一种2D数字人视频生成方法与系统与流程
本技术涉及数字人,尤其涉及一种2d数字人视频生成方法与系统。
背景技术:
1、2d数字人是一种虚拟形象,可以通过移植人的表情、动作驱动2d数字人执行与人相同的动作,以在电商、直播等领域中工作,降低了这些领域的人力需求。
2、2d数字人在应用时可用于直播,也可以为一段录制好的视频用于播报一些内容。在合成2d数字人视频时,常通过将视频帧拼成视频的方式。为了提升2d数字人在视频中的播放效果,要尽可能的保证2d数字人的口型、动作与发出的音频的一致性。
3、在训练数字人生成模型时,训练样本由于口音、音色、音调等干扰因素会增加模型的训练难度。并且,在移植面部表情及动作时,嘴部区域容易对整体移植形成干扰,导致生成的2d数字人在视频中出现口型与音频不对应的问题。
技术实现思路
1、本技术提供了一种2d数字人视频生成方法与系统,以解决在移植2d数字人面部表情时,嘴部区域容易对整体移植形成干扰,导致生成2d数字人在视频中出现口型与音频不对应的问题。
2、第一方面,本技术提供了一种2d数字人视频生成方法,包括:
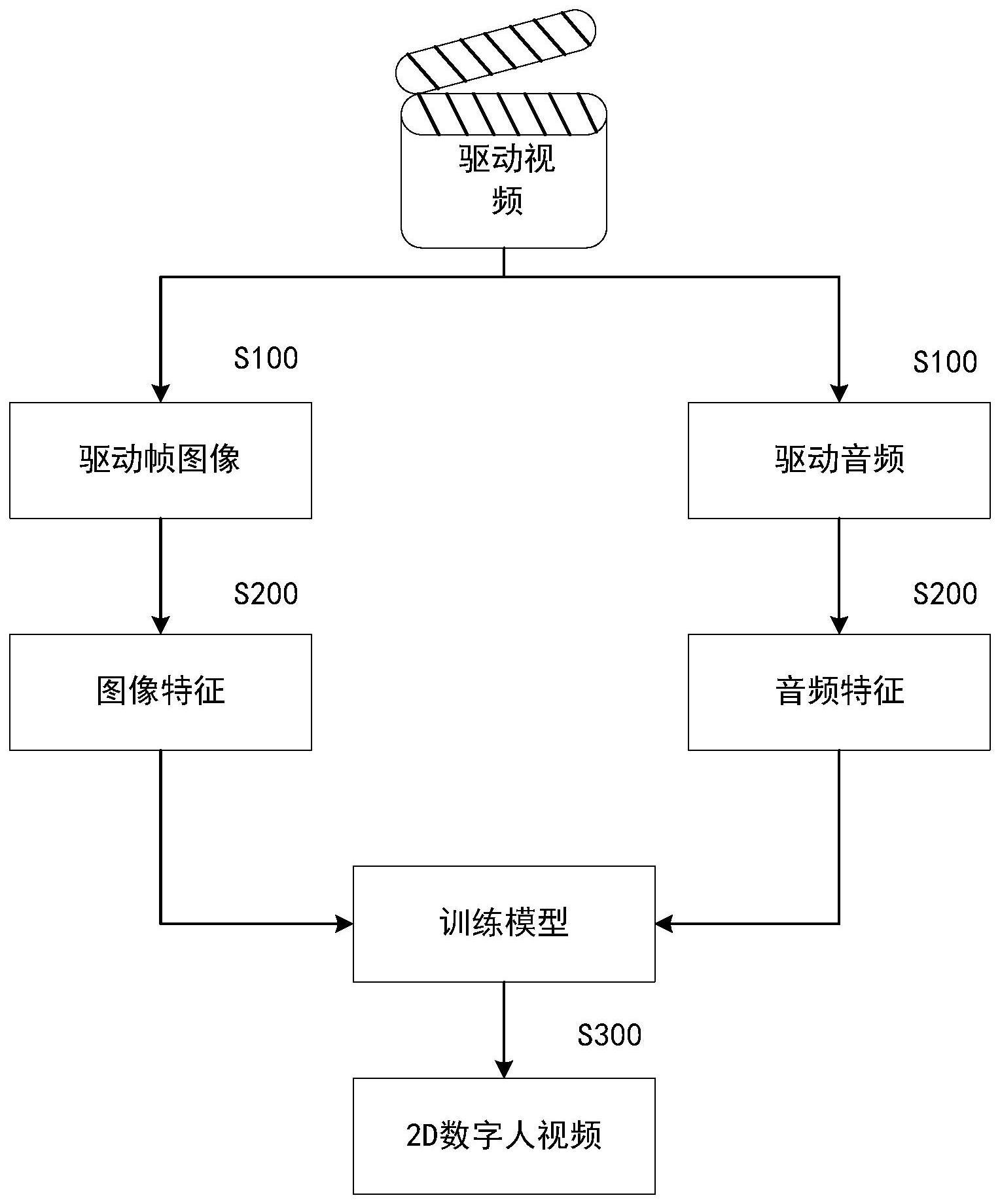
3、获取驱动视频,以及从所述驱动视频中提取驱动帧图像和驱动音频;所述驱动帧图像包括驱动人物,所述驱动音频为驱动人物发出的音频;
4、从所述驱动帧图像中提取图像特征,以及从所述驱动音频中提取音频特征;所述图像特征包括所述驱动人物的脸部关键点数据图像、脸部图像,所述音频特征包括所述驱动人物发出所述音频时的口型图像;
5、根据所述特征图像和所述音频特征驱动训练模型,生成2d数字人视频。
6、在一些实施例中,从所述驱动帧图像中提取图像特征,包括:
7、以所述驱动人物的脸部为中心,在所述驱动帧图像中识别以及裁剪所述驱动人物的头部区域;
8、过滤所述头部区域中的干扰区域,得到目标头部区域图像;
9、对所述目标头部区域图像进行关键点标记以及掩膜处理,得到所述图像特征。
10、在一些实施例中,过滤所述头部区域中的干扰区域,得到目标头部区域图像,包括:
11、根据所述头部区域图像的宽和高,确定过滤圆心;
12、根据所述过滤圆心,绘制过滤图形,所述过滤图形为封闭图形,所述过滤图形外部的区域为干扰区域;所述过滤图形内部的区域的图像为所述目标头部区域图像。
13、在一些实施例中,对所述目标头部区域图像进行关键点标记以及掩膜处理,包括:
14、检测所述目标头部区域的关键点,以及标记所述关键点,得到关键点数据图像;
15、连接所述目标头部区域中的嘴部区域的关键点,得到嘴部区域;
16、调整所述嘴部区域的像素,以对所述嘴部区域进行掩膜处理,得到脸部图像。
17、在一些实施例中,从所述驱动音频中提取音频特征,包括:
18、将所述驱动音频输入至音频特征提取模型,以获取所述音频特征提取模型输出的所述驱动音频对应的文本信息;
19、根据所述文本信息,匹配与所述文本信息对应的口型图像。
20、在一些实施例中,所述方法还包括:
21、获取训练音频;所述训练音频为标记有标准文本信息的音频;
22、将训练音频输入至待训练的音频特征提取模型,以获取所述待训练的音频特征提取模型输出的所述训练音频对应的文本信息;
23、根据所述文本信息和所述训练音频的标准文本信息,计算生成损失;
24、若所述生成损失小于或等于生成损失阈值,则输出当前音频特征提取模型的训练参数;
25、若所述生成损失大于生成损失阈值,则根据所述生成损失调整所述待训练的音频特征提取模型的模型参数。
26、在一些实施例中,根据所述图像特征和所述音频特征驱动训练模型,包括:
27、将所述关键点数据图像、所述脸部图像分别输入至所述训练网络的图像编码网络,得到编码图像;
28、将所述音频特征输入至所述训练网络的音频编码网络,得到编码音频;
29、拼接所述编码图像和所述编码音频,解码得到与所述编码音频对应的目标图像;所述目标图像包括与所述编码音频对应的口型动作图像;
30、根据所述驱动帧图像的时间顺序,对所述目标图像排序,以生成2d数字人视频。
31、在一些实施例中,所述方法还包括:
32、获取样本视频,以及从所述样本视频中提取样本帧图像和样本音频;所述样本帧图像包括样本人物,所述样本音频为所述样本人物发出的音频;
33、从所述样本视频中提取训练特征图像、以及从所述样本音频中提取训练音频特征;所述训练特征图像包括所述样本人物的训练脸部关键点数据图像、训练脸部图像,所述训练音频特征包括多个样本帧图像对应的音频信息;
34、将所述训练特征图像和所述训练音频特征输入至待训练模型的生成器,得到训练2d数字人训练模型;
35、通过损失函数计算所述训练2d数字人训练模型的训练损失;
36、若所述训练损失小于训练损失阈值,则输出当前生成器的训练参数;
37、若所述训练损失大于训练损失阈值,则根据所述生成损失调整所述待训练的2d数字人训练模型的模型参数。
38、第二方面,本技术还提供了一种2d数字人视频生成系统,包括预处理模块和驱动模块;
39、所述预处理模块用于获取驱动视频,以及从所述驱动视频中提取驱动帧图像和驱动音频;所述驱动帧图像包括驱动人物,所述驱动音频为驱动人物发出的音频;
40、所述预处理模块还用于从所述驱动帧图像中提取特征图像,以及从所述驱动音频中提取音频特征;所述图像特征包括所述驱动人物的脸部关键点数据图像、脸部图像,所述音频特征包括所述驱动人物发出所述音频时的口型图像;
41、所述驱动模块用于根据所述特征图像和所述音频特征驱动训练模型,生成2d数字人视频。
42、在一些实施例中,所述系统还包括训练模块;
43、所述预处理模块用于获取样本视频,以及从所述样本视频中提取样本帧图像和样本音频;所述样本帧图像包括样本人物,所述样本音频为所述样本人物发出的音频;
44、所述预处理模块还用于从所述样本视频中提取训练特征图像、以及从所述样本音频中提取训练音频特征;所述训练特征图像包括所述样本人物的训练脸部关键点数据图像、训练脸部图像,所述训练音频特征包括多个样本帧图像对应的音频信息;
45、所述训练模块用于将所述训练特征图像和所述训练音频特征输入至待训练模型的生成器,得到训练2d数字人训练模型;
46、所述训练模块还用于通过损失函数计算所述训练2d数字人训练模型的训练损失;
47、所述训练模块还用于若所述训练损失小于训练损失阈值,则输出当前生成器的训练参数。
48、由上述技术内容可知,本技术提供了一种2d数字人视频生成方法与系统。所述方法通过获取驱动视频,并从驱动视频中提取驱动帧图像和驱动音频。其中驱动帧图像包括驱动人物,驱动音频为驱动人物发出的音频。从驱动帧图像和驱动音频中分别提取图像特征和音频特征,根据图像特征和音频特征驱动训练模型,生成2d数字人视频。所述方法通过音频特征训练得到对应的口型图像,并结合脸部图像以及脸部关键点数据图像,进一步训练得到2d数字人形象。降低了在表情移植时,嘴部区域特征对表情移植的干扰,提高了模型的运算效率。
- 还没有人留言评论。精彩留言会获得点赞!