卷积运算电路、及具有该卷积运算电路的相关电路或设备的制作方法
本技术涉及处理器,具体而言,涉及一种卷积运算电路、及具有该卷积运算电路的相关电路或设备。
背景技术:
1、ai(artificial intelligence,人工智能)算法中存在大量的卷积运算,根据精度的需求卷积运算需要支持不同类型的数据,例如需要支持诸如fp32/tf32/fp16/bf16/int8/uint8/int4/uint4等类型的数据。其中,fp32/tf32/fp16/bf16为浮点数据类型,而int8/uint8/int4/uint4为定点数据类型。而随着ai技术的不断发展,需要处理器能够同时支持定点数据的运算和浮点数据的运算。
2、目前,为实现处理器同时支持定点数据的卷积运算和浮点数据的运算,常规的实现方式是在处理器内同时设计单独的进行定点数运算的定点数卷积运算电路和进行浮点数运算的浮点数卷积运算电路,这就导致了处理器中的面积开销大。
技术实现思路
1、本技术实施例的目的在于提供一种卷积运算电路、及具有该卷积运算电路的相关电路或设备,用以解决相关技术存在着的会导致处理器内面积开销大的问题。
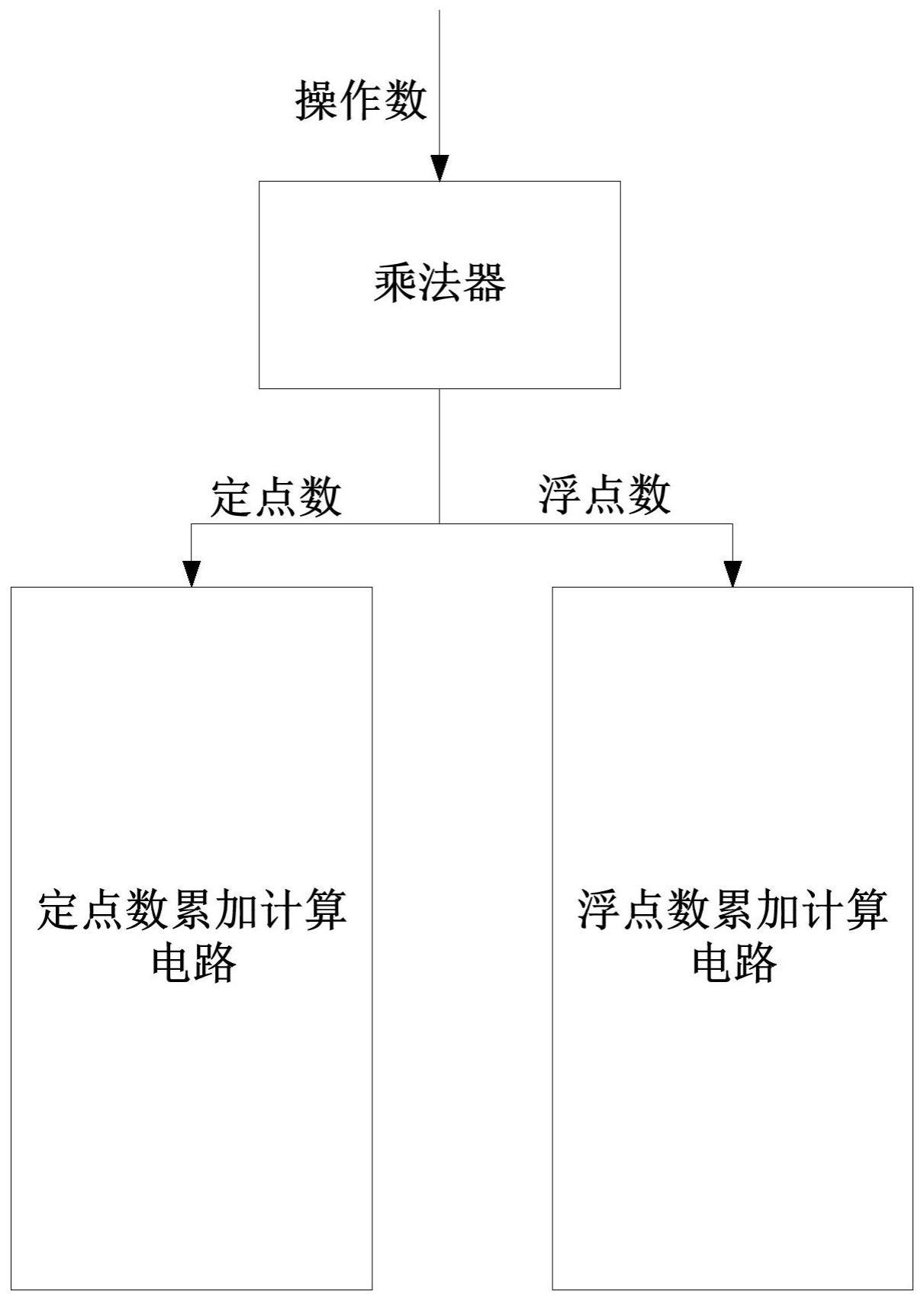
2、本技术实施例提供了一种卷积运算电路,包括:乘法器,用于接收操作数,以完成乘法中间结果计算,输出部分积;定点数累加计算电路,与所述乘法器连接,用于在所述操作数为定点数时,对所述乘法器输出的部分积进行压缩并对压缩后的部分积进行相加处理,得到定点卷积运算结果;浮点数累加计算电路,与所述乘法器连接,用于在所述操作数为浮点数时,根据所述操作数的指数部分进行指数计算得到浮点乘法指数结果,并根据所述乘法器输出的部分积进行尾数计算得到尾数计算结果。
3、在上述实现结构中,由于定点数累加计算电路和浮点数累加计算电路均与乘法器相连接,因此对于定点数的计算和对于浮点数的计算可以复用乘法器,从而相比于单独配置定点数卷积运算电路和浮点数卷积运算电路的方案而言,面积开销得以降低;同时,定点数的计算和浮点数的计算在累加计算时,分别通过定点数累加计算电路和浮点数累加计算电路实现,可以节省不同数据类型的卷积运算的功耗开销。
4、进一步地,所述操作数为按照所述乘法器的位宽对待运算数据和待运算权重的尾数进行拆分或填充后得到的数据和权重;
5、所述浮点数累加计算电路包括:尾数计算单元,与所述乘法器连接,用于对所述乘法器输出的针对同一待运算数据的部分积进行压缩并求和,得到对应该待运算数据的浮点尾数乘法结果;指数计算单元,用于对所述待运算数据和所述待运算数据对应的待运算权重的指数部分进行计算,得到针对该待运算数据的浮点乘法指数结果;累加单元,与所述尾数计算单元和所述指数计算单元连接,用于从多个待运算数据对应的浮点乘法指数结果中,选择出最大浮点乘法指数结果,以及用于对所述多个待运算数据对应的浮点尾数乘法结果进行压缩并求和得到所述尾数计算结果。
6、在上述实现方式中,通过尾数计算单元和指数计算单元分别实现了对于待运算数据的尾数部分和指数部分的计算。而通过累加单元的处理,就实现了多个浮点尾数乘法结果之间的累加,从而满足了针对浮点卷积计算的要求。
7、进一步地,所述指数计算单元还用于:对所述待运算数据和所述待运算权重中携带的异常标志位进行检查,在存在表征数据为denormal的异常标志位时,将具有该异常标志位的所述待运算数据或所述待运算权重的指数部分表示为1。
8、在上述实现方式中,通过待运算数据中携带的异常标志位实现对于待运算数据是否为denormal数据的确定,通过待运算权重中携带的异常标志位实现对于待运算权重是否为denormal数据的确定,从而不需要在对于指数部分的计算路径上引入浮点数denormal的判断逻辑,可以节省指数部分的计算开销。
9、进一步地,所述指数计算单元还用于:在用于计算的所述待运算数据和所述待运算权重的指数部分中,存在至少一个指数部分为0时,确定所述浮点乘法指数结果为0。
10、在上述实现方式中,通过将存在指数部分为0的指数计算情况中的浮点乘法指数结果确定为0,从而可以保证指数运算的正确,一方面可以提高指数部分运算效率(存在至少一个指数部分为0时,直接确定浮点乘法指数结果为0,无需再进行运算),而另一方面也可以避免按照正常累加后,造成运算出错。
11、进一步地,所述尾数计算单元包括:压缩电路,与所述乘法器连接,用于对所述乘法器输出的针对同一待运算数据的部分积进行压缩;第一加法器,与所述压缩电路的输出端连接,用于将所述压缩电路输出的部分积求和,得到对应该待运算数据的浮点尾数乘法结果。
12、在上述实现方式中,通过压缩电路进行乘法器中部分积的压缩运算,并通过第一加法器进行累加,即可实现对应于同一待运算数据的乘法运算,快速地得到对应该待运算数据的浮点尾数乘法结果。
13、进一步地,所述累加单元中包括:指数选择单元,用于从多个待运算数据对应的浮点乘法指数结果中,选择出最大浮点乘法指数结果;指数阶差计算单元,与所述指数选择单元连接,用于计算各所述待运算数据对应的浮点乘法指数结果与所述最大浮点乘法指数结果之间的指数阶差;累加器,与所述指数阶差计算单元连接,用于按照所述指数阶差对各所述待运算数据对应的浮点尾数乘法结果进行对阶移位,并对对阶移位后的浮点尾数乘法结果进行压缩并求和得到所述尾数计算结果。
14、在上述实现方式中,通过指数阶差计算单元计算出各待运算数据对应的浮点乘法指数结果与最大浮点乘法指数结果之间的指数阶差,进而对各待运算数据对应的浮点尾数乘法结果进行对阶移位,这样就可以保证对多个待运算数据对应的尾数部分进行计算时,浮点尾数乘法结果是对齐的,从而保证计算结果的准确。
15、进一步地,所述指数选择单元包括第一级指数选择单元和第二级指数选择单元;所述指数阶差计算单元包括第一级指数阶差计算单元和第二级指数阶差计算单元;所述累加器包括第一级累加器和第二级累加器;
16、所述第一级指数选择单元用于从多个待运算数据对应的浮点乘法指数结果中,选择出第一级最大浮点乘法指数结果,并传输给所述第一级指数阶差计算单元和所述第二级指数选择单元;
17、所述第一级指数阶差计算单元用于计算各所述待运算数据对应的浮点乘法指数结果与所述第一级最大浮点乘法指数结果之间的指数阶差;
18、所述第一级累加器用于按照所述指数阶差对各所述待运算数据对应的浮点尾数乘法结果进行对阶移位,并对对阶移位后的浮点尾数乘法结果进行压缩并求和得到第一级尾数计算结果,并输出给所述第二级累加器;
19、所述第二级指数选择单元用于从多个所述第一级最大浮点乘法指数结果中,选择出第二级最大浮点乘法指数结果;
20、所述第二级指数阶差计算单元用于计算多个所述第一级最大浮点乘法指数结果与第二级最大浮点乘法指数结果之间的指数阶差;
21、所述第二级累加器用于根据各所述指数阶差,对各所述第一级尾数计算结果进行对阶移位,并对对阶移位后的第一级尾数计算结果进行压缩并求和得到所述尾数计算结果。
22、在上述实现方式中,通过两级累加单元的设计(其中第一级指数选择单元、第一级指数阶差计算单元和第一级累加器可以看作第一级累加单元,第二级指数选择单元、第二级指数阶差计算单元和第二级累加器可以看作第二级累加单元),从而可以一次性实现更多数量的待运算数据的卷积计算,从而显著提高所能支持的浮点数卷积运算性能。例如,假设单个累加器仅能实现4个数据的压缩、求和处理,那么通过上述方式就可以实现8个数据的压缩、求和处理,从而显著提高所能支持的浮点数卷积运算性能。
23、进一步地,所述第一级累加器包括:对阶移位器,用于按照所述指数阶差对各所述待运算数据对应的浮点尾数乘法结果进行对阶移位;第一符号处理电路,与所述对阶移位器连接,用于对对阶移位后的浮点尾数乘法结果进行符号处理;两级csa32电路,与所述第一符号处理电路连接,用于对符号处理后的数据进行压缩;第二加法器,与所述两级csa32电路的输出端连接,用于将所述两级csa32电路输出的数据相加得到所述第一级尾数计算结果。
24、在上述实现方式中,通过对阶移位器进行浮点尾数乘法结果的对阶移位操作,通过第一符号处理电路实现符号处理,并通过两级csa32电路即可实现基于符号的数据压缩处理,并通过第二加法器实现对于两级csa32电路输出的数据的累加,这就可以快速准确的实现第一级的尾数部分的卷积运算,电路实现简单、可靠。
25、进一步地,所述对阶移位器具体用于:在所述待运算数据和所述待运算权重的数据类型为fp16或bf16或tf32类型时,按照所述指数阶差对各所述待运算数据对应的浮点尾数乘法结果进行对阶移位;在所述待运算数据和所述待运算权重的数据类型为fp32类型时,将所述待运算数据对应的低位浮点尾数乘法结果右移12位;其中,所述低位浮点尾数乘法结果为b12_d_l×b12_w_l对应的浮点尾数乘法结果,所述b12_d_l为所述待运算数据中的第0位至11位尾数,所述b12_w_l为所述待运算权重中的第0位至11位尾数。
26、在上述实现方式中,针对fp32类型的待运算数据,由于其尾数乘法是b24×b24运算,在采用本技术实施例所提供的方案时,可以拆分成4个b12×b12乘法实现,也即可以拆分成b12_d_l×b12_w_l、b12_d_l×b12_w_h、b12_d_h×b12_w_l、以及b12_d_h×b12_w_h四个b12×b12乘法实现。其中,b12_d_l为待运算数据中的第0位至11位尾数,b12_d_h为待运算数据中的第12位至23位尾数,b12_w_l为待运算权重中的第0位至11位尾数,b12_w_h为待运算权重中的第12位至23位尾数。而在拆分成4个b12×b12乘法实现后,需要对拆分后的4个b12×b12乘法的浮点尾数乘法结果进行移位,以保证对4个b12×b12乘法的浮点尾数乘法结果的累加可以得到正确的b24×b24乘法运算的浮点尾数乘法结果。为此,在上述实现过程中,将b12_d_l×b12_w_l乘法对应的浮点尾数乘法结果右移12位,即可保证b12_d_l×b12_w_l、b12_d_l×b12_w_h、b12_d_h×b12_w_l三个b12×b12乘法的浮点尾数乘法结果的对齐,而对于b12_d_h×b12_w_h对应的浮点尾数乘法结果则可以通过后续运算时在尾部赋值12’b0实现与左移12位相同的效果,实现b12_d_h×b12_w_h的浮点尾数乘法结果与b12_d_l×b12_w_l、b12_d_l×b12_w_h、b12_d_h×b12_w_l三个b12×b12乘法的浮点尾数乘法结果的对齐。这样,对阶移位器则只需要右移的对阶移位器即可,无需额外增设左移的对阶移位器,可以节约面积。
27、进一步地,所述第一符号处理电路用于:若4个对阶移位后的浮点尾数乘法结果的符号同时为负,则将计算第一标志信息并传输到第二级累加器;所述两级csa32电路中的第一级csa32电路用于对4个对阶移位后的浮点尾数乘法结果中的3个浮点尾数乘法结果进行部分积压缩,输出2个部分积pp0,pp1;所述两级csa32电路中的第二级csa32电路用于对4个对阶移位后的浮点尾数乘法结果中剩余的1个浮点尾数乘法结果和所述pp0、所述pp1进行部分积压缩,最终输出两个部分积。
28、可以理解,csa32电路自带1bit的进位,正常使用时,进位默认0,从而可以用于标识浮点尾数乘法结果的符号同时为负的情况,从而利用该特点,通过两级csa32电路即可快速、可靠地对4个对阶移位后的浮点尾数乘法结果进行处理,从而可以得到准确、可靠的运算后的部分积,进而保证最终的运算结果的准确性。同时,在上述实现方式中,在4个对阶移位后的浮点尾数乘法结果的符号同时为负时,不进行取反操作,而是计算第一标志信息并传输到第二级累加器,从而可以在第二级累加器中统一进行取反操作,从而可以减少取反操作的次数(至少可以将4次取反操作减少至1次),从而降低运算开销,提高电路的运算效率。
29、进一步地,所述第一符号处理电路还用于:若4个对阶移位后的浮点尾数乘法结果的符号不同时为负,则根据所述4个对阶移位后的浮点尾数乘法结果中符号为负的个数,生成3bit的标志值neg[2:0],并对符号为负的所述浮点尾数乘法结果取反;所述两级csa32电路中的第一级csa32电路还用于对符号处理后的4个所述浮点尾数乘法结果中的3个浮点尾数乘法结果和neg[0]进行部分积压缩,输出2个部分积pp0,pp1;所述两级csa32电路中的第二级csa32电路还用于对4个对阶移位后的浮点尾数乘法结果中剩余的1个浮点尾数乘法结果和所述pp0、所述pp1、进行neg[1]进行部分积压缩,最终输出两个部分积。所述第二加法器用于对所述最终输出两个部分积和neg[2]进行累加。
30、在上述实现方式中,通过4个对阶移位后的浮点尾数乘法结果中符号为负的个数,生成3bit的标志值neg[2:0],从而可以利用csa32电路自带1bit的进位,实现4输入的部分积压缩运算,从而可以在不额外增加硬件开销的基础上,实现最多3个负数的取反操作,降低面积开销。
31、进一步地,所述乘法器为8×4乘法器;所述第二级累加器包括:对阶移位器,用于根据各所述指数阶差,对各所述第一级尾数计算结果进行对阶移位;第二符号处理电路,与所述对阶移位器连接,用于对对阶移位后的第一级尾数计算结果进行符号处理;csa42电路,与所述第二符号处理电路连接,用于对符号处理后的数据进行压缩;第三加法器,与所述csa42电路的输出端连接,用于将所述csa42电路输出的两个部分积和neg_cout进行累加得到所述尾数计算结果;其中,所述neg_cout为所述第二符号处理电路进行取反操作的次数。
32、上述实现方式中,csa42电路可以实现对第一级尾数计算结果的快速压缩处理,同时第二符号处理电路可以实现对于第一级符号处理电路中未取反处理的结果进行符号处理,避免了在第一级符号处理电路中对4个符号同时为负的浮点尾数乘法结果进行取反操作,减少面积开销和功耗。
33、进一步地,所述乘法器为12×4乘法器;所述第二级累加器包括:对阶移位器,用于根据各所述指数阶差,对各所述第一级尾数计算结果进行对阶移位;第二符号处理电路,与所述对阶移位器连接,用于对对阶移位后的第一级尾数计算结果进行符号处理;两级csa42电路,与所述第一符号处理电路连接,用于对符号处理后的数据进行压缩;第四加法器,与所述两级csa42电路的输出端连接,用于将所述两级csa42电路输出的两个部分积和neg_cout进行累加得到所述尾数计算结果;其中,所述neg_cout为所述第二符号处理电路进行取反操作的次数。
34、上述实现方式中,通过两级csa42电路输出可以实现8个第一级尾数计算结果的快速压缩处理,同时第二符号处理电路可以实现对于第一级符号处理电路中未取反处理的结果进行符号处理,避免了在第一级符号处理电路中对4个符号同时为负的浮点尾数乘法结果进行取反操作,减少面积开销和功耗。
35、进一步地,所述定点数累加计算电路包括:两条并行的华莱士树csa_tree_h和csa_tree_l;所述csa_tree_h用于与奇数序号的乘法器连接,以对奇数序号的所述乘法器输出的部分积进行压缩,并输入第五加法器中进行累加得到result_h;所述csa_tree_l用于与偶数序号的乘法器连接,以对偶数序号的所述乘法器输出的部分积进行压缩,并输入第六加法器中进行累加得到result_l;所述定点数累加计算电路还包括第七加法器,与所述第五加法器和所述第六加法器连接,用于对所述result_h和所述result_l进行累加,得到所述定点卷积运算结果。
36、在上述实现发方式中,通过两条并行的华莱士树csa_tree_h和csa_tree_l,可以满足对于int4/uint4/int8/uint8的卷积运算需求,且两路并行运算也可以提高运算效率。此外,对于int8/uint8类型的数据而言,csa_tree_h和csa_tree_l分奇数和偶数序号进行乘法器输出数据的处理,因此对于int8/uint8类型的数据进行移位对齐时,可以针对csa_tree_h的输出统一进行移位,从而可以有效降低移位操作的次数,提高运算效率,同时,相比于只设置一个华莱士树的情况,还可以降低华莱士树的宽度,降低功耗。
37、进一步地,所述操作数包括对int8或uint8类型的待运算数据进行拆分后得到的4bit数据;所述定点数累加计算电路还包括移位器,设置于所述第五加法器和所述第七加法器之间,以对所述result_h进行左移4位的操作。
38、int8或uint8类型的待运算数据为8bit,因此可以拆分为两个4bit的数据,拆分后为保证数据运算的准确性,对于高位部分的4bit数据需要左移4位。而上述实现方式中利用移位器对result_h进行左移4位的操作,可在保证运算结果准确的前提下,仅进行一次移位操作,从而有效降低移位操作的次数,提高运算效率。
39、进一步地,所述乘法器为无符号数乘法器;所述定点数累加计算电路还包括第三符号处理电路、第四符号处理电路、第一neg count计算单元和第二neg count计算单元;其中:所述第三符号处理电路设置于所述csa_tree_h和奇数序号的所述乘法器之间,并用于获取各奇数序号的所述乘法器处理的操作数的符号;所述第四符号处理电路设置于所述csa_tree_l和偶数序号的所述乘法器之间,并用于获取各偶数序号的所述乘法器处理的操作数的符号;所述第三符号处理电路和所述第四符号处理电路还用于:对所连接的每个所述乘法器输出的部分积进行符号处理,若任一乘法器的两操作数的符号值异或运算结果为真,则对该乘法器输出的部分积取反;所述第一neg count计算单元用于计算所述第三符号处理电路进行的取反次数neg_count_h;所述第二neg count计算单元用于计算所述第四符号处理电路进行的取反次数neg_count_l;所述第五加法器用于对所述csa_tree_h的输出数据和所述neg_count_h进行累加得到所述result_h;所述第六加法器用于对所述csa_tree_l的输出数据和所述neg_count_l进行累加得到所述result_l。
40、在上述实现方式中,为实现对于无符号数乘法器的复用,通过在定点数累加计算电路中设计符号处理电路进行符号处理,并计算取反次数,可以在华莱士树的处理结果的基础上,结合取反次数得到正确的定点卷积运算结果。将定点负数的处理从定点和浮点共享的乘法路径上移动到了定点数累加计算电路中,缩短了浮点数的尾数乘法路径(即对浮点数的尾数进行运算的路径)。
41、本技术实施例还提供了一种卷积计算单元,包括:权重传输子单元,用于接收待运算权重;数据传输单元,用于接收待运算数据;前述任一种的卷积运算电路,与所述权重传输子单元和所述数据传输单元连接,用于根据所述待运算数据和所述待运算权重进行卷积运算;其中,所述卷积运算电路中运算的操作数为对所述待运算数据和所述待运算权重处理后得到的数据。
42、进一步地,所述数据传输单元包括:数据传输子单元,用于接收待选数据;数据选择器,分别与所述数据传输子单元和所述权重传输子单元连接,用于根据所述权重传输子单元传来的权重掩码从所述待选数据中选择出待运算数据。
43、本技术实施例还提供了一种ai运算阵列,包括至少一个前述的卷积计算单元。
44、本技术实施例还提供了一种ai算法架构的实现装置,包括:存储单元,用于存储待运算数据和待运算权重;访存控制单元,用于从所述存储单元获取所述待运算权重和所述待运算数据;前述的ai运算阵列,所述ai运算阵列用于根据所述待运算权重和所述待运算数据进行卷积运算。
45、进一步地,所述ai算法架构的实现装置还包括:权重浮点异常处理单元,用于判断所述访存控制单元获取到的所述待运算权重是否为denormal数据,在所述待运算权重为denormal数据时,将所述待运算权重的指数部分表示为1;数据浮点异常处理单元,用于判断所述访存控制单元获取到的所述待运算数据是否为denormal数据,在所述待运算数据为denormal数据时,将所述待运算数据的指数部分表示为1。
46、在上述实现方式中,通过权重浮点异常处理单元和数据浮点异常处理单元,在待运算权重和待运算数据进入卷积计算单元之前,就对denormal数据进行异常处理(即将指数部分表示为1),从而只需分别对待运算权重和待运算数据进行一次浮点数的异常处理,无需在每个卷积计算单元中再分别进行异常处理,可以将浮点数的异常处理次数减少到1,减少了重复的异常处理开销,且无需在每个卷积运算电路中单独设置处理异常的浮点数的电路,节约了面积开销。
47、也即,本技术通过将每个卷积运算电路中都需要进行的denormal数据异常处理统一在顶层的权重浮点异常处理单元和数据浮点异常处理单元中进行处理,每个卷积运算电路中就可以不再需要引入异常判断逻辑,优化了面积,降低了每个卷积运算电路中浮点数卷积的计算复杂度,提高了卷积运算速度。
48、进一步地,所述ai算法架构的实现装置还包括:数据定点绝对值处理单元用于对访存控制单元取出的待运算数据进行符号位分离和绝对值处理,以将处理后的绝对值数据和符号位数据传给后续的卷积运算电路;权重定点绝对值处理单元用于对访存控制单元取出的待运算权重进行符号位分离和绝对值处理,以将处理后的绝对值权重数据和符号位权重数据传给后续的卷积运算电路。
49、通过上述实现方式,输入至乘法器进行运算的数据是绝对值处理后的绝对值数据和绝对值权重数据,这就使得乘法器不需要进行符号处理,从而可以使得乘法器本身的设计更简单,也缩短了浮点数的尾数乘法路径,使得功耗更低。
50、本技术实施例还提供了一种处理器,包括前文所述的ai算法架构的实现装置。
51、本技术实施例还提供了一种电子部件,包括前文所述的处理器。
52、本技术实施例中还提供了一种电子设备,包括前文所述的处理器,或包括前文所述的电子部件。
- 还没有人留言评论。精彩留言会获得点赞!