视频时序动作检测方法、系统、电子设备及存储介质与流程
本公开的实施例属于动作识别,具体涉及一种视频时序动作检测方法、系统、电子设备及存储介质。
背景技术:
1、时序动作检测的主要目的是对某段视频的行为发生时段和行为类别进行预测,即推算出视频中什么时间段发生了什么行为。时间段预测主要是预测行为边界的起始点和结束点,即行为发生开始时间点和结束时间点,行为类型分类主要是识别某片段发生了哪种行为。
2、目前主流的时序动作检测网络主要仅通过计算机视觉(如视频)信息进行建模,如bmn,tcanet等。基于计算机视觉的算法主要由3d卷积网络和全连接层组成,一般情况下,3d卷积网络和全连接层的输入形状大小和输出形状大小在模型定义阶段已被固定,因此也固定了输入源数据的形状大小。若输入源数据的形状大小发生了变化,动作检测网络会无法处理数据。基于以上原因,目前较为先进的主流算法需要先将时序特征进行下采样,统一到动作检测网络所支持的时序长度,但下采样操作也会带来信息损失的问题。除此之外,cnn(卷积神经网络)具有局部性和空间归纳偏置,即cnn可将空间上相邻的特征进行联系,因此在局部空间上有强关联的数据(如图像)有较好的表现,但其无法建立远距离特征间的联系,因此在序列问题上性能较弱。
3、另一方面,现有的计算机视觉算法,仅能从视频数据中获取信息进行时序动作检测,准确率较低,具有较大局限性。并且目前大部分主流的时序动作检测算法是二阶段,需要先完成“动作提名网络”的训练或推理,才能进行“动作识别网络”的训练或推理。
技术实现思路
1、本公开的实施例旨在至少解决现有技术中存在的技术问题之一,提供一种视频时序动作检测方法、系统、电子设备及存储介质。
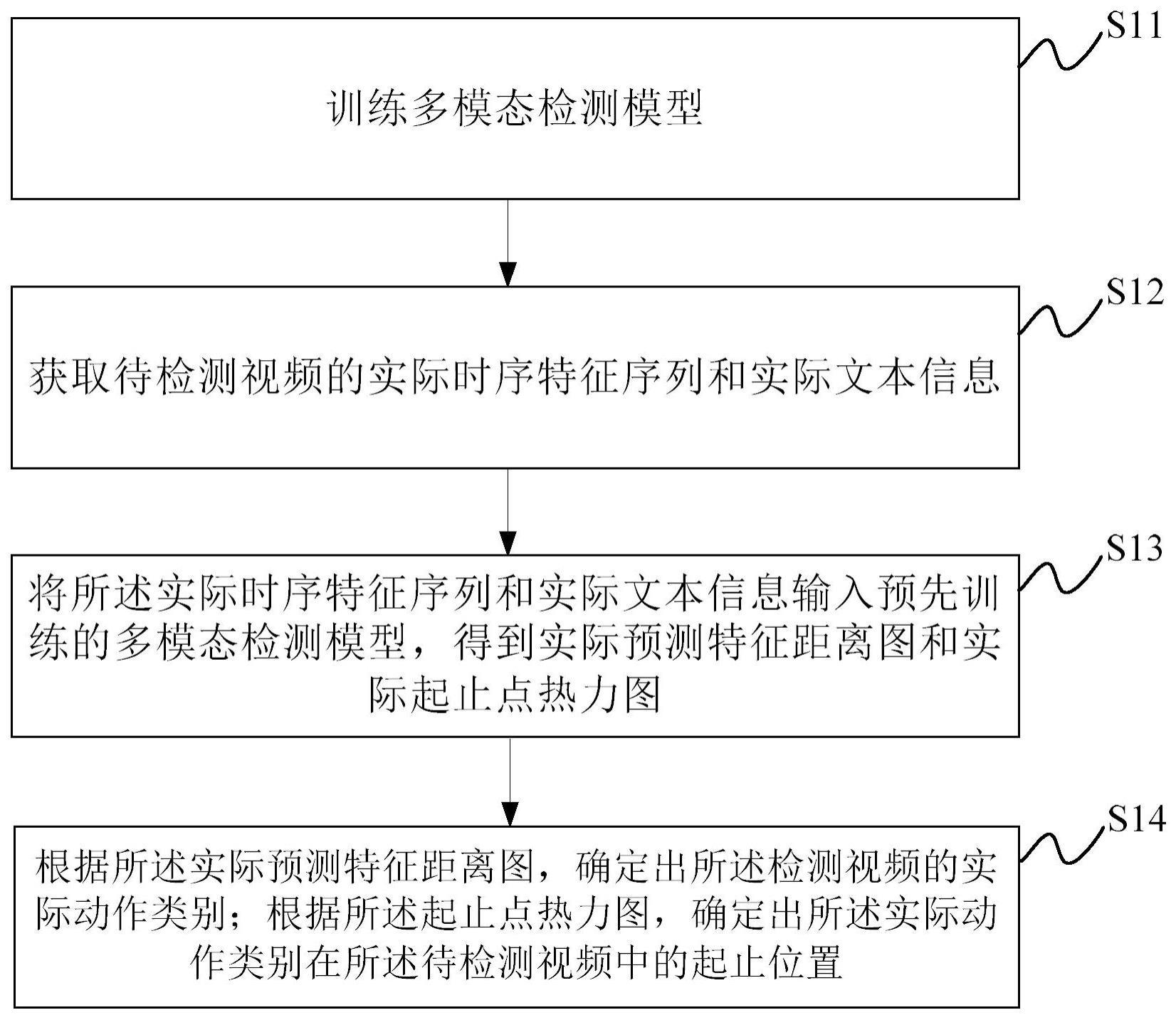
2、本公开的一个方面提供一种视频时序动作检测方法,包括:
3、获取待检测视频的实际时序特征序列和实际文本信息;
4、将所述实际时序特征序列和实际文本信息输入预先训练的多模态检测模型,得到实际预测特征距离图和实际起止点热力图;其中,所述预先训练的多模态检测模型是根据训练时序特征序列和预设的提示型文本描述库对自监督学习算法进行训练得到;
5、根据所述实际预测特征距离图,确定出所述检测视频的实际动作类别;以及,根据所述起止点热力图,确定出所述实际动作类别在所述待检测视频中的起止位置。
6、可选的,所述预先训练的多模态检测模型采用以下步骤训练
7、得到:
8、建立动作类别的所述提示型文本描述库;其中,所述提示型文本描述库包括通用型语句集和详述型语句集;
9、基于所述提示型文本描述库,得到分词组集;
10、获取训练视频的训练时序特征序列;
11、根据所述分词组集和所述训练时序特征序列通过自监督学习算法进行训练,得到所述多模态检测模型。
12、可选的,所述自监督学习算法包括编码模块、动作分类模块和动作时间边界匹配模块,所述编码模块包括视频编码器和文本编码器,所述动作分类模块包括视频mlp层和文本mlp层,所述动作时间边界匹配模块包括由mlp层构成的边界预测器;
13、所述根据所述分词组集和所述训练时序特征序列通过自监督学习算法进行训练,得到所述多模态检测模型,包括:
14、将所述训练时序特征序列和所述分词组集分别输入至所述视频编码器和所述文本编码器,分别得到视频编码和文本编码;
15、将所述视频编码和所述文本编码分别输入至所述视频mlp层和所述文本mlp层,分别得到视频网络编码和文本网络编码;
16、根据所述视频网络编码和所述文本网络编码,得到训练特征距离图;
17、将所述视频编码输入至所述边界预测器,得到初始训练起止热力图;
18、根据所述训练特征距离图和所述初始训练起止热力图,得到最终训练起止热力图。
19、可选的,所述根据所述训练特征距离图和所述初始训练起止热力图,得到最终训练起止热力图之后,所述方法还包括:
20、根据所述训练特征距离图和所述最终训练起止热力图,更新所述多模态检测模型的参数。
21、可选的,所述基于所述提示型文本描述库,得到分词组集,包括:
22、分别从所述通用型语句集和所述详述型语句集中获取多个通用型语句和多个详述型语句;
23、将所述多个通用型语句和所述多个详述型语句对应组合,形成多个组合语句;
24、对所述多个组合语句进行分词,得到分词组集。
25、本公开的另一个方面提供一种视频时序动作检测系统,包括:
26、获取模块:用于获取待检测视频的实际时序特征序列和实际文本信息;
27、输入模块:用于将所述实际时序特征序列和实际文本信息输入预先训练的多模态检测模型,得到实际预测特征距离图和实际起止点热力图;
28、检测模块:用于根据所述实际预测特征距离图,确定出所述检测视频的实际动作类别;以及,根据所述起止点热力图,确定出所述实际动作类别在所述待检测视频中的起止位置。
29、可选的,所述系统还包括训练模块,所述训练模块用于:
30、建立动作类别的所述提示型文本描述库;其中,所述提示型文本描述库包括通用型语句集和详述型语句集;
31、基于所述提示型文本描述库,得到分词组集;
32、获取训练视频的训练时序特征序列;
33、根据所述分词组集和所述训练时序特征序列通过自监督学习算法进行训练,得到所述多模态检测模型。
34、可选的,所述训练模块还用于:
35、根据所述训练特征距离图和所述最终训练起止热力图,更新所述多模态检测模型的参数。
36、本公开的另一方面提供一种电子设备,包括:
37、至少一个处理器;以及,
38、与所述至少一个处理器通信连接的存储器,用于存储一个或多个程序,当所述一个或多个程序被所述至少一个处理器执行时,能使得所述至少一个处理器实现如上所述的视频时序动作检测方法。
39、本公开的最后一方面提供一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的视频时序动作检测方法。
40、本公开的实施例采用vlm多模态预训练模型构建视频时序动作检测,并设计了一种关于动作的提示型文本描述库帮助检测模型的训练,可同时从视频的图像数据和文本数据中获取信息进行时序动作检测,准确率高,能更好地适应多种检测条件。
技术特征:
1.一种视频时序动作检测方法,其特征在于,所述方法包括:
2.根据权利要求1所述的视频时序动作检测方法,其特征在于,所述预先训练的多模态检测模型采用以下步骤训练得到:
3.根据权利要求2所述的视频时序动作检测方法,其特征在于,所述自监督学习算法包括编码模块、动作分类模块和动作时间边界匹配模块,所述编码模块包括视频编码器和文本编码器,所述动作分类模块包括视频mlp层和文本mlp层,所述动作时间边界匹配模块包括由mlp层构成的边界预测器;
4.根据权利要求3所述的视频时序动作检测方法,其特征在于,所述根据所述训练特征距离图和所述初始训练起止热力图,得到最终训练起止热力图之后,所述方法还包括:
5.根据权利要求2所述的视频时序动作检测方法,其特征在于,所述基于所述提示型文本描述库,得到分词组集,包括:
6.一种视频时序动作检测系统,其特征在于,所述系统包括:
7.根据权利要求6所述的视频时序动作检测系统,其特征在于,所述系统还包括训练模块,所述训练模块用于:
8.根据权利要求7所述的视频时序动作检测系统,其特征在于,所述训练模块还用于:
9.一种电子设备,其特征在于,包括:
10.一种计算机可读存储介质,存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至5中任一项所述的视频时序动作检测方法。
技术总结
本公开的实施例提供一种视频时序动作检测方法、系统、电子设备及存储介质,包括:训练多模态检测模型;获取待检测视频的实际时序特征序列和实际文本信息;将实际时序特征序列和实际文本信息输入预先训练的多模态检测模型,得到实际预测特征距离图和实际起止点热力图;根据实际预测特征距离图,确定出检测视频的实际动作类别;根据起止点热力图,确定出实际动作类别在待检测视频中的起止位置。本公开的实施例采用VLM多模态预训练模型构建视频时序动作检测,并设计了一种关于动作的提示型文本描述库帮助检测模型的训练,可同时从视频的图像数据和文本数据中获取信息进行时序动作检测,准确率高,能更好地适应多种检测条件。
技术研发人员:张睿
受保护的技术使用者:重庆特斯联启智科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!