一种基于特征融合的类别文本生成系统
1.本发明涉及类别文本生成领域,具体涉及一种基于特征融合的类别文本生成系统。
背景技术:
2.类别文本生成旨在自动生成不同属性的连贯且有意义的文本,多类别多情感的文本生成可以使机器更加智能化,从而实现更好的人机交互效果。类别文本生成可以广泛地应用于对话系统、情感分析任务的数据集构建、评论文本生成等领域,为人们提供便捷自动化的工具,降低人工撰写文本的开销。
3.类别文本生成是文本生成领域的一个子任务,传统文本生成方法主要基于规则模板,通过内容规划、句子规划和语言实现完成文本生成工作,随后基于概率统计的文本生成方法也被广泛应用,该方法将词与上下文的关系编码成条件概率,从概率统计的角度出发来进行文本生成。随着深度学习的迅速发展,当前大多数类别文本生成工作不再使用传统文本生成方法,而是使用深度学习方法来提高模型的泛化能力。
4.目前基于深度学习的类别文本生成模型主要可以分为以下三类:基于序列到序列模型(sequence-to-sequence,seq2seq)、基于变分自编码器(variational auto-encoders,vae)和基于生成对抗网络(generative adversarial networks,gan):
5.基于序列到序列模型的类别文本生成模型通过编码器-解码器模型将输入序列通过编码器编码为中间向量,然后通过解码器将中间向量解码为输出序列。目前有研究人员采用集束搜索生成数个备选序列,并基于某些规则来排序得到最好结果。还有研究者在seq2seq模型的基础上引入lda模型来得到文本主题,以生成多样性更好的类别文本。尽管该类模型的应用较为广泛,但加入额外的类别信息较为困难,生成文本的类别准确度有限。
6.基于变分自编码器的类别文本生成模型先将输入文本编码为隐向量,再根据隐变量重构输入文本以训练模型参数。然而,训练vae模型的最大难点是kl散度崩溃问题,研究人员通过引入一个权重来控制kl项,并在训练过程中使该权重逐渐增大来缓解kl散度崩溃问题。此外,研究者提出了一种基于规划的层次变分模型,利用多层网络结构学习高层语义特征和局部特征,在长文本生成中取得较好效果。此类方法虽然在缓解kl散度奔溃问题上取得了一定的进展,但该问题仍是一项挑战,生成文本的质量也受到限制。
7.基于生成对抗网络的类别文本生成模型通过生成器与判别器间的交替对抗训练,使生成器生成的文本尽可能拟合真实文本的分布,让判别器无法区分,从而提升生成文本质量。研究人员提出一种由多个生成器和一个多类别判别器组成的gan,通过建立一个基于惩罚的目标函数传递类别信息,使每个生成器可以生成特定类别的文本。在上述方法的基础上,研究人员提出在模型的训练过程中引入层次进化学习算法,通过进化、评估、筛选得到生成文本质量最高的模型优化方向。但是此类方法对于文本语义特征的提取较为片面,难以获得兼顾质量和多样性的文本,因此人们希望能够找到一种更加高效的类别文本生成方法,生成更加流畅且准确的类别文本。
技术实现要素:
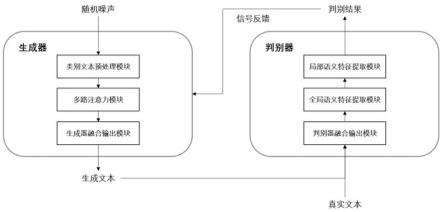
8.本发明的目的在于提供一种基于特征融合的类别文本生成系统,对于生成器,利用改进型多路注意力机制从多角度提取句子的语义特征关系,并通过双向gru有效融合多路注意力特征以输出生成文本;对于判别器,在局部语义特征提取模块的基础上引入全局语义特征提取模块,将综合判别结果反馈给生成器,使其生成高质量的类别文本。
9.为实现上述目的,本发明的技术方案是:一种基于特征融合的类别文本生成系统,包括:
10.一个类别文本预处理模块,用于对类别文本的向量化处理;
11.一个多路注意力模块,在生成器中利用多种注意力机制学习文本的多种注意力表示;
12.一个生成器融合输出模块,将多种注意力表示融合并输出生成文本;
13.一个局部语义特征提取模块,用于判别器提取文本的局部依赖特征;
14.一个全局语义特征提取模块,用于判别器提取文本的长距离依赖特征;
15.一个判别器融合输出模块,将文本的局部和长距离依赖特征融合并反馈给生成器判别结果。
16.在本发明一实施例中,所述类别文本预处理模块将分词后的文本数据转换为one-hot编码的向量形式,并引入附加类别信息,通过嵌入层形成输入向量。
17.在本发明一实施例中,所述多路注意力模块运用多头自注意力机制、拼接注意力机制和点乘注意力提取不同种类的注意力信息,从不同角度提取句子中单词与单词间的特征关系。
18.在本发明一实施例中,所述生成器融合输出模块基于双向gru来动态融合多路注意力特征,学习注意力之间在高维空间的表征关系,形成综合多角度考虑的特征向量,使用gumbel-softmax生成离散文本的近似采样,解决生成对抗网络直接采样时的梯度消失问题以输出生成文本。
19.在本发明一实施例中,所述局部语义特征提取模块,采用不同尺寸的卷积核对每个生成文本和真实文本进行特征提取,对通过最大池化后的各个特征图进行拼接,从而获得局部上下文依赖特征。
20.在本发明一实施例中,所述全局语义特征提取模块采用双向gru对句子进行全局语义特征提取,从而获取句子中的长距离上下文依赖特征,弥补卷积神经网络无法充分捕获文本全局语义信息的不足。
21.在本发明一实施例中,所述判别器融合输出模块将局部语义特征和全局语义特征相融合,通过高速神经网络使更多梯度信息得以回传,并将判别结果作为学习信号反馈给生成器,使生成器生成更可能骗过判别器的高质量类别文本。
22.相较于现有技术,本发明具有以下有益效果:本发明对于生成器,利用改进型多路注意力机制从多角度提取句子的语义特征关系,并通过双向gru有效融合多路注意力特征以输出生成文本;对于判别器,在局部语义特征提取模块的基础上引入全局语义特征提取模块,将综合判别结果反馈给生成器,使其生成高质量的类别文本。
附图说明
23.图1为本发明一种基于特征融合的类别文本生成系统框图。
24.图2为本发明一种基于特征融合的类别文本生成系统示意配置图。
具体实施方式
25.下面结合附图,对本发明的技术方案进行具体说明。
26.如图1、2所示,本发明一种基于特征融合的类别文本生成系统,包括:类别文本预处理模块1,用于对类别文本的向量化处理;多路注意力模块2,在生成器中利用多种注意力机制学习文本的注意力表示;生成器融合输出模块3,将多种注意力表示融合,并解决生成对抗网络中直接采样造成的梯度消失问题,输出生成文本;局部语义特征提取模块4,用于判别器提取文本的局部依赖特征;全局语义特征提取模块5,用于判别器提取文本的长距离依赖特征;判别器融合输出模块6,将文本的局部依赖特征和长距离依赖特征融合,并反馈给生成器判别结果。下面分别详细描述各模块配置。
27.1)类别文本预处理模块1
28.首先,描述类别文本预处理模块1如何得到附加了类别信息的初始文本向量。
29.神经网络的输入数据一般为向量,为便于模型的端到端训练,需要对文本数据进行向量化表示。在文本预处理阶段,先对源文本进行分词,再将分词后的文本数据转换为one-hot编码的向量形式以便后续的嵌入编码处理。在训练阶段,先采用序列生成的方法将上一时间步的生成词y
t-1
通过嵌入层转换为词嵌入接着将类别信息c编码成类别嵌入ec,并把两个嵌入表示拼接,最后通过参数矩阵w
x
,生成当前时间步附加了类别信息的输入向量x
t
:
[0030][0031]
2)多路注意力模块2
[0032]
下面描述在生成器中,多路注意力模块2如何处理上一模块得到的输入向量。此模块融合了多种注意力机制,包括:多头自注意力、点乘注意力和拼接注意力。这种新编码机制可以解决以往模型的生成器因不能从多角度提取语义特征,而使语义信息提取片面的问题,从而生成语义更多样,丰富度更高的类别文本。
[0033]
首先,描述多头自注意力机制。本发明的生成器基于关系存储核心网络实现(relational memory core,rmc),其引入了存储矩阵m
t
对文本的上下文信息进行记忆。具体而言,利用上一时间步得到的存储矩阵m
t-1
和当前输入向量x
t
,构成n组query、key和value,通过多头自注意力机制来提取文本自身的语义特征。在计算过程中,和分别作为query、key和value,和分别为第i组query、key和value的权重矩阵,dk代表key的列维度,将n组自注意力结果拼接后最终生成当前时间步的多头自注意力结果计算公式如下:
[0034]
[0035][0036]
对于拼接注意力机制,和代表拼接注意力的权重矩阵,为权重向量,代表t时刻第i个单词的注意力,n是句子的最长单词数,代表t时刻单词i的权重,最终生成当前时间步的拼接注意力表示具体计算过程如下:
[0037][0038][0039][0040]
点乘注意力机制的计算过程与拼接注意力机制类似,但计算每个单词权重的方式略有不同。点乘注意力机制中wd代表点乘注意力的权重矩阵,为权重向量,代表t时刻第i个单词的注意力,代表t时刻单词i的权重,最终生成当前时间步的点乘注意力表示
[0041][0042][0043][0044]
3)生成器融合输出模块3
[0045]
下面描述在生成器中,模块3如何将模块2中得到的三种注意力表示融合,形成充分考虑多路特征间交互关系的文本表示,并通过gumbel-softmax方法解决在生成对抗网络中直接进行采样导致的梯度消失问题,最终输出生成文本。
[0046]
本发明基于双向门控循环网络(gate recurrent unit,gru)动态融合每路语义特征,以综合多头自注意力、拼接注意力、点乘注意力表示在高维空间的表征关系,充分学习各注意力之间的内在关系,形成综合多角度考虑的特征向量。在gru网络的更新过程中,x
t
和h
t
分别代表网络的输入和输出,wz、wr、wh为可训练参数,σ为sigmoid激活函数,z
t
和r
t
分别为更新门和重置门,
⊙
为阿达玛积,具体计算过程如下:
[0047]zt
=σ(wz[h
t-1
,x
t
])
[0048]rt
=σ(wr[h
t-1
,x
t
])
[0049][0050][0051]
在多路特征动态融合的过程中,为三种注意力特征拼接后的表征向量,将输入到上述的双向gru网络中,从前向和后向分别捕捉多路特征之间的差异化信息和拼接得到当前时间步的综合注意力信息具体计算过程如下:
[0052][0053][0054][0055][0056]
将综合注意力信息经过多层感知机(multilayer perceptron,mlp),获得中间存储矩阵再通过rmc的门控机制,得到当前时间步的存储矩阵m
t
及输出向量o
t
,公式中ψ1和ψ2代表rmc的门控操作,计算过程如下:
[0057][0058][0059][0060]
最后描述如何使用输出向量o
t
采样并输出生成文本。因为文本是离散数据,在生成对抗网络中直接采样输出文本,则梯度信息是不可微的,从而导致梯度消失问题。本发明使用gumbel-softmax来生成离散的生成文本y
t
及其基于argmax函数的可微近似来解决该问题:
[0061][0062][0063]
其中,g
t
代表gumbel分布,d表示第d维。τ为温控参数,用来控制近似离散采样y
t
的程度,同时控制生成文本质量和多样性之间的平衡。
[0064]
4)局部文本特征提取模块4
[0065]
在模型的判别器中,本发明将具有强大局部特征捕获能力的卷积神经网络(convolutional neural networks,cnn)作为局部文本特征提取模块,并使用多尺寸卷积核对真实文本和生成文本进行局部特征提取。记所有文本中最长句子单词数为l
max
,每个单词的词嵌入维度为le,则句子的向量表示为接着,使用不同大小的卷积核ci对句子矩阵进行卷积操作,获得当前卷积核下的特征图mi,其中b为偏置向量,relu为激活函数:
[0066][0067]
对每个特征图mi执行最大池化操作,以保留该特征图最突出的判别特征。最后将经过最大池化后的所有特征图maxpool(mi)拼接,获得局部文本特征表示m:
[0068]
m=[maxpool(m1);maxpool(m2);
···
]
[0069]
5)全局文本特征提取模块5
[0070]
本发明的判别器在模块4的基础上额外设置全局文本特征提取模块,基于双向gru网络对句子进行全局语义特征提取,获取句子中的长距离上下文依赖关系,以此来弥补卷积神经网络无法充分捕获文本全局语义信息的不足。具体而言,通过模块3中描述的双向gru网络提取句子的向量表示ey的分类特征,得到全局文本特征表示hn:
[0071]hn
=gru(ey)
[0072]
6)判别器融合输出模块6
[0073]
将模块4中得到的局部文本特征m与模块5中得到的全局文本特征hn相融合,并通过relu得到句子总体特征表示z。
[0074]
z=relu(m+hn)
[0075]
随着全局文本特征提取模块的引入,含有单词间依赖的上下文信息增加,而单词自身的语义信息减少。为了更好的利用文本自身的语义信息,本发明引入高速网络(highway networks),在总体特征表示z的基础上获得更多低层次的语义特征,同时使更多梯度信息回流。最后,将高速网络得到的文本特征通过基于mlp的特征输出层,输出文本的判别结果作为学习信号反馈给生成器,使生成器生成更可能骗过判别器的高质量类别文本。
[0076]
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1