对认证页面进行数据爬取的方法及装置与流程
本公开涉及计算机信息处理领域,具体而言,涉及一种对认证页面进行数据爬取的方法、装置、电子设备及计算机可读介质。
背景技术:
1、网络爬虫(或简称爬虫),是一种自动抓取互联网上数据的工具。利用爬虫抓取数据时往往从一个或若干初始网页的url(统一资源定位器,uniform resource locator)开始,获得初始网页上的url,在抓取网页的过程中,一边按自己的业务需求对页面资源进行处理,例如截取包含某关键词的文本;一边不断从当前页面上抽取新的url,放入爬虫队列,递归爬取,直到满足系统的一定停止条件,如达到一定的页面爬取深度。
2、能否获取更多、更有效的页面资源是一款爬虫工具优秀与否的基本评判标准,现有的爬虫工具主要针对没有做限制的资源进行发掘,而无法有效处理一些特殊资源,比如有认证拦截的页面资源。
3、因此,需要一种新的对认证页面进行数据爬取的方法、装置、电子设备及计算机可读介质。
4、在所述背景技术部分公开的上述信息仅用于加强对本申请的背景的理解,因此它可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、有鉴于此,本申请提供一种对认证页面进行数据爬取的方法、装置、电子设备及计算机可读介质,能够爬取认证页面的数据,相较于普通的无法进行http认证的爬虫工具,本申请能够爬取更多的页面资源。
2、本申请的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本申请的实践而习得。
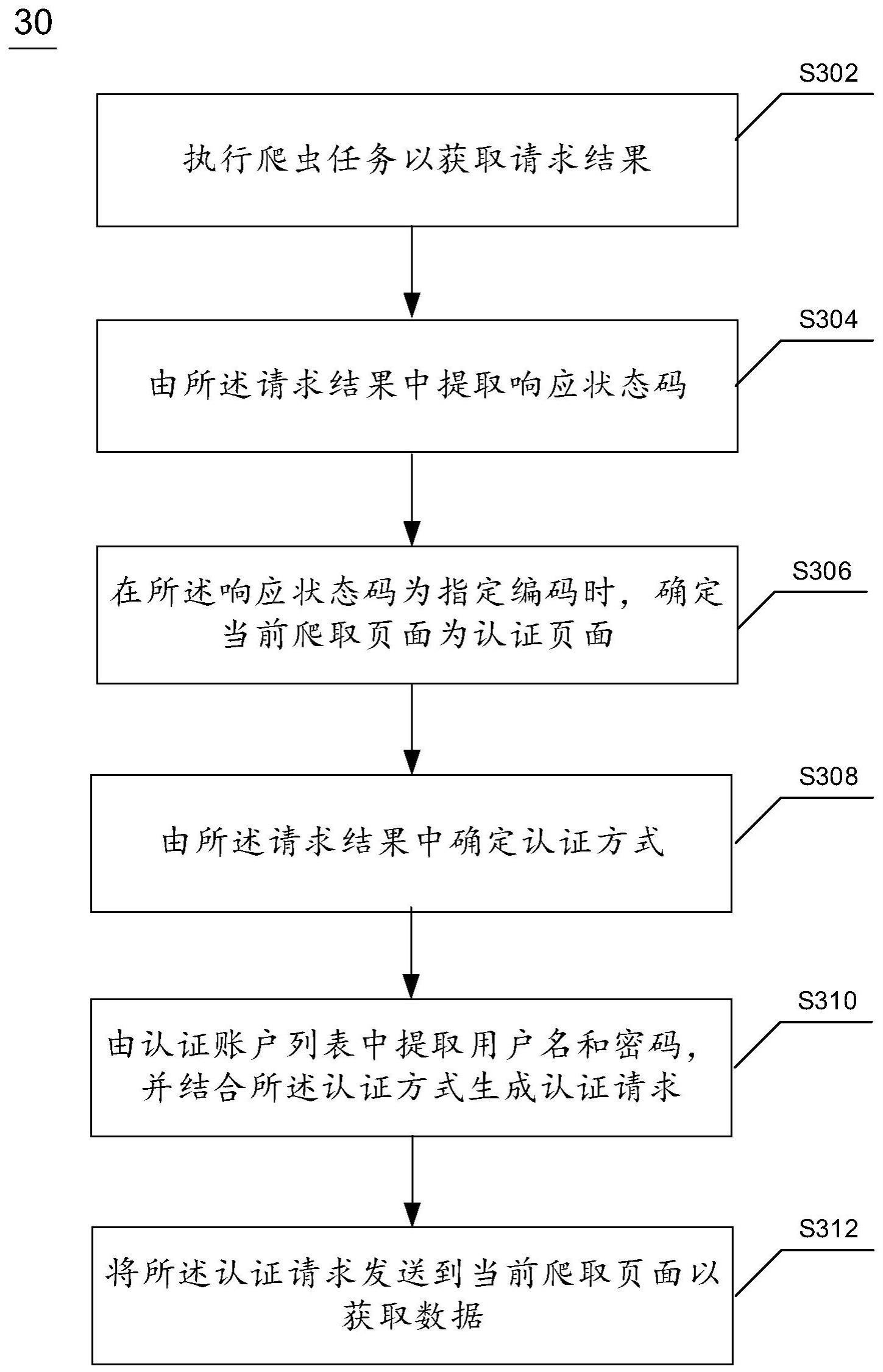
3、根据本申请的一方面,提出一种对认证页面进行数据爬取的方法,该方法包括:执行爬虫任务以获取请求结果;由所述请求结果中提取响应状态码;在所述响应状态码为指定编码时,确定当前爬取页面为认证页面;由所述请求结果中确定认证方式;由认证账户列表中提取用户名和密码,并结合所述认证方式生成认证请求;将所述认证请求发送到当前爬取页面以获取数据。
4、在本申请的一种示例性实施例中,执行爬虫队列中的爬虫任务获取请求结果之前,还包括:对目标端口进行监听以生成爬虫任务;在获取到爬虫任务后,将所述爬虫任务发送到任务池中;为任务池中的所述爬虫任务分配爬虫子进程。
5、在本申请的一种示例性实施例中,在获取到爬虫任务后,将所述爬虫任务发送到任务池中,包括:初始化任务状态为等待状态;在获取到爬虫任务后,将所述爬虫任务对应的任务配置储存到数据库;定时扫描数据库中的任务,以将所述爬虫任务发送到所述任务池。
6、在本申请的一种示例性实施例中,执行爬虫任务以获取请求结果,包括:爬虫子进程由任务池中提取所述爬虫任务;初始化爬虫客户端;将所述爬虫任务对应的目标url加入爬虫队列以获取请求结果。
7、在本申请的一种示例性实施例中,初始化爬虫客户端,包括:解析数据库中的任务配置数据获取任务参数;根据所述任务参数初始化所述爬虫客户端。
8、在本申请的一种示例性实施例中,将所述爬虫任务对应的目标url加入爬虫队列以获取请求结果,包括:将所述爬虫任务对应的目标url加入爬虫队列;基于爬虫队列的排序向所述目标url对应的页面发送请求;获取请求结果。
9、在本申请的一种示例性实施例中,由所述请求结果中确定认证方式,包括:由所述请求结果中提取响应头报文;提取响应头报文中的头部信息;截取所述头部信息中的预设区域字符;根据所述区域字符确定所述认证方式。
10、在本申请的一种示例性实施例中,由认证账户列表中提取用户名和密码,并结合所述认证方式生成认证请求,包括:由所述认证方式中确定协议拼接方式;将所述用户名和所述密码按照所述协议拼接方式进行拼接生成头部信息;根据所述头部信息生成所述认证请求。
11、在本申请的一种示例性实施例中,将所述认证请求发送到当前爬取页面以获取数据,包括:将所述认证请求发送到当前爬取页面;在请求结果为认证成功时,基于当前头部信息设置当前页面后续的url页面的认证请求。
12、在本申请的一种示例性实施例中,将所述认证请求发送到当前爬取页面以获取数据,还包括:在请求结果为认证失败时,由认证账户列表中提取其他用户名和密码,并结合所述认证方式生成认证请求。
13、根据本申请的一方面,提出一种对认证页面进行数据爬取的装置,该装置包括:爬虫模块,用于执行爬虫任务以获取请求结果;提取模块,用于由所述请求结果中提取响应状态码;确定模块,用于在所述响应状态码为指定编码时,确定当前爬取页面为认证页面;认证模块,用于由所述请求结果中确定认证方式;请求模块,用于由认证账户列表中提取用户名和密码,并结合所述认证方式生成认证请求;数据模块,用于将所述认证请求发送到当前爬取页面以获取数据。
14、根据本申请的一方面,提出一种电子设备,该电子设备包括:一个或多个处理器;存储装置,用于存储一个或多个程序;当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现如上文的方法。
15、根据本申请的一方面,提出一种计算机可读介质,其上存储有计算机程序,该程序被处理器执行时实现如上文中的方法。
16、根据本申请的对认证页面进行数据爬取的方法、装置、电子设备及计算机可读介质,通过执行爬虫任务以获取请求结果;由所述请求结果中提取响应状态码;在所述响应状态码为指定编码时,确定当前爬取页面为认证页面;由所述请求结果中确定认证方式;由认证账户列表中提取用户名和密码,并结合所述认证方式生成认证请求;将所述认证请求发送到当前爬取页面以获取数据的方式,能够爬取认证页面的数据,相较于普通的无法进行http认证的爬虫工具,本申请能够爬取更多的页面资源。
17、应当理解的是,以上的一般描述和后文的细节描述仅是示例性的,并不能限制本申请。
技术特征:
1.一种对认证页面进行数据爬取的方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,执行爬虫队列中的爬虫任务获取请求结果之前,还包括:
3.如权利要求2所述的方法,其特征在于,在获取到爬虫任务后,将所述爬虫任务发送到任务池中,包括:
4.如权利要求1所述的方法,其特征在于,执行爬虫任务以获取请求结果,包括:
5.如权利要求4所述的方法,其特征在于,初始化爬虫客户端,包括:
6.如权利要求4所述的方法,其特征在于,将所述爬虫任务对应的目标url加入爬虫队列以获取请求结果,包括:
7.如权利要求1所述的方法,其特征在于,由所述请求结果中确定认证方式,包括:
8.如权利要求9所述的方法,其特征在于,由认证账户列表中提取用户名和密码,并结合所述认证方式生成认证请求,包括:
9.如权利要求1所述的方法,其特征在于,将所述认证请求发送到当前爬取页面以获取数据,包括:
10.如权利要求9所述的方法,其特征在于,将所述认证请求发送到当前爬取页面以获取数据,还包括:
11.一种对认证页面进行数据爬取的装置,其特征在于,包括:
技术总结
本申请涉及一种对认证页面进行数据爬取的方法、装置、电子设备及计算机可读介质。该方法包括:执行爬虫任务以获取请求结果;由所述请求结果中提取响应状态码;在所述响应状态码为指定编码时,确定当前爬取页面为认证页面;由所述请求结果中确定认证方式;由认证账户列表中提取用户名和密码,并结合所述认证方式生成认证请求;将所述认证请求发送到当前爬取页面以获取数据。本申请涉及的对认证页面进行数据爬取的方法、装置、电子设备及计算机可读介质,能够爬取认证页面的数据,相较于普通的无法进行HTTP认证的爬虫工具,本申请能够爬取更多的页面资源。
技术研发人员:吕振旺,曹浪,杨圣华
受保护的技术使用者:杭州迪普科技股份有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!