一种基于浏览器插件的网页无障碍检测方法
:
1.本发明属于信息无障碍领域,涉及一种基于浏览器插件的网页无障碍检测方法,特别运用于跨局域网场景下对网页进行源码级的无障碍检测。
背景技术:
2.随着互联网技术的飞速发展,当前网页种类繁多,信息存储方式电子化、信息传播方式网络化,信息获取方式技术化、信息表现方式多媒体化。而由于早期技术水平的限制,一部分网页在设计与开发时没能很好地考虑用户的使用体验,在用户需求与服务人群的全面性方面存在不足,对障碍人群的支持不够,残障人士等特殊群体在获取信息时面临技术革新带来的各种人为障碍。
3.同时,由于数字化的发展与障碍人群遭遇信息困境的进一步加深,障碍人群的需求与时代的发展逐渐展现出一些无法调和的矛盾:一部分是快速发展的互联网技术,一部分是互联网使用方式受限,操作不便的障碍人群。
4.近年来,国家陆续出台相关法规、政策积极推进网站无障碍服务能力建设。网站设计者也具有相关的无障碍设计标准可供遵循,但网站最后对于标准的符合程度仍然需要专业的网页无障碍评估来给出可靠的评价,以此更好地发现网站中存在的不足、帮助开发者进行无障碍改造。无障碍检测是无障碍建设的重要一环,有效的无障碍检测能够帮助开发者及时地找出设计中不利于用户获取信息的部分,及时督促网页开发者进行功能优化。目前,现有的无障碍检测流程中往往会出现一些由于待检测网站的相关设置导致系统无法高效正确地获取网页源代码的现象。
技术实现要素:
5.本发明要克服现有技术的上述缺点,提出一种基于浏览器插件的网页无障碍检测方法,实现一种跨局域网、并发式的网页无障碍检测方法。与服务端进行网页爬取,实现无障碍检测的方法相比,本发明方法可以有效地规避多样化的网页反爬验证手段,普适性更高。使用本发明的方法可以更高效地获取网页数据资源,并进一步检测网页是否符合无障碍设计标准,从而确定待检测网页的可用性以及对用户的友好程度。
6.一种基于浏览器插件的网页无障碍检测方法,其特征在于,包括以下步骤:
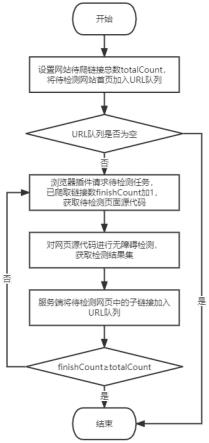
7.s1:服务端从用户输入中获取待检测网站的首页链接以及需要获取的网站总数totalcount,并将待检测网站的首页链接加入url队列urlqueue,其中url队列urlqueue定义为:urlqueue=[url1,url2,...,urli];
[0008]
s2:服务端启动爬虫线程,构建浏览器插件爬虫任务,等待爬虫返回结果;
[0009]
s211:服务端根据步骤s1中的url队列urlqueue按列表顺序从队首分配一个url以及一个唯一标识taskid包装为浏览器插件任务,其中任务t定义为:t={taskid,url},已访问链接数finishcount值加1;
[0010]
s212:服务端将步骤s211中的任务t加入task队列taskqueue,其中task队列
taskqueue定义为:taskqueue=[t1,t2,...,ti];
[0011]
s213:服务端构建一个哈希表hashmap用于监听任务信息,其中哈希表hashmap定义为:hashmap=[(taskid1,t1),(taskid2,t2),...,(taskidi,ti)],taskid为任务的唯一标识,t为对应的等待任务;
[0012]
s3:浏览器插件创建爬虫环境并定义爬虫相关配置;
[0013]
s31:浏览器插件在content scripts与浏览器扩展程序页面之间建立短期通道,用于监听网页状态,收发消息;
[0014]
s32:浏览器插件设置跨域访问权限,支持访问已声明的任何域名下的网页;
[0015]
s33:浏览器插件新建一个窗口w,其中窗口w的id值定义为winid,窗口w下tab页面数量定义为tabcount,同时设置页面并发爬取上限值为window_max_num;
[0016]
s4:浏览器插件向服务端请求一个待检测任务t,获取待检测页面的网页源代码s;
[0017]
s41:浏览器插件从服务端请求一个待检测任务t;
[0018]
s42:服务端将步骤s41中的待分配任务t从步骤s212中定义的task队列taskqueue中移动到步骤s213定义的监听表hashmap中并等待爬虫返回结果;
[0019]
s43:浏览器插件获取步骤s41中任务t的url后,打开浏览器标签并访问该url,页面级别并发获取网页源代码s;
[0020]
s431:浏览器插件获取当前客户端存放的cookie信息以及待检测url。
[0021]
s432:若tabcount≤window_max_num,浏览器插件根据步骤s33中的winid与步骤s43中的url在窗口w下新增一个tab页面用于爬取当前待检测url,当前tab数量tabcount加1;若tabcount》window_max_num,则等待当前已开启的tab页面爬取结束直至tabcount≤window_max_num;
[0022]
s433:浏览器插件根据步骤s432中页面的tabid,通过content-scripts向待检测页面注入脚本,获取该页面文档元素对象(包括其后代)的序列化html片段outerhtml,即待检测源代码s;
[0023]
s434:浏览器插件关闭当前已爬取的tab页面,当前tab数量tabcount减1;
[0024]
s5:根据步骤s4中获取的源代码s进行源码级别的无障碍检测;
[0025]
s51:从用户输入中获取待检测无障碍条目与规则集r=[r1,r2,r3,
…
,ri];
[0026]
s52:对步骤s4中获取的源代码s应用步骤s51中选取的规则集r进行无障碍检测,判断当前网页是否符合标准《gb/t 37668-2019信息技术互联网内容无障碍可访问性技术要求与测试方法》中对应条目ri定义的技术要求;
[0027]
s6:浏览器插件获取步骤s5中生成的检测结果集p,其中p=[ns,n
t
,nf,ni],ns为规则数量,n
t
为检测结果通过的规则数量,nf为检测结果不通过的规则数量,ni为检测结果未知的规则数量;
[0028]
s7:浏览器插件将步骤s4中获取的网页源代码s和步骤s6中获取的检测结果集p与当前任务唯一标识taskid上传至服务端;
[0029]
s8:服务端根据步骤s7中得到的任务唯一标识taskid,在查找对应的等待结果t并将其返回给等待线程;
[0030]
s9:服务端从网页源代码s中获取子链接集l,其中子链接集l定义为:l=[url1,url2,...,urli],并将l加入url队列urlqueue;
[0031]
s10:服务端将步骤s7中得到的检测结果集p加入检测结果;
[0032]
s11:如果task队列taskqueue为空或已经获取了足够数量的链接数finishcount≥totalcount,流程结束,否则重复执行步骤s2。
[0033]
综上,本发明创建了基于浏览器插件的无障碍检测方法,具有如下有益效果:
[0034]
(1)具有普适性,利用浏览器插件通信机制,可以高效地规避网页中存在的反爬虫策略,为后续的无障碍检测提供数据信息。(2)具有高效性,通过结构设计,能够并发地检测大量待测网页,提升网站整体的无障碍检测效率。(3)实现跨文本档、多窗口、跨域消息传递,扩大了可用检测场景。
附图说明:
[0035]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0036]
图1是本发明提供的基于浏览器插件无障碍检测方法的总体流程图;
[0037]
图2是本发明提供的基于浏览器插件无障碍检测方法的总体流程图中浏览器插件爬取待测网页源代码的流程图。
[0038]
具体实施方法:
[0039]
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
[0040]
本实例以检测某个网页为例,一种基于浏览器插件的网页无障碍检测方法,包括如下具体步骤:
[0041]
s1:服务端从用户输入中获取待检测网站的首页链接以及需要获取的网站总数totalcount,并将待检测网站的首页链接加入url队列urlqueue,其中url队列urlqueue定义为:urlqueue=[url1,url2,...,urli];
[0042]
s2:服务端启动爬虫线程,构建浏览器插件爬虫任务,等待爬虫返回结果;
[0043]
s211:服务端根据步骤s1中的url队列urlqueue按列表顺序从队首分配一个url以及一个唯一标识taskid包装为浏览器插件任务,其中任务t定义为:t={taskid,url},已访问链接数finishcount值加1;
[0044]
s212:服务端将步骤s211中的任务t加入task队列taskqueue,其中task队列taskqueue定义为:taskqueue=[t1,t2,...,ti];
[0045]
s213:服务端构建一个哈希表hashmap用于监听任务信息,其中哈希表hashmap定义为:hashmap=[(taskid1,t1),(taskid2,t2),...,(taskidi,ti)],taskid为任务的唯一标识,t为对应的等待任务;
[0046]
s3:浏览器插件创建爬虫环境并定义爬虫相关配置;
[0047]
s31:浏览器插件在content scripts与浏览器扩展程序页面之间建立短期通道,用于监听网页状态,收发消息;
[0048]
s32:浏览器插件设置跨域访问权限,支持访问已声明的任何域名下的网页;
[0049]
s33:浏览器插件新建一个窗口w,其中窗口w的id值定义为winid,窗口w下tab页面数量定义为tabcount,同时设置页面并发爬取上限值为window_max_num;
[0050]
s4:浏览器插件向服务端请求一个待检测任务t,获取待检测页面的网页源代码s;
[0051]
s41:浏览器插件从服务端请求一个待检测任务t;
[0052]
s42:服务端将步骤s41中的待分配任务t从步骤s212中定义的task队列taskqueue中移动到步骤s213定义的监听表hashmap中并等待爬虫返回结果;
[0053]
s43:浏览器插件获取步骤s41中任务t的url后,打开浏览器标签并访问该url,页面级别并发获取网页源代码s;
[0054]
s431:浏览器插件获取当前客户端存放的cookie信息以及待检测url;
[0055]
s432:若tabcount≤window_max_num,浏览器插件根据步骤s33中的winid与步骤s43中的url在窗口w下新增一个tab页面用于爬取当前待检测url,当前tab数量tabcount加1;若tabcount》window_max_num,则等待当前已开启的tab页面爬取结束直至tabcount≤window_max_num;
[0056]
s433:浏览器插件根据步骤s432中页面的tabid,通过content-scripts向待检测页面注入脚本,获取该页面文档元素对象(包括其后代)的序列化html片段outerhtml,即待检测源代码s;
[0057]
s434:浏览器插件关闭当前已爬取的tab页面,当前tab数量tabcount减1;
[0058]
图1是本发明提供的基于浏览器插件无障碍检测方法的总体流程图。
[0059]
图2是本发明提供的基于计算机视觉的网页端漂浮窗关闭检测算法的总体流程图中漂浮窗位置检测的流程图。
[0060]
s5:根据步骤s4中获取的源代码s进行源码级别的无障碍检测;
[0061]
s51:从用户输入中获取待检测无障碍条目与规则集r=[r1,r2,r3,
…
,ri];
[0062]
s52:对步骤s4中获取的源代码s应用步骤s51中选取的规则集r进行无障碍检测,判断当前网页是否符合标准《gb/t 37668-2019信息技术互联网内容无障碍可访问性技术要求与测试方法》中对应条目ri定义的技术要求;
[0063]
s6:浏览器插件获取步骤s5中生成的检测结果集p,其中p=[ns,n
t
,nf,ni],ns为规则数量,n
t
为检测结果通过的规则数量,nf为检测结果不通过的规则数量,ni为检测结果未知的规则数量;
[0064]
s7:浏览器插件将步骤s4中获取的网页源代码s和步骤s6中获取的检测结果集p与当前任务唯一标识taskid上传至服务端;
[0065]
s8:服务端根据步骤s7中得到的任务唯一标识taskid,在查找对应的等待结果t并将其返回给等待线程;
[0066]
s9:服务端从网页源代码s中获取子链接集l,其中子链接集l定义为:l=[url1,url2,...,urli],并将l加入url队列urlqueue;
[0067]
s10:服务端将步骤s7中得到的检测结果集p加入检测结果;
[0068]
s11:如果task队列taskqueue为空或已经获取了足够数量的链接数dinishcount≥totalcount,流程结束,否则重复执行步骤s2。
[0069]
本发明可应用于对网站页面无障碍的自动化检测,能够有效地规避部分网页的反
爬策略,实现一种跨局域网下的源码级别的无障碍检测,并通过并发控制提升检测效率,帮助开发者进行无障碍改造。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1