一种基于激光雷达的交通目标检测系统
1.本发明涉及交通目标检测系统技术领域,尤其涉及一种基于激光雷达的交通目标检测系统。
背景技术:
2.随着激光雷达点云进行3d目标检测在自动驾驶领域的快速发展,智能驾驶系统中的环境感知不断扩展。实际应用中,障碍物检测功能是环境感知系统中的基本功能,障碍物类型主要包括行人、车辆、自行车等结构化道路上的常见物体。激光雷达可以直接探测目标的真实距离和尺寸,是自动驾驶方案中的主要传感器,激光雷达与摄像头不同,可以直接测量目标的真实尺寸和距离。
3.但是激光雷达产生的点云数据是无序的数据,而且点云数据相比图像更稀疏,随着距离的增加点云数据密度逐渐降低。针对激光雷达点云数据的稀疏性和无序性特点,现有voxel-based和poin-based两种雷达点云特征处理方式。
4.然而,voxel_based方式由于使用体素来聚集点集特征,不可避免地带来了信息损失,point_based方式则由于需要逐点处理特征带来了计算效率低下的问题。所以亟需一种基于激光雷达的交通目标检测系统来克服上述不足之处。
技术实现要素:
5.本发明的目的是为了解决现有技术中存在的缺点,而提出的一种基于激光雷达的交通目标检测系统。
6.为了实现上述目的,本发明采用了如下技术方案:
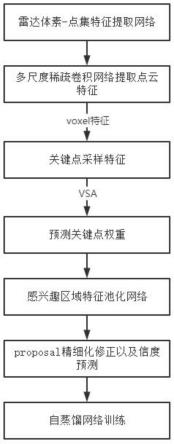
7.一种基于激光雷达的交通目标检测系统,包括雷达体素-点集特征提取网络,所述雷达体素-点集特征提取网络包括:
8.基于体素的多尺度稀疏卷积网络;
9.基于关键点采样的特征提取网络;
10.感兴趣区域的特征池化网络;
11.所述雷达体素-点集特征提取网络的特征提取修正方法包括如下步骤:
12.s1:首先,通过点云场景划分体素并将其送入多尺度的3d系数卷积网络来提取体素特征并将其转换到bev视角特征,进行目标类别和目标框的预测并生成proposal;
13.s2:然后,采用fps的方式采样关键点,并使用vsa模块为关键点提取多尺度的体素,原始点云以及bev特征;
14.s3:最后,将基于体素的多尺度稀疏卷积网络得到的proposal划分为多个网格,通过池化操作将关键点特征提取到网格点上,进而利用该特征进行目标框的精细化修正。
15.优选的:所述检测系统中,将3d稀疏卷积网络进行体素的特征提取方法,作为backbone并生成3d proposal;其中:
16.3d体素cnn网络;将点云输入p划分成l
×h×
w个体素网格,其中非空的体素网格特
征为体素内所包含多个点的特征平均值;体素化后的点云特征通过一系列多尺度的3d卷积网络聚集点云局部特征以及全局特征,其3d卷积网络的下采样尺度分别为1
×
,2
×
,4
×
,8
×
;
17.3dproposal生成;将8
×
下采样的3d体素特征沿着z轴进行堆叠得到l/8
×
w/8的bev特征图表示;之后,为点云场景中多种目标生成候选锚框,每一类目标有2
×
l/8
×
w/8的3d的锚框,其尺寸为该类目标的平均尺寸大小,0
°
,90
°
两个方向。
18.进一步的:所述检测系统中,提出将多尺度的提速特征聚集到少量的关键点,使得关键点成为3d体素特征和proposal精细化调整网络之间的桥梁;
19.通过furthest-point-sampling(fps)算法从点云场景中选择n个关键点k={p1,p2,...,pn};采用fps算法进行关键点采样能够使得关键点遍布整个点云场景,以确保关键点特征能够表示整个场景的特征信息;
20.以关键点位置为参考点,使用sva模块来聚集关键点周围体素特征。
21.进一步优选的:所述检测系统中,f
(lk)
={f
1(lk)
,...,f
nk(lk)
}表示第k个尺度的3d体素特征;v()={v
1(lk)
,...,v
nk(lk)
}表示对应提速特征的3d坐标,该坐标是通过体素索引以及对应尺度体素的尺寸大小计算所得,nk表示第k尺度中非空体素的数量;对于每一个关键点pi而言,首先通过rk来确定它的邻近非空体素,将其表示为:
[0022][0023]
在这个过程中,将pi于v
j(lk)
的相对坐标与voxel特征合并到一起以表示两者间的相对位置关系;通过pointblock模块来生成关键点pi的特征表示:
[0024][0025]
m表示从s
i(lk)
中随机采样tk个体素的特征以达到节省计算量的目的;g表示用于编码体素特征和相对关系mlp网络;同时选择多个半径距离进行vsa操作;将多个尺度的体素特征聚集到关键点上,关键点pi的特征表示:
[0026][0027]
作为本发明一种优选的:所述检测系统中,扩展的vsa模块:除了在关键点上聚集多尺度的体素特征外,还将原始点云的以及八倍下采样所得bev的特征聚集到关键点上,将关键点pi投影到bev视图上,然后通过双线性插值的方法将邻近bev特征fi(bev)聚集到关键点上;最后,关键点特征表示所下式所示:
[0028][0029]
作为本发明进一步优选的:所述检测系统中,通过predicted keypoint weighting模块进行关键点的权重预测;pkw模块以3dbounding box的标注为监督,包含在3d目标框内关键点的监督标签就是前景关键点;最终,经过权重预测网络处理,关键点特征
如下式所示:
[0030][0031]
其中,a表示用于前景置信度预测的三层mlp网络和sigmoid函数;pkw网络通过focal loss进行训练。
[0032]
作为本发明再进一步的方案:所述检测系统中,用感兴趣区域的池化网络将关键点的特征按多个接受域同时聚集到感兴趣区域网格点上;将3d proposal划分成6
×6×
6个网格点,如下式表示:
[0033]
g={g1,
……
,g
216
}
[0034]
通过下式来确定每个网格点的邻近关键点:
[0035][0036]
其中,pj-gi用于保留网格点与邻近关键点pj之间的相对位置关系;进而采用pointnet模块将邻近关键点特征聚集编码到网格点gi上:
[0037][0038]
采用多种半径r来聚集不同接受域的关键点特征,并将不同接受域的特征合并到一起;然后将向量化后的特征经过两层mlp网络转换成256维度的特征来表示proposal。
[0039]
在前述方案的基础上:所述检测系统中,利用proposal的特征,精细化修正网络能够预测3d proposal的尺寸以及位置信息;整个精细化修正网络由两个分支组成:置信度预测分支和框回归分组,每一个分支由两层mlp网络组成;
[0040]
置信度预测网络采用3d感兴趣区域的roi以及对应gt之间的3d iou作为训练目标,对于第k个3d感兴趣区域,其置信度训练目标yk为:
[0041]
yk=min(1,max(0,2iou
k-0.5))
[0042]
然后将confidence gt与预测confidence score进行loss计算:
[0043][0044]
通过传统的基于残差的方式来获取目标框的回归目标,并使用smooth l1 loss进行优化。
[0045]
在前述方案的基础上优选的:所述检测系统中,对于输入为x以及k维度one-hot监督目标y的模型而言,将x输入到模型中得到z(x)=[z1(x),...,zk(x)]的logit vector;再经过一个softmax函数获得预测置信度p(x)=[p1(x),...,pk(x)];将置信度进行软化处理:
[0046][0047]
τ表示温度缩放的温度系数;将教师模型和学生模型的输出经过softmax后得到pt(x),ps(x);对于学生模型而言,其训练目标如下式所示:
[0048][0049]
当温度系数τ为1时,目标函数退化成ps(x)关于软监督目标的cross entropy函数。
[0050]
在前述方案的基础上进一步优选的:所述检测系统中,知识自蒸馏模型从模型本身获取知识进而提高的模型的泛化能力;第t个epoch,在自蒸馏处理下关于x的预测为p
ts
的目标函数为:
[0051][0052]
对于epoch的模型而言,其训练目标为(1-α)y+αpt-1s(x);参数α为对老师模型的信任程度。
[0053]
本发明的有益效果为:
[0054]
1.本发明将voxel_based和point_based方法结合在一起,使得该模型在同时具备voxel-based模型的高效性以及point-based模型的高性能表现;同时,为了进一步优化模型训练的过程,在模型训练过程中使用自蒸馏的方式对训练目标进行改进,使得模型能够更快的收敛,提高精准度。
[0055]
2.本发明对多个基于激光雷达点云的目标检测模型进行了检测性能对比实验,改进后模型在kitti数据集上取得了优异的性能,同时对自蒸馏模块进行了消融实验,实验结果证明自蒸馏模块对训练过程产生了巨大的作用。
附图说明
[0056]
图1为本发明提出的一种基于激光雷达的交通目标检测系统的流程图。
具体实施方式
[0057]
下面结合具体实施方式对本专利的技术方案作进一步详细地说明。
[0058]
实施例1:
[0059]
一种基于激光雷达的交通目标检测系统,包括雷达体素-点集特征提取网络,所述雷达体素-点集特征提取网络包括:
[0060]
基于体素的多尺度稀疏卷积网络;
[0061]
基于关键点采样的特征提取网络;
[0062]
感兴趣区域的特征池化网络;
[0063]
所述雷达体素-点集特征提取网络的特征提取修正方法包括如下步骤:
[0064]
s1:首先,通过点云场景划分体素并将其送入多尺度的3d系数卷积网络来提取体素特征并将其转换到bev视角特征,进行目标类别和目标框的预测并生成proposal;
[0065]
s2:然后,采用fps的方式采样关键点,并使用vsa模块为关键点提取多尺度的体素,原始点云以及bev特征;
[0066]
s3:最后,将基于体素的多尺度稀疏卷积网络得到的proposal划分为多个网格,通过池化操作将关键点特征提取到网格点上,进而利用该特征进行目标框的精细化修正。
[0067]
所述检测系统中,将3d稀疏卷积网络进行体素的特征提取方法,作为backbone并
生成3d proposal;其中:
[0068]
3d体素cnn网络;将点云输入p划分成l
×h×
w个体素网格,其中非空的体素网格特征为体素内所包含多个点的特征平均值,通常其特征包括点的3d坐标,反射强度属性;体素化后的点云特征将通过一系列多尺度的3d卷积网络聚集点云局部特征以及全局特征,其3d卷积网络的下采样尺度分别为1
×
,2
×
,4
×
,8
×
;
[0069]
3dproposal生成;将8
×
下采样的3d体素特征沿着z轴进行堆叠得到l/8
×
w/8的bev特征图表示;之后,为点云场景中多种目标生成候选锚框,每一类目标有2
×
l/8
×
w/8的3d的锚框,其尺寸为该类目标的平均尺寸大小,0
°
,90
°
两个方向;相比pointnet-based方法,采用3d体素cnn网络以及锚框策略能够实现更高的召回率;
[0070]
检测目标的精细化修正的讨论。一方面,直接在3d的体素化特征或者2d的特征图上进行proposal的精细化化修正会带来许多问题。其一,经backbone下采样网络处理的点云特征无法完成目标框的精细定位,影响其精细修正的效果;其二,即便将特征通过线性插值等方式进行上采样处理,其特征也是稀疏的,同样无法实现目标框的精细化修正。
[0071]
另一方面,pointnet网络中所提出的set abstraction操作能够以任意的半径范围从周围点提取特征;因此,用set abstraction的操作来实现有效的目标框的精细化修正工作。为了避免提取所有voxel特征带来的内存占用和计算效率的问题。提出选取点云场景中的部分关键点,并将voxel特征提取到部分关键点上。这样做既可以避免体素化特征过于稀疏的问题,还能够避免提取所有体素特征带来的内存占用等实现问题,极大的提升了目标框精细化修正的效果。
[0072]
所述检测系统中,提出将多尺度的提速特征聚集到少量的关键点,使得关键点成为3d体素特征和proposal精细化调整网络之间的桥梁;
[0073]
关键点采样,首先,通过furthest-point-sampling(fps)算法从点云场景中选择n个关键点k={p1,p2,...,pn};采用fps算法进行关键点采样能够使得关键点遍布整个点云场景,以确保关键点特征能够表示整个场景的特征信息;
[0074]
vsa模块;所选取的关键点只包含整个点云场景中的极少部分的特征信息;因此需要以关键点位置为参考点,使用sva模块来聚集关键点周围体素特征;
[0075]f(lk)
={f
1(lk)
,...,f
nk(lk)
}表示第k个尺度的3d体素特征;v()={v
1(lk)
,...,v
nk(lk)
}表示对应提速特征的3d坐标,该坐标是通过体素索引以及对应尺度体素的尺寸大小计算所得,nk表示第k尺度中非空体素的数量。对于每一个关键点pi而言,首先通过rk来确定它的邻近非空体素,将其表示为:
[0076][0077]
在这个过程中,将pi于v
j(lk)
的相对坐标与voxel特征合并到一起以表示两者间的相对位置关系;通过pointblock模块来生成关键点pi的特征表示:
[0078]
[0079]
这里m表示从s
i(lk)
中随机采样tk个体素的特征以达到节省计算量的目的;g表示用于编码体素特征和相对关系mlp网络;不同关键点邻近区域内的体素的个数有所差异,沿通道进行最大值池化操作能够有效的解决关键点之间的特征匹配问题;为了聚集多尺度的语义信息,同时选择了多个半径距离进行vsa操作;
[0080]
经过多次的vsa操作,能够将多个尺度的体素特征聚集到关键点上;经过合并操作后,将得到如下式所示的关键点pi的特征表示:
[0081][0082]
扩展的vsa模块:除了在关键点上聚集多尺度的体素特征外,还将原始点云的以及八倍下采样所得bev的特征聚集到关键点上;原始点云的特征聚集操作如式(2)所示;为了实现bev特征聚集,将关键点pi投影到bev视图上,然后通过双线性插值的方法将邻近bev特征fi(bev)聚集到关键点上;最后,关键点特征表示所下式所示:
[0083][0084]
预测关键点权重:
[0085]
现在,已经得到了有小部分关键点编码的场景特征表示,需要进一步利用这些关键点特征进行目标框的精细化修正工作;利用fps算法进行采样所得到的关键点遍布整个点云场景,前景区域和背景区域均有关键点分布;为了提高精细化修正的精确率,需要将位于前景区域的关键点权重设置的更大一些,背景区域的关键点权重小一些;
[0086]
因此,通过predicted keypoint weighting模块进行关键点的权重预测;pkw模块以3d bounding box的标注为监督,即包含在3d目标框内关键点的监督标签就是前景关键点;最终,经过权重预测网络处理,关键点特征如下式所示:
[0087][0088]
其中,a表示用于前景置信度预测的三层mlp网络和sigmoid函数;pkw网络通过focal loss进行训练;设置超参数以解决前景,背景点不均衡的问题。
[0089]
感兴趣区域特征池化网络:提出用感兴趣区域的池化网络将关键点的特征按多个接受域同时聚集到感兴趣区域网格点上;将3dproposal划分成6
×6×
6个网格点,如下式表示:
[0090]
g={g1,
……
,g
216
[0091]
通过下式来确定每个网格点的邻近关键点:
[0092][0093]
其中,pj-gi用于保留网格点与邻近关键点pj之间的相对位置关系。进而采用pointnet模块将邻近关键点特征聚集编码到网格点gi上:
[0094][0095]
其中m和g和式(2)保持一致;采用多种半径r来聚集不同接受域的关键点特征,并
将不同接受域的特征合并到一起;然后将向量化后的特征经过两层mlp网络转换成256维度的特征来表示proposal;
[0096]
相比之前基于体素的感兴趣区域特征池化操作。的网络能够获得更丰富语义信息,以及更加灵活的接受域选择。
[0097]
proposal精细化修正以及置信度预测:利用proposal的特征,精细化修正网络能够预测3d proposal的尺寸以及位置信息。整个精细化修正网络由两个分支组成:置信度预测分支和框回归分组,每一个分支由两层mlp网络组成。
[0098]
置信度预测网络采用3d感兴趣区域的roi以及对应gt之间的3d iou作为训练目标,对于第k个3d感兴趣区域,其置信度训练目标yk为:
[0099]
yk=min(1,max(0,2iou
k-0.5))
[0100]
然后将confidence gt与预测confidence score进行loss计算:
[0101][0102]
通过传统的基于残差的方式来获取目标框的回归目标,并使用smooth l1 loss进行优化。
[0103]
自蒸馏网络:知识蒸馏作为软监督目标只是蒸馏一个模型(老师模型)的知识迁移到另一个模型(学生模型)上。通常是从一个大的模型迁移到小的模型上。除了one-hot监督目标外,学生模型还可以从老师模型获取信息进行学习。最后,较小的学生模型在老师模型的基础上进行训练能够获得跟教师模型一致的性能。如果两个模型的大小规模一致,学生模型的性能甚至更优。
[0104]
对于输入为x以及k维度one-hot监督目标y的模型而言,将x输入到模型中得到z(x)=[z1(x),...,zk(x)]的logit vector。再经过一个softmax函数获得预测置信度p(x)=[p1(x),...,pk(x)]。为了更好的进行知识蒸馏,将置信度进行软化处理:
[0105][0106]
τ表示温度缩放的温度系数。将教师模型和学生模型的输出经过softmax后得到pt(x),ps(x)。对于学生模型而言,其训练目标如下式所示:
[0107][0108]
当温度系数τ为1时,目标函数退化成ps(x)关于软监督目标的cross entropy函数。
[0109]
从上一阶段的预测结果进行知识蒸馏,知识自蒸馏模型从模型本身获取知识进而提高的模型的泛化能力;第t个epoch,在自蒸馏处理下关于x的预测为p
ts
的目标函数为:
[0110][0111]
与传统的知识蒸馏模型相比,自蒸馏模型的老师模型处于动态变化之中。对于学生模型,以往训练epoch的模型都可以作为老师模型。为了能够获取更多有价值的信息,选择将t-1时刻的模型作为老师模型。对于epoch的模型而言,其训练目标为(1-α)y+αpt-1s(x)。参数α反映了对老师模型的信任程度。
[0112]
在模型训练过程中使用自蒸馏的方式对训练目标进行改进,使得模型能够更快的
收敛,提高精准度。
[0113]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1