一种基于特征选取与GS-LSTM的磁盘故障预测
本发明属于人工智能和故障预测,涉及一种基于特征选取与gs-lstm的磁盘故障预测,主要基于磁盘的s.m.a.r.t.属性所产生的数据完成磁盘故障预测,可用于存储。
背景技术:
1、在当今大数据时代,大规模海量数据存储系统遍布各大数据中心,磁盘作为主要的存储介质,能否提供稳定可靠的数据访问能力,直接影响整个系统的可靠性。虽然理论上单个磁盘故障发生概率可能低于1%,但在数据中心发现磁盘实际的年故障率可能超过10%。磁盘故障不仅会造成其承载的业务中断,而且存储在磁盘上的数据丢失会给企业和个人带来不可估量的损失。ponemon institute报告称,数据中心的最大停机成本从2010年的100万美元增加到2016年的240万美元,而磁盘故障是主要原因。通过故障预测等手段,适时做好磁盘的更换和维护,有利于保障数据安全,并降低数据中心的运营成本。因此,磁盘故障预测有非常重要的研究价值。
2、现有磁盘故障预测大多是基于神经网络的故障预测方法,基本思路为:利用磁盘的s.m.a.r.t.属性所产生的历史数据作为输入,训练神经网络得到最优的预测模型;在进行故障预测时,输入实时磁盘的s.m.a.r.t.属性产生的数据,得到预测的磁盘状态。
3、xu等人在文献xu,chang,wang,gang,liu,xiaoguang,guo,dongdong,liu,tie-yan.health status assessment and failure prediction for hard drives withrecurrent neural networks[j].ieee transactions on computers,2016,65(11).中提出将磁盘的剩余寿命进行进行划分来定义磁盘的健康度,进而将磁盘的故障预测转化为多分类问题,使用递归神经网络建立模型,以基于逐渐变化的顺序s.m.a.r.t.属性来评估磁盘的健康状态。lima等人在文献lima,f.d.dos s.,amaral,g.m.r.,leite,l.g.de m.,gomes,j.p.p.,&machado,j.de c.(2017).predicting failures in hard drives withlstm networks.2017brazilian conference on intelligent systems(bracis).doi:10.1109/bracis.2017.72中提出将磁盘的剩余寿命属性离散化来定义磁盘的健康,将问题作为多标签分类任务来处理,使用lstm网络预测磁盘长期和短期的故障。wang等人在文献wang guochao,wang yu,sun xiaojie.multi-instance deep learning based onattention mechanism for failure prediction of unlabeled hard disk drives[j].ieee transactions on instrumentation and measurement,2021,70提出了一种基于长短期记忆网络和注意力机制的多实例长期数据分类方法来进行预测,将长时间序列hdd数据视为实例包,多实例学习将其分为子概念层中的多个实例,然后研究实例与包标签之间的关系,从而实现故障预测。
4、以上方法在进行磁盘故障预测的过程中,对于磁盘特征的选取多数研究都是基于专家知识选取磁盘特征或选择磁盘全部特征,从而导致对工业应用和预测模型效率低的问题。
技术实现思路
1、要解决的技术问题
2、为了避免现有技术的不足之处,本发明提出一种基于特征选取与gs-lstm的磁盘故障预测,采用相关性分析的特征选择方法,比现有方法所采用的特征具有更强的故障表征能力;针对磁盘正负样本严重不均衡的问题,使用smoteenn算法对训练样本进行平衡化处理;同时本发明采用网格搜索算法对lstm模型超参数进行优化,克服了现有方法超参数的选择方式效率较低,提高了模型的预测效果。
3、技术方案
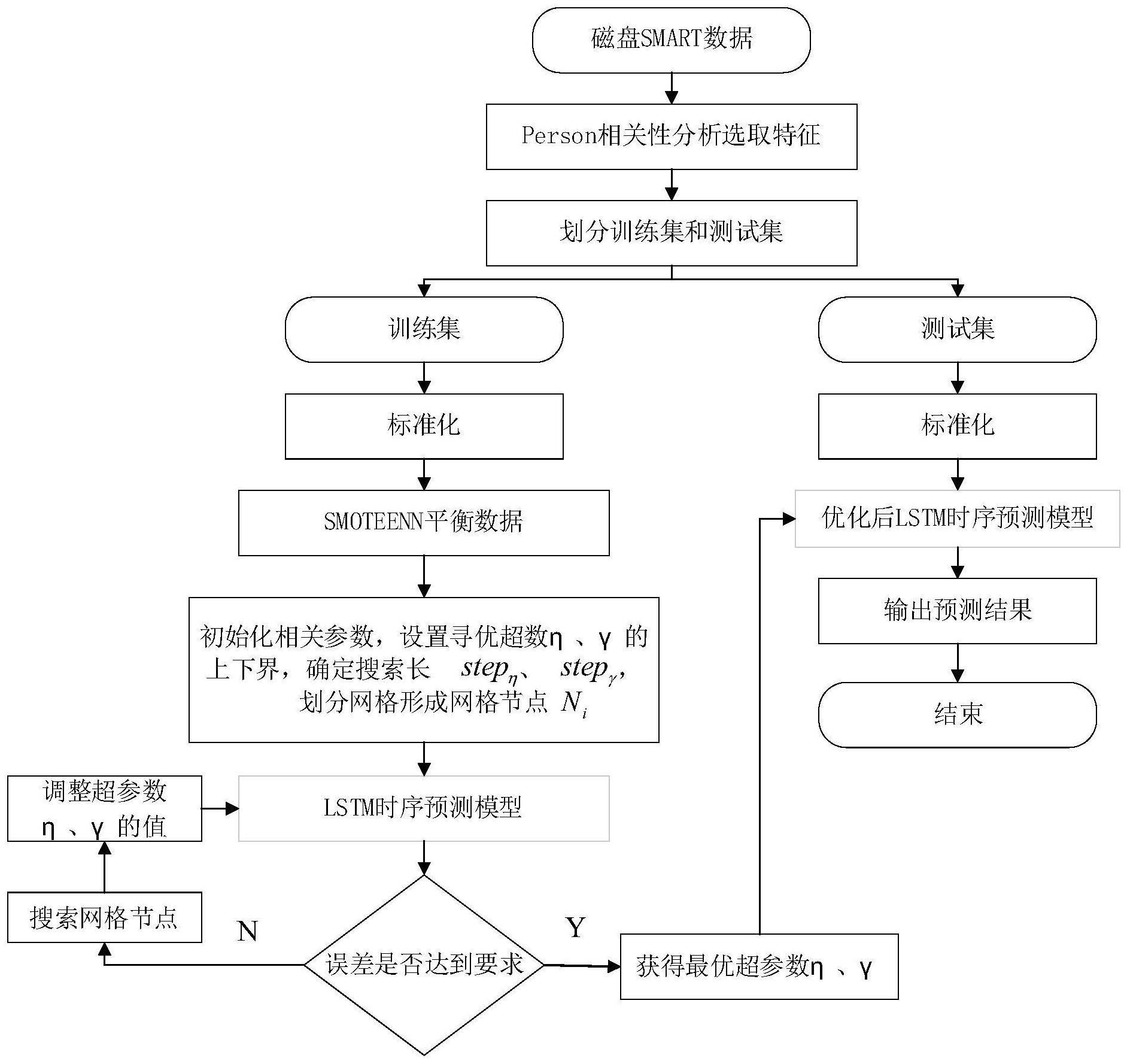
4、一种基于特征选取与gs-lstm的磁盘故障预测,其特征在于步骤如下:
5、步骤1、利用person相关性分析选取磁盘的s.m.a.r.t.属性:
6、将n块故障磁盘的每块磁盘发生故障前t天以及故障当天的s.m.a.r.t.属性数据,合并为t+1组,n块故障磁盘的t+1组数据合并为n*(t+1)组;其中故障磁盘的k个s.m.a.r.t.属性为xi(i=1,2,…,k);
7、随机n块正常磁盘,以每块磁盘的s.m.a.r.t.属性数据,合并为t+1组,n块故障磁盘的t+1组数据合并为n*(t+1)组;其中正常磁盘的k个s.m.a.r.t.属性为xj(j=1,2,…,k);
8、所述k个s.m.a.r.t.属性是rm空间中的k个变量,则故障磁盘的s.m.a.r.t.属性与正常磁盘s.m.a.r.t.属性的相关系数:
9、
10、式中,r(i,j)为pearson相关系数pccs,
11、计算这两个的序列的pearson相关系数,对比每个s.m.a.r.t.属性的皮尔逊相关系数,以0.00≤∣r∣<0.20的s.m.a.r.t.属性作为故障特征;
12、步骤2:将所有故障特征数据集划分为训练集和测试集;
13、步骤3:采用smoteenn算法平衡训练集的正负样本,形成正负样本平衡的训练集;
14、步骤4:以正负样本平衡的训练集作为gs-lstm故障预测模型的输入,基于正负样本平衡的训练集进行预测,并使用gs算法对模型的超参数进行优化,获得最优的lstm故障预测模型;
15、所述gs-lstm故障预测模型采用长短期记忆网络,采用lstm的网络层数γ和初始学习率η两个超参数:
16、网格搜索的目标函数为:minn(kt,ft)
17、满足
18、
19、式中,kt为训练集对应的预测序列,ft为测试集,stepγ和stepη分别表示为搜索步长。首先要预设lstm的网络层数γ和学习率η的取值范围,为了加快模型的寻优速度,η控制在一定的取值范围,γmax需要控制在较小范围内取值,然后分别选择合适的搜索步长,训练lstm模型,取最优的网络层数和学习率;
20、步骤5:测试集作为优化后的lstm时序预测模型输入,输出为磁盘故障预测结果。
21、所述步骤5得到的磁盘故障预测结果,做出分类结果混淆矩阵,根据矩阵并通过accuracy、far、fdr三个指标来评估模型:
22、accuracy:准确度,是所有预测中预测正确的比例,也是最常用的分类性能指标
23、
24、far:误检率,即一块硬盘实际为好盘,而模型预测为坏盘的比例:
25、
26、fdr:故障检出率,即一块硬盘实际为坏盘,而模型预测为坏盘的比例:
27、
28、其中分类结果混淆矩阵为:
29、
30、所述所有故障特征数据集的70%为训练集,30%为测试集。
31、所述步骤3采用smoteenn算法平衡训练集的正负样本是:首先通过smote过采样生成故障磁盘样本,再利用enn方法对生成的数据进行深度清洗,最后形成类别平衡的数据。
32、所述采样流程如下:
33、步骤(1):根据正常状态样本和故障状态样本的数量确定采样倍率n;
34、步骤(2):对于故障集中的每一个样本xi,i∈(1,2,…,t),找到其k个近邻样本;
35、步骤(3):从xi的k个最邻近样本中,随机选取m个最邻近样本,记作xij,j=1,2,…,m;
36、步骤(4):对每个xij样本进行随机线性插值,构造新样本xnew;
37、xnew=xi+rand(0,1)×|xij-(xi)|
38、步骤(5):将合成的新样本加入不平衡样本集以平衡样本,形成正负平衡的样本;
39、步骤(6):利用最近邻规则enn,对形成正负平衡的样本中的每一个样本进行预测,若预测的故障状态标签与实际标签不符,则删除该样本,得到正负样本平衡的训练集。
40、所述长短期记忆网络模型采用文献“hochreiter,s.,schmidhuber,j.,1997.longshort-term memory.neural computation 9,1735–1780.”所公开的方法,构建长短期记忆网络模型。
41、所述步骤4的gs算法优化lstm步骤的具体步骤为:
42、步骤(4.1)确定超参数的范围,初始学习率η∈[0.0001,0.001]、网络层数γ∈[1,5],选择合适的搜索步长,stepη设置为0.0001,stepγ设置为1,在超参数的空间中划分网格并形成网格节点ni;
43、步骤(4.2)计算每一网格节点ni下的目标函数值;
44、步骤(4.3)若所有网格节点已搜索完毕,对比每一网格节点ni,根据目标函数值,输出最优超参数η、γ。
45、有益效果
46、本发明提出的一种基于特征选取与gs-lstm的磁盘故障预测,针对磁盘正负样本严重不均衡的问题,使用smoteenn算法对训练样本进行平衡化处理;同时本发明采用网格搜索算法对lstm模型超参数进行优化,克服了现有方法超参数的选择方式效率较低,提高了模型的预测效果。
47、本发明由于采用pccs对磁盘s.m.a.r.t.属性进行特征选取,比现有方法所采用的特征具有更强的故障表征能力,同时本发明为了更好的应用于工作场景,设计了网格优化算法的预测模型按需构造模型,对于不同的磁盘型号有更好的预测模型使模型泛化性强。克服了现有方法不依赖于专业知识对s.m.a.r.t.属性特征进行选取和工业应用和预测模型效率低的问题,该模型在保持较低误检率的同时,有着较高的预测准确性和故障检出率。
- 还没有人留言评论。精彩留言会获得点赞!