信息瓶颈增强的视频行人重识别方法、系统及存储介质
本发明涉及图像处理,尤其涉及一种信息瓶颈增强的视频行人重识别方法及系统。
背景技术:
1、行人重识别(person-reid)的目的是给定视频监控网络下一个特定的身份的人,在监控网络下的其他监控设备中的精确地检索出相同的身份,并给出查询结果。行人重识别是实现视频监控网络智能化必不可少的一环,也是安防智能化技术的核心。
2、现有的基于视频的行人重识别方法使用一段视频片段作为输入而不是单一的一张图片,根据现实中监控设备采集的原始视频数据,能够更贴近实际场景,提供人物的外貌信息和时间维度上的姿势变化、步态信息。现有技术主要从空间特征提取和时序特征建模两个方面,进行视频行人重识别任务;其中,空间特征提取方法包括卷积神经网络、图神经网络等,时序特征提取包括循环神经网络、三维卷积等。
3、但是,现有技术在处理原始视频数据后,所得到的特征数据仍然存在较多的噪声干扰和背景变化,如何利用好视频数据的时间和空间信息是解决视频行人重识别任务的关键。
技术实现思路
1、本发明的目的是针对上述现有技术的不足,提出一种信息瓶颈增强的视频行人重识别方法、系统及存储介质,旨在解决现有技术缺乏对特征中行人的有效信息的直接优化,所提取的特征会包含大量的冗余/干扰信息的问题。
2、第一方面,本发明提供了一种信息瓶颈增强的视频行人重识别方法,所述方法包括:
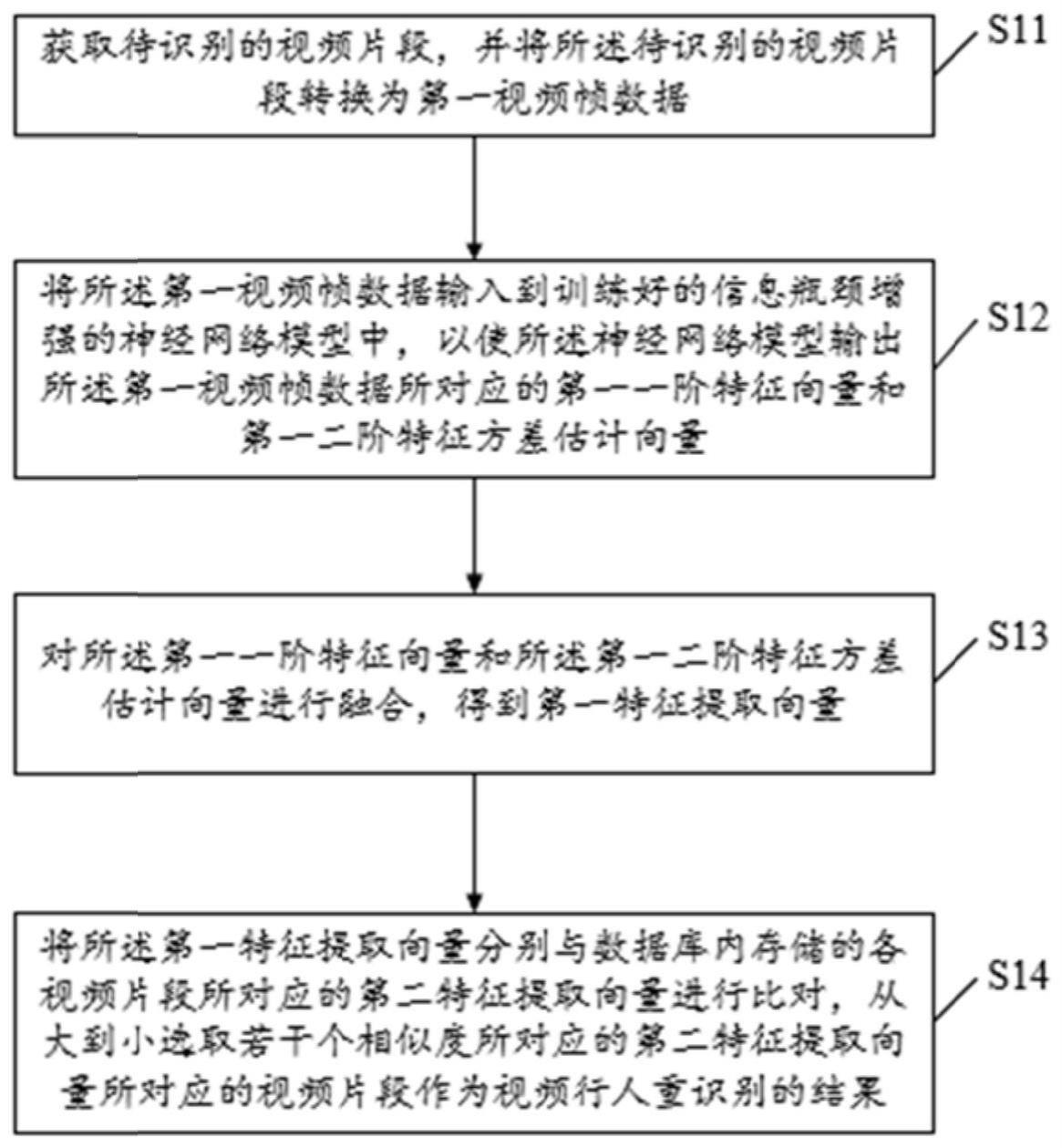
3、获取待识别的视频片段,并将所述待识别的视频片段转换为第一视频帧数据;
4、将所述第一视频帧数据输入到训练好的信息瓶颈增强的神经网络模型中,以使所述神经网络模型输出所述第一视频帧数据所对应的第一一阶特征向量和第一二阶特征方差估计向量;其中,所述神经网络模型是以视频片段样本作为输入,以一阶特征向量和二阶特征方差估计向量作为输出,并对每次输出进行重参数化,根据信息瓶颈损失函数和重识别损失函数计算损失函数,进行若干次训练后而获得;
5、对所述第一一阶特征向量和所述第一二阶特征方差估计向量进行融合,得到第一特征提取向量;
6、将所述第一特征提取向量分别与数据库内存储的各视频片段所对应的第二特征提取向量进行比对,从大到小选取若干个相似度所对应的第二特征提取向量所对应的视频片段作为视频行人重识别的结果。
7、本发明通过计算一阶特征向量外,还计算二阶特征方差估计向量,采用重参数化技术才可以计算信息瓶颈损失函数中的互信息,并以计算信息瓶颈损失函数和重识别损失函数进行参数更新,能够挖掘行人视频片段数据中空间和时间上高判别性的特征信息将其保留,而且可以抑制视频的帧序列空间和时间中的干扰信息,能够减少冗余/低判别性信息对特征提取的干扰,提高行人重识别的精确度。
8、进一步,所述神经网络模型内设置了第一网络和第二网络;
9、所述第一网络为特征提取网络,用于输出所述一阶特征向量;
10、所述第二网络为特征提取网络,用于输出所述二阶特征方差估计向量;其中,所述第一网络和所述第二网络为相同或者不同的独立结构。
11、所述对每次输出进行重参数化,具体计算为:
12、z=f+s*e, (1)
13、其中,z是重参数化结果,f和s分别是一阶特征向量和二阶特征方差估计向量,e是服从标准正态分布的伪随机数向量。
14、本发明构建一阶特征向量和二阶特征方差估计向量的相关关系,在训练中添加伪随机数向量作为噪声,能够避免训练过拟合,能够提高算法的鲁棒性,从而提高本算法在测试时的性能。
15、再进一步,所述根据信息瓶颈损失函数和重识别损失函数计算损失函数,所述损失函数的表达式为:
16、ltotal=lreid+λlib, (2)
17、其中,ltotal为总损失函数,lreid和lib分别为重识别损失函数和信息瓶颈损失函数,λ为所述信息瓶颈损失函数的影响因子。
18、本发明采用线性方程构建重识别损失函数和信息瓶颈损失函数的相关关系,通过信息瓶颈损失函数和重识别损失函数来训练神经网络,调整其权值,从而利用信息瓶颈理论挖掘行人视频片段数据中空间和时间上高判别性的特征信息将其保留,而且可以抑制视频的帧序列空间和时间中的干扰信息。
19、进一步,所述对所述第一一阶特征向量和所述第一二阶特征方差估计向量进行融合,得到第一特征提取向量。具体为:根据所述第一二阶特征方差估计向量,对所述第一一阶特征向量的每个维度上的值都进行加权修正,得到第一特征提取向量。
20、本发明通过在识别过程中,融合一阶特征向量和二阶特征方差估计向量,用二阶特征方差估计向量进一步优化一阶特征向量,能够进一步提升性能。
21、再进一步,所述获取待识别的视频片段,并将所述待识别的视频片段转换为第一视频帧数据,包括:
22、按顺序随机抽取t帧,作为图片序列输入神经网络;或者,
23、采用全部帧作为输入。
24、本发明采用对视频片段划分为视频帧,可以获得具有时间连续且空间特征连续的多张图片数据,初步获取到具有时空特征的粗糙的视频帧数据。
25、再进一步,所述将所述第一特征提取向量分别与数据库内存储的各视频片段所对应的第二特征提取向量进行比对,包括:
26、将所有视频片段转换为第二视频帧数据,将所述第二视频帧数据作为所述神经网络模型的输入,分别输出与所述第二视频帧数据对应的第二一阶特征向量和第二二阶特征方差估计向量,将所述第二一阶特征向量和所述第二二阶特征方差估计向量进行融合,得到第二特征提取向量,并将所述第二特征提取向量存入数据库中。
27、第二方面,本发明提供了一种信息瓶颈增强的视频行人重识别系统,所述系统包括:
28、视频帧获取模块,用于获取待识别的视频片段,并将所述待识别的视频片段转换为第一视频帧数据;
29、特征向量提取模块,用于将所述第一视频帧数据输入到训练好的信息瓶颈增强的神经网络模型中,以使所述神经网络模型输出所述第一视频帧数据所对应的第一一阶特征向量和第一二阶特征方差估计向量;其中,所述神经网络模型是以视频片段样本作为输入,以一阶特征向量和二阶特征方差估计向量作为输出,并对每次输出进行重参数化,根据信息瓶颈损失函数和重识别损失函数计算损失函数,进行若干次训练后而获得;
30、融合模块,用于对所述第一一阶特征向量和所述第一二阶特征方差估计向量进行融合,得到第一特征提取向量;
31、识别模块,用于将所述第一特征提取向量分别与数据库内存储的各视频片段所对应的第二特征提取向量进行比对,从大到小选取若干个相似度所对应的第二特征提取向量所对应的视频片段作为视频行人重识别的结果。
32、第三方面,本发明提供了一种信息瓶颈增强的视频行人重识别存储介质,所述存储介质存储有一个或者多个程序,所述一个或者多个程序被处理器运行时,执行如第一方面所述的信息瓶颈增强的视频行人重识别方法的步骤。
33、本发明在基本不修改原有视频行人重识别模型的情形下,通过增加特征方差估计向量和重参数化操作,进一步引入信息瓶颈训练整个模型,易于开发使用,能够减少一次提取的特征向量中的冗余信息,提高提取特征的精度,能够通过二阶特征方差估计向量进一步优化特征向量进行融合,提升性能。
- 还没有人留言评论。精彩留言会获得点赞!