一种基于大数据的企业数据采集分析方法及系统与流程
本发明涉及计算机大数据处理,尤其涉及一种基于大数据的企业数据采集分析方法及系统。
背景技术:
1、大数据作为对信息技术的兴趣正在全球范围内迅速兴起,并且关注的重点是公共机构和公司将通过迄今为止收集的大数据来创造什么价值。hadoop是一个用于大数据处理分析的开源项目,它是hadoop文件系统(hdfs),操作系统级别抽象和mapreduce引擎,可以轻松地聚合,查询和分析大量数据。包括能够进行分布式和并行处理的库,用于开发需要大量数据的智能应用程序。它还包括必要的java归档文件(java archive,jar),启动hadoop的脚本,源代码和相关资料。
2、大数据包括结构化、半结构化和非结构化数据,非结构化数据越来越成为数据的主要部分。据idc的调查报告显示:企业中80%的数据都是非结构化数据,这些数据每年都按指数增长60%。在以云计算为代表的技术创新大幕的衬托下,这些原本看起来很难收集和使用的数据开始容易被利用起来了,通过各行各业的不断创新,大数据会逐步为人类创造更多的价值。
3、传统的大数据采集的方式为对于大数据的数据采集具体为通过一个open api、web爬行器以及日志聚合器。open api模块实时收集公共门户网站提供的公共机构的相关信息数据。web爬网程序模块通过web爬网程序实时收集公共机构网站公告板提供的企业需要的数据。日志聚合器模块从各种收集器收集企业需要的数据。
4、然而,传统的大数据采集通常采用例如爬虫工具对多个数据节点进行爬取,得到的数据量很大,虽然后期的分析模块会对大量的数据进行处理得到用户希望得到的采集数据,但是将采集和分析进行分离的方式会导致采集的数据量过大,增加平台压力,并且对数据节点也不友好。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明公开了一种基于大数据的企业数据采集分析方法,所述采集分析方法应用于大数据采集分析平台,所述大数据采集分析平台与多个数据源进行分布式连接,所述大数据采集分析平台在低负载时间对所述多个数据源内的数据进行分析,按照数据源内的数据分布和数据对应的建立时间对数据源进行标签标注,所述采集分析方法包括如下步骤:
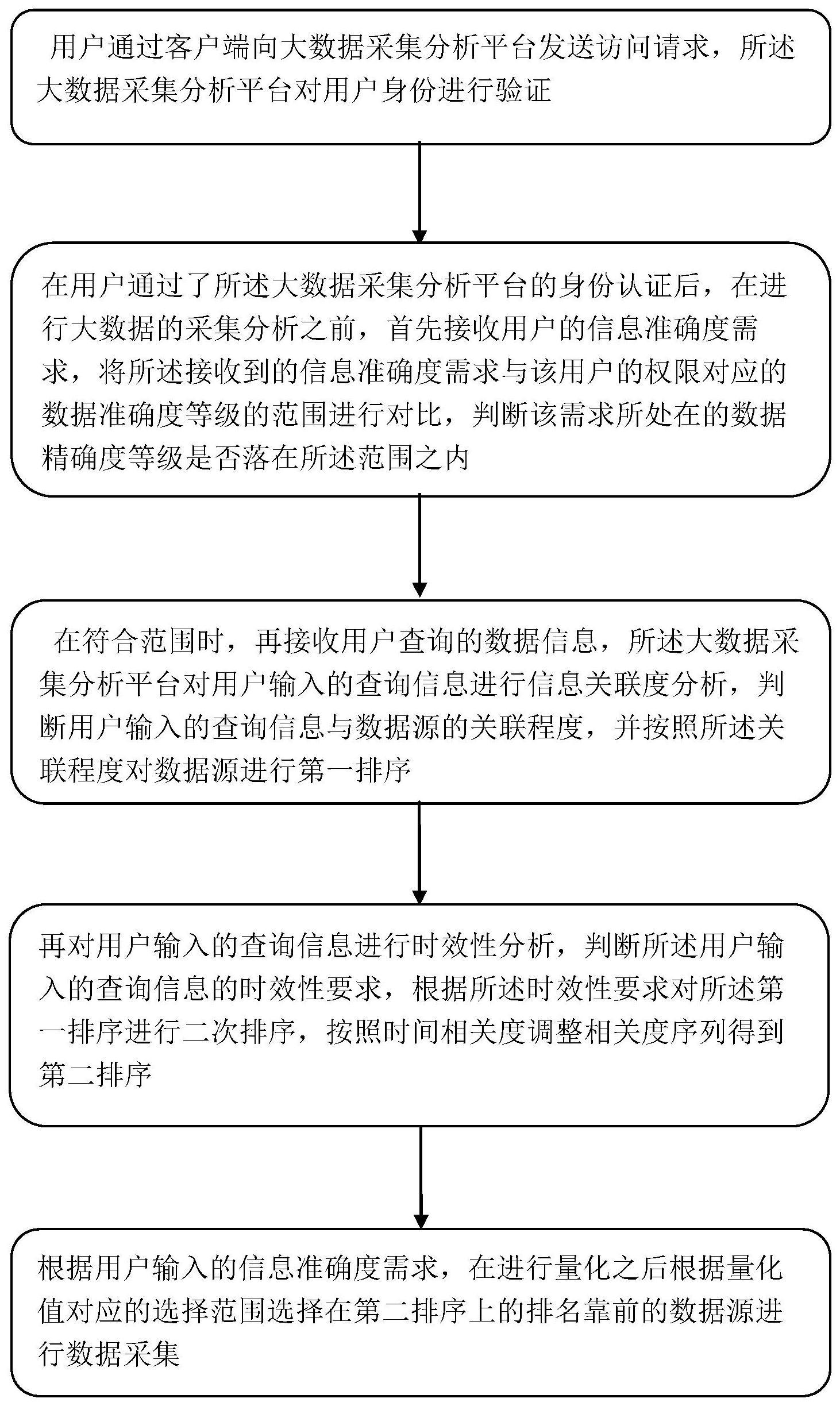
2、步骤1,用户通过客户端向大数据采集分析平台发送访问请求,所述大数据采集分析平台对用户身份进行验证,其中,所述用户身份的权限对应于可以进行数据采集的准确度等级的范围;
3、步骤2,在用户通过了所述大数据采集分析平台的身份认证后,在进行大数据的采集分析之前,首先接收用户的信息准确度需求,将所述接收到的信息准确度需求与该用户的权限对应的数据准确度等级的范围进行对比,判断该需求所处在的数据精确度等级是否落在所述范围之内,当并未落在所述范围内时,所述大数据采集分析平台通过api接口与一般性数据爬取单元连接,所述一般性数据爬取单元包括web爬行器以及日志聚合器,用以实时收集全部数据源的相关信息数据,用户的查询为通过所述api接口在一般性数据爬取单元中直接查询,而当落在所述范围之内时,继续执行步骤3;
4、步骤3,再接收用户查询的数据信息,所述大数据采集分析平台对用户输入的查询信息进行信息关联度分析,判断用户输入的查询信息与数据源的关联程度,并按照所述关联程度对数据源进行第一排序;
5、步骤4,再对用户输入的查询信息进行时效性分析,判断所述用户输入的查询信息的时效性要求,根据所述时效性要求对所述第一排序进行二次排序,按照时间相关度调整相关度序列得到第二排序;
6、步骤5,根据用户输入的信息准确度需求,在进行量化之后根据量化值对应的选择范围选择在第二排序上的排名靠前的数据源进行数据采集。
7、更进一步地,所述按照数据源内的数据分布和数据对应的建立时间对数据源进行标签标注进一步包括:预先设置企业查询标签,标注的内容标签为数据源中的标签对应的相关数据内容占该数据源内的全部数据的占比,而时效性标签为与企业采集数据相关的数据的更新频率。
8、更进一步地,所述首先接收用户的信息准确度需求进一步包括:接收用户需要的信息准确度等级,或者接收用户对需求信息的描述,所述大数据采集分析平台根据用户的信息描述进行语义分析,对需求的准确度进行量化,在根据量化值归类于不同的准确度等级。
9、更进一步地,所述查询信息的时效性为平台按照企业相关的数据进行分类,建立企业相关数据与时效性要求的对应关系并存储于数据库中(例如特定税务信息需要在对应时间分级分类查询)。
10、更进一步地,所述当并未落在所述范围内时,所述大数据采集分析平台通过api接口与一般性数据爬取单元连接,所述一般性数据爬取单元包括web爬行器以及日志聚合器,用以实时收集全部数据源的相关信息数据,用户的查询为通过所述api接口在一般性数据爬取单元中直接查询进一步包括:当用户的准确度需求低于其本技术的权限后,用户通过平台的另一个接口连接分布式爬虫模块,通过爬取多个数据源内的数据建立数据索引表,用户输入查询信息后,与分布式爬虫模块相连接的分析模块对查询信息进行关键词提取,然而与所述索引表进行对应提取相关的企业数据。
11、本发明还公开了一种基于大数据的企业数据采集分析系统,所述采集分析系统包括大数据采集分析平台,所述大数据采集分析平台与多个数据源进行分布式连接,所述大数据采集分析平台在低负载时间对所述多个数据源内的数据进行分析,按照数据源内的数据分布和数据对应的建立时间对数据源进行标签标注,用户通过客户端向大数据采集分析平台发送访问请求,所述大数据采集分析平台对用户身份进行验证,其中,所述用户身份的权限对应于可以进行数据采集的准确度等级的范围;在用户通过了所述大数据采集分析平台的身份认证后,在进行大数据的采集分析之前,首先接收用户的信息准确度需求,将所述接收到的信息准确度需求与该用户的权限对应的数据准确度等级的范围进行对比,判断该需求所处在的数据精确度等级是否落在所述范围之内,当并未落在所述范围内时,所述大数据采集分析平台通过api接口与一般性数据爬取单元连接,所述一般性数据爬取单元包括web爬行器以及日志聚合器,用以实时收集全部数据源的相关信息数据,用户的查询为通过所述api接口在一般性数据爬取单元中直接查询,而当落在所述范围之内时,再接收用户查询的数据信息,所述大数据采集分析平台对用户输入的查询信息进行信息关联度分析,判断用户输入的查询信息与数据源的关联程度,并按照所述关联程度对数据源进行第一排序;然后对用户输入的查询信息进行时效性分析,判断所述用户输入的查询信息的时效性要求,根据所述时效性要求对所述第一排序进行二次排序,按照时间相关度调整相关度序列得到第二排序;根据用户输入的信息准确度需求,在进行量化之后根据量化值对应的选择范围选择在第二排序上的排名靠前的数据源进行数据采集。
12、优选地,所述按照数据源内的数据分布和数据对应的建立时间对数据源进行标签标注进一步包括:预先设置企业查询标签,标注的内容标签为数据源中的标签对应的相关数据内容占该数据源内的全部数据的占比,而时效性标签为与企业采集数据相关的数据的更新频率。
13、优选地,所述首先接收用户的信息准确度需求进一步包括:接收用户需要的信息准确度等级,或者接收用户对需求信息的描述,所述大数据采集分析平台根据用户的信息描述进行语义分析,对需求的准确度进行量化,在根据量化值归类于不同的准确度等级。
14、优选地,所述查询信息的时效性为平台按照企业相关的数据进行分类,建立企业相关数据与时效性要求的对应关系并存储于数据库中(例如特定税务信息需要在对应时间分级分类查询)。
15、优选地,所述当并未落在所述范围内时,所述大数据采集分析平台通过api接口与一般性数据爬取单元连接,所述一般性数据爬取单元包括web爬行器以及日志聚合器,用以实时收集全部数据源的相关信息数据,用户的查询为通过所述api接口在一般性数据爬取单元中直接查询进一步包括:当用户的准确度需求低于其本技术的权限后,用户通过平台的另一个接口连接分布式爬虫模块,通过爬取多个数据源内的数据建立数据索引表,用户输入查询信息后,与分布式爬虫模块相连接的分析模块对查询信息进行关键词提取,然而与所述索引表进行对应提取相关的企业数据。
16、针对现有技术,本发明的有益效果非常显著,本发明的有益效果为:设计两套并行的数据采集方案,并根据用户可能的数据需求进行精准度区分,区别于传统的模糊检索或者精准检索,本发明还进一步设计了用户的权限划分,本发明不限制用户对于大数据的采集,而是对采集的数据源进行设计,如果用户需要精细度查询则采集特定的和数据相关度高的数据集,以减少大数据采集对平台的符合,更进一步地,本发明区分限时和忙时,在空闲阶段系统自动对数据进行初步处理,例如建立第二爬取数据的索引表,或者对数据源进行标注,以便于用户在应用本系统时可以更快地进行执行,提升用户体验感。
- 还没有人留言评论。精彩留言会获得点赞!