一种融合项目属性信息的序列推荐方法
本发明涉及数据挖掘的序列推荐领域,具体是一种融合项目属性信息的序列推荐方法。
背景技术:
1、推荐系统在帮助用户从海量数据中过滤出有价值的信息方面,发挥了重要作用。一个成功的推荐系统的关键在于用户兴趣的准确建模。早期的推荐系统根据用户的全部历史行为来提取用户的兴趣。然而,用户在特定时刻的兴趣受之前多个时刻兴趣的影响,并且是动态变化的。基于这个事实,一部分推荐算法将用户的历史行为作为序列来进行建模,被称为序列推荐。序列推荐的目的是根据用户最近一段时期的历史行为预测下一个该用户感兴趣的项目。其模型的输入为项目的id序列,输出兴趣向量。
2、一些研究工作在项目id序列的基础上,融合项目的其它属性信息构建增强序列模型,使得模型推荐效果有显著改进。已有研究中,融合属性信息的方式主要是在嵌入层和注意力层之间使用多层感知机。由于属性的数据结构和元素数量各不相同,具有异构性。id嵌入表达项目整体信息,属性嵌入代表项目局部信息,两者之间存在混合相关性。这类融合属性信息的方式,会导致注意力矩阵的秩瓶颈,限制注意力矩阵的表达能力,而且融合后的嵌入向量在注意力层中不可分割,必然导致模型的开发和训练更加复杂。具体而言,p-rnn这样的早期工作通常使用简单的连接来将辅助信息直接注入到项目表示中,导致嵌入维度成倍扩张。fdsa分别在项目序列和属性序列上应用自注意力,在预测层融合两个特征向量。icai-sr在注意力层之前将属性信息融合到项目表示中。fdsa和icai-sr这两种模型均使用多层感知机融合异构的属性信息,存在着表示能力有限、梯度不灵活和开发和训练复杂等缺陷。
技术实现思路
1、本发明的目的是针对现有技术中存在的不足,而提出一种融合项目属性信息的序列推荐方法。这种方法能降低模型噪声影响,消除异构属性信息之间的混合相关性,提高了模型性能。
2、实现本发明目的的技术方案是:
3、一种融合项目属性信息的序列推荐方法,包括如下步骤:
4、1)数据预处理和项目属性嵌入:
5、给定用户与系统的历史交互,序列推荐任务要求预测下一个交互的项目,若u表示用户,u的历史交互vu用公式(1)中的括号表示的顺序元组为:
6、
7、其中vju表示用户u进行的第j次交互,也称为行为,每个交互的项目都简单地用项目id和项目属性表示,如公式(2):
8、vju=(idk,atk) (2),
9、其中idk∈ι,代表项目词汇表中第k个项目的id,ι={id1,id2,…,idm}是系统中要考虑的所有项目id的标识集,m是问题域中的项目的总数,代表项目词汇表第k个项目的属性集,j={attr1,attr2,…,attrr}是系统中所有项目属性的词汇表,r是问题域中的项目属性总数;
10、原始训练序列的长度是不确定的,需要转换为固定长度的序列s=(s1,s2,…,sn),n为模型能处理的最大长度,若序列长度大于n,取最近的n个项目,若序列长度小于n,则在序列左侧使用零填充,直到序列长度为n;因此n也是转换后所有定长序列的长度;
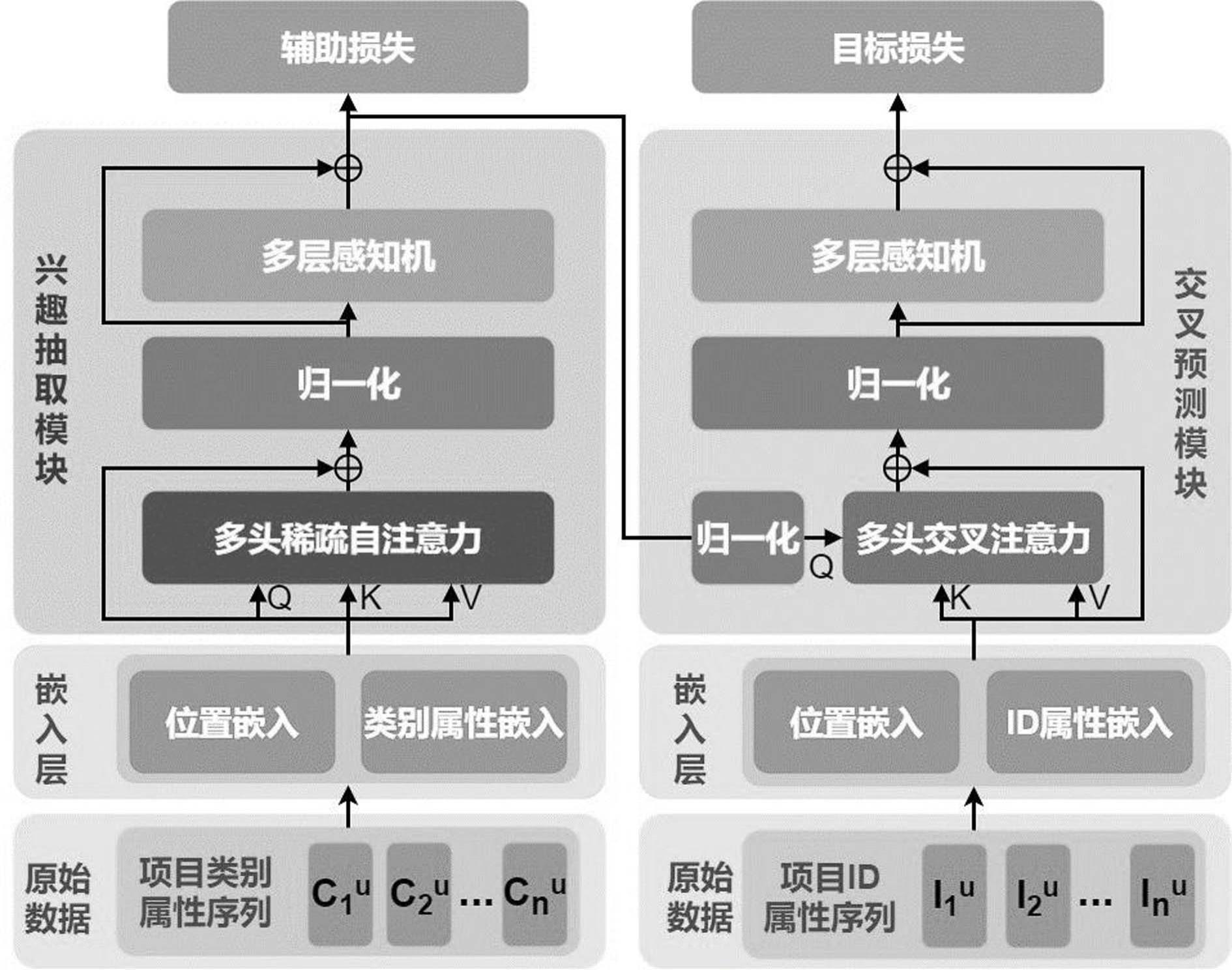
11、在将不定长序列转换为固定长度的序列后,将原始序列转换为嵌入序列,嵌入指嵌入向量,它是项目属性在推荐算法中的向量表示,嵌入层将不同类型的项目属性分开建模,将序列转化为项目的类别属性嵌入向量和id嵌入向量,分别用于兴趣抽取模块和交叉预测模块;(1)id属性嵌入:
12、创建id属性嵌入矩阵mid∈rm×d,m为项目的总数,d为嵌入向量的维度,根据序列s中项目的id,查找mid中对应的嵌入向量,将s转换为嵌入序列eid∈rn×d,零填充项的id属性嵌入为常数零向量;
13、(2)类别属性嵌入:
14、创建类别属性嵌入矩阵mcate∈rr×d,r为类别元素的总数,d为嵌入向量的维度,由于项目的类别属性是类别元素的集合,是一对多的关系,不能像id属性嵌入一样直接查找,需先将s中第i个项目的类别属性进行muti-hot编码,表示为向量ei的j位置值为1,则si拥有编号为j的类别元素,序列的类别属性嵌入表示为公式(3),零填充项的类别属性嵌入也为常数零向量:
15、
16、(3)位置嵌入:
17、原始的注意力机制不包含序列的位置信息,无法识别序列中项目的先后顺序,通过添加位置编码可拟补这一不足,位置编码使用可学习的嵌入矩阵p∈rn×d,位置嵌入和id属性嵌入及位置嵌入和类别属性嵌入的融合操作均为向量对应位置相加,如公式(4):
18、
19、添加位置嵌入后的类别嵌入表示为id属性嵌入表示为id属性嵌入和类别属性嵌入使用的位置嵌入矩阵不共享;
20、2)抽取兴趣类别:
21、兴趣抽取模块的主要结构是多头稀疏自注意力块,多头稀疏自注意力方法,是对多头自注意力方法的扩展,多头自注意力层(msa)和多层感知机(mlp)两者串联在一起构成一个多头注意力块;
22、兴趣抽取模块从输入的类别嵌入中抽取用户的类别兴趣ocate∈rd,
23、输入使用公式(5)获得查询向量q、键向量k、值向量v:
24、f(·)(x)=xw(·) (5),
25、其中是可学习的投影矩阵,i代表第i个自注意力头,n代表定长序列的长度,d为嵌入向量的维度,h为自注意力头的总数,在通过公式(6)获得注意力分数矩阵a:
26、
27、显式选择是在a上做稀疏化操作,如公式(7)所示,aij为序列中项目i与项目j的注意力分数,ti为关于项目i的第k个最大注意力分数,k是超参数:
28、
29、然后对做归一化,如公式(8):
30、
31、为标准化分数,由于掩蔽函数将小于top-k的分数赋值为负无穷,其归一化分数即概率近似为0;
32、第i个头的值的聚合操作如公式(9)所示:
33、ci=aivi (9),
34、多头自注意力将每个头的输出串联在一起,并进行线性投影得到输出,如公式(10),wo是可学习的投影矩阵:
35、msa(x)=concat(c1,...,ch)wo (10)),
36、多层感知机在多头自注意力层之间,fc(·)为全连接层,w∈rd×d,b∈rd是可学习的投影矩阵和偏置,σ(·)为激活函数,如公式(11)所示:
37、mlp(x)=fc(σ(fc(x))),fc(x)=xw+b (11),
38、多头自注意力和多层感知机上都使用residual connections方法防止训练时梯度消失问题,使用layer normalization来加速训练,并串联作为一个多头注意力块,h(l)为第l块的输入,g(l)为该块多头注意力层的输出,如公式(12):
39、输入的类别嵌入在经过一个或多个多头稀疏自注意力块以后,输出ocate,代表用户的类别兴趣,用于计算辅助损失函数及交叉预测模块预测兴趣项目;
40、3)推荐项目:
41、交叉预测模块的主要结构是多头交叉注意力块,多头交叉注意力块由交叉注意力块和多层感知机串联而成,自注意力方法使用序列内的信息聚合序列,而交叉注意力方法能够引入额外的信息来聚合序列,交叉预测模块输入类别兴趣ocate和id嵌入使用交叉注意力方法,输出项目兴趣oid∈rd;
42、交叉预测模块查询向量来自兴趣抽取模块的输出ocate,而键向量和值向量则来自id嵌入序列
43、如公式(13):
44、
45、线性变换f(·)(x)见公式(5),其投影矩阵与稀疏自注意力模块的投影矩阵不共享;
46、注意力矩阵计算过程如公式(6),多头聚合操作和多层感知机与多头注意力块一致,见公式(9)、(10)、(11)、(12),oid与项目id嵌入向量的内积用于衡量用户对该项目的兴趣,内积越大,用户对该项目有兴趣的概率越大;
47、4)训练过程:
48、技术方案采用二元交叉熵损失函数进行模型优化,定义n为训练序列的数量,t为序列中的时刻,e[t+1]∈iu作为正例,表示用户在t+1时刻交互的项目,作为负例,表示随机抽取的用户在t+1时刻没有交互过的项目,iu是用户u交互过的项目的集合,i是全部项目的集合,o[t]表示模型输出的t时刻的兴趣,lg是对数函数,σ是sigmoid函数,·为内积运算;
49、损失函数定义为公式(14),系统中所有序列的全部时刻模型输出的兴趣与正例和负例的二元交叉熵损失的和为:
50、
51、为使兴趣抽取模块学到有意义的兴趣表示,模型使用辅助损失函数,将兴趣抽取模块输出的ocate、作为正例的类别嵌入序列ecate和作为负例的随机抽取的类别嵌入序列作为辅助损失函数的输入,同样的,目标损失函数将交叉预测模块输出的oid、作为正例的id嵌入序列eid和作为负例的随机抽取的类别嵌入序列作为输出,如公式(15):
52、
53、最终模型的损失函数为目标项目损失ltarget与辅助损失laux相结合,β是超参数,用于平衡目标损失和辅助损失,如公式(1,6):
54、l=ltarget+β*laux (16)。
55、本技术方案与现有方法相比,能产生如下有益效果:
56、序列中不可避免的包含噪声信息,如用户的随机交互。同时,序列中可能包含多个兴趣中心。如果不对这两个问题进行处理,必定会限制模型性能。本技术方案采用了基于top-k选择的显式选择自注意力稀疏化方法。这种方法只关注k个注意力分数最大的项目,能实现降低噪声项目的影响和集中注意力的功能,使本技术方案的模型性能较同类型模型有显著提升。
57、以往使用多层感知机融合异构的属性信息的方法,存在着表示能力有限、梯度不灵活和开发和训练复杂等问题。本技术方案采用的使用交叉注意力融合属性信息的方法。交叉注意力方法通常作为decoder,与自注意力方法作为encoder共同使用。对于本技术方案的模型,兴趣抽取模块就是encoder,交叉预测模块是decoder。交叉注意力方法对项目嵌入向量无入侵,也避免异构属性信息之间的混合相关性。
58、这种方法降低了模型噪声影响,消除异构属性信息之间的混合相关性,提高了模型性能。
- 还没有人留言评论。精彩留言会获得点赞!