基于事件时序信息的分布式异构数据流合流方法与流程
本发明涉及异构数据流的处理技术,具体涉及一种基于事件时序信息的异构数据流的flink合流方法。
背景技术:
1、flink作为一种分布式数据流处理框架,用于无边界和有边界的数据流上进行有状态(流处理过程中,前后数据存在一些逻辑关系,在处理时需要关注)的计算,在实时流处理领域中得到了越来越多的使用,对于不同异构(异构是指数据结构不同的数据集合)流水合流处理提供了一些基本的操作接口,但是考虑到真实的应用场景,flink本身的合流功能有其局限性。
2、flink可以通过联合(union)方法将拥有相同数据类型的流合并,但要求合并的流水必须是相同数据类型,对于异构的流水不支持;也可以实现基于窗口(window)的流合并,但对于一些不使用窗口的flink任务不适用;而通过连接(connect)方法,可以将两个流水合并为一个流水,但这种方法在事件时序要求严格的场景中会面临合流需要大量的复杂逻辑处理的问题,比如基于事件时间,要求不同流水时序满足某种对齐策略,同时对于某些特定事件也需要触发特殊计算,考虑交易市场中的委托流水和成交流水,有不同的数据类型,同时附加时间以及交易、收盘等特殊事件,在合流时容易出现流水互相等待而出现的卡顿等问题,从而导致checkpoint(checkpoint是指flink中的状态每隔一段时间会进行持久化存储,是一种轻量级分布式快照实现的容错机制)检查点提交超时,导致整个任务运行失败。
3、因此,目前业界亟待能够高效解决这种异构事件时间数据流的合流问题的产品或者算法。
技术实现思路
1、以下给出一个或多个方面的简要概述以提供对这些方面的基本理解。此概述不是所有构想到的方面的详尽综览,并且既非旨在指认出所有方面的关键性或决定性要素亦非试图界定任何或所有方面的范围。其唯一的目的是要以简化形式给出一个或多个方面的一些概念以为稍后给出的更加详细的描述之序。
2、本发明的目的在于解决上述问题,提供了一种基于事件时序信息的分布式异构数据流合流方法,可实现自主的控制合流过程,将复杂的业务逻辑简单化,解决了合流过程中的复杂逻辑和性能问题,达到高效稳定的合流效果,解决了业务需求。
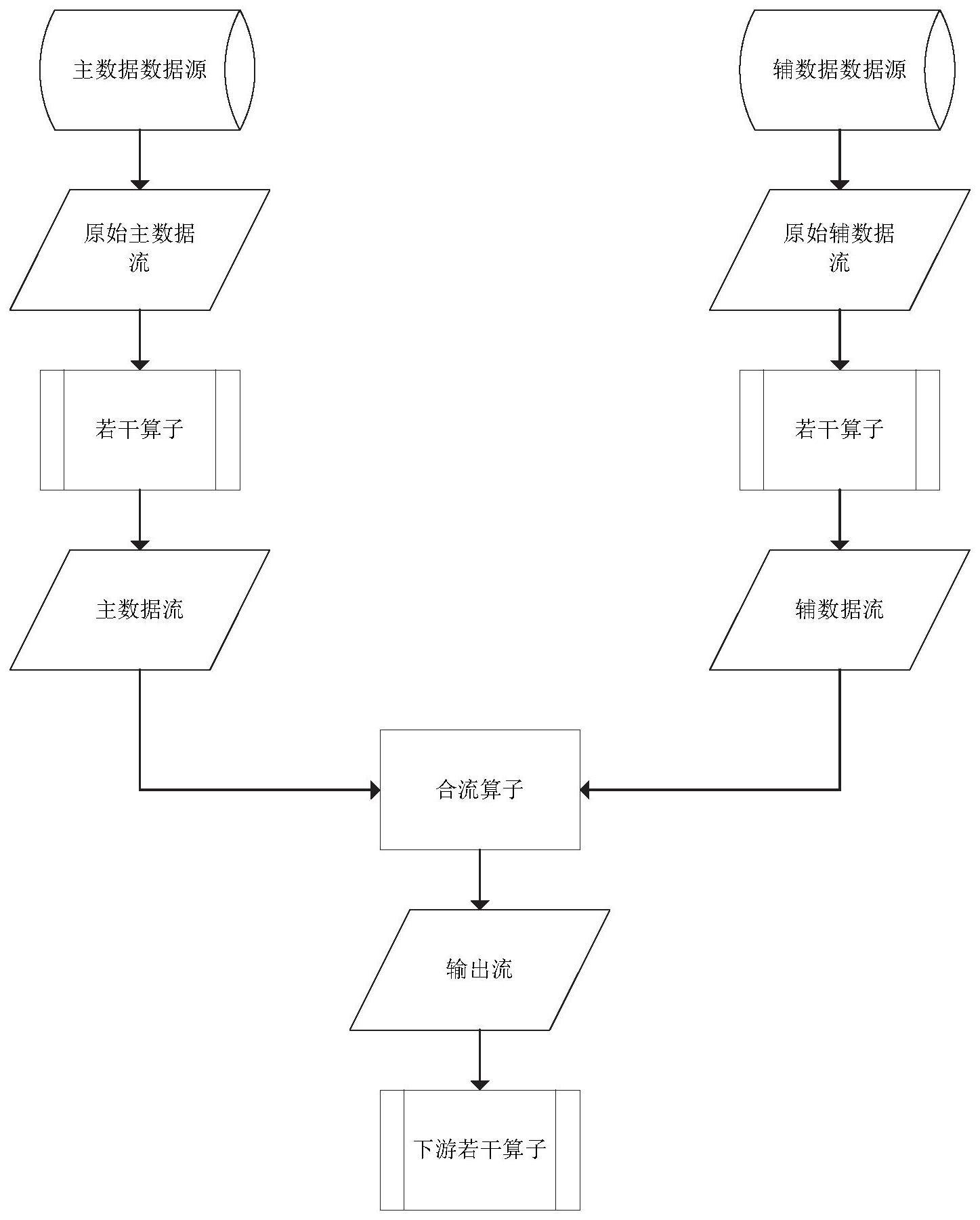
3、本发明的技术方案为:本发明揭示了一种基于事件时序信息的分布式异构数据流合流方法,方法包括主数据流和辅数据流的两个处理流程,其中:
4、主数据流的处理流程包括:
5、步骤1-1:接收主数据流数据存入到一级缓存;
6、步骤1-2:判断所接收到的主数据流数据是否满足一级缓存准出条件,如果满足则进入步骤1-3,如果不满足则主数据流的处理流程结束;
7、步骤1-3:一级缓存提交到二级缓存;
8、步骤1-4:根据当前时间清除辅数据二级缓存中过期的数据;
9、步骤1-5:检查辅数据二级缓存中是否有值。如果有值则进入步骤1-6,否则主数据流的处理流程结束;
10、步骤1-6:合并主辅二级缓存数据时,以主数据二级缓存中每个时刻的数据为基准,进行合并;
11、辅数据流的处理流程包括:
12、步骤2-1:接收辅数据流数据进入一级缓存;
13、步骤2-2:判断所接收的辅数据流数据是否满足一级缓存,如满足则进入下一步,如果不满足则辅数据流的处理流程结束;
14、步骤2-3:将一级缓存提交到二级缓存;
15、步骤2-4:判断主数据流是否结束,如果结束则辅数据流的流程结束,如果未结束则进入步骤2-5;
16、步骤2-5:合并主辅二级缓存数据时,以主数据二级缓存中每个时刻的数据为基准,进行合并。
17、根据本发明的基于事件时序信息的分布式异构数据流合流方法的一实施例,步骤1-2中的主数据流数据的一级缓存准出条件包括:
18、接收到下一个时刻的事件数据;或
19、在某一时刻满足计算维度的所有数据都已经到达;或
20、接收到数据流结束的事件。
21、根据本发明的基于事件时序信息的分布式异构数据流合流方法的一实施例,步骤1-3中进一步包括:
22、在二级缓存数据提交的过程中对数据进行补齐操作。
23、根据本发明的基于事件时序信息的分布式异构数据流合流方法的一实施例,步骤1-4由主数据驱动,每当有新数据提交到主数据的二级缓存,做以下处理:
24、对于辅数据中的初始化数据,在主数据流接收到第一条事件数据之后就对初始化数据进行清理;
25、在辅数据流中找到某个时刻,其中该时刻是小于主数据流中的当前时刻,然后将辅数据流中所有小于该时刻的数据进行清理。
26、根据本发明的基于事件时序信息的分布式异构数据流合流方法的一实施例,步骤1-5中进一步包括:
27、每次有新的数据提交到主数据的二级缓存时,处理所有的二级缓存中的数据,当主数据流接收到第一条事件数据,接收到的时刻点之前只和辅数据流中的初始化数据进行合并;
28、再检查以下条件是否满足,在找到满足条件的对应的辅数据的二级缓存数据后,将主辅二级数据按设定的业务逻辑进行合并计算,并输出结果供下游计算,其中条件是:
29、1)检查当前主数据流数据的时刻是否大于或等于辅数据流中某数据的时刻;
30、2)检查辅数据二级缓存中的最大时刻是否大于或等于当前主数据流数据的时刻或者数据流结束时刻。
31、根据本发明的基于事件时序信息的分布式异构数据流合流方法的一实施例,步骤1-6中,对于主数据流先于辅数据流结束的场景,由辅数据流触发合并二级缓存数据的逻辑调用,反之由主数据流触发。
32、根据本发明的基于事件时序信息的分布式异构数据流合流方法的一实施例,步骤1-6中,在处理主数据流时,会接收到表明主数据流结束的特殊事件数据,这时在合流算子中保存下结束状态,供辅数据流处理逻辑判断使用。
33、根据本发明的基于事件时序信息的分布式异构数据流合流方法的一实施例,步骤2-2中的辅数据流数据的一级缓存准出条件包括:
34、接收到下一个时刻的事件数据;或
35、在某一时刻满足计算维度的所有数据都已经到达;或
36、接收到数据流结束的事件。
37、根据本发明的基于事件时序信息的分布式异构数据流合流方法的一实施例,分布式异构数据流是flink数据流。
38、本发明对比现有技术有如下的有益效果:本发明在flink的连接(connect)方法的基础上,实现了自主的控制合流过程,将复杂的业务逻辑简单化。针对特殊事件时间数据流的合流做了设计与实现,解决了合流过程中的复杂逻辑和性能问题,达到高效稳定的合流效果,解决了业务需求。详细而言,本发明是在flink中对于存在事件时序的异构数据流的合流做了二级缓存的设计,通过二级缓存简化了复杂的业务逻辑,同时对于原始流水进行了过滤,大大提升了流处理效率,降低了异构流水合流时两个流互相等待造成流处理卡顿的现象。
- 还没有人留言评论。精彩留言会获得点赞!