基于视觉Transformer和卷积网络相融合的人脸表情识别方法
本发明属于计算机视觉的图像分类领域,具体涉及一种基于视觉transformer和卷积网络相融合的人脸表情识别方法。
背景技术:
1、伴随着计算机技术的日益发展,越来越多的技术面向并应用于社会,国家正朝着信息化时代的步伐前进,信息化推动着技术的发展。人工智能正是该时代下的产物,人工智能已经开始全面浸透到人们的日常生活当中,通过人工智能带来的各种便利,使得人们能够在某些领域里让计算机代替人类操作,降低人们的时间成本,能够更加高效地处理事务,例如人脸识别技术让社会更加信息化,人们再也不会有随时随地需要带着身份证随行的烦恼。再者现如今最为火热的自动驾驶领域,让人们对驾驶的概念有更深层次的思考,虽然该技术还有许多的不足和需要改进的地方,但该技术的应用代表着计算机视觉从理论层面转入现实生活,正是该技术应用到实际场景,催生出越来越多的计算机视觉技术的现实落地。
2、人脸面部表情在人们日常的生活当中起到主导作用,相比于文字或者动作表达,表情能够更加直接且有效的表达人类的情感,并且大多数的人也是通过人自身表情的变化来传达自己此时此刻的情感,它几乎能够囊括大多数人在不同场景下的情感状态。因此,表情通常是作为判断情感的主要依据。社会上充斥着各种因为情绪导致的惨剧发生,例如人们因为生活和工作压力过大,随之想结束自己的生命一了了之,再者有些人因为忍受不了他人的侮辱,进而对对方造成伤害,造成不可能逆转的伤害。这些事件往往都是可预防的,通过计算人类的情感状态,快速的做出判断,预防危险事件的发生。表情识别主要的目的就是通过一些仅有的信息,在短时间内识别出人脸的表情。表情识别要求的输入可以分为静态图像和图像序列,从这些图片中分离出人类的各种表情。当计算机达到人类对表情理解与判断的时候,就可以将计算机代替人类对表情的判断,进而使得人类和机器达到更好的合作。随着表情识别技术的快速发展,未来能够应用到非常广泛的场景。目前已经有许多领域已经通过表情识别技术应用到现实生活场景当中。人工智能可以通过远程视频监控,实时地捕捉客户地表情变化,通过表情地变化迅速地做出判断是否处于危险状态。学校场景同样应用了表情识别,在线教育平台通过识别学生的表情来分析学生是否有在认真上课,并将计算的结果反馈给正在上课的老师,进而让老师能够更好的管理学生。
技术实现思路
1、本发明主要解决的技术问题在于,针对人脸表情识别模型在训练过程中某个表情类别数量过少,导致最后网络训练完成之后某个表情类别的识别率过低的问题,以及在训练过程当中特征图只包含局部信息而不含全局信息的问题。本发明提供基于的技术方案如下:
2、一种基于视觉transformer和卷积网络相融合的人脸表情识别方法,其包括以下步骤:
3、获取人脸表情图片输入样本和对应的表情类别标签;根据所述人脸表情图片进行人脸检测和人脸对齐;
4、建立视觉transformer和卷积网络相融合的网络模型,将所述的人脸表情图
5、片
6、送入模型中提取人脸表情特征,得到图片的表情特征;
7、计算输入进网络模型当中的各个类别图片在所有图片当中的数量占比;
8、将表情特征送入分类器进行分类,输出分类结果;
9、根据每个表情类别在整个数据集当中所占的比例计算对应的损失值;
10、进一步的,所述人脸表情图片样本和对应的类别标签,具体包括:
11、获取人脸表情图片当中的人脸位置,对人脸表情图片当中的人脸进行人脸检测,以获取到人脸在图片当中的具体位置。
12、将上述所得到的人脸位置放置经过映射,得到人脸对齐后的人脸表情图片。
13、进一步的,所述建立视觉transformer和卷积网络相融合的网络模型,将人脸表情图片输入模型当中进行训练,进而得到图片特征具体包括如下:
14、创建视觉transformer和卷积网络相结合的模块,共创建4个上述的模块,并对模型内部的优化器、学习率、卷积核等参数进行初始化;
15、将表情图片输入到视觉transformer和卷积网络相结合的网络模型当中,根据最后一层视觉transformer所输出的一维特征序列,将一维特征序列作为最后的特征序列;
16、进一步的,所述视觉transformer当中新增自注意力机制,即cbam模块,计算公式如下:
17、
18、
19、其中f是输入的特征图,mc(·)是通道注意函数,是特征图之间对应元素位置相乘,ms(·)是空间注意力函数,f″是cbam模块最后的输出,该输出是结合通道注意力与空间注意力的特征图;
20、通道注意力计算公式如下:
21、mc(f)=σ(mlp(avgpool(f))+mlp(maxpool(f))),
22、其中avgpool(·)是将图片进行平均池化,maxpool(·)是将图片进行最大池化,mlp(·)是对输入的特征图进行全连接操作,σ(·)是sigmoid函数;
23、空间注意力计算公式如下:
24、ms(f)=σ(f([avgpool(f);maxpool(f)])),
25、其中f(·)是对特征图进行卷积操作,[avgpool(·);maxpool(·)]是将最大池化和平均池化输出的特征图进行拼接;
26、进一步的,所述计算输入进网络模型当中的各个类别图片在所有图片当中的数量占比,具体包括如下:
27、每个表情类别在所有图片当中的数量占比会有所不同,该占比会直接影响网络模型训练过程中对某个类别的梯度计算,导致某些表情类别在训练时没有得到相同或者更多的关注,最后导致网络在训练过后对不同的类别具有不同的倾向性。
28、进一步的,所述将表情特征送入分类器进行分类,输出分类结果。其特征在于将最后一层transformer所得到的表情特征输入到softmax函数得到网络对该图片的类别预测置信度,该置信度代表网络对于该图片属于每个表情类别的概率。
29、进一步的,所述根据每个表情类别在整个数据集当中所占的比例计算对应的损失值,具体包括如下:
30、所述表情类别占所有类别比例指的是数量上的占比,解决的是网络训练过程当中占比较少的表情类别图片的梯度影响较小。计算公式如下:
31、
32、其中n是每次网络训练当中表情图片样本数量,m是表情类别数量,pij是网络模型最后一层对第i个样本的第j个表情类别的输出值,wj是第j个表情类别在整个训练集当中所占的比例。该loss值可以有效地帮助网络在训练过程中少量表情类别训练不充分的问题。
技术特征:
1.一种基于视觉transformer和卷积网络相融合的人脸表情识别方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于视觉transformer和卷积网络相融合的人脸表情识别方法,其特征在于,所述人脸表情图片样本和对应的类别标签,具体包括:
3.根据权利要求1所述的一种基于视觉transformer和卷积网络相融合的人脸表情识别方法,其特征在于,所述建立视觉transformer和卷积网络相融合的网络模型,将人脸表情图片输入模型当中进行训练,进而得到图片特征具体包括如下:
4.根据权利要求1所述的一种基于视觉transformer和卷积网络相融合的人脸表
5.根据权利要求1所述的一种基于视觉transformer和卷积网络相融合的人脸表
6.根据权利要求1所述的一种基于视觉transformer和卷积网络相融合的人脸表情识别方法,所述计算输入进网络模型当中的各个类别图片在所有图片当中的数量占比,具体包括如下:
7.根据权利要求3所述的一种基于视觉transformer和卷积网络相融合的人脸表情识别方法,其特征在于将最后一层transformer所得到的表情特征输入到softmax函数得到网络对该图片的类别预测置信度,该置信度代表网络对于该图片属于每个表情类别的概率。
8.根据权利要求1所述的一种基于视觉transformer和卷积网络相融合的人脸表情识别方法,所述根据每个表情类别在整个数据集当中所占的比例计算对应的损失值,具体包括如下:
技术总结
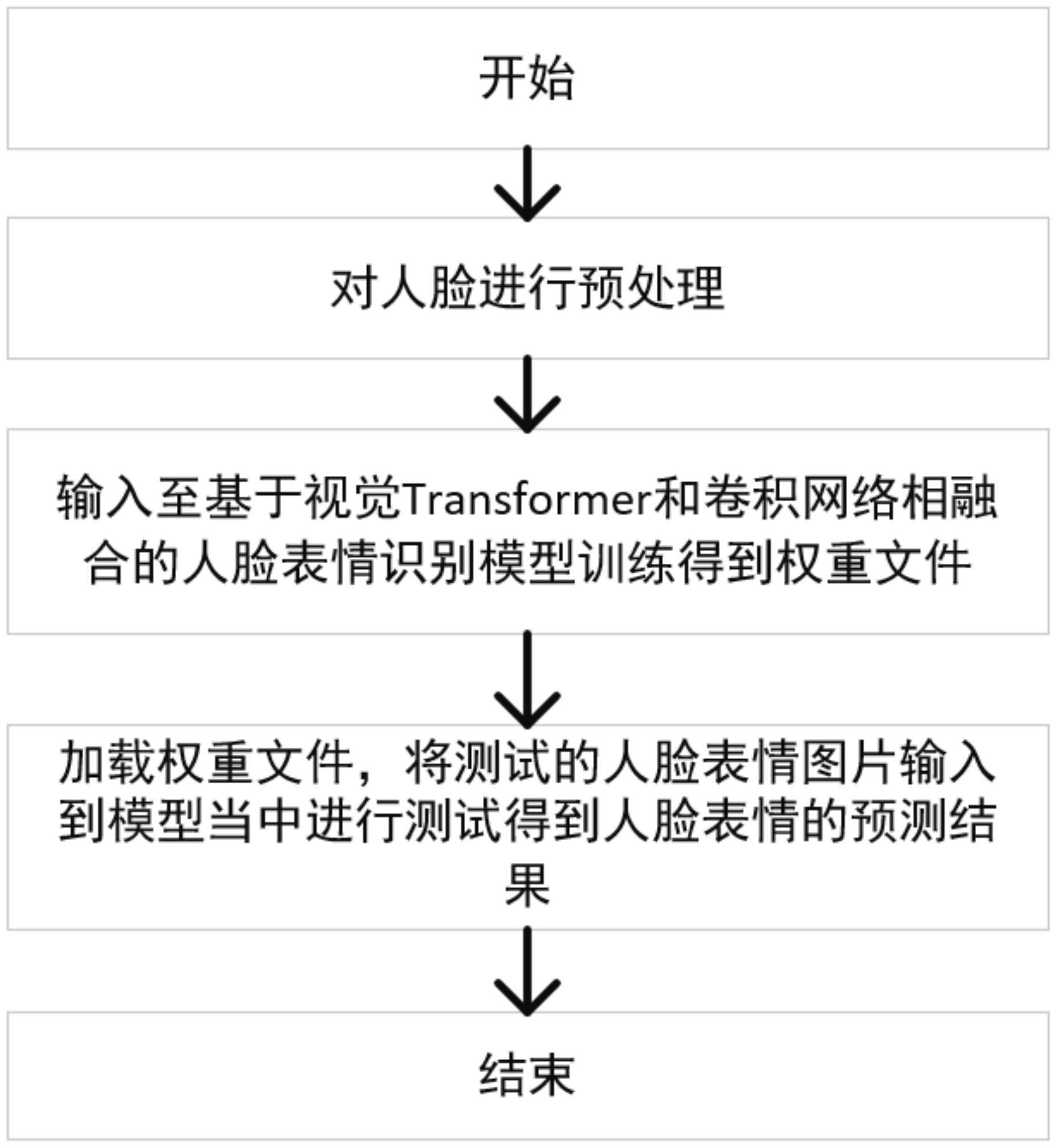
本发明属于计算机视觉的图像分类领域,具体涉及一种基于视觉Transformer和卷积网络相融合的人脸表情识别方法,该方法具有如下特征,包括以下步骤:步骤1,将待训练图像进行预处理获得预处理图像;步骤2,将预处理图像输入到基于视觉Transformer和卷积网络相融合的模型进行训练,进而得到模型的权重文件,该模型包括卷积模块、编码器以及注意力机制,所述卷积层包括对图片特征的位置信息进行关联;所述编码器包多个残差模块,所述残差模块是将编码器的输入与编码器最后输出作为编码器最后的输出结果,编码器当中由多个残差模块组成,并将这些输出作为融合注意力的输入;所述融合注意力机制将池化层中的输出作为注意力机制模块的输入,将输入的特征图使用自适应的注意力机制找出特征中不同的权重响应,最后输入到视觉Transformer当中进行训练;步骤3,加载模型权重文件,将测试的人脸表情图片输入到模型中得出表情预测结果。此外,本发明的人脸表情识别割模型对各个类别之间的特征更好的分离开,提高了表情识别模型预测的精度。
技术研发人员:米建勋,刘毅,邹立志
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!