基于模型间和模型内不确定性的半监督分割模型
1.本发明属于医学图像分割技术领域,具体来说涉及一种基于模型间和模型内不确定性的半监督分割模型。
背景技术:
2.深度学习模型在各种图像分割任务中表现出了极大的成功,尤其是当有大量带注释的训练样本时1.–
[4]。但是,获取像素级的注释是一件非常耗时的任务。这在很大程度上降低了效率,尤其是在需要领域知识和专业知识(例如生物医学图像处理)的应用中。半监督学习(semi-supervised learning,ssl)是应对这一挑战的方法之一,该方法使用有限监督的数据进行训练。在半监督图像分割中,模型从具有已知语义标签的像素中学习,并充分利用了任意未标注数据的信息。
[0003]
半监督分割的主要挑战性问题之一是如何将标记数据和未标记数据之间的一致性进行建模。不一致将导致分割结果的不确定性或者差异性。在最近流行的半监督框架教师-学生框架(mean teacher[5])中,学生和教师模型[6]
–
[8]的预测之间存在不一致,这被称为模型间不确定性。由于未标记的数据没有金标准(ground truth),一种常见的策略是将教师模型的预测用作指导。然而,在mean teacher架构中,以往的工作并不能保证教师模型在未标记的数据上总是比学生模型产生更好的结果,上述这种预测差异有助于估计不确定性。其次,在以往工作中,学生模型本身内部的不确定性和网络扰动是被忽略的,这种不确定性被称为模型内不确定性。在一个特定层的卷积神经网络(cnn)中提取的特征可能会影响后续层,这极大影响了感受野,进而将导致信息在从浅层到深层的传播过程中存在不一致性[9],[10]。
技术实现要素:
[0004]
针对现有技术的不足,本发明的目的在于提供一种基于模型间和模型内不确定性的半监督分割模型,该半监督分割模型从标记和未标记的数据中进行高效学习,对降低专业医生标注数据的工作量具有重要的意义。
[0005]
本发明的目的是通过下述技术方案予以实现的。
[0006]
一种基于模型间和模型内不确定性的半监督分割模型,包括学生模型、教师模型和半监督学习损失模块,所述学生模型和教师模型分别为一个医学图像分割模型(pg-fanet),所述学生模型的初始数据为有标注数据和无标注数据,所述教师模型的初始数据为无标注数据,每个所述医学图像分割模型包括:卷积块、二阶网络模型结构、伪蒙版引导特征增强模块(mgfe)、多尺度多阶段特征聚合模块(mmfa)、第一卷积层、第二卷积层和第三卷积层,二阶网络模型结构包括:一阶子网络和二阶子网络;
[0007]
卷积块用于向其输入初始数据并将从卷积块输出的粗糙特征分别流向一阶子网络和伪蒙版引导特征增强模块;
[0008]
二阶子网络和一阶子网络的构架相同,各包括:i+1个残差块(rb
i_s
)和一个空洞空
间卷积池化金字塔(aspp)模块,一阶子网络的i+1个残差块(rb
i_s
)用于对粗糙特征进行精细化调整,再向一阶子网络的空洞空间卷积池化金字塔(aspp)模块输送一阶精细化特征;一阶子网络的空洞空间卷积池化金字塔(aspp)模块用于对一阶精细化特征提取高阶潜在特征;
[0009]
第一卷积层用于对一阶子网络获得的高阶潜在特征生成伪蒙版;
[0010]
伪蒙版引导特征增强模块用于利用伪蒙版增强粗糙特征的表达能力,以获得伪蒙版引导的融合特征;
[0011]
二阶子网络的i+1个残差块(rb
i_s
)用于输入融合特征并输出二阶精细化特征,二阶子网络的空洞空间卷积池化金字塔(aspp)模块用于接收二阶子网络的第i+1个残差块输出的二阶精细化特征并输出高阶潜在特征;
[0012]
多尺度多阶段特征聚合模块(mmfa)包括:多尺度特征聚合模块和多阶段特征聚合模块,多尺度特征聚合模块用于对一阶子网络第i个残差块输出的低级特征和二阶子网络第i个残差块输出的低级特征进行多尺度特征聚合以获得多尺度聚合特征,其中,i=1、
……
、i;
[0013]
第二卷积层用于融合多尺度聚合特征,以输出高阶特征;
[0014]
多阶段特征聚合模块用于对一阶子网络第i+1个残差块的特征输出、二阶子网络的第i+1个残差块的特征输出和高阶特征进行多阶段特征聚合,进而输出多尺度多阶段聚合特征;
[0015]
第三卷积层用于对多尺度多阶段聚合特征和由二阶子网络获得的高阶潜在特征进行特征拼接后再融合以获得预测结果;
[0016]
所述半监督学习损失模块的计算公式为:
[0017][0018]
其中,lseg为有监督的损失函数,λ(t)表示第t次训练的一致性损失的平衡因子,表示有标注数据集,x
l
表示有标注数据集中的图像,y
l
表示有标注数据集中图像的标注,m表示有标注数据集中图像的个数;表示无标注数据集中的图像,n表示无标注数据集的图像个数,λ
in
tra为控制模型内不确定性正则化l
intra
的权重因子;
[0019][0020]
l
intra
=l
mse
(f1(xr|θ
t
),f2(xr|θ
t
))
[0021]
其中,u
shape
为形状不确定性,u
shape
=-u
shape
log u
shape
[0022]ushape
=|softmax(f2(xr|θ
t
))-softmax(f2(xr|θ
t
′
))|
[0023]
f2(xr|θ
t
)为学生模型在第t次训练的预测结果,f1(xr|θ
t
)为学生模型在第t次训练的伪蒙版,l
mse
表示均方误差损失函数;σ表示最小-最大归一化函数,用以将形状不确定性u
shape
归一化到[0,1];
[0024]
θ
t
为学生模型在第t次训练的权重,θ
′
t
=αθ
′
t-1
+(1-α)θ
t
,θ
′
t
为教师模型在第t次训练的权重;θ
′
t-1
为教师模型在第t-1次训练的权重,α为在总的训练过程中使用梯度下降
更新学生模型θ
t
的指数移动平均值(exponential moving average)的衰减率;
[0025]
为教师模型在第t次训练的预测结果的修正;
[0026][0027]
f2(xr|θ
t
′
)为教师模型在第t次训练的预测结果,μ
′r=-f2(xr|θ
t
′
)logf2(xr|θ
t
′
)。
[0028]
在上述技术方案中,t为训练总次数。
[0029]
在上述技术方案中,α=0~1。
[0030]
在上述技术方案中,将模型间不确定性建模为:
[0031][0032]
模型内不确定性(u
intra
)为:
[0033][0034]
在上述技术方案中,第一卷积层包括:上采样层和卷积层,第一卷积层的计算过程如下:
[0035]ys
=conv(up(xc))
[0036]
其中,xc为由一阶子网络获得的高阶潜在特征,up为第一卷积层中的上采样层,conv为卷积层,ys为伪蒙版。
[0037]
在上述技术方案中,多尺度特征聚合模块的计算公式为:
[0038][0039]
其中,xm为多尺度聚合特征,为第s阶子网络第i个残差块(rbis),为第s阶子网络第i-1个残差块输出的低级特征,s=1、2,i=1、
……
、i,其中,为卷积块输出的粗糙特征,为伪蒙版引导的融合特征,up为上采样层,δ为参数校正线性单元(prelu),为批归一化处理,conv为卷积层。
[0040]
在上述技术方案中,第二卷积层的运算过程如下:
[0041]
x
′m=conv(xm)
[0042]
其中,x
′m为高阶特征,conv为卷积层,xm为多尺度聚合特征。
[0043]
在上述技术方案中,多阶段特征聚合模块的计算公式如下:
[0044][0045]
其中,x
′m为高阶特征,xh为多尺度多阶段聚合特征,up为上采层,δ为参数校正线性单元(prelu),为批归一化处理,conv为卷积层,为第s阶子网络第i+1个残差块,s=1、2,为第s阶子网络第i个残差块的特征输出。
[0046]
在上述技术方案中,第三卷积层包括:上采样、特征拼接和卷积层,第三卷积层的
计算公式如下:
[0047]ys
=conv(concat(xh,up(xf)))
[0048]
其中,ys为预测结果,conv为卷积层,concat为特征拼接操作,xh为多尺度多阶段聚合特征,up为上采样层,xf为由二阶子网络获得的高阶潜在特征。
[0049]
本发明的半监督分割模型利用部分标注数据有效地提取了细胞(monuseg)/腺体(crag)的上下文特征,分割出相应细胞/腺体实例并用于下游任务分析,减少了标注数据的使用量,大大降低了专家标注数据所需的工作量。
附图说明
[0050]
图1为本发明医学图像分割模型的结构示意图;
[0051]
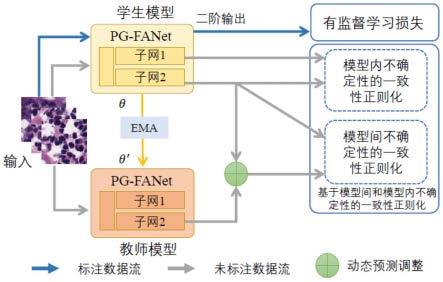
图2为半监督分割模型的结构示意图;
[0052]
图3为(a)monuseg数据集上使用5%/10%/20%/50%/70%/90%标注数据训练的细胞分割结果图;(b)crag数据集上使用5%/10%/20%/50%/70%/90%标注数据训练的腺体分割结果图;
[0053]
图4为monuseg和crag数据集上使用5%/10%/20%/50%标注数据训练的细胞和腺体分割结果图。
具体实施方式
[0054]
下面结合具体实施例进一步说明本发明的技术方案。
[0055]
实施例1
[0056]
一种基于模型间和模型内不确定性的半监督分割模型,如图2所示,包括学生模型、教师模型和半监督学习损失模块,如图1所示,学生模型和教师模型分别为一个医学图像分割模型(pg-fanet),学生模型和教师模型参数独立,教师模型对学生模型的多阶输出进行指导以使得学生模型获得更好的分割性能,学生模型的初始数据为有标注数据和无标注数据,教师模型的初始数据为无标注数据,学生模型通过有监督损失和无监督损失利用有标注与无标注数据进行训练。每个医学图像分割模型包括:卷积块、二阶网络模型结构、伪蒙版引导特征增强模块(mgfe)、多尺度多阶段特征聚合模块(mmfa)、第一卷积层、第二卷积层和第三卷积层,二阶网络模型结构包括:一阶子网络和二阶子网络;
[0057]
卷积块用于向其输入初始数据并将从卷积块输出的粗糙特征分别流向一阶子网络和伪蒙版引导特征增强模块;
[0058]
二阶子网络和一阶子网络的构架相同,各包括:i+1个残差块(rb
i_s
)和一个空洞空间卷积池化金字塔(aspp)模块,一阶子网络的i+1个残差块(rb
i_s
)用于对粗糙特征进行精细化调整,再向一阶子网络的空洞空间卷积池化金字塔(aspp)模块输送一阶精细化特征;一阶子网络的空洞空间卷积池化金字塔(aspp)模块用于对一阶精细化特征提取高阶潜在特征;在本发明的实施例中i=3;
[0059]
第一卷积层用于对一阶子网络获得的高阶潜在特征生成伪蒙版;
[0060]
一阶子网络用于粗略的伪蒙版生成,伪蒙版引导特征增强模块用于利用伪蒙版增强粗糙特征的表达能力,以获得伪蒙版引导的融合特征;伪蒙版引导特征增强模块在伪蒙版引导下将二阶子网络的注意力移到感兴趣区域上。伪蒙版引导特征增强模块将由卷积块
产生的粗糙特征和第一阶段子网络的伪蒙版特征拼接起来并通过1
×
1的卷积层融合作为第二阶段子网络的输入;
[0061]
二阶子网络的i+1个残差块(rb
i_s
)用于输入融合特征并输出二阶精细化特征,二阶子网络的空洞空间卷积池化金字塔(aspp)模块用于接收二阶子网络的第i+1个残差块输出的二阶精细化特征并输出高阶潜在特征,用于细化预测结果;
[0062]
鉴于二阶子网络和一阶子网络对不同尺度形状和大小进行提取特征,本发明使用多尺度多阶段特征聚合模块(mmfa)来聚合多尺度和多阶段特征,提高模型的特征表达能力,避免u形跳跃连接中的特征不兼容问题。多尺度多阶段特征聚合模块(mmfa)包括:多尺度特征聚合模块和多阶段特征聚合模块,多尺度特征聚合模块用于对一阶子网络第i个残差块输出的低级特征和二阶子网络第i个残差块输出的低级特征进行多尺度特征聚合以获得多尺度聚合特征,其中,i=1、
……
、i;
[0063]
第二卷积层用于融合多尺度聚合特征,以输出高阶特征;
[0064]
多阶段特征聚合模块用于对一阶子网络第i+1个残差块的特征输出、二阶子网络的第i+1个残差块的特征输出和高阶特征进行多阶段特征聚合,进而输出多尺度多阶段聚合特征;
[0065]
第三卷积层用于对多尺度多阶段聚合特征和由二阶子网络获得的高阶潜在特征进行特征拼接后再融合以获得预测结果;
[0066]
半监督学习损失模块的计算公式为:
[0067][0068]
其中,lseg为有监督的损失函数,λ(t)表示第t次训练的一致性损失的平衡因子,其计算公式为t为训练总次数,在本发明中t设置为300。表示有标注数据集,x
l
表示有标注数据集中的图像,y
l
表示有标注数据集中图像的标注,m表示有标注数据集中图像的个数;表示无标注数据集中的图像,n表示无标注数据集的图像个数;λ
intra
为控制模型内不确定性正则化l
intra
的权重因子,本发明中设置为1;本发明利用形状不确定性u
shape
来增强模型对边界区域的注意,将形状不确定性融合到l
inter
,l
inter
表示无监督的一致性损失,以最大程度地减少模型间不确定性,l
intra
代表了附加的模型内不确定性正则化,它将模型内不确定性纳入了半监督学习目标中;
[0069][0070]
l
intra
=l
mse
(f1(xr|θ
t
),f2(xrlθ
t
))
[0071]
其中,u
shape
为形状不确定性,u
shape
=-u
shape
log u
shape
[0072]ushape
=|softmax(f2(xr|θ
t
))-softmax(f2(xr|θ
t
′
))|
[0073]
f2(xr|θ
t
)为学生模型在第t次训练的预测结果,f1(xr|θ
t
)为学生模型在第t次训练的伪蒙版,l
mse
表示均方误差损失函数;σ表示最小-最大归一化函数,用以将形状不确定性u
shape
归一化到[0,1]。至此,学生模型和教师模型之间边界预测的差异可以通过本发明的形状不确定性加权方法降低,从而可以在训练过程中针对医学影像边界处细节的调整,保留
分割对象的完整形状。除了促进组织学图像的完整分割外,本发明还利用形状信息不确定性权重(u
shape
)来增强模型对边界区域的注意,以更好地分割预测。
[0074]
每个训练过程中教师模型的权重更新依据于上次训练过程中的教师模型的权重以及本次训练过程中学生模型的权重,具体来说,教师模型在第t次训练的权重θ
′
t
,θ
′
t
=αθ
′
t-1
+(1-α)θ
t
;θ
t
为学生模型在第t次训练的权重,θ
′
t-1
为教师模型在第t-1次训练的权重,α为在总的训练过程中使用梯度下降更新学生模型θt的指数移动平均值(exponential moving average)的衰减率,一般可以取0到1,在本实施例中取0.99。
[0075]
为教师模型在第t次训练的预测结果的修正。
[0076][0077]
f2(xr|θ
t
′
)为教师模型在第t次训练的预测结果,u
′r为第r个样本预测的不确定性估计,μ
′r=-f2(xr|θ
t
′
)log f2(xr|θ
t
′
);
[0078]
通过学生模型和教师模型的预测差异,可将模型间不确定性建模为:
[0079][0080]
但是,由于神经网络的层级体系结构,学生模型内的不同阶段的感受野存在差异,这将导致不同子网络的预测不一致。为了解决差异,每个子网络的结果预测必须高度一致。因此,本发明额外估计了模型内不确定性(u
intra
)为:
[0081][0082]
一方面,监督的学习过程不断根据l
s1
中l
seg
项,不断提高学生模型的能力。另一方面,半监督的学习过程迫使学生模型的最终预测与教师模型的模型保持一致。同时,学生模型将一阶子网络的伪蒙版与一阶子网络的预测结果保持一致。通过这样的操作,最终限制了半监督学习中存在的不一致性。
[0083]
由于教师模型并不能一直提供比学生模型更准确的预测。因此,本发明提出一种模型间和模型内不确定性一致性模块u
inter
和u
intra
,防止教师模型预测中存在的噪声和不确定性对学生模型进行错误引导。为了动态地防止教师模型获得较高不确定性的预测,本发明引入了可学习的损失函数l
inter,
以惩罚教师模型产生的不确定性。当教师模型提供不可靠的结果(高不确定性)时,近似于f2(xr|θ
t
),相反,当教师模型自信(低不确定性)时,与f2(xr|θ
t
)相近,提供了可靠预测作为学生模型学习的目标。
[0084]
在上述技术方案中,第一卷积层包括:上采样层和卷积层,第一卷积层的计算过程如下:
[0085]ys
=conv(up(xc))
[0086]
其中,xc为由一阶子网络获得的高阶潜在特征,up为第一卷积层中的上采样层,conv为卷积层,ys为伪蒙版。
[0087]
在上述技术方案中,多尺度特征聚合模块的计算公式为:
[0088][0089]
其中,xm为多尺度聚合特征,为第s阶子网络第i个残差块(rb
i_s
),为第s阶子网络第i-1个残差块输出的低级特征,s=l、2,i=l、
……
、i,其中,为卷积块输出的粗糙特征,为伪蒙版引导的融合特征,up为上采样层,δ为参数校正线性单元(prelu),为批归一化处理,conv为卷积层。多尺度特征聚合模块重新使用伪蒙版引导的信息,并获得更好的特征表示以进行进一步传播。
[0090]
在上述技术方案中,第二卷积层用于进一步提高特征表达,为多阶段特征聚合模块提供更具有表达能力的高级特征,第二卷积层的运算过程如下:
[0091]
x
′m=conv(xm)
[0092]
其中,x
′m为高阶特征,conv为卷积层,xm为多尺度聚合特征;
[0093]
在上述技术方案中,多阶段特征聚合模块中的卷积层用于接收一阶子网络第i+1个残差块的特征输出和二阶子网络的第i+1个残差块的特征输出。随着网络深度加深,低级特征的空间信息(例如区域边界)可能会丢失,本发明使用多阶段特征聚合模块融合了高阶特征、一阶子网络第i+1个残差块的特征输出和二阶子网络的第1+1个残差块的特征输出,避免了引入特征不兼容的u形跳跃连接。
[0094]
多阶段特征聚合模块的计算公式如下:
[0095][0096]
其中,x
′m为高阶特征,xh为多尺度多阶段聚合特征,up为上采层,δ为参数校正线性单元(prelu),为批归一化处理,conv为卷积层,为第s阶子网络第i+1个残差块,s=1、2,为第s阶子网络第i个残差块的特征输出。
[0097]
在上述技术方案中,第三卷积层包括:上采样、特征拼接和卷积层,第三卷积层的计算公式如下:
[0098]ys
=conv(concat(xh,up(xf)))
[0099]
其中,ys为预测结果,conv为卷积层,concat为特征拼接操作,xh为多尺度多阶段聚合特征,up为上采样层,xf为由二阶子网络获得的高阶潜在特征。
[0100]
实施例2
[0101]
多器官细胞分割数据集(multi-organ nuclei segmentation,monuseg)[13]由44张h&e染色的组织病理学图像组成,组织病理学图像是从多家医院收集而得,分辨率为1000
×
1000像素。从44张组织病理学图像中选取30张组织病理学图像组成训练数据集和14张作为测试数据集,将训练数据集随机分成27张作为训练集a和3张作为验证集b,测试数据集作为测试集c。使用滑动窗口从每张组织病理学图像中裁剪大小为128
×
128的图像块,共计1728个图像块。对图像块执行在线数据增强,包括随机缩放、翻转、旋转和仿射操作,所有图像块都通过使用imagenet[14]中图像的均值和标准差进行归一化。
[0102]
用实施例1中半监督分割模型筛选细胞电镜图。
[0103]
将训练集a的图像块作为初始数据分别送入学生模型和教师模型中训练,学生模型中使训练集a中带有手工注释细胞组织病理学图像的占比分别为5%、10%、20%、50%、70%和90%(余下为未标注数据),教师模型的训练集a不使用标注,将验证集b作为初始数据送入学生模型(不使用标注),通过验证集b选取最优θ
t
的半监督分割模型,将不使用标注的测试集c的图像块顺序送入最优θ
t
的学生模型并将预测结果按照小切块顺序重新堆叠,得到精准的细胞分割结果。实施例效果如图4所示,其中,图4中monuseg对应的“全监督”为专利申请号2022113429217中实施例2中测试集c获得的预测结果。
[0104]
实施例3
[0105]
腺体数据集制作:结直肠腺癌(colorectal adenocarcinoma gland,crag)数据集共包含38张全视野数字切片(whole slide images,wsi),从中获取了213张具有不同癌症等级的h&e cra图像[15]。用实施例1中半监督分割模型筛选腺体电镜图,选取173张h&e cra图像组成训练数据集,选取40张h&e cra图像组成测试数据集作为测试集f,将训练数据集随机分成153张作为训练集d以及20张作为验证集e。h&e cra图像的分辨率大部分都是1512
×
1516。本发明从153张h&e cra图像中提取了5508个480
×
480像素的图像块。进一步执行在线数据增强,包括随机缩放、翻转、旋转和仿射操作。所有这些图像块都通过使用imagenet[14]中图像的均值和标准差进行归一化。
[0106]
将训练集d的图像块送入学生模型和教师模型中进行训练,学生模型中使训练集d中带有手工注释腺体h&e cra图像占比分别为5%、10%、20%、50%、70%和90%(余下为未标注数据),教师模型的训练集d不使用标注,用验证集e选择最优θ
t
的半监督分割模型(不使用标注)。将不使用标注的测试集f的图像块按小切块顺序送入最优θ
t
的学生模型进行预测,并将预测结果按照小切块顺序重新堆叠,得到精准的腺体分割结果。实施例效果如图4所示,其中,图4中crag对应的“全监督”为专利申请号2022113429217中实施例3中测试集f获得的预测结果。
[0107]
对实施例2和实施例3中半监督分割模型(pg-fanet ssl)进行评估。
[0108]
细胞分割质量分数指标包括:f1-score(f1),intersection over union(iou),average dice coefficient(dice),aggregated jaccard index(aji),以及95% hausdorff distance(95hd)。
[0109]
腺体分割质量分数指标包括:f1-score(f1),object-level dice coefficient(dice
obj
),object-level hausdorff distance(haus
obj
)以及95%object-level hausdorff distance(95hd
obj
)。
[0110]
本发明还与最近最先进的半监督模型进行了比较,包括mean teacher(mt)[5]模型,不确定性感知的自集成模型(ua-mt)[6],差值一致性训练模型(ict)[11],变换一致性自集成模型(tcsm)[7],和双不确定性权值模型(duw)[12]。最近最先进的半监督模型使用带有手工注释细胞组织病理学图像的占比分别为5%、10%、20%、50%、70%和90%(余下为未标注数据)进行训练,其与实施例2的aji的质量分数如图3的a所示;最近最先进的半监督模型使用带有手工注释腺体h&e cra图像占比分别为5%、10%、20%、50%、70%和90%(余下为未标注数据)进行训练,其与实施例3的dice
obj
的质量分数如图3的b所示。
[0111]
细胞分割:如表1所示,首先,在使用相同标注量的数据上训练,本发明将半监督分割模型(pg-fanet ssl)与全监督方法pg-fanet full(专利申请号2022113429217)比较。随
着标注图像的数量从5%到50%提升,本发明半监督分割模型(pg-fanet ssl)的aji数值相比于全监督方法分别提高了5.9%、2.5%、2.7%和2.8%。值得注意的是,当标注的数据比例从5%增加到50%时,aji分数获得了明显的改进,这表明当只有少量标注数据时,增加标注数据的数量会对模型产生重大影响。其次,相比之下,本发明半监督分割模型(pg-fanet ssl)与所有半监督学习模型进行了比较。结果表明,本发明相比于其它方法而言都取得了最佳的表现。
[0112]
腺体分割:如表1所示,在使用相同标注量的数据上训练,与全监督基准实验pg-fanet full(专利申请号2022113429217)相比,在使用5%和10%标记数据时,本发明半监督分割模型(pg-fanet ssl)在f1、dice
obj
和haus
obj
指标上显著改善了8.9%/5.2%,9.6%/5.7%和109.632/75.872。与最先进的半监督模型相比,本发明半监督分割模型(pg-fanet ssl)也表现出了最好的性能。
[0113]
表1
[0114][0115]
表1中labeled data表示有标注数据在训练集a/训练集d中的比例,以“5%(1/8)”为例,“5%”表示标注数据在训练集a/训练集d中的占比,“1/8”为训练集a中有标注的组织病理学图像为1张/训练集d中有标注的h&e cra图像为8张。
[0116]
实施例4
[0117]
依照表2去除实施例1中半监督分割模型中的l
inter
、l
intra
或/和u
shape
(表2中的
“×”
代表去除),分别按照实施例2中当训练集a中带有手工注释细胞的占比为5%(余下为未标注数据)和实施例3中当训练集d中带有手工注释腺体的占比为5%(余下为未标注数据)时送入学生模型进行训练,测试集c和测试集f的预测结果进行评估,如表2所示。如表2所示,一方面,添加模型间不一致性正则化策略改进了aji/dice
obj
性能指标,在monuseg/crag数据集上分别提升了1.5%/8.5%。另一方面,降低模型内部不确定性会增加aji/dice
obj
性能。此外,由表2中可得,形状不确定性加权模块保留了医学图像中分割的完整形状,使得分割结果提升。借助所有一致性正规化策略,不确定性大大减少,从而改善了模型性能。
[0118]
表2
[0119][0120]
[1]h.su,f.xing,x.kong,y.xie,s.zhang,and l. yang,“robust cell detection and segmentation in histopathological images using sparse reconstruction and stacked denoising autoencoders,”in internationalconference on medicalimage computing and computer-assistedintervention,2015,pp.383-390.
[0121]
[2]s.graham etal.,“mild-net:minimal information loss dilated networkfor gland instance segmentation in colon histology images,”medicalimageanalysis,vo1.52,pp.199-21 1,20l 9.[3]y.xu etal.,“gland instance segmentation using deep multichannel neural networks,”ieee transactions onbiomedicalengineering,vol.64,no.12,pp.290l-2912,2017.
[0122]
[4]h.qu,z.yan,g.m.riedlinger,s.de,and d.n.metaxas,“improving nuclei/gland instance segmentation in histopathology images by full resolutiom meural network and spatial constrained loss,”in internationalconference on medicalimage computing and computer-assistedintervention,2019,pp.378-386.
[0123]
[5]a.tarvainen and h.valpola,“mean teachers are better role models:weight-averaged consistemey targets improve semi-supervised deep learning results,”inadvances inneuralinformationprocessing systems,2017,pp.1195-1204.
[0124]
[6]l.yu,s.wang,x.li,c.-w.fu,and p.-a.heng,“uncertainty-aware self-ensembling model for scmi-supervised 3d left atrium segmentation,”in internationalconference on medicalimage computing and computer-assisted intervention,2019,pp.605-613.
[0125]
[7]x.li,l.yu,h.chen,c.-w.fu,l.xing,and p.-a.heng,“transformatiom-consistent self-ensembling model for semi-supervised medical image segmentation,”ieee transactions on neuralnetworks andlearning systems,pp.1-12,2020.
[0126]
[8]y.zhou,h.chem,h.lin,and p.-a.hemg,“deep semi-supervised knowledge distillation for overlapping cervical cell instance segmentation,”ininternationalconference on medicalimage computing and computer-assisted intervention,2020,pp.521-531.
[0127]
[9]z.zheng and y.yang,“rectifying pseudo label learning via uncertainty estimation for domain adaptive semantic segmentation,”internationaljournalofcomputer vision,vo1.129,no.4,pp.1106-1120,2021.
[0128]
[10]q.dou etal,“pnp-adanet:plug-and-play adversarial domain adaptation network at unpaired cross-modality cardiac segmentation,”ieeeaccess,vol.7,pp.99065-99076,2019,doi:10.1109/access.2019.2929258.
[0129]
[11]v.verma,a.lamb,j.kannala,y.bengio,and d.lopez-paz,“interpolation consistency trainingfor semi—supervised learning,”inproceedingsofthe28thinternationaljoint conference onartiffcialintelligence,2019,pp.3635-3641.
[0130]
[12]y.wang etal.,“double—uncertainty weighted method for semi-supervised learning,”ininternationalconference onmedicalimage computingand computer-4ssisted intervention,2020,pp.542-551.
[0131]
[13]n.kumar etal,“a multi-organ nucleus segmentation challenge,”ieee transactiohs onmedicalimaging,vol.39,no.5,pp.1380-1391,2019.
[0132]
[14]j.deng,w.dong,r.socher,l.-j.li,k.li,and l.fei-fei,“imagenet:a large-scale hierarchical image database,”in2009ieee conference oncomputer visionandpatternrecognition,2009,pp.248-255.
[0133]
[15]r.awan etal,“glandular morphometrics for objective grading of colorectal adenocarcinoma histology images,”scientificreports,vol.7,no.1,pp.1-12,2017.
[0134]
以上对本发明做了示例性的描述,应该说明的是,在不脱离本发明的核心的情况下,任何简单的变形、修改或者其他本领域技术人员能够不花费创造性劳动的等同替换均落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1