一种基于改进YOLOv5模型的炮孔识别方法
一种基于改进yolov5模型的炮孔识别方法
技术领域
1.本发明涉及一种基于改进yolov5模型的炮孔识别方法,属于计算机视觉领域。
背景技术:
2.目前井下巷道掘进过程仍然处于自动化程度低、智能化水平差的状态,同时井下恶劣的环境同样威胁着工作人员的健康情况和生命安全。现阶段井下掘进过程中工作面的钻孔、装药和封堵等过程基本都需要人工完成。在工作面钻孔后,需要对打孔信息进行核对,因为准确而科学的炮孔布局对巷道爆破掘进的速度和效果至关重要。对打孔后的工作面炮孔布局进行人工统计测算是既费时又费力的工作,工作人员长时间在巷道内的支架上工作对身体也是一种伤害,同时也存在很大的安全隐患。
3.随着深度学习技术的不断发展,其技术被广泛应用到各个领域。目前计算机视觉领域的目标检测技术有多种,例如:faster-rcnn、ssd和yolo系列等。其中yolov5在目标检测的速度和精度上都有不错的表现。本发明结合炮孔识别的特点,对yolov5模型的部分结构进行改进,可以得到更好的炮孔识别结果。
4.因此本发明提供了一种基于改进yolov5模型的炮孔识别方法,主要是对井巷掘进工作面的炮孔进行检测,通过检测工作面炮孔照片自动快速识别图片上炮孔的位置,并根据坐标数据绘制出实际炮孔布局图。工作人员仅仅拍摄工作面的照片就可以得到工作面打孔后的实际炮孔布局图,直接将绘制的炮孔布局图和设计图进行核对,大大提高了工作效率,同时工人也不必费力地上下支架,在很大程度上保证了工作人员的人身安全。
技术实现要素:
5.本发明的目的在于提供一种基于改进yolov5模型的炮孔识别方法,以解决上述背景技术中提及的井巷掘进爆破过程中费时费力的问题。
6.为实现上述目的,本发明提出的一种基于改进yolov5模型的炮孔识别方法,其采用的技术方案如下:
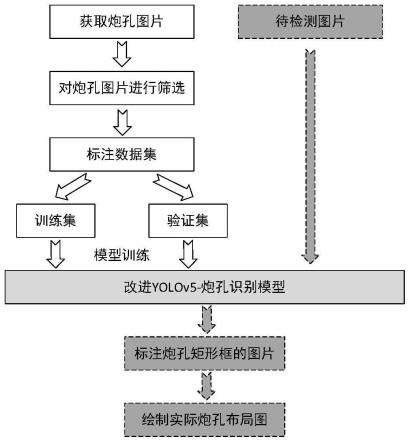
7.步骤一:获取炮孔图片;
8.步骤二:对图片数据进行处理,标注数据集;
9.步骤三:使用改进的yolov5网络架构训练井巷掘进爆破炮孔识别模型;
10.步骤四:待检测图片中炮孔的识别标注;
11.步骤五:获取图片中每个炮孔的中心点位置坐标,绘成炮孔的实际布局图。
12.优选地,步骤一进一步包括:
13.在井下使用防爆照相机获取井巷工作面上不同亮度、不同角度和不同距离的炮孔图片,作为原始的图片数据集,本发明方法使用到的图片数据均来自真实井巷掘进过程中拍摄的照片。
14.优选地,步骤二进一步包括:
15.通过防爆照相机获取的炮孔图片,其中有一些是无法使用的,比如拍摄过程中严
重失真、模糊变形的图片等,需要筛选去除这些图片。通过使用labelimg标注软件,采用软件中的yolo标注模式对炮孔图片进行标注,将标注好的数据作为模型训练时使用的数据集,其中包括训练集和验证集,两者的占比为:训练集占80%,验证集占20%。训练集是对模型的学习,权重参数的训练,验证集用于模型训练过程中超参数的调整和对模型进行评估。
16.优选地,步骤三进一步包括:
17.在yolov5模型的基础上,添加attention机制,使模型更加突出关注图片中含有炮孔的位置,从而提高模型检测炮孔的准确率。调整炮孔检测的损失函数,增强对图片中炮孔的感知能力,通过改进目标框的回归公式,提高对炮孔的检测精度。模型的输入数据为640*640大小的图片,训练次数设置为300,批次大小设置为60,然后通过对训练数据进行训练得到炮孔识别模型。
18.attention机制在众多的领域中被证实可以提高cnn模型的特征提取能力,可以对提取的特征进行校正,关注提取的特征中最具有价值的部分。其基本步骤为:将模型的输入x通过attention网络层计算出其对应的权重,然后把计算出的输入x对应的权重与特征图相乘,得到attention机制调整后更优的特征信息,调整后的特征图中需要重点关注的区域也更加突出。本发明中引入了cbam注意力模块,通过该模块可以对特征图上不同位置进行不同程度的特征信息提取。该注意力模块同时对通道域和空间域进行特征提取的改进,对于特征图上不同位置的关注程度是不同的。将每一个特征图进行平均池化和最大值池化特征提取,然后对两次池化的特征结果进行拼接,通过使用一个7*7的卷积核对特征图进行卷积操作,获得通道数为1的特征向量,将特征向量通过sigmoid激活函数得到注意力的权重数据,最后将得到的注意力权重矩阵与输入特征图进行乘积得到调整后更优的特征向量。
19.通道域模块的计算公式如下:
[0020][0021]
空间域模块的计算公式如下:
[0022][0023]
其中,mc为cbam通道注意力特征图部分,mlp为多层感知机,w0和w1为mlp的共享权重。ms为cbam空间注意力特征图部分,σ为sigmoid激活函数,f7×7为卷积核为7*7的卷积操作,avgpool(f)为进行平均池化特征提取,maxpool(f)为进行最大值池化特征提取。
[0024]
目标检测任务中损失函数iou用来反映预测框与真实框之间的交并比,选择一个较好的损失函数可以更加准确的反映预测目标与真实目标之间的重合程度。本发明中将原yolov5模型的损失函数进行改进,采用ciou损失函数来进行预测框的回归,该损失函数分别考虑了预测框与真实框之间的重叠面积、中心点的距离以及长宽比等量,通过使用ciou可以使得预测框的位置更加符合真实框,通过实验证明,使用ciou损失函数比其他损失函数在本炮孔检测的实验中其平均准确率有较明显的提升。
[0025]
ciou损失函数公式如下:
[0026][0027]
[0028][0029][0030]
l
ciou
=1-ciou
[0031]
其中,a表示预测框的面积,b表示真实框的面积,α表示为权重系数,v表示长宽比之间的相似性,w和h分别表示预测框的宽度和高度,w
gt
和h
gt
分别表示真实框的宽度和高度。l
ciou
为最终的ciou损失函数。
[0032]
优选地,步骤四进一步包括:
[0033]
通过将待检测的图片输入到训练好的炮孔检测模型中得到图片中的炮孔,如果图片中检测到的炮孔目标经过计算得到的置信度值大于设定的阈值,则确定检测到的为目标炮孔,并将炮孔用矩形框标定出来。
[0034]
优选地,步骤五进一步包括:
[0035]
通过图片中炮孔标定的位置,计算得到炮孔矩形框中心点的坐标,并根据获得的炮孔中心点坐标绘制炮孔的实际布局图,此图供工作人员与炮孔设计布局图进行核对。
附图说明
[0036]
下面结合附图和实施例对本发明进一步说明。
[0037]
图1是一种基于改进yolov5模型的炮孔识别方法流程图。
[0038]
图2是cbam注意力模块结构图。
[0039]
图3是待检测图片与模型标注炮孔图片。
[0040]
图4是炮孔实际布局图。
具体实施方式
[0041]
为使本发明的目的、技术方案更加清楚明白,以下通过具体实施例,对本发明进一步详细说明。
[0042]
本发明是在windows 11的开发环境下工作,通过采用深度学习框架pytorch进行搭建而成。输入图片大小为640*640,训练次数epoch为300,批次大小batch_size为60。
[0043]
如图1所示,本说明书的具体实施例提供的一种基于改进yolov5模型的炮孔识别方法包括以下步骤:
[0044]
步骤一:获取炮孔图片;
[0045]
进一步的,在井下使用防爆照相机获取井巷中工作面上不同亮度、不同角度和不同距离的炮孔图片,作为原始的图片数据集,本发明方法使用到的图片数据均来自真实井巷掘进过程中拍摄的照片。
[0046]
步骤二:对图片数据进行处理,标注数据集;
[0047]
进一步的,通过防爆照相机获取的炮孔图片,由于收集的图片中有一些是不能使用的,在进行炮孔图片拍摄过程中严重失真、模糊变形的图片需要筛选去除。通过使用labelimg标注软件,采用软件中的yolo标注模式对炮孔图片进行标注,将标注好的数据作为模型训练时使用的数据集,其中包括训练集和验证集,两者的占比为:训练集占80%,验
证集占20%。训练集是对模型的学习,权重参数的训练,验证集用于模型训练过程中超参数的调整和对模型进行评估。
[0048]
步骤三:使用改进的yolov5网络架构训练井巷掘进爆破炮孔识别模型;
[0049]
进一步的,在yolov5模型的基础上,添加attention机制,使模型更加突出关注图片中含有炮孔的位置,从而提高模型检测炮孔的准确率。调整炮孔检测的损失函数,增强对图片中炮孔的感知能力,通过改进目标框的回归公式,提高对炮孔的检测精度。模型的输入数据为640*640大小的图片,训练次数设置为300,批次大小设置为60,然后通过对训练数据进行训练得到炮孔识别模型。
[0050]
进一步的,attention机制在众多的领域中被证实可以提高cnn模型的特征提取能力,可以对提取的特征进行校正,关注提取的特征中最具有价值的部分。其基本步骤为:将模型的输入x通过attention网络层计算出其对应的权重,然后把计算出的输入x对应的权重与特征图相乘,得到attention机制调整后更优的特征信息,调整后的特征图中需要重点关注的区域也更加突出。本发明中引入了cbam注意力模块,通过该模块可以对特征图上不同位置进行不同程度的特征信息提取。该注意力模块同时对通道域和空间域进行特征提取的改进,对于特征图上不同位置的关注程度是不同的。将每一个特征图进行平均池化和最大值池化特征提取,然后对两次池化的特征结果进行拼接,通过使用一个7*7的卷积核对特征图进行卷积操作,获得通道数为1的特征向量,将特征向量通过sigmoid激活函数得到注意力的权重数据,最后将得到的注意力权重矩阵与输入特征图进行乘积得到调整后更优的特征向量,cbam注意力模块结构图如图2所示。
[0051]
通道域模块的计算公式如下:
[0052][0053]
空间域模块的计算公式如下:
[0054][0055]
其中,mc为cbam通道注意力特征图部分,mlp为多层感知机,w0和w1为mlp的共享权重。ms为cbam空间注意力特征图部分,σ为sigmoid激活函数,f7×7为卷积核为7*7的卷积操作,avgpool(f)为进行平均池化特征提取,maxpool(f)为进行最大值池化特征提取。
[0056]
进一步的,目标检测任务中损失函数iou用来反映预测框与真实框之间的交并比,选择一个较好的损失函数可以更加准确的反映预测目标与真实目标之间的重合程度。本发明中将原yolov5模型的损失函数进行改进,采用ciou损失函数来进行预测框的回归,该损失函数分别考虑了预测框与真实框之间的重叠面积、中心点的距离以及长宽比等量,通过使用ciou可以使得预测框的位置更加符合真实框,通过实验证明,使用ciou损失函数比其他损失函数在本炮孔检测的实验中其平均准确率有较明显的提升。
[0057]
ciou损失函数公式如下:
[0058][0059]
[0060][0061][0062]
l
ciou
=1-ciou
[0063]
其中,a表示预测框的面积,b表示真实框的面积,α表示为权重系数,v表示长宽比之间的相似性,w和h分别表示预测框的宽度和高度,w
gt
和h
gt
分别表示真实框的宽度和高度。l
ciou
为最终的ciou损失函数。
[0064]
步骤四:待检测图片中炮孔的识别标注;
[0065]
进一步的,通过将待检测的图片输入到训练好的炮孔检测模型中得到图片中的炮孔,如果图片中检测到的炮孔目标经过计算得到的置信度值大于设定的阈值,则确定检测到的为目标炮孔,并将炮孔用矩形框标定出来。如图3所示,左侧为待检测的图片,右侧为通过模型检测得到的含有置信度的标注结果。
[0066]
步骤五:获取图片中每个炮孔的中心点位置坐标,绘成炮孔的实际布局图;
[0067]
进一步的,通过图片中炮孔标定的位置,计算得到炮孔矩形框中心点的坐标,并根据获得的炮孔中心点坐标绘制炮孔的实际布局图,如图4所示,为工作面上局部的炮孔实际布局图,供工作人员与炮孔设计布局图进行核对。图中坐标为炮孔中心点坐标,是以图片左上角为坐标原点,第一个数字为距离左侧边缘的像素位数,第二个数字为距离上侧边缘的像素位数。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1