模型参数更新方法、装置、计算机设备以及存储介质与流程
本发明涉及计算机,尤其涉及一种模型参数更新方法、装置、计算机设备以及存储介质。
背景技术:
1、现有的深度学习框架将深度学习模型表示为由张量和算子构成的张量程序。深度学习模型通常包括几千个算子。这些算子由图形处理器(graphics processing unit,gpu)的内核计算单元(kernel)执行。内核计算单元运行过程包括启动、执行等。
2、然而,相关技术中,对于一些算子来说,内核计算单元的启动时间比内核计算单元的执行时间长,因此,相关技术中内核计算单元启动开销占比有待减少。
技术实现思路
1、本发明提供一种模型参数更新方法、装置、计算机设备以及存储介质,以至少解决相关中kernel启动开销占比有待减少的问题。
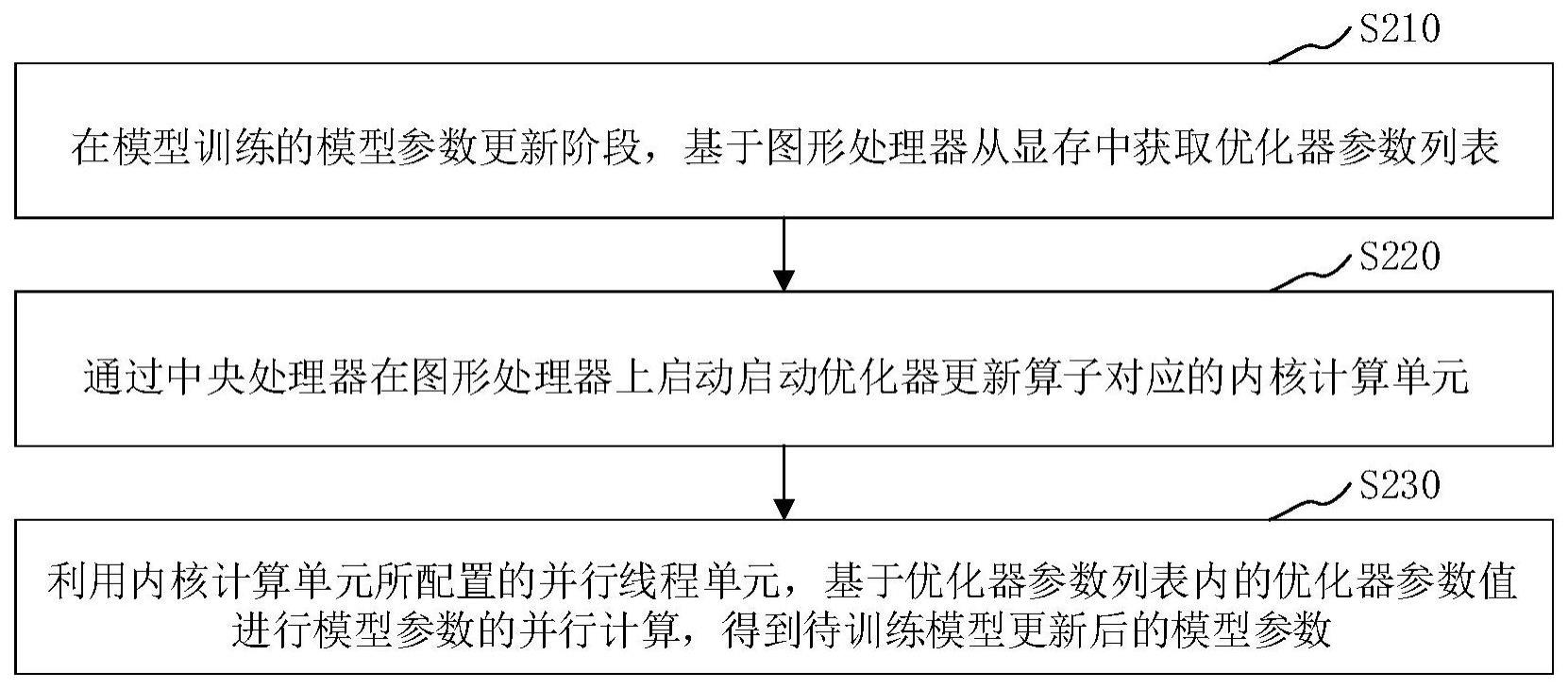
2、本发明提供一种语言模型的模型参数更新方法,应用于包括图形处理器和中央处理器的异构服务器;所述方法包括:在模型训练的模型参数更新阶段,基于所述图形处理器从显存中获取优化器参数列表;其中,所述优化器参数列表包括待训练模型的模型参数对应的优化器参数值;通过所述中央处理器在所述图形处理器上启动优化器更新算子对应的内核计算单元;利用所述内核计算单元所配置的并行线程单元,基于所述优化器参数列表内的优化器参数值进行模型参数的并行计算,得到更新后的模型参数;其中,所述更新后的模型参数用于对所述待训练模型进行更新,以对更新后的所述待训练模型进行训练。
3、在其中一个实施例中,所述基于所述优化器参数列表内的优化器参数值进行模型参数的并行计算,得到所述待训练模型更新后的模型参数,包括:
4、根据所述待训练模型的待更新模型参数,从所述优化器参数列表中获取所述待更新模型参数对应的优化器参数值;
5、基于所述所述待更新模型参数对应的优化器参数值进行模型参数的并行计算,得到所述更新后的模型参数。
6、在其中一个实施例中,所述优化器参数列表包括第t-1个训练轮次的第一动量列表、第t个训练轮次的梯度列表;所述基于所述优化器参数列表内的优化器参数值进行模型参数的并行计算,得到所述待训练模型更新后的模型参数,包括:
7、基于所述第一动量列表中的动量数据、所述梯度列表中的模型参数梯度数据确定所述第t个训练轮次的第二动量列表;
8、根据所述第二动量列表中的动量数据、所述第t个训练轮次的模型参数列表中的模型参数值进行模型参数的并行计算,得到第t+1个训练轮次的模型参数值。
9、在其中一个实施例中,所述优化器参数列表包括第t-1个训练轮次的第一一阶动量列表、第一二阶动量列表、第t个训练轮次的梯度列表;所述基于所述优化器参数列表内的优化器参数值进行模型参数的并行计算,得到所述待训练模型更新后的模型参数,包括:
10、基于所述第一一阶动量列表中的一阶动量数据、所述梯度列表中的模型参数梯度数据确定所述第t个训练轮次的第二一阶动量列表;
11、基于所述第一二阶动量列表中的二阶动量数据、所述梯度列表中的模型参数梯度数据确定所述第t个训练轮次的第二二阶动量列表;
12、根据所述第二一阶动量列表中的一阶动量数据、所述第二二阶动量列表中的二阶动量数据、所述第t个训练轮次的模型参数列表中的模型参数值进行模型参数的并行计算,得到第t+1个训练轮次的模型参数值。
13、在其中一个实施例中,所述待训练模型为bert模型。
14、在其中一个实施例中,所述bert模型的多层感知机mlp模块包括第一融合算子和第二融合算子,其中,所述第一融合算子、所述第二融合算子是基于所述多层感知机mlp模块包括的线性算子、偏置算子和激活算子进行算子融合得到的。
15、在其中一个实施例中,所述方法还包括:
16、在所述bert模型训练的第t个训练轮次内的前向计算过程中,不保留所述前向计算过程中网络中间层的输出;
17、在第t个训练轮次内的反向计算过程中,执行所述网络中间层对应的局部前向计算,得到所述网络中间层的输出,并基于所述网络中间层的输出确定模型参数梯度数据。
18、在其中一个实施例中,所述待训练模型的模型状态量包括的张量划分为n个张量集合;所述n个张量集合与n个并行进程之间具有一一对应关系;所述张量为所述待训练模型包括的网络层的输入和输出;n为大于1的整数;所述方法还包括:
19、针对所述n个并行进程中的目标并行进程,基于所述目标并行进程对应的目标张量集合进行第t个训练轮次的前向计算和第t个训练轮次的反向计算,得到模型参数梯度数据。
20、本发明提供一种语言模型的模型参数更新装置,应用于包括图形处理器和中央处理器的异构服务器;所述装置包括:
21、参数列表获取模块,用于在模型训练的模型参数更新阶段,基于所述图形处理器从显存中获取优化器参数列表;其中,所述优化器参数列表包括待训练模型的模型参数对应的优化器参数值;
22、计算单元启动模块,用于通过所述中央处理器在所述图形处理器上启动优化器更新算子对应的内核计算单元;
23、参数并行计算模块,用于利用所述内核计算单元所配置的并行线程单元,基于所述优化器参数列表内的优化器参数值进行模型参数的并行计算,得到更新后的模型参数;其中,所述更新后的模型参数用于对所述待训练模型进行更新,以对更新后的所述待训练模型进行训练。
24、本发明提供一种计算机设备,包括:处理器;用于存储处理器可执行指令的存储器;其中,所述处理器被配置为执行所述可执行指令以实现上述任一所述的方法。
25、本发明提供一种计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现上述任一项所述的方法。
26、本发明提供一种计算机程序产品,所述程序产品包括计算机程序,计算机程序被处理器执行上述任一项所述的方法。
27、本发明的实施例提供的技术方案至少带来以下有益效果:
28、通过在模型训练的模型参数更新阶段,获取图形处理器的显存中存储的优化器参数列表;然后,启动优化器更新算子对应的内核计算单元,并利用内核计算单元包括的并行线程单元,基于优化器参数列表内的优化器参数值进行模型参数的并行计算,得到待训练模型更新后的模型参数;最后,利用更新后的模型参数更新待训练模型。可见,本发明的实施例需要启动优化器更新算子的内核计算单元一次或者几次,减少kernel启动次数,降低kernel启动开销占比,提升模型的训练效率。
29、本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.一种语言模型的模型参数更新方法,其特征在于,应用于包括图形处理器和中央处理器的异构服务器;所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述基于所述优化器参数列表内的优化器参数值进行模型参数的并行计算,得到所述待训练模型更新后的模型参数,包括:
3.根据权利要求1所述的方法,其特征在于,所述优化器参数列表包括第t-1个训练轮次的第一动量列表、第t个训练轮次的梯度列表;所述基于所述优化器参数列表内的优化器参数值进行模型参数的并行计算,得到所述待训练模型更新后的模型参数,包括:
4.根据权利要求1所述的方法,其特征在于,所述优化器参数列表包括第t-1个训练轮次的第一一阶动量列表、第一二阶动量列表、第t个训练轮次的梯度列表;所述基于所述优化器参数列表内的优化器参数值进行模型参数的并行计算,得到所述待训练模型更新后的模型参数,包括:
5.根据权利要求1至4任一项所述的方法,其特征在于,所述待训练模型为bert模型。
6.根据权利要求5所述的方法,其特征在于,所述bert模型的多层感知机mlp模块包括第一融合算子和第二融合算子,其中,所述第一融合算子、所述第二融合算子是基于所述多层感知机mlp模块包括的线性算子、偏置算子和激活算子进行算子融合得到的。
7.根据权利要求5所述的方法,其特征在于,所述方法还包括:
8.根据权利要求5所述的方法,其特征在于,所述待训练模型的模型状态量包括的张量划分为n个张量集合;所述n个张量集合与n个并行进程之间具有一一对应关系;所述张量为所述待训练模型包括的网络层的输入和输出;n为大于1的整数;所述方法还包括:
9.一种语言模型的模型参数更新装置,其特征在于,应用于包括图形处理器和中央处理器的异构服务器;所述装置包括:
10.一种计算机设备,其特征在于,包括:处理器;用于存储处理器可执行指令的存储器;其中,所述处理器被配置为执行所述可执行指令以实现权利要求1至8中任一项所述的方法。
技术总结
本发明公开了一种模型参数更新方法、装置、计算机设备以及存储介质。通过在模型训练的模型参数更新阶段,获取图形处理器的显存中存储的优化器参数列表;然后,启动优化器更新算子对应的内核计算单元,并利用内核计算单元包括的并行线程单元,基于优化器参数列表内的优化器参数值进行模型参数的并行计算,得到待训练模型更新后的模型参数;最后,利用更新后的模型参数更新待训练模型,该过程中需要启动优化器更新算子的内核计算单元一次或者几次,减少内核计算单元的启动次数,降低内核计算单元的启动开销占比,提升模型的训练效率。
技术研发人员:弓静
受保护的技术使用者:腾讯科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!