一种油浸式变压器故障诊断方法与流程
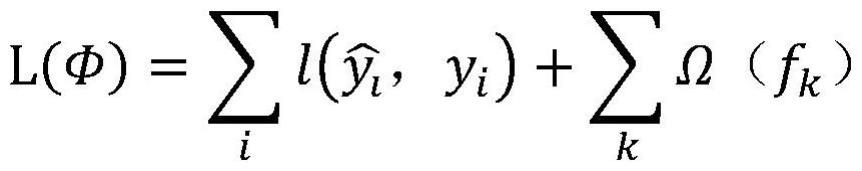
本发明涉及变压器故障诊断,特别涉及了一种油浸式变压器故障诊断方法。
背景技术:
1、油浸式变压器是输变电系统的关键设备之一,其运行状态决定着电力系统能否安全可靠运行。然而,我国目前尚在投运的油浸式变压器中,有很大一部分运行年限较长,存在绝缘劣化等故障隐患。油浸式变压器发生绝缘老化时会产生少量气体溶解在绝缘油中,油中溶解气体的组成成分及其比例关系能够反映变压器的运行工况。正常运行的油浸式变压器,由于绝缘老化裂解等原因会产生极少量的气体,其主要成分为氢气、甲烷、乙烷、乙烯、乙炔、一氧化碳和二氧化碳。变压器故障类型和气体成分的变化呈现较强的相关性,因此对气体组分、含量进行分析的油中溶解气体分析dga(dissolved gas analysis)方法是目前最为重要的变压器状态检测和故障诊断方法之一。
2、但dga存在着状态编码不完备、编码界限过于绝对的问题,在实际应用中存在局限性。当前主流的变压器故障诊断模型分为非集成学习模型和集成学习模型。其中非集成学习的方法包bp神经网络、支持向量机(svm)、贝叶斯网络等,上述方法改进了传统模型的计算速度和精度,但均存在局限性:bp神经网络学习能力强,但是易陷入局部最优,需要人为调整大量参数,且收敛速度较慢;svm本质为二分类器,在处理变压器故障诊断等多分类问题时效率较低;贝叶斯网络要求条件属性较多等。基于集成学习的方法主要有随机森林rf和梯度提升树2个分支。rf以多个决策树为基分类器建立组合模型,通过减小方差提高预测精度,但在处理噪声较大的分类和回归问题时易产生过拟合的问题;gbdt通过降低偏差的方式减小总误差,且对调参的要求较低,具有更好的鲁棒性,但由于其个体学习器之间存在强依赖关系,无法并行训练,因此模型的训练速度较慢。
技术实现思路
1、本发明的目的是克服现有技术中存在的油浸式变压器故障诊断速度慢、效率低,诊断精度低的问题,提供了一种油浸式变压器故障诊断方法,利用xgboost,提高了模型的泛化能力,防止过拟合,有更高的适应性和鲁棒性;xgboost并行和分布式的计算模式也大幅提高了其训练速度,同时提高了油浸式变压器故障诊断精度以及诊断的稳定性。
2、为了实现上述目的,本发明采用以下技术方案:一种油浸式变压器故障诊断方法,包括下列步骤:
3、s1:以油中溶解气体分析为依据,采用无编码比值方法提取油浸式变压器实时运行特征;
4、s2:对提取的特征数据进行归一化处理;
5、s3:以归一化处理后的特征数据作为输入,对基于xgboost的故障诊断模型进行训练;
6、s4:利用遗传算法对基于xgboost的故障诊断模型进行优化;
7、s5:利用优化后的故障诊断模型,对油浸式变压器进行故障诊断。
8、极端梯度提升-xgboost算法,以损失函数的负梯度为依据训练多个个体学习器,并按照一定策略组合成一个准确可靠的集成学习器。xgboost在损失函数中加入正则化项对模型的复杂程度施加惩罚,以提高模型的泛化能力,防止过拟合;并行和分布式的计算模式也大幅提高了其训练速度。本发明采用无编码比值法提取变压器实时运行的特征;采用归一化方法处理提取后的特征数据;将处理后的数据作为样本训练xgboost模型,并采用遗传算法(ga)对模型的多个超参数同时进行优化,最终建立基于xgboost的变压器故障诊断模型,实现对油浸式变压器运行状态的实时精准诊断。能够稳定可靠地提升变压器故障诊断的准确率和稳定性。
9、作为优选,所述的步骤s1中,所述无编码比值提取的油浸式变压器实时运行特征即油浸式变压器器油中溶解的特征气体含量比值,利用油中溶解的特征气体含量比值与油浸式变压器故障类型的相关性,分析判断变压器故障类型,所述无编码比值法包括九个维度的特征。
10、油浸式变压器故障诊断中,dga气体的特征编码方式较多,如ice比值法(包含3个维度的特征)、rogers比值法(包含4个维度的特征)等,不同的编码方式可提取变压器内部不同的故障信息,从而对后续故障诊断的结果产生影响。当变压器发生不同类型的故障时,特定的气体组分会迅速增加,例如绝缘油过热时,ch4和c2h4的比例迅速增大;高能放电时,h2和c2h2含量升高。变压器故障类型和气体成分的变化呈现较强的相关性。本发明采用无编码比值作为油浸式变压器故障诊断模型的特征输入,利用油中溶解特征气体含量比值与故障类型的相关性来诊断变压器故障类型。与传统的比值法相比,无编码比值法包含了更多维度的特征信息,解决了三比值法编码不完备的问题,能够提升诊断结果的准确性。
11、作为优选,利用如下公式对提取的特征数据进行归一化处理:
12、
13、式中,其中,x ij为第i个样本中第j个特征气体含量;x′ij为归一化的特征气体含量。
14、油浸式变压器油中溶解特征气体包括氢气、甲烷、乙烷、乙烯、乙炔,这五种气体含量分散性较大,直接作为样本输入会对诊断精度造成影响。本发明采用特征气体含量比值而非单一气体含量作为样本输入,因此需要对特征气体含量进行归一化处理。
15、作为优选,所述步骤s3包括基于xgboost的故障诊断模型构建:
16、s3.1:对一个有n个样本、m个特征的数据集d,对于每个样本,各分类回归树依据不同分类规则将其分类到叶子节点中,通过累加对应叶子的分数ω,获得最终预测结果每棵分类回归树的每个叶子节点对应一个连续分数值;
17、s3.2:最小化正则化目标:
18、
19、
20、得到目标函数,构造基于xgboost的故障诊断模型,式中:φ为基于xgboost的故障诊断模型中的函数集合;γ、λ为控制模型复杂程度的正则化参数;
21、s3.3:利用加法学习的方式对基于xgboost的故障诊断模型进行训练。
22、γ、λ为控制模型复杂程度的正则化参数,参数值越大,模型越不容易过拟合。l(φ)为可微的凸损失函数,用于度量预测值与标签值的差距;为损失函数,用于度量cart预测值与真实值之间的差距;∑kω(fk)为正则项,用于对模型的复杂程度进行惩罚,该附加的正则项能够平滑各叶节点的权重,避免过拟合。
23、作为优选,所述步骤s3.3进一步表示为:
24、s3.3.1:对基于xgboost的故障诊断模型进行训练前,对油浸式变压器故障类型进行编码;
25、s3.3.2:将无编码比值作为基于xgboost的故障诊断模型的输入,将样本数据按比例随机分为训练集和测试集,所述样本数据为无编码比值及其对应的故障类型;
26、s3.3.3:设置基于xgboost的故障诊断模型的初始参数,并进行预训练。
27、油浸式变压器故障类型分为低温过热、中温过热、高温过热、局部放电、低能放电、高能放电、低能放电兼过热、高能放电兼过热8种。
28、作为优选,所述步骤s3中,所述基于xgboost的故障诊断模型以分类回归树为基分类器,采用集成学习中梯度提升的方法进行加法训练,所述加法训练由一个常数预测开始,在每次迭代过程中,以最小化正则化目标函数为依据生成新的弱学习器并将其加入现有模型中;利用精确贪心算法,从单叶节点开始迭代向树中加入分支,对每个特征的所有数据进行排序,并按照顺序访问数据,在基于xgboost的故障诊断模型的训练中,找到最佳分裂点。
29、通过多轮迭代提升基于xgboost的故障诊断模型的准确率。
30、作为优选,所述步骤s4中包括:
31、在基于xgboost的故障诊断模型训练过程中,选取对模型性能有影响的参数,利用遗传算法对选取的超参数进行优化;所述遗传算法参数设置为:采用实数编码方式,种群个数为n,适应度函数为xgboost故障诊断模型诊断正确率。
32、在基于xgboost的故障诊断模型训练过程中,迭代次数过少易造成欠拟合,导致模型对问题的求解能力不足,而迭代次数过多又可能造成过拟合,使得模型对于训练数据表达能力过强而泛化性能低下。学习率η过小时,梯度下降很慢,过大时又可能跨过最优值,产生振荡;同时模型中其他参数,如决策树的最大深度dmax、随机样本的抽取比例、特征的抽取比例、决策树节点分裂标准都会对模型学习能力和分类性能产生影响,本发明选取对基于xgboost的故障诊断模型由影响的超参数,利用遗传算法进行优化,提高基于xgboost的故障诊断模型性能。
33、作为优选,所述步骤s4还包括:
34、b1:利用遗传算法不断对基于xgboost的故障诊断模型参数进行调整;
35、b2:判断是否达到最大迭代次数或者终止条件,若达到则将此时的训练参数值作为模型的最优参数,否则返回步骤b2;
36、b3:利用测试集对模型的诊断效果进行测试,输出故障分类结果。
37、利用遗传算法进行优化,提高基于xgboost的故障诊断模型性能。
38、因此,本发明具有如下有益效果:1、利用xgboost,提高了模型的泛化能力,防止过拟合,有更高的适应性和鲁棒性;2、xgboost并行和分布式的计算模式也大幅提高了其训练速度,同时提高了油浸式变压器故障诊断精度以及诊断的稳定性;3、利用遗传算法进行优化,提高基于xgboost的故障诊断模型性能。
- 还没有人留言评论。精彩留言会获得点赞!