一种基于动作空间约束的离线强化学习方法
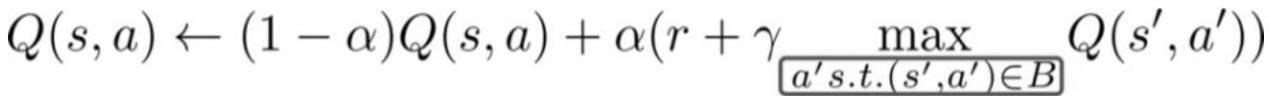
本发明属于强化学习,具体涉及一种基于动作空间约束的离线强化学习方法。
背景技术:
1、强化学习是机器学习领域的一类学习问题,它与常见的有监督学习、无监督学习等的最大不同之处在于,它是通过与环境之间的交互和反馈来学习的。强化学习的中心思想,就是让智能体在环境里学习。每个行动会对应各自的奖励,智能体通过分析数据来学习,怎样的情况下应该做怎样的事情。在每个时刻环境和个体都会产生相应的交互。个体可以采取一定的行动(action),这样的行动是施加在环境中的。环境在接受到个体的行动之后,会反馈给个体环境目前的状态(state)以及由于上一个行动而产生的奖励(reward)。强化学习的目标是希望个体从环境中获得的总奖励最大,不是短期的某一步行动之后获得最大的奖励,而是希望长期地获得更多的奖励。
2、跟监督学习不一样,强化学习的数据来自agent跟环境的各种交互。对于数据平衡性问题,监督学习可以通过各种补数据加标签来达到数据平衡。但这件事情对强化学习确实非常难以解决的,因为数据收集是由policy来做的,它们在学习过程中,对于任务激励信号的理解的不完善的,很可能绝大部分时间都在收集一些无用且重复的数据。样本效率一直是传统强化学习被诟病的问题,所以强化学习在过去主要是在可获取无限样本的游戏领域上取得成功。
3、利用现有记录的数据集,在corr abs/2005.01643(2020)上提出的离线强化学习(offline rl)方法是解决上述问题的一种很有希望的方法。它可以在不与环境进一步交互的情况下学习策略。数据集可以由其他智能体、其他算法甚至其他任务生成。离线rl的最终目的是优化目标策略π,但是无法依据行为策略与环境交互以及收集额外的转变。本质上离线rl需要从一个固定的数据集中,充分理解隐含在马尔可夫决策过程(mdp)背后的动态系统,而后构建策略π(a|s)从而在实际与mdp交互时获得最大累计奖励。使用πβ表示离线数据集集d中的状态和动作分布,因此状态-动作元组(s,a)∈d由s~dπβ(s)采样得到,而动作由行为策略采样得到a~πβ(a|s),那么最终的学习目标就成了最大化q值。
4、离线强化学习成为研究热点的原因就是就是标准的rl的一个核心难点便是采样效率极低,需要频繁地与环境进行交互收集数据来训练智能体。而交互过程中大量的探索在很多现实场景会带来严重的成本损失。例如,使用机器人在真实环境中进行探索可能会有损坏机器人硬件或周围物体的风险;在广告投放中进行探索可能会导致广告主的预算白白浪费;在医疗和自动驾驶中进行探索则可能会严重危害人类的生命安全。而离线强化学习的设定是利用离线数据进行策略学习而不进行任何交互,因此避免了探索可能带来的成本损失。
5、另一方面,对于复杂的现实场景,建立simulator是很难的一件事情,开销不会低,建立high fidelity(高精确)的simulator更是如此。离线强化学习是直接对应真实世界得来的数据学的,可以绕过这一点。标准强化学习算法在offline rl场景往往表现不佳,甚至很差。学到的策略无法在实际部署中取得令人满意的表现。这是因为在离线数据集的情况下,策略倾向于选择偏离数据集d的动作。
6、具体来说,由于离线数据集的狭窄和有限,现有的强化学习方法很难找到一个最优的策略。当只通过offline数据进行学习时,由于外推误差(extrapolation error),即不可见的状态-动作对被错误地估计为一个不真实的值。而具有深度rl中的大多数offpolicy算法都将失败,其中offline数据之外的状态动作对(s,a)可能具有不准确的q值,这将对依赖于传播这些值的算法产生不利影响。在online学习中,采用exploration可以纠正这些误差,因为agent可以得到得到真实的reward值,但在offline的情况下off policy的rl缺乏这种纠错能力。
技术实现思路
1、针对现有技术的不足,为解决智能体(agent)在不和环境交互的情况下,来从获取的轨迹中学习经验知识,达到目标最大化,本发明提供一种基于动作空间约束的离线强化学习方法。
2、一种基于动作空间约束的离线强化学习方法,具体包括以下步骤:
3、步骤1:利用在线rl算法ddpg在基准数据集d4rl上获取离线数据集b,该离线数据集的行为分布即为行为策略πβ(a|s);使用异策略q-learning在离线数据集中收集多条轨迹样本存入回放缓存中,然后对当前学习策略进行策略评估;
4、首先定义状态价值函数v,即每种动作会带来的后续奖励,用于评估策略;因为当前奖励大并不代表其未来的最终奖励一定是最大的,所以需要使用v期望函数来评价未来;
5、vπ(s)=eπ(rt+1+γrt+2+γ2rt+3+...∣st=s)
6、其中,r为奖励,s为智能体状态,t为第t步,第t步的状态是状态st,vπ(s)为策略π在状态s下,选择的行动后获得的价值,γ为回报折扣率,这是因为考虑到奖励的时效性,时间越久的奖励所占的比重应该越小;
7、定义动作价值函数,其同样为某一时刻回报的条件期望;即从某个状态选取动作a,走到最终状态多次;最终获得奖励总和的平均值,即q值;
8、vπ(st)=∑aπ(a|s)·qπ(s,a)
9、此函数用于评价当前状态的好坏,也用于评价策略函数的好坏,策略函数越好,状态价值函数的平均值就越大;首先对于在状态s,根据策略采取动作a的总奖励q是当前奖励r和对未来各个可能的状态转化奖励的期望v组成,根据一定的∈概率每次选择奖励最大q或探索,组成完整的策略,那么目标就变成了计算这个q值,然后根据q选择策略;
10、对所有的策略函数π求最大值,得到最优状态价值函数;而选择能够产生最大q值的动作at+1;
11、步骤2:利用深度神经网络来计算预估价值q;
12、通过深度学习的方式来计算q值;dqn即深度q网络;总体思路还是用q学习的思路,不过对于给定状态选取哪个动作所能得到的q值,是由一个深度神经网络来计算的;
13、步骤3:处理分布转移带来的影响,将学习策略向行为策略进行规范和约束;所述分布转移指的是离线数据集中的数据分布与真实环境中的测试数据分布不一致;
14、通过限制学习策略选择的状态动作对,使它与离线数据集b中存在数据或状态动作对相似,使选择动作的q值估计变得准确,因此在进行动作选择时,设置需要满足的目标为:
15、1)最小化所选择的动作和离线数据集中存在的行为的距离;
16、2)能转移到和离线数据集中状态相似的状态;
17、步骤4:改进学习策略,进一步处理分布转移带来的影响;设置每过一段时间,将评估策略时得到优异表现的网络参数更新到目标策略中去,使学习策略得到改进;
18、q-learing中下一状态的动作选择π(s')=argmaxq(s’,a’),从离线数据集b学习的q函数,定义一个对应的mdp为mb,真实的mdp记为m;mb和m具有相同的动作空间和状态空间,初始状态为s,初始动作值是q(s,a);
19、为了缓解分布转移带来的影响,进行正常的q-learning,在选取最大化q值对应的动作时,只考虑实际出现在这批离线数据中的动作a,而不考虑动作空间中所有可能的动作;即让学习策略不要采取构建离线数据集的行为策略πb不选择的动作;
20、步骤5:利用vae训练得到的生成模型生成与离线数据集b相似的动作集合,并通过q选择价值最高的动作;
21、利用变分自动解码器vae训练一个生成模型g来生成可能来自离线数据集中的动作即重建行为策略,然后进一步利用干扰动作的扰动网络对生成的动作进行调优;即使用一个状态生成模型vae去产生与数据集中action类似的action,然后结合了一个扰动网络,这个网络的目标是在小范围内扰动生成的actions,此外再引入一个q网络,用于从扰动的actions中选出一个使q值最大的action;
22、为了对末来一些不常见的状态进行惩罚,训练一对q网络,每次都选择两个网络中输出q值最小的那个;
23、
24、该计算式的框内强调部分即为使用了一个vae来估计动作的那个部分;
25、步骤6:利用随机集成混合方法来训练多个q值的估计,并将其加权组合得到更加精确的q值估计,减少神经网络近似q值带来的评估误差;
26、对于离线数据集b中每次训练序列随机抽取一个分类分布α,定义一个k估计的凸组合,以此来近似最优的q函数;用该方法对其相应的目标进行训练,以最小化td误差;损失l(θ)的形式:
27、
28、l(θ)看作是一个对应于不同混合概率分布的无限约束集,lλ是huber loss,pδ表示一个非常简单的分布:从正态分布n(0,1)中获取k个独立同分布的值,且该分布满足ak={a1+a2+...+ak=1,ak>=0,k=1,2,3,...,k};
29、对于动作的选择,使用k个值函数估计值的平均值作为q函数,即;
30、
31、步骤7:当训练次数结束时,更新最终的策略参数,将训练好的策略在现实环境进行交互并评估;验证在离线数据集训练好的策略在在线是否表现良好。
32、本发明有益技术效果:
33、标准的rl的一个核心难点便是采样效率极低,需要频繁地与环境进行交互收集数据来训练智能体。而交互过程中大量的探索在很多现实场景会带来严重的成本损失。并且现有的标准rl算法在离线的设定下学习效果往往非常差,学到的策略无法在实际部署中取得令人满意的表现。
34、本发明通过离线强化学习(offline rl)可以利用离线数据进行策略学习而不进行任何交互,因此避免了探索可能带来的成本损失,并且可以在较短时间内学习到一个性能好的策略。通过对学习策略所生成对动作空间进行约束对方式,解决离线强化学习中分布转移所带来的推断误差的问题。对于给定的状态,利用生成模型来生成与离线数据集(batch)相似的动作集合,并通过q网络来选择价值最高的动作。另外,还对价值估计过程中采取了随机集成混合的方法,访问多个q值的估计,并将其加权组合得到q值的估计,最后本发明能学到与数据集的状态动作对访问分布相似的策略。
- 还没有人留言评论。精彩留言会获得点赞!