基于时空自适应融合的端到端人体行为分类方法及系统
本发明涉及计算机识别,具体涉及一种基于时空自适应融合的端到端人体行为分类方法及系统。
背景技术:
1、针对解决复杂行为识别任务,现有方案中,绝大多数采用二维或三维卷积神经网络提取视频特征,再利用深度学习的方法训练网络模型,最终利用训练好的模型得到预测结果。
2、在采用了二维卷积神经网络的方案中,有基于双流模型结构的方案,通过使用卷积神经网络分别处理rgb图片帧数据和光流数据,再将得到的两组特征数据进行融合,进行模型训练或预测;另一种方案是先利用二维卷积神经网络提取每一帧的图片特征,再利用其它不同的聚合模块对这些图片数据进行时间因果建模,例如tsn网络。
3、在采用了三维卷积神经网络的方案中,如,slowfast模型,它跟双流模型结构相似,不同点是利用三维卷积主干特征提取模块对视频帧中的高频数据和低频数据进行特征提取,再进行特征融合,以便区分行为主体和背景,从而提升识别效果;另一种方案,如video transformer,是引入区域建议网络(region proposal network,rpn)先找出特征图中的行为主体,再利用其它方法对这些行为主体特征进行时空维度建模,目的是利用不同行为主体之间和环境背景之间的的联系,从而进一步提升行为识别效果。引入三维卷积网络的目的是为了在提取视频特征时,更好地对数据的时间和空间维度进行联合建模,但这样会增大模型的参数量,并且对于一些以行为主体为中心建模的网络,rpn的加入会使模型计算量和参数进一步增大,以上这些问题会损害模型的高效性。
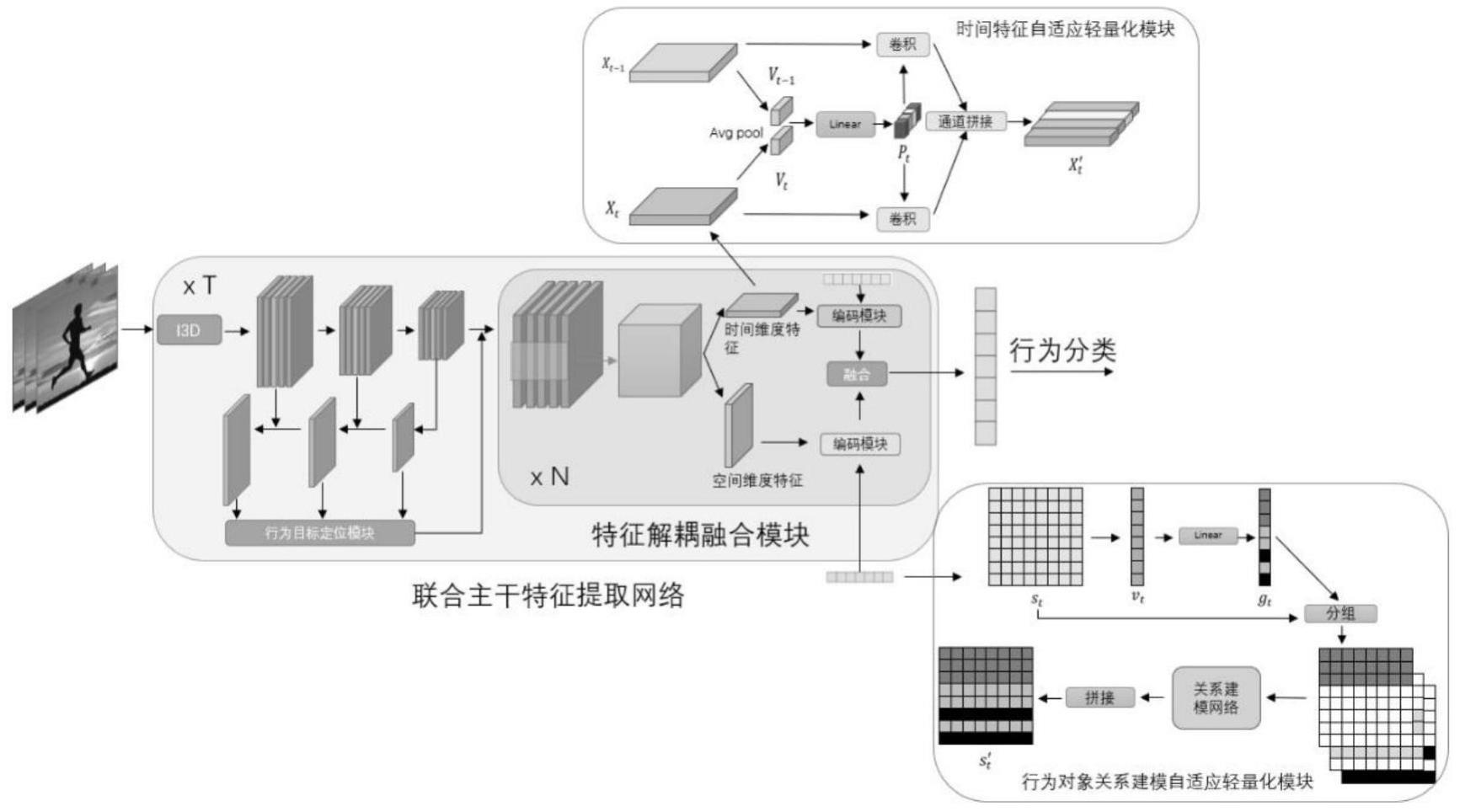
4、综上,现有的方案要么通常将三维卷积分解为二维空间卷积和一维时间卷积来降低计算复杂度,要么使用通道分离后的卷积神经网络,或者选取包含显著特征的图片帧作为输入。这些方案针对模型的输入数据或特征结构加以改变来减小模型的计算复杂度和参数量,但它们忽略了视频数据特征在时空维度上的关联性,并且常常删除了一些可以复用的重要特征信息,导致行为识别模型的准确率有所损失。并且,采用关联行为主体的模型在对主体关系进行建模时,将所有不同主体的特征全部用于计算,这会大大增加模型的参数量,且现在鲜有方案解决这个问题。对于模型的网络结构,现如今大多数性能优越的行为分析框架都采用了三维卷积神经网络提取视频特征,并且以行为主体为中心建模,然而这种架构要么将行为检测任务分成目标定位和行为分类两个阶段,要么在单阶段里训练两个分离的模型,这会让模型的参数量大,计算复杂度高。对于特征数据结构,通过分离特征图通道或采用维度不同的卷积分别处理输入数据的时间和空间维度来降低模型参数量,或是设计负责对特征图在特定维度上的剪枝模块,伴随模型的训练和预测,例如adafuse模型,然而这些方法忽略了视频数据特征在时空维度上的关联性,并且常常在轻量化的过程中删除了一些可以复用的重要特征信息,会导致行为识别模型的准确率有所损失。
技术实现思路
1、本发明的目的在于提供一种在降低了计算复杂度和参数量的同时,保证了识别精度的基于时空自适应融合的端到端人体行为分类方法及系统,以解决上述背景技术中存在的至少一项技术问题。
2、为了实现上述目的,本发明采取了如下技术方案:
3、一方面,本发明提供一种基于时空自适应融合的端到端人体行为分类模型训练方法,包括:
4、获取训练数据;所述训练数据包括多张图像以及标注图像中行为分布特征;所述行为分布特征指示至少一个行为在所述标注图像中的位置分布;
5、基于训练数据对行为分类模型进行训练;其中,
6、所述行为分类模型包括主干特征提取网络、特征解耦融合网络和分类网络;其中,所述主干特征提取网络用于提取所述多个图像的行为类别特征和位置特征,得到三维特征图;所述特征解耦融合网络用于对所述三维特征图分别在时间维度和空间维度上进行全局平均池化后,分别编码空间属性和时间尺度属性,再进行融合得到融合特征图;所述分类网络用于对所述融合特征图进行分类,得到所述融合特征图中各个通道的行为分类,并根据各个通道的行为分类,进行归一化处理,得到标注图像在单通道的行为分布特征。
7、优选的,所述主干特征提取网络包括特征金字塔单元、目标定位单元和对齐操作单元;所述特征金字塔单元用于提取图像的关键帧特征;所述目标定位单元用于将特征金字塔层的输出作为输入,提取图像的锚框位置信息;所述对齐操作单元用于将目标定位层的输出作为输入,提取包含行为主体的建议框,再分别进行对齐操作,得到所述三维特征图。
8、优选的,所述特征解耦融合模块包括特征解耦单元、第一特征编码单元、第二特征编码单元以及特征融合单元;所述特征解耦单元用于对所述三维特征图分别在空间维度和时间维度上进行全局平均池化,分别得到时间维度特征图和空间维度特征图;所述第一特征编码单元用于对所述时间维度特征图编码时间尺度属性特征;所述第二特征编码单元用于对空间维度特征图编码空间属性特征;所述特征融合单元用于对编码后的时间维度特征图和空间维度特征图进行融合。
9、优选的,所述特征融合单元对编码后的空间维度特征图和时间维度特征图进行融合包括:分别将时间维度特征图和空间维度特征图进行卷积操作调整通道数后,进行拼接得到第一矩阵特征图,然后再次卷积提取特征得到第二矩阵特征图,第二矩阵特征图经过reshape操作后得到第三矩阵特征图,将第三矩阵特征图和其转置相乘得到格拉姆矩阵,使用softmax层生成通道注意图矩阵,将通道注意图矩阵与第三矩阵特征图相乘,与第二矩阵特征图结合得到第四矩阵特征图,再卷积提取特征输出最终融合特征图。
10、优选的,所述特征解耦单元还包括时间特征通道自适应剪枝网络层,用于对所述编码后的时间维度特征图进行挑选保留、删除和复用的时间维度通道,输出时间特征。
11、优选的,所述特征解耦单元还包括行为对象关系建模自适应剪枝网络层,用于对所述空间属性特征中关联性强的对象特征进行通道分组拼接,得到关系特征向量。
12、优选的,所述行为分布特征指示至少一个行为在所述标注图像中的像素分布,每个行为对应于连通的像素区域。
13、第二方面,本发明提供一种基于时空自适应融合的端到端人体行为分类模型训练系统,包括:
14、获取模块,用于获取训练数据;所述训练数据包括多张图像以及标注图像中行为分布特征;所述行为分布特征指示至少一个行为在所述标注图像中的位置分布;
15、训练模块,用于基于训练数据对行为分类模型进行训练;其中,
16、所述行为分类模型包括主干特征提取网络、特征解耦融合网络和分类网络;其中,所述主干特征提取网络用于提取所述多个图像的行为类别特征和位置特征,得到三维特征图;所述特征解耦融合网络用于对所述三维特征图分别在时间维度和空间维度上进行全局平均池化后,分别编码空间属性和时间尺度属性,再进行融合得到融合特征图;所述分类网络用于对所述融合特征图进行分类,得到所述融合特征图中各个通道的行为分类,并根据各个通道的行为分类,进行归一化处理,得到标注图像在单通道的行为分布特征。
17、第三方面,本发明提供一种基于时空自适应融合的端到端人体行为分类方法,包括:
18、获取待分类行为的多个图像;
19、利用基于时空自适应融合的端到端人体行为分类模型对所述多个图像进行处理,得到行为特征图像,所述基于时空自适应融合的端到端人体行为分类模型根据权利要求1-7中任一项所述的模型训练方法训练得到。
20、第四方面,本发明提供一种基于时空自适应融合的端到端人体行为分类方法,包括:
21、获取针对目标群体采集的视频帧序列,所述目标群体中包括多个主体;
22、利用基于时空自适应融合的端到端人体行为分类模型对所述视频帧序列进行处理,得到所述多个主体各自的行为与所述视频帧序列中多个视频帧对应的位置分布;
23、基于与所述多个视频帧对应的位置分布,确定所述多个主体的行为,其中,所述基于时空自适应融合的端到端人体行为分类模型根据权利要求1-7中任一项所述的模型训练方法训练得到。
24、第五方面,本发明提供一种基于时空自适应融合的端到端人体行为分类系统,包括:
25、获取模块,用于获取待分类行为的多个图像;
26、分类模块,用于利用基于时空自适应融合的端到端人体行为分类模型对所述多个图像进行处理,得到行为特征图像,所述基于时空自适应融合的端到端人体行为分类模型根据权利要求1-7中任一项所述的模型训练方法训练得到。
27、第六方面,本发明提供一种基于时空自适应融合的端到端人体行为分类系统,包括:
28、获取模块,用于获取针对目标群体采集的视频帧序列,所述目标群体中包括多个主体;
29、分类模块,用于利用基于时空自适应融合的端到端人体行为分类模型对所述视频帧序列进行处理,得到所述多个主体各自的行为与所述视频帧序列中多个视频帧对应的位置分布;基于与所述多个视频帧对应的位置分布,确定所述多个主体的行为,其中,所述基于时空自适应融合的端到端人体行为分类模型根据权利要求1-7中任一项所述的模型训练方法训练得到。
30、第七方面,本发明提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质用于存储计算机指令,所述计算机指令被处理器执行时,实现如第一方面所述的基于时空自适应融合的端到端人体行为分类模型训练方法。
31、第八方面,本发明提供一种计算机程序产品,包括计算机程序,所述计算机程序当在一个或多个处理器上运行时,用于实现如第一方方面所述的基于时空自适应融合的端到端人体行为分类模型训练方法。
32、第九方面,本发明提供一种电子设备,包括:处理器、存储器以及计算机程序;其中,处理器与存储器连接,计算机程序被存储在存储器中,当电子设备运行时,所述处理器执行所述存储器存储的计算机程序,以使电子设备执行实现如第一方面所述的基于时空自适应融合的端到端人体行为分类模型训练方法的指令。
33、第十方面,本发明提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质用于存储计算机指令,所述计算机指令被处理器执行时,实现如第三方面或第四方面所述的基于时空自适应融合的端到端人体行为分类方法。
34、第十一方面,本发明提供一种计算机程序产品,包括计算机程序,所述计算机程序当在一个或多个处理器上运行时,用于实现第三方面或第四方面所述的基于时空自适应融合的端到端人体行为分类方法。
35、第十二方面,本发明提供一种电子设备,包括:处理器、存储器以及计算机程序;其中,处理器与存储器连接,计算机程序被存储在存储器中,当电子设备运行时,所述处理器执行所述存储器存储的计算机程序,以使电子设备执行实现如第三方面或第四方面所述的基于时空自适应融合的端到端人体行为分类方法的指令。
36、本发明有益效果:对三维视频特征图进行解耦融合,更少的丢失特征在时间和空间维度上的关键信息,保证模型在性能和效率之间的平衡;针对时间维度上的特征通道进行自适应剪枝,使其在模型计算的过程中,根据情况挑选保留、丢弃和复用的通道,合理地减少了参数量;针对不同行为对象关系进行自适应剪枝模块,减少模型在空间维度上的计算复杂度和参数量。
37、本发明附加方面的优点,将在下述的描述部分中更加明显的给出,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!