一种具有可学习辅助惩罚和增强判别器的图像生成方法
1.本发明属于数据信息处理技术领域,涉及一种具有可学习辅助惩罚和增强判别器的图像生成方法。
背景技术:
2.针对基于生成对抗网络合成图像质量不佳的问题,现有的变体模型可以分为三类,即基于网络结构的变体模型、基于损失函数的变体模型、基于训练技术的变体模型。首先,基于网络结构的变体模型包括基于深度卷积网络的dcgan模型、结合自编码器的cvae-gan模型、基于级联结构的progressivegan模型、基于注意力机制的sagan模型以及多生成器和判别器的模型。其次,基于损失函数的变体模型包括基于wasserstein距离的wgan模型、基于均方误差的lsgan模型、基于hinge损失的sngan、基于相对概念的relativisticgan模型以及基于fisher概率积分的fishergan模型。最后,基于训练技术的变体模型包括批量正则化实例正则化、自适应实例正则化、谱正则化以及双时间尺度更新规则。
3.目前的现有技术普遍存在以下问题:当训练gans时,可以观察到一些输入导致生成器和判别器的损失值突然变化,它们的损失曲线剧烈振荡。这种不稳定的训练过程导致生成图像质量较差。因此,在生成图像的过程中,如何提高模型训练的稳定性十分关键。进一步地,如何提高模型训练的稳定性存在以下两个亟待解决的问题:首先,如何设计约束生成器的惩罚项,减少生成器训练的不稳定性;其次,为了减少判别器训练的不稳定性,如何设计判别器。
技术实现要素:
4.有鉴于此,本发明的目的在于提供一种具有可学习辅助惩罚和增强判别器的图像生成方法,在该方法中首先设计了一种可学习的辅助模块,用于构造约束生成器的惩罚项;其次,设计了一种增强判别器,用于甄别真实图像、生成图像以及可学习辅助模块输出的真伪;最后,通过设计的惩罚项和增强判别器来稳定生成对抗网络的训练过程,以此提高图像生成的质量。
5.为达到上述目的,本发明提供如下技术方案:
6.一种具有可学习辅助惩罚和增强判别器的图像生成方法,该方法包括以下步骤:
7.s1:设计可学习的辅助模块,用于构造约束生成器的惩罚项;
8.s2:设计一种增强判别器,用于甄别真实图像、生成图像以及可学习辅助模块输出的真伪;
9.s3:通过步骤s1中设计的惩罚项和步骤s2中的增强判别器来稳定生成对抗网络的训练过程,以此提高图像生成的质量。
10.进一步,步骤s1中,所述可学习的辅助模块由解码器的输出、调节参数α以及生成器的输出构成;其中,解码器由多层反卷积或上采样组成,调节参数α是手动选择的参数,可学习的辅助模块的输出lr表示为:
11.lr=g(z)+α*δ,
ꢀꢀ
(1)
12.δ=decoder(z
′
),
ꢀꢀ
(2)
13.其中,lr表示可学习辅助模块的输出;g表示生成器;δ表示生成的噪声;decoder表示解码器;z和z
′
均是来自高斯分布的随机噪声;g(z)表示生成的图像。为方便数据处理,随机采样噪声的每个维度被映射到0和1之间,进行正则化处理,如下:
[0014][0015]
进一步,在步骤s2中,首先,使用编码器en对可学习的辅助模块的输出lr进行编码;然后最小化对应的编码和输入噪声之间的均方误差,以此构成惩罚项p;可学习的辅助惩罚项p具体计算表达式为:
[0016]
p=||en(lr)-z||2.
ꢀꢀ
(4)
[0017]
在本方案中,直接把这个惩罚加到生成器的损失函数中;因此,具有可学习辅助惩罚的生成器的损失函数为:
[0018][0019]
其中,表示生成器的损失函数;e表示期望;z~pz表示从高斯分布随机采样的噪声;d表示判别器;β为辅助惩罚的参数。通过设计这种辅助惩罚,生成器能够在训练过程中自适应地处理输入噪声,降低系统的不稳定性;在求解过程中,将最小化
[0020]
进一步,在步骤s3中,对于原始的生成对抗网络而言,判别器的能力受到其训练过程的影响。其训练过程难以实现稳定的训练。最终,它影响了生成图像的质量。因此,为了从判别器方面稳定训练过程,本方案设计了一个可学习的增强鉴别器,具体的,在本方法设计的模型中,将生成的图像、真实图像以及可学习辅助模块的输出用于训练判别器;因此,设计的增强判别器的损失函数包括三个部分,即识别真实样本、生成样本和可学习辅助模块的输出,计算方法如下:
[0021][0022]
其中,表示判别器的损失函数;x~p
data
表示从真实图像集合中随机采样的真实样本;g(z)表示生成的图像;lr是来自可学习辅助模块的输出;lr~p
lr
表示从可学习模块输出集合中采样的样本。当求解模型时,将最大化
[0023]
本发明的有益效果在于:
[0024]
本发明针对基于生成对抗网络的图像生成方法存在难以训练的问题,提出了一种新的训练机制:首先,巧妙地将辅助噪声输入到可学习辅助模块中;然后利用可学习辅助模块输出的编码与输入噪声设计惩罚项约束生成器;接着将真实图像、生成的图像以及可学习辅助模块输出一起训练增强判别器。由此可知,本方案设计的惩罚项约束了生成器,其训练过程更加稳定;此外,由于训练增强判别器的样本增加了,其稳定性也得到了提升;最后,本方案还可以应用到hinge损失函数和均方差损失函数中。
[0025]
由于本方案能够生成图像,为此本方案可以用来扩充人脸、车牌等数据样本,节省收集数据样本所带来的人力和物力的开销。此外,生成的图像可以视为视频中的帧,因此也可以用于生成视频。最后,图像生成方法可以生成对抗样本去攻击现有的深度学习模型,这
样能够检测出现有深度学习模型的漏洞,预防深度学习模型的漏洞,以此提高深度学习模型的鲁棒性和可靠性。综上所述,本方案具有广泛的应用领域和学术研究价值。
[0026]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0027]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0028]
图1为本发明所述方法的模型示意图。
具体实施方式
[0029]
下面结合附图对本发明技术方案进行详细说明。
[0030]
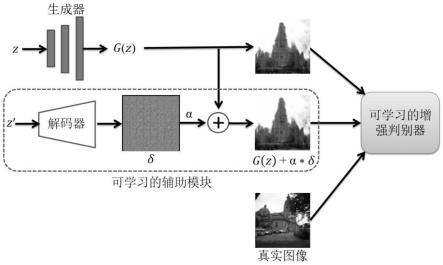
图1为本发明所述方法的模型示意图,如图所示,在本方法中,首先设计了一种可学习的辅助模块,用于构造约束生成器的惩罚项。其次,设计了一种增强判别器,用于甄别真实图像、生成图像以及可学习辅助模块输出的真伪。最后,通过设计的惩罚项和增强判别器来稳定生成对抗网络的训练过程,以此提高图像生成的质量。
[0031]
具体包括:1)可学习的辅助模块
[0032]
可学习的辅助模块由解码器的输出、调节参数α以及生成器的输出构成。其中,解码器由多层反卷积或上采样组成。调节参数α是手动选择的参数。因此,可学习的辅助模块的输出lr可以表示为:
[0033]
lr=g(z)+α*δ,(1)
[0034]
′
[0035]
δ=decoder(z),(2)
[0036]
其中,z和z
′
均是来自高斯分布的随机噪声。为方便数据处理,随机采样噪声的每个维度被映射到0和1之间,进行正则化处理。如下:
[0037][0038]
2)可学习的辅助惩罚
[0039]
首先,使用编码器en对可学习的辅助模块的输出lr进行编码。然后最小化对应的编码和输入噪声之间的均方误差,以此构成惩罚项p。可学习的辅助惩罚项p具体计算表达式为:
[0040]
p=en(lr)-z2.(4)
[0041]
在本方案中,直接把这个惩罚加到生成器的损失函数中。因此,具有可学习辅助惩罚的生成器的损失函数为:
[0042][0043]
其中,β为辅助惩罚的参数。通过这种巧妙设计的辅助惩罚,生成器可以在训练过程中自适应地处理输入噪声,降低了系统的不稳定性。在求解过程中,将最小化
[0044]
3)可学习的增强判别器
[0045]
对于原始的生成对抗网络而言,判别器的能力受到其训练过程的影响。其训练过程难以实现稳定的训练。最终,它影响了生成图像的质量。因此,为了从判别器方面稳定训练过程,本方案设计了一个可学习的增强鉴别器。具体的,在所设计的模型中,将生成的图像、真实图像以及可学习辅助模块的输出用于训练判别器。因此,设计的增强判别器的损失函数包括三个部分,即识别真实样本、生成样本和可学习辅助模块的输出。计算方法如下:
[0046][0047]
其中,lr是来自可学习辅助模块的输出。当求解模型时,将最大化
[0048]
在本实施例中,为了测试本方法的有效性,本实施例在lsun和celeba数据集中进行试验,并将gans、wgan、wgan-sn、sagans和lsgans方法作为实验的对比方法。在本实施例中,本发明所述方法带有
“‑dlr-p”后缀名。首先,关于模型训练稳定性评价方面,使用变异系数(coefficientofvariation,cv)来刻画判别器和生成器训练过程中的稳定性。变异系数越小,则表明训练过程中越稳定。在lsun数据集中的实验结果如表1所示。由此可知,本发明的方法分别提高了判别器和生成器训练过程中的稳定性。因此,整个模型训练的稳定性可到提升。
[0049]
表1变异系数测试结果。
[0050]
方法判别器的变异系数生成器的变异系数gans80.8358%40.6756%gans-d
lr-p79.1931%14.4585%lsgans113.4347%14.0093%lsgans-d
lr-p93.6716%9.6673%
[0051]
其次,关于生成图像质量评价方面,使用fid和amt指标来刻画生成图像的质量。其中,fid值越小,则表明生成图像质量越好。amt值越大,则表明生成图像质量越好。实验统计结果如表2所示。由此可知,与对比方法相比,本发明方法能够生成更好质量的图像。
[0052]
表2生成图像质量评价统计结果。
[0053][0054]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1