一种基于双路编码和精确匹配信号的观点检索系统
本发明涉及观点检索,特别是一种基于双路编码和精确匹配信号的观点检索系统。
背景技术:
1、随着web2.0在当今高速的发展,以及互联网的普及,互联网出现大量以社交为基础的平台(比如,知乎、新浪微博、b站等)。越来越多的人热衷于在社交媒体上发表和分享自己对热门信息的看法,这些社交平台已经成为人们表达自己观点的载体。通过分析这些观点信息可以了解到。以情感分析和信息挖掘(挖掘文本的观点信息)为目标的观点挖掘已经成为自然语言处理的领域的前言研究之一。网络文本观点检索是研究如何从大量的社交文本的文档中检索出与查询文本相关并且对检索出的文档有一定的主观倾向。针对文本观点检索课题的研究和讨论,引起了来自学术、工业以及各行业学者的广泛关注。文本观点检索模型的研究经历了早期的二阶段检索模型,到线性检索模型,最后到统一相关模型,这三个阶段。下面将对这三个阶段作简要介绍。
2、两阶段检索模型,首先检索出与给定查询话题相关的文档,然后识别出这些与给定查询相关文档的倾向性,最后综合相关性和倾向性对文档进行排序。该模型结构简单,容易理解,但是缺乏合理的理论解释。该方法第一阶段通常采用语言模型、bm25等经典检索模型,而将研究重点放在第二阶段,即文档的观点挖掘。
3、线性检索模型它们给了研究者们提供了新的思路,即用一个最终的指标对文档进行评分,这也促使了人们对统一观点检索模型的研究。不同于传统文档表示方法的主题-观点词表示方法,捕获句子内部观点词与其目标之间的上下文信息,同时考虑相同主题的多个观点词句子间的关系,将这两种信息合并到一个统一的图模型中,采用hits算法计算文档得分并排序。
4、统一检索模型,借助当前信息检索和文本挖掘领域的最新模型,直接挖掘描述主题的倾向性对文档进行排序。该方法相对于两阶段模型,具有在理论上易解释、对信息需求表达更直接有效等优点。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于双路编码和精确匹配信号的观点检索系统,通过双路编码来获取局部语义信息和全局语义信息,能够通过融合并基于这些信息进行观点检索,通过精确匹配机制获取的精确语义信息能够提高查询与文档的相关性。
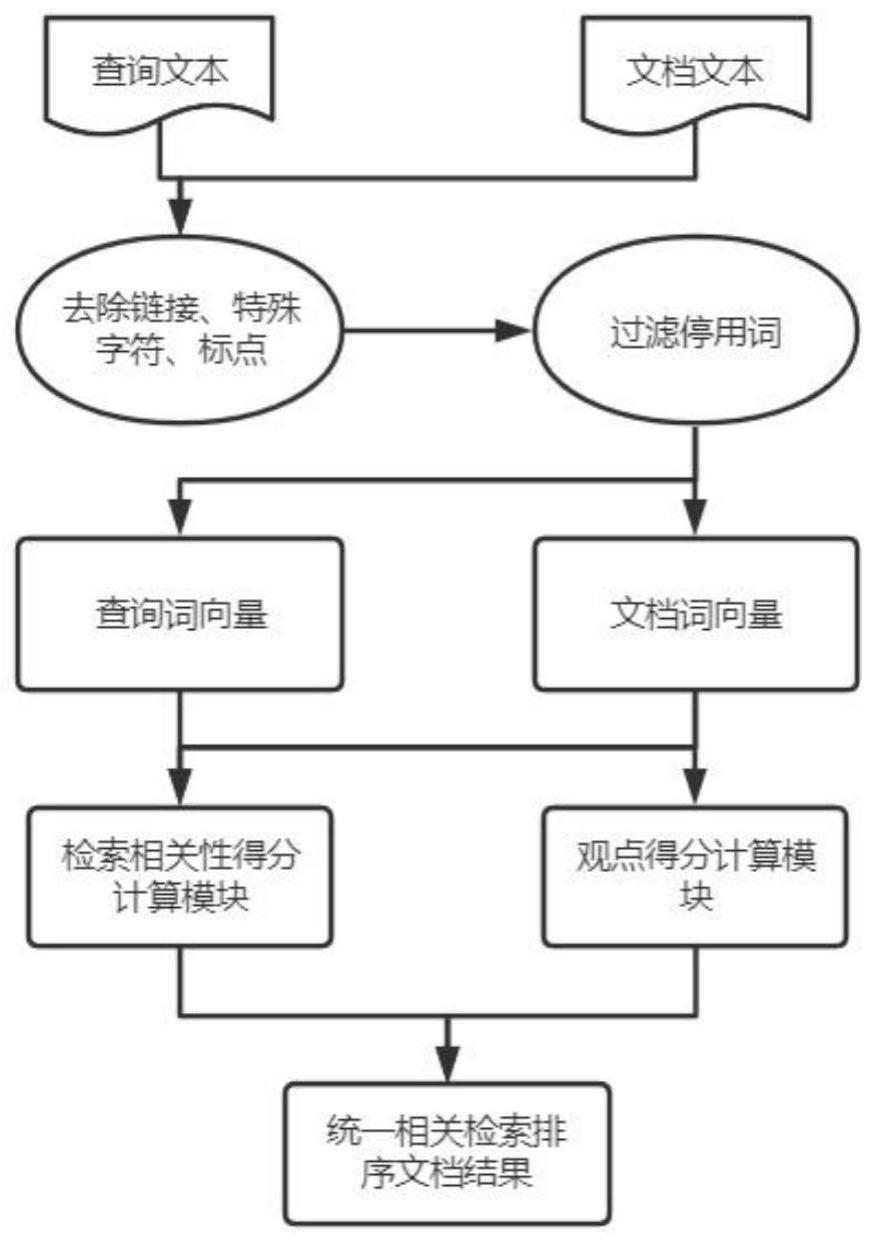
2、为实现上述目的,本发明采用如下技术方案:一种基于双路编码和精确匹配信号的观点检索系统,包括:
3、一个查询文本和文档文本预处理模块,对输入的查询和候选文档据进行预处理,主要对数据去除符号、表情、停用词等无关信息,以及对数据进行分词、编码和映射语义空间获得词向量和句表示向量;
4、一个查询文本和文档文本相关得分计算模块,通过transformer和循环神经网络lstm获取句子编码,然后把两路获取到的编码信息进行融合,将句子表示加入到精确匹配网络获取,获取精确匹配语义信息,最后将语义信息用高斯核池方法,获取查询和文档之间的相关得分;
5、一个查询文本和文档文本观点得分计算模块,通过预训练一个观点特征提取模型,通过预训练模型计算候选文档的观点得分;
6、统一相关检索模块,用于根据相关检索模块得出的查询和文档的相关得分和根据观点得分模块获取文档的观点得分,最终计算文档的观点检索得分,对文档进行排序,输出排序结果。
7、在一较佳的实施例中:查询文本和文档文本预处理模块,对查询和文档数据去除符号、表情、网络链接、停用词无关信息,以及对数据进行分词建立词表、编码和映射语义空间获得词向量和句表示向量。
8、在一较佳的实施例中:查询文本和文档文本相关得分计算模块由双路上下文编码层、上下文融合层、精确匹配层、卷积层、匹配层、核池化层及学习层组合而成;
9、双路上下文编码层由transformerencoder和lstm循环神经网络组成,根据输入词向量用于获取对应全局上下文语义表示和局部上下文语义表示的上下文向量;
10、transformerencoder公式如下:
11、x′=transformer(x)
12、transformer(x)=layernorm(layernorm(multiheadattention(ll(x))+x)+ffn(layernorm(multiheadattention(ll(x))+x))
13、ll(x)=linear(reli(linear(x)))
14、multiheadattention(x)=concat(h ead1,...,h eadh)wo
15、
16、linear(x)=xat+b
17、ffn(x)=max(0,xw1+b1)w2+b
18、
19、其中x为对应输入的词向量,multiheadattention为多头自注意力模块,relu为非线性激活函数,wi为需要模型学习的参数矩阵;
20、lstm公式如下表示:
21、ft=σ(wf·[ht-1,xt]+bf)
22、it=σ(wi·[ht-1,xt]+bi)
23、
24、
25、ot=σ(wo[ht-1,xt]+bo)
26、ht=ot*tanh(ct)
27、ti=ht
28、其中,σ表示logistic sigmoid函数;tanh表示hyperbolic tangent函数;wf、wi、wc、wo表示可训练的参数矩阵;bf、bi、bc、bo表示对应的偏置;it表示t时刻的输入门,决定当前时间步输入需要保留的信息;ft表示t时刻的遗忘门,用于控制历史细胞状态应该丢失的信息比例;ot表示t时刻的输出门,用于控制隐藏状态的输出;表示由非线性函数tanh计算出的当前输入特征;ct表示t时刻的记忆单元状态;ht表示t时刻的隐含层输出向量;
29、lstm结构根据上一时间状态计算当前节点状态,获取局部上下文语义信息;
30、x″=gate(linear(concat(transformer(x),lstm(x))))
31、gate(y)=tanh(w*(σ(w1*(y,h)+e(w2*(y,h))))
32、上下文融合层主要由全连接层模块和门控网络组成,全局上下文语义信息和局部上下文语义信息通过拼接的方式进行第一步融合,此时每个表示向量的维度变为原来的两倍,然后通过第一个全连接层对这些向量进行降维,每个表示向量的维度变回原来的维度,得到全局和局部的融合上下文表示向量,此时每个词语对应的上下文向量不仅包含自身单词的信息,还带有不同层次且丰富的上下文信息;wi为需要模型学习的参数矩阵,σ表示logistic sigmoid函数,y为拼接的语义信息,h为上一节点的隐藏状态,tanh()为双曲正切函数;
33、精确匹配层相关计算公式:
34、点积函数:最常用的计算方式,查询向量q和文档向量q直接进行点积运算得到相关性分数:
35、rel1(q,d)=qtd
36、缩放点积函数:查询向量q和文档向量d做点积运算后乘以缩放因子得到相关性分数,其中dim为查询向量q的维度:
37、
38、再通过
39、similar(q,d)
40、=linear(linear(concat(rel1,rel2)))+linear(q)
41、卷积层由若干个窗口大小不同的卷积核组成,通过这些卷积核可以在上一层获取到的融合局部上下文信息和全局上下文信息的基础上进一步获取输入文本中的相邻位置表示信息;
42、ch=relu(wh·x″+bh),i=1,2,...,n
43、其中h∈[1,n]为卷积核在词语维度的窗口大小,n=2,w为卷积核的参数矩阵;
44、匹配层根据上一层获得的n-gram信息,计算用户查询和候选文档之间的每个n-gram向量的相似度得分,构建查询-候选文档的交互矩阵:
45、
46、核池化层由k个高斯核函数组成,用于产生软交互特征,该层通过k个高斯核函数计算交互矩阵中k个强度级别的n-gram相似度得分,捕捉隐含的软交互特征φ(m):
47、
48、
49、
50、学习层通过学习根据上一层提取到的软交互特征,获得最终的相关得分relscore;
51、relscore(q,d)=sigmoid(linear(φ(m)))。
52、在一较佳的实施例中:查询文本和文档文本观点得分计算模块引入预训练模型,通过训练一个观点特征提取的预训练模型,引入大语料预训练模型bert的encoder结构,提取出文本的深层上下文语义信息,经过微调训练出符合本系统的观点特征提取器,从而得到候选文档的观点得分。
53、在一较佳的实施例中:统一相关检索模块,通过将文档和查询的相关得分与文档的观点得分通过统一观点检索模型进行融合,得到文档关于查询的观点检索得分,rankscore(q,d)=relscore(q,d)·opiscore(d),并根据所得文档的观点检索得分对所有的候选文档进行重新排序,并输出最终的排序的得分集合的结果。
54、与现有技术相比,本发明具有以下有益效果:能够通过循环神经网络lstm和基于多头注意力transformer来获取全局语义信息和局部语义信息,通过两者融合获更加丰富的文本数据的上下文语义信息,在由精确匹配机制获取到查询的精确语义信息,在由卷积神经网络得到文本数据的n-gram信息,对查询和文档进行余弦相似度计算,再将结果通过核池化方法,并基于这些方法实现较好的观点检索性能。以及包括一个观点特征提取的预训练模型,通过多层bert的encoder方法,提取深层的观点特征。对观点检索的性能有进一步的提升
- 还没有人留言评论。精彩留言会获得点赞!