流发送至解释执行层;解释执行层,用于接收可视化交互层发送来的工作流,按照预设的调度执行策略,读取工作流中的任务节点并将经解释器处理后的任务节点发送至数据处理层;数据处理层,用于接收经解释器处理过的任务节点,将Spark作为计算引擎,运行任务节点,得到运行结果;可视化交互层,用于提供结果显示界面,将接收到的运行结果展示在结果显示界面上。采用本发明实施例能够方便用户以较小的学习成本完成海量数据的处理分析,降低了海量数据处理操作的门槛。
技术研发人员:羊少帅,张铁山,刘韧,廖海波
受保护的技术使用者:中电科普天科技股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!