基于单视角的人体模型驱动方法及电子设备与流程
本申请涉及三维重建,提供一种基于单视角的人体模型驱动方法及电子设备。
背景技术:
1、人体运动捕捉在人机交互、个人健康管理和人类行为理解等方面有着多种应用。随着计算机视觉技术的发展,目前,主要通过网络回归或者优化的方法,从单视角视频和图像中以运动学的方式捕捉准确人体姿态。
2、基于优化的方法是将观测数据和待驱动数据进行不断的拟合,使驱动后模型的骨骼数据和图像中观测的骨骼数据不断的接近获得最小误差,由于拟合过程是一个不断迭代的过程,所以基于优化的方法通常耗时较长。而基于回归的方法是基于深度学习的方法,输入人体参数化模型的数据和人体特征图估计出观测数据的人体姿态,该方法速度较快,适用于实时性较强的虚拟交互场景。
3、然而,基于回归的方法在估计全身的动作姿态时,使用单视角视频或图像,无法正确的估计出人体在三维空间中的深度信息,从而在模型驱动时,不能进行准确的移动,特别是在深度方向上。
技术实现思路
1、本申请实施例提供了一种基于单视角的人体模型驱动方法及电子设备,用于在保证实时性的条件下,提高模型驱动的准确性。
2、一方面,本申请实施例提供一种基于单视角的人体模型驱动方法,包括:
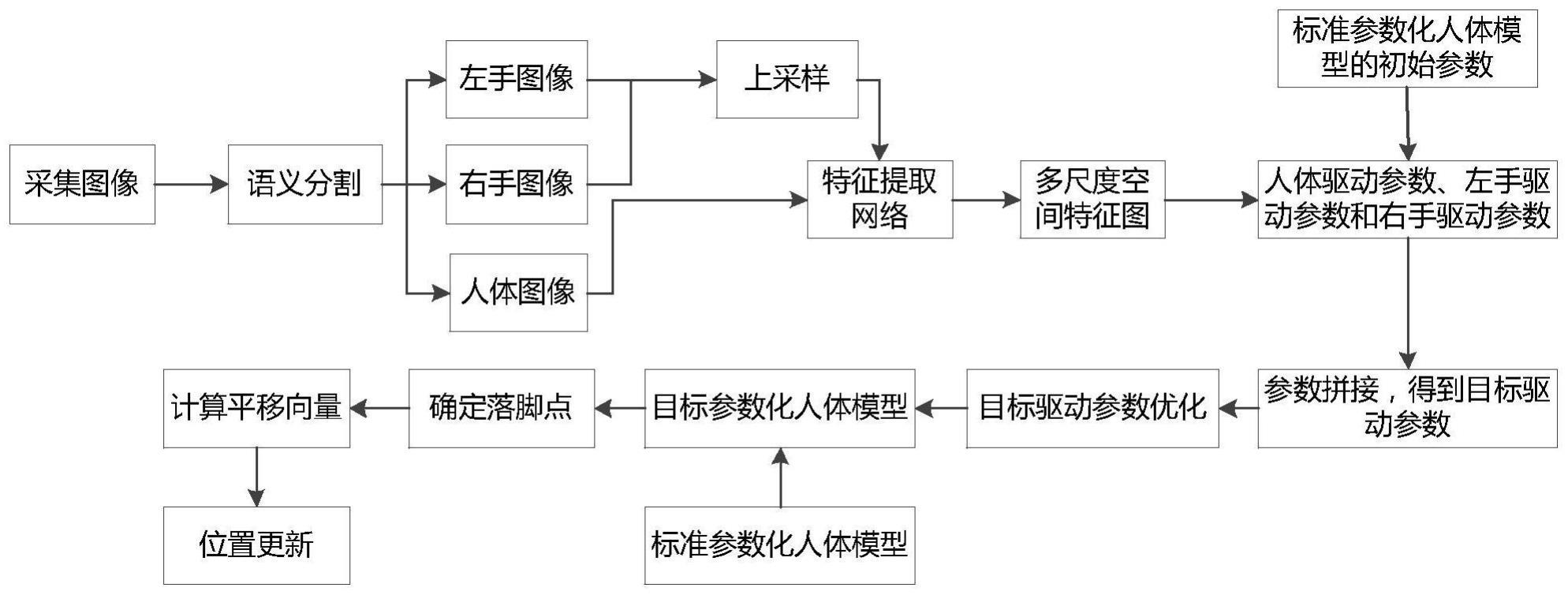
3、获取单视角相机连续采集的多帧包含目标对象全身的图像;
4、对当前帧图像进行语义分割,获得人体图像和人手图像,并编码出所述人体图像和所述人手图像各自对应的多尺度空间特征图;
5、将标准人体参数化模型的初始参数,以及所述人体图像和所述人手图像各自对应的多尺度空间特征图输入到姿态估计回归网络,分别获得人体驱动参数和人手驱动参数;
6、用所述人体驱动参数和所述人手驱动参数驱动所述标准人体参数化模型变形,得到目标人体参数化模型;
7、根据所述目标参数化模型的后脚跟区域内的网格顶点,确定所述目标人体参数化模型的落地点;
8、根据所述当前帧图像确定的落地点以及上一帧图像确定的落地点,驱动所述目标人体参数化模型运动。
9、另一方面,本申请实施例一种电子设备,包括处理器、存储器和显示屏,所述显示屏、所述存储器和所述处理器通过总线连接:
10、所述存储器存储有计算机程序,所述处理器根据所述计算机程序,执行以下操作:
11、获取单视角相机连续采集的多帧包含目标对象全身的图像;
12、对当前帧图像进行语义分割,获得人体图像和人手图像,并编码出所述人体图像和所述人手图像各自对应的多尺度空间特征图;
13、将标准人体参数化模型的初始参数,以及所述人体图像和所述人手图像各自对应的多尺度空间特征图输入到姿态估计回归网络,分别获得人体驱动参数和人手驱动参数;
14、用所述人体驱动参数和所述人手驱动参数驱动所述标准人体参数化模型变形,得到目标人体参数化模型;
15、根据所述目标参数化模型的后脚跟区域内的网格顶点,确定所述目标人体参数化模型的落地点;
16、根据所述当前帧图像确定的落地点以及上一帧图像确定的落地点,驱动所述目标人体参数化模型运动,并通过所述显示屏显示所述目标人体参数化模型。
17、另一方面,本申请实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令用于使计算机设备执行本申请实施例提供的基于透明度纹理贴图的头发重建方法的步骤。
18、本申请实施例提供的基于单视角的人体模型驱动方法及电子设备,对单视角相机连续采集每一帧包含目标对象全身的图像进行语义分割,并对分割出的人手图像和人体图像分别进行编码,生成多尺度空间特征,结合标准人体参数化模型的初始参数进行回归,分别得到人体驱动参数和人手驱动参数,从而驱动标准人体参数化模型变形,得到与目标对象当前形态匹配的目标人体参数化模型。通过对目标人体参数化模型的后脚跟进行实时跟踪,利用前后两帧后脚跟的位置,在三维空间中对目标人体参数化模型进行移动,从而在保证实时性的条件下,提高模型在三维空间中的驱动效果,解决由于单视角视频或图像缺乏深度信息导致的模型移动不准确的问题。
技术特征:
1.一种基于单视角的人体模型驱动方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,所述根据所述目标参数化模型的后脚跟区域内的网格顶点,确定所述目标人体参数化模型的落地点,包括:
3.如权利要求l所述的方法,其特征在于,所述根据所述当前帧图像确定的落地点以及上一帧图像确定的落地点,驱动所述目标人体参数化模型运动,包括:
4.如权利要求1所述的方法,其特征在于,所述用所述人体驱动参数和所人手驱动参数驱动所述标准人体参数化模型变形,得到目标人体参数化模型,包括:
5.如权利要求4所述的方法,其特征在于,得到所述目标驱动参数后,驱动所述标准化人体模型变形前,所述方法还包括:
6.如权利要求1-5中任一项所述的方法,其特征在于,所述将标准人体参数化模型的初始参数,以及所述人体图像和所述人手图像各自对应的多尺度空间特征图输入到姿态估计回归网络,分别获得人体驱动参数和人手驱动参数,包括:
7.如权利要求1-5中任一项所述的方法,其特征在于,所述人手图像包括左手图像和右手图像,获得人手图像后,获得所述人手图像对应的多尺度空间特征图之前,所述方法还包括:
8.一种电子设备,其特征在于,包括处理器、存储器和显示屏,所述显示屏、所述存储器和所述处理器通过总线连接:
9.如权利要求8所述的电子设备,其特征在于,所述处理器根据所述目标参数化模型的后脚跟区域内的网格顶点,确定所述目标人体参数化模型的落地点,具体操作为:
10.如权利要求8所述的电子设备,其特征在于,所述处理器根据所述当前帧图像确定的落地点以及上一帧图像确定的落地点,驱动所述目标人体参数化模型运动,具体操作为:
技术总结
本申请涉及三维重建技术领域,提供一种基于单视角的人体模型驱动方法及电子设备,基于单视角相机捕捉的人体运动过程中的图像,采用回归方式,估计人体参数化模型的骨架中各个骨骼节点间的姿态参数,以及人体参数化模型的形状参数,从而驱动标准人体参数化模型变形,得到与当前帧图像中目标对象姿态和体型一致的目标人体参数化模型,并对目标人体参数化模型的后脚跟进行实时跟踪,利用前后两帧图像中目标人体参数化模型的落地点间的平移向量,在三维空间中对目标人体参数化模型进行移动,从而在保证实时性的条件下,提高模型在三维空间中的驱动效果,解决由于单视角视频或图像缺乏深度信息导致的模型移动不准确的问题。
技术研发人员:张思栋,许瀚誉
受保护的技术使用者:聚好看科技股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!