一种文本审核的方法和装置与流程
1.本发明涉及的是一种文本审核的方法和装置,涉及计算机多媒体信息处理技术领域。
背景技术:
2.在文本信息审核技术领域中,现有技术的方案一般是通过敏感词匹配或者神经网络的方法。其中通过敏感词匹配是指原文中出现某个敏感词就判定为违规,这种方法非常高效。通过神经网络的方法是指将原文先进行预处理,如分词、向量化等,再输入到训练好的神经网络中,最终网络会输出是否违规或者某个分类的标签。
3.单独依赖敏感词匹配的方法虽然高效,但是存在误判或者漏判的情况,比如某词在涉黄上下文中通常是个违规词,但是正常语境中也会用到,这种词如果作为敏感词就有可能导致误判,如果不作为敏感词就有可能导致漏判。
4.如果采用神经网络的方法,网络通常会通过上下文语义而不是某个词去判定是否违规,准确性相较敏感词的方法会高一点,但是也有可能会误判或漏判,比如在长段正常文本中插入几个违规的词,这种情况神经网络大概率会判为正常文本,而且因为神经网络通常计算量比较大,同等硬件条件下审核效率较低。
5.cn112434522a公开了一种降低敏感词误警率的文本审核后处理装置及方法,需要设置敏感多义消歧词库,同样存在可能漏判的问题。
技术实现要素:
6.本发明提出的是一种文本审核的方法和装置,其目的旨在克服现有技术存在的上述不足,结合敏感词匹配方法和神经网络审核方法来减少漏判或误判的情况,并提高系统审核效率。
7.本发明的技术解决方案:将敏感词在原有分类基础上继续划分为确信词和疑似词两大类,审核时先进行敏感词匹配,如果匹配到确信词,则直接判定为违规,如果匹配到疑似词,则通过神经网络继续判定其分类,如果网络输出分类(如涉黄、涉政等)与疑似词所在分类一致,则判定为违规,否则判定为正常。该方法通过结合敏感词匹配方法和神经网络审核方法来减少漏判或误判的情况,同时因为不是所有文本都需要经过神经网络,所以相较纯神经网络的方法能够提高系统审核效率。具体的,包括以下步骤:
8.步骤1:对输入文本进行预处理,包括繁体转简体、大写转小写、全角转半角等,文本预处理有利于对各种敏感词的变体进行识别,能降低漏判情况。
9.步骤2:对文本进行分词,采用jieba中文分词工具进行分词。
10.步骤3:对分词结果与敏感词词库进行匹配,得到敏感词集合s及其分类。
11.步骤4:如果集合s为空则直接输出文本正常,如果s不为空,则继续执行以下步骤。
12.步骤5:如果s中存在确信词,则直接输出文本违规。否则,将整个文本输入到训练好的fasttext神经网络模型中。
13.步骤6:fasttext神经网络对输入文本进行预测,得到文本的分类及概率值,分别记为l和p。
14.步骤7:如果l和s中某个疑似词所属的分类一致且p大于某个阈值t则输出文本违规,否则输出文本正常。
15.本发明的优点:1)相较现有技术单纯依赖敏感词匹配或者单纯采用神经网络的方法能够提高准确率,减少漏判或误判的情况;
16.2)并非所有文本都需要经过神经网络模型,在一定程度上提高了系统整体的审核效率。
附图说明
17.图1是本发明文本审核装置的结构框图。
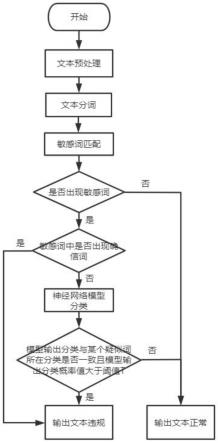
18.图2是本发明文本审核方法的流程图。
具体实施方式
19.下面结合实施例和具体实施方式对本发明作进一步详细的说明。
20.如图1所示,一种文本审核装置,包括决策模块、敏感词匹配模块和神经网络模块,决策模块分别与敏感词匹配模块和神经网络模块双向信号连接,
21.决策模块用于对文本审核的流程进行管理,决定文本审核任务需要流经的模块,并最终输出审核结果。
22.敏感词匹配模块用于找出文本中出现的敏感词。
23.神经网络模块用于对文本进行分类,并输出文本分类标签,如:涉政、涉黄等等,该模块采用fasttext神经网络模型,该模型网络结构简单,效率较高。
24.如图2所示,一种文本审核方法,将敏感词划分为确信词和疑似词,如果出现确信词则直接判定为违规,否则结合神经网络模型分类结果进一步判断,具体包括以下步骤:
25.步骤1:对输入文本进行预处理,包括繁体转简体、大写转小写、全角转半角等,文本预处理有利于对各种敏感词的变体进行识别,能降低漏判情况。
26.步骤2:对文本进行分词,采用jieba中文分词工具进行分词。
27.步骤3:对分词结果与敏感词词库进行匹配,得到敏感词集合s及其分类。
28.步骤4:如果集合s为空则直接输出文本正常,如果s不为空,则继续执行以下步骤。
29.步骤5:如果s中存在确信词,则直接输出文本违规。否则,将整个文本输入到训练好的fasttext神经网络模型中。
30.步骤6:fasttext神经网络对输入文本进行预测,得到文本的分类及概率值,分别记为l和p。
31.步骤7:如果l和s中某个疑似词所属的分类一致且p大于某个阈值t则输出文本违规,否则输出文本正常。
32.实施例
33.例如“插入”这个词,在涉黄上下文中通常是个违规词,但是正常语境中也会用到,比如“插入门卡”,所以“插入”这个词属于涉黄疑似词;而“出售卡洛因”则属于违禁确信词。如果审核文本中出现“出售可卡因”这个词,则直接返回文本违规,如果审核文本中出现“插
入”这个词,则继续通过神经网络模型判断文本所属类别,如果模型输出类别为涉黄,说明与疑似词的所属类别一致,由此判定为文本违规,否则判定为文本正常。
34.以上所述的仅是本发明的优选实施方式,应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
技术特征:
1.一种文本审核装置,其特征在于,包括决策模块、敏感词匹配模块和神经网络模块,决策模块分别与敏感词匹配模块和神经网络模块双向信号连接,决策模块用于对文本审核的流程进行管理,决定文本审核任务需要流经敏感词匹配模块或神经网络模块,并最终输出审核结果,敏感词匹配模块用于匹配识别文本中出现的敏感词,神经网络模块用于对文本进行分类,并输出文本分类标签。2.如权利要求1所述的一种文本审核装置,其特征在于,所述的神经网络模块为fasttext神经网络模型。3.如权利要求2所述的一种文本审核装置的文本审核方法,其特征在于,将敏感词划分为确信词和疑似词,如果出现确信词则直接判定为违规,否则由神经网络模型分类结果判断是否违规。4.如权利要求3所述的一种文本审核装置的文本审核方法,其特征在于,包括以下步骤:步骤1:对输入文本进行预处理,包括繁体转简体、大写转小写、全角转半角;步骤2:对文本进行分词,采用jieba中文分词工具进行分词;步骤3:对分词结果与敏感词词库进行匹配,得到敏感词集合s及其分类;步骤4:如果集合s为空则直接输出文本正常,如果s不为空,则继续执行步骤5;步骤5:如果s中存在确信词,则直接输出文本违规,否则将整个文本输入到训练好的fasttext神经网络模型中;步骤6:fasttext神经网络对输入文本进行预测,得到文本的分类及概率值,分别记为l和p;步骤7:如果l和s中某个疑似词所属的分类一致且p大于预设的阈值t则输出文本违规,否则输出文本正常。
技术总结
本发明是一种文本审核的方法和装置,将敏感词在原有分类基础上继续划分为确信词和疑似词两大类,审核时先进行敏感词匹配,如果匹配到确信词,则直接判定为违规,如果匹配到疑似词,则通过神经网络继续判定其分类,如果网络输出分类与疑似词所在分类一致,则判定为违规,否则判定为正常。该方法通过结合敏感词匹配方法和神经网络审核方法来减少漏判或误判的情况,同时因为不是所有文本都需要经过神经网络,所以相较纯神经网络的方法能够提高系统审核效率。本发明的优点:相较现有技术单纯依赖敏感词匹配或者单纯采用神经网络的方法能够提高准确率,减少漏判或误判的情况;有的文本无需经过神经网络模型,在一定程度上提高了系统整体的审核效率。系统整体的审核效率。系统整体的审核效率。
技术研发人员:苏许臣 黄建杰
受保护的技术使用者:央视国际网络无锡有限公司
技术研发日:2022.12.16
技术公布日:2023/3/20
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1