基于VMD和LSTM融合模型的风电功率预测方法、系统、装置及介质与流程
本发明属于海上风电场的发电功率预测领域,涉及一种基于vmd和lstm融合模型的风电功率预测方法、系统、装置及介质。
背景技术:
1、循环神经网络模型在时间序列数据预测研究方面颇有成效,但同时会出现长期依赖问题。长短期记忆神经网络(lstm)作为循环神经网络的一种变体,适用于时间序列中间隔较长、延迟较的事件的处理和预测。然而单一模型的预测精度太低,目前很多模型是将经验模态分解(emd)或小波分解与神经网络模型组合进行预测。但是emd分解会出现断点效应以及模态混叠的现象,小波分解存在小波基的选择困难,同时,不同的小波基分析结果也不一样,这将不利于预测结果,预测过程复杂化。
技术实现思路
1、本发明的目的在于解决现有技术中预测模型中不同的小波基分析结果不一样,不利于预测结果,预测过程复杂化的问题,提供一种基于vmd和lstm融合模型的风电功率预测方法、系统、装置及介质。
2、为达到上述目的,本发明采用以下技术方案予以实现:
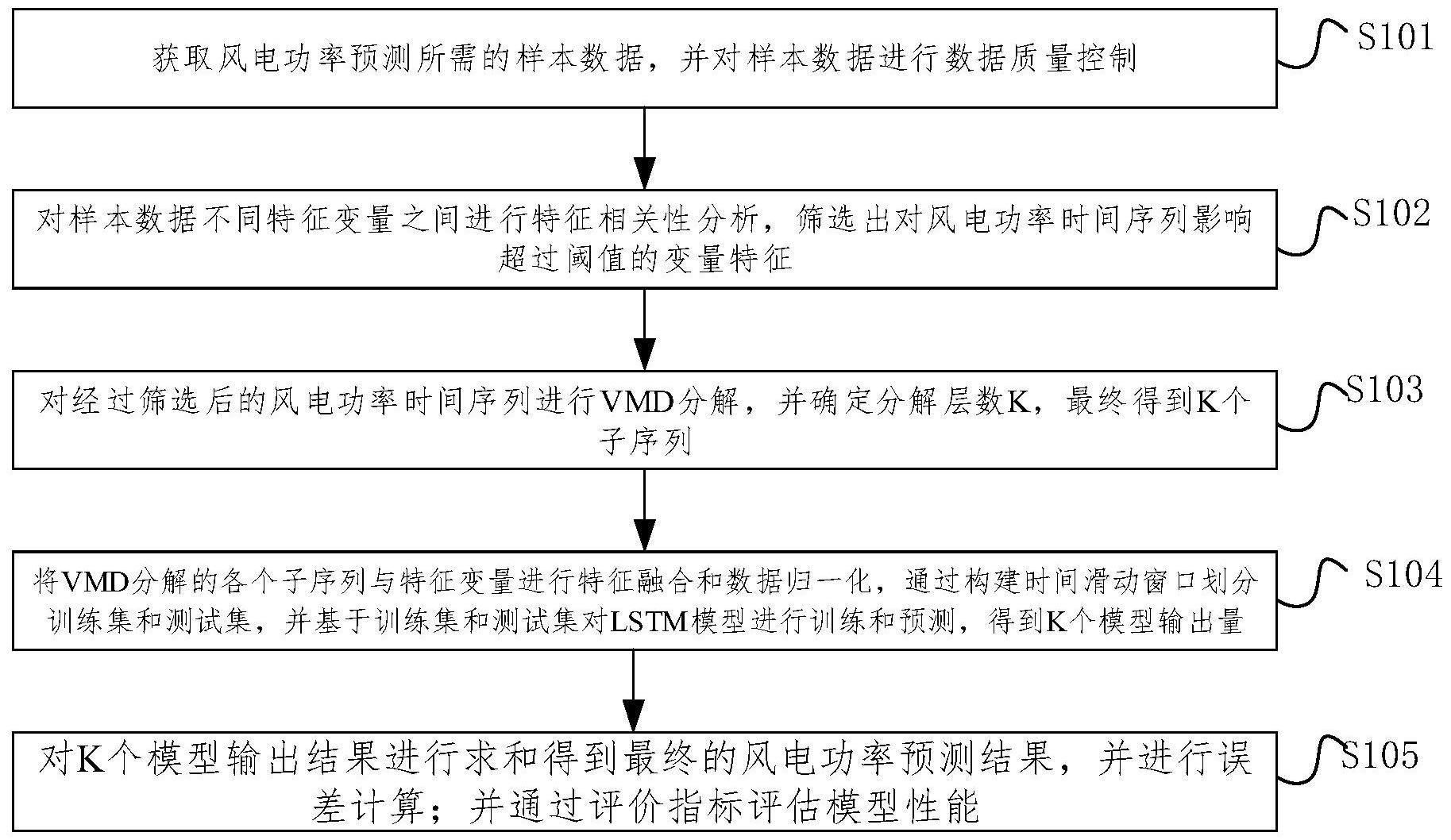
3、基于vmd和lstm融合模型的风电功率预测方法,包括:
4、获取风电功率预测所需的样本数据,并对样本数据进行数据质量控制;
5、对样本数据不同特征变量之间进行特征相关性分析,筛选出对风电功率时间序列影响超过阈值的变量特征;
6、对经过筛选后的风电功率时间序列进行vmd分解,并确定分解层数k,最终得到k个子序列;
7、将vmd分解的各个子序列与特征变量进行特征融合和数据归一化,通过构建时间滑动窗口划分训练集和测试集,并基于训练集和测试集对lstm模型进行训练和预测,得到k个模型输出量;
8、对k个模型输出结果进行求和得到最终的风电功率预测结果,并进行误差计算;并通过评价指标评估模型性能。
9、本发明的进一步改进在于:
10、质量控制包括对样本数据中的风机桨矩角异常值进行识别和处理,具体为:
11、s101:对样本数据进行可视化并利用箱线图对风机桨矩角异常值识别,当异常值数量超过所设定的阈值时,将异常值数量作为缺失值处理;
12、s102:利用随机森林法和均值法分别对缺失值填补并进行误差对比,确定通过随机森林填补缺失值。
13、对样本数据不同特征变量之间进行特征相关性分析,具体为:
14、基于随机森林方法对样本数据不同特征变量之间进行特征相关性分析;其中,基于特征重要性排序,筛选出前十个特征变量,具体为:
15、s301:建立决策树之前,有放回地随机抽取一定的样本集,重复采样多次构成决策树模型的训练集,其余没有被抽取到的数据记为袋外数据,基于袋外数据对决策树性能进行评价,训练决策数模型并计算此时每一颗决策树的袋外数据误差;
16、s302:将噪声随机加入袋外数据的特征中,并计算袋外数据误差;
17、s303:设森林中有t棵树,则计算特征的重要性为:若在袋外数据加入噪声后,袋外数据的准确率变化超过预期,而表面特征对于样本数据的预测结果影响并未达到预期,则对该特征进行忽略。
18、对经过筛选后的风电功率时间序列进行vmd分解,并确定分解层数k,最终得到k个子序列,具体为:
19、s401:构造变分问题;设原始风电功率信号p被分解为k个子分量,约束条件为各模态分量和为原信号,其约束变分模型为:
20、
21、
22、式中,δ(t)单位脉冲函数,表示偏导函数,*表示二者之间的卷积过程,uk={u1,u2,…uk}为各个模态分量bimfs,ωk={ω1,ω2,…ωk}则表示各个模态分量的中心频率,uk(t)表示第k个模态分量,是单边际谱的指数信号,p(t)为原始风电功率信号。
23、s402:求解变分问题。为求约束变最优化,将约束变分问题转变为非约束变分问题,在s401中的约束变分模型中利用二次惩罚项和拉格朗日乘子法的优势,引入了增广lagrangian函数,其具体公式:
24、
25、其中,α表示惩罚参数,λ为lagrange因子。
26、s403:更新s402中的泛函,对应的更新结果为:
27、
28、
29、
30、其中,s表示迭代次数,γ表示噪声容限,当信号含有强噪声时,可设γ为0达到去噪的效果;
31、s404:不断重复s403,直至满足迭代停止条件:
32、
33、s405:vmd分解层数的确定;通过原始信号和分解信号之间的mape判断,确定分解层数;mape的具体公式为:
34、
35、其中,代表分解后各模态的相加值,p代表原始信号,n代表信号的数量。
36、数据归一化采用z-score标准化,具体为:
37、
38、其中,xy表示归一化前的数据,x’y表示归一化后的数据,xmin表示归一化前的最小值,xmax表示归一化前的最大值。
39、训练集和测试集对lstm模型进行训练和预测,得到k个模型输出量,具体为:
40、lstm为门控输出,即遗忘门(ft)、输入门(it)和输出门(ot),对应的输出分别为:
41、ft=σ(wf·[ht-1,xt]+bf)
42、it=σ(wi·[ht-1,xt])+bi
43、
44、
45、ot=σ(wo·[ht-1,xt]+bo)
46、ht=ot*tanh(ct)
47、其中,σ和tanh是激活函数,将变量映射到[0,1]和[-1,1]之间,wf、bf表示遗忘门σ激活函数的权重与偏置,wi、bi表示输入门σ激活函数的权重与偏置,wc、bc表示输入门tanh激活函数的权重与偏置,ct表示新得到的细胞状态信息,wo、bo表示输出门σ激活函数的权重与偏置,ht则是下一隐藏层的值。
48、评价指标为rmse、mae、r2_score和mape;
49、所述rmse为:
50、
51、式中,predn表示风电功率预测值,truen表示风电功率真实值,n表示预测数量;
52、所述mae为:
53、
54、式中,predn表示风电功率预测值,truen表示风电功率真实值,n表示预测数量;
55、所述r2_score为:
56、
57、式中,predn表示风电功率预测值,truen表示风电功率真实值,n表示预测数量;
58、所述mape为:
59、
60、式中,predn表示风电功率预测值,truen表示风电功率真实值,n表示预测数量。
61、基于vmd和lstm融合模型的风电功率预测系统,包括:
62、获取模块,所述获取模块用于获取风电功率预测所需的样本数据,并对样本数据进行数据质量控制;
63、筛选模块,所述筛选模块用于对样本数据不同特征变量之间进行特征相关性分析,筛选出对风电功率时间序列影响超过阈值的变量特征;
64、分解模块,所述分解模块用于对经过筛选后的风电功率时间序列进行vmd分解,并确定分解层数k,最终得到k个子序列;
65、融合模块,所述融合模块用于将vmd分解的各个子序列与特征变量进行特征融合和数据归一化,通过构建时间滑动窗口划分训练集和测试集,并基于训练集和测试集对lstm模型进行训练和预测,得到k个模型输出量;
66、误差分析模块,所述误差分析模块用于对k个模型输出结果进行求和得到最终的风电功率预测结果,并进行误差计算;并通过评价指标评估模型性能。
67、一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
68、一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。
69、与现有技术相比,本发明具有以下有益效果:
70、本发明通过对风电功率预测所需的样本数据进行数据质量控制,并通过vmd分解,确定分解的层数k,得到k个子序列;利用lstm模型对各个子序列进行预测;对所有子序列对应的lstm模型输出量叠加求和,得到最终的融合模型预测的风电功率结果,并通过误差评价指标计算其误差。本发明缓解了风电数据的不平稳性特征,在vmd分解时确定最佳分解层数,减少了模型训练的压力;本发明引入信号分解,充分利用数据之间的联系,实现了风电功率的准确预测;提高了预测的准确性,简化了预测过程。
- 还没有人留言评论。精彩留言会获得点赞!