一种基于遗传模拟退火参数优化的飞灰含碳量预测方法与流程
1.本发明涉及工业测量技术领域,具体为一种基于遗传模拟退火参数优化的飞灰含碳量预测方法。
背景技术:
2.飞灰含碳量是反映火电厂燃煤锅炉燃烧效率的重要指标,燃煤煤种不同、锅炉燃烧系统结构特性不同、燃烧工况不同都会导致煤粉不充分燃烧,锅炉尾部烟气中飞灰的含碳量过高,这种情况会导致锅炉燃烧效率低、低温段过热器磨损、机组运行易出故障等问题,这将会使锅炉的维护成本增加,不利于锅炉的长期稳定运行;此外,飞灰含碳量过高会造成锅炉尾部烟气中碳氧化物含量过高,环境污染严重,因此锅炉飞灰含碳量的实时在线测量对火电厂的经济效益、机组安全运行、节能减排等具有重要意义。
3.目前,国内外有关飞灰含碳量测量方法主要分为两种:物理测量方法和软测量方法,物理测量方法主要有:燃烧失重法、静电法、微波法等,现有的基于物理测量法测量飞灰含碳量的产品较多,他们的测量精度高,但是测量时间长实时性较差,其设备需要定期检查维护否则设备的测量精度将会降低,飞灰含碳量的软测量方法包括数值计算和神经网络预测这两种方案。其中神经网络预测方法容易陷入局部最小值,收敛速度慢,易出现过拟合现象,输入和输出的匹配度低,造成飞灰含碳量预测值与实际值误差较大。
技术实现要素:
4.本发明的目的在于提供一种基于遗传模拟退火参数优化的飞灰含碳量预测方法,以解决上述背景技术中bp神经网络在权值选择上的随机性,提高了bp神经网络的收敛速度和泛化性能,降低了飞灰含碳量预测偏差大的问题。
5.为实现上述目的,本发明提供如下技术方案:一种基于遗传模拟退火参数优化的飞灰含碳量预测方法,包括如下步骤:
6.s1:从数据库中提取飞灰含碳量的历史数据,采用主元分析法筛选对应飞灰含碳量的历史数据的影响参数,对其数据进行处理,并划分训练集和测试集;
7.s2:将训练集中对应飞灰含碳量历史数据的影响参数作为输入变量,输出变量为飞灰含碳量;构建三层bp神经网络建立飞灰含碳量预测模型;
8.s3:对bp神经网络进行初始化并且采用遗传模拟退火算法对bp神经网络权值阈值进行优化,获取最优权值和阈值;
9.s4:采用误差梯度下降法更新bp神经网络的权值和阈值直至满足网络误差精度要求,从而完成网络的训练;利用训练好的bp神经网络对测试样本进行预测,得到飞灰含碳量预测值。
10.优选的,所述在s1中对bp神经网络输入变量降维和数据处理主要包括以下步骤:
11.(1)根据锅炉燃烧运行影响飞灰含碳量的影响因素,初选40个燃烧参数作为飞灰含碳量的影响参数;其中,40个燃烧参数分别为燃尽风门开度、燃烧器摆角、炉膛压力、炉膛
温度、灰分、挥发分、一次风速、4项进风的风压、4项煤粉浓度、5项一次风温、4项煤粉细度、热风温度、炉膛出口氧量、5项风率、锅炉负荷、5项二次风门开度、4项磨煤机给煤量;
12.(2)采用主元分析方法得出各参数的贡献率并结合锅炉燃烧工况数据采集实况选定15个燃烧参数作为飞灰含碳量预测模型的输入变量,这15个锅炉燃烧工况参数分别为灰分、挥发分、锅炉负荷、一次风速、煤粉浓度、一次风率,煤粉细度、热风温度、燃尽风门开度、4项磨煤机给煤量、一次风温、燃烧器摆角;
13.(3)对采集的输入输出变量数据进行异常值剔除、数据归一化并划分网格训练集和测试集。
14.优选的,所述s2中bp神经网络的结构包括输入层、隐藏层和输出层,其中,根据s1选出的输入变量的个数确定bp神经网络的输入层神经元个数m和输出层神经元个数n,确定隐藏层神经元个数h。
15.优选的,所述隐藏层神经元个数h采用的公式为:
16.其中:α为[0,10]的常数。
[0017]
优选的,所述s2中三层bp神经网络的构建的具体步骤如下:
[0018]
(1)确定输入成节点数m,从步骤1可得输入层节点数为15;
[0019]
(2)确定输出层节点数n,网络输出为飞灰含碳量可确定其节点数为1;
[0020]
(3)确定隐含层节点数h,根据公式和实际训练误差可知当隐含层节点数为10时,预测效果最好;
[0021]
(4)确定网络的激励函数为sigmoid型函数
[0022]
(5)设定网络的误差精度为0.01。
[0023]
优选的,所述s3的具体过程如下:
[0024]
(1)设定初始种群规模n、最大遗传算法迭代次数gmax、模拟退火初始温度t0、退火速率λ、终止温度tmin,并根据bp神经网络的结构计算染色体编码长度m,该处采用浮点数编码方式,长度m计算方式如下:
[0025]
m=m
×
h+h
×
n+h+n,其中m,h,n分别为输入层、隐含层和输出层神经元个数,染色体编码中的每一段基因都代表着某一神经元的权值或阈值;
[0026]
(2)清零遗传迭代次数;
[0027]
(3)解码染色体,获得bp神经网络权值、阈值数据;
[0028]
(4)输入数据并初始化bp神经网络,进入种群适应度值计算阶段;以更新后的权值、阈值,单次运行bp神经网络,输出结果与期望结果的均方误差的倒数作为该个体的适应度值,计算如下:
[0029]
其中mse(x)为输出结果与期望结果的均方误差,mse(x)的其计算如下;
[0030]
用该方法替代传统遗传算法中的适应度评价函数,适
应度值的大小决定该个体的优秀程度;
[0031]
(5)将染色体数据重新编码,采用“轮盘赌”选择法对群体中的个体进行选择,其个体被选择的概率为pi,其计算如下:
[0032]
其中(i=1,2,
…
,n),fi为某个个体i的适应度;
[0033]
(6)经过选择算子处理后的种群依次进行交叉与变异,其交叉概率与变异概率分别为pc,pm;计算公式如下:
[0034][0035][0036]
其中,fa为种群平均适应度值,fm为种群最大适应度值;k1,k2为设置参数,若则当前最优个体适应度值远离平均值,越小说明种群特征越分散;若则最优个体适应度值接近平均值,越大说明种群特征越集中,该方式可使交叉过程中产生更加多样性的个体丰富种群的同时保留优秀基因遗传,强化全局搜索能力;
[0037]
(7)以改进metropolis准则对种群进行选择和退火操作,产生新种群,其判断方式如下:
[0038][0039]
其中f(xn(i))、f(xo(i))分别为新、旧种群个体i适应度值,t为当前退火温度;若新个体的适应度值大于旧个体,则新个体替换旧个体;若新个体的适应度值小于旧个体,则根据改进metropolis准则的概率p接受该个体,并将该个体的所有染色体片段以0.02的概率发生相互交换,产生改良新个体,进入下一代;
[0040]
(8)当温度t≤t
min
时,终止算法,转至(9);当遗传代数g=g
max
时,t=λt并返回(2);否则g<g
max
,g=g+1,返回(3);
[0041]
(9)将输出后的最优个体染色体解码,读取数据作为初始权值、阈值,获得算法优
化后的bp神经网络。
[0042]
优选的,所述s4利用误差梯度下降法更新bp神经网络的权值和阈值,具体为:
[0043]
权值更新公式:
[0044]
阈值更新公式为:其中,w
ij
为输入层到隐含层的权值,w
jk
为隐含层到输出层的权值,w
ij*
为更新后输入层到隐含层的权值,w
jk*
为更新后隐含层到输出层的权值,η为网络学习率,hj为隐含层输出,xi为输入数据归一化后的值,n为bp神经网络输出层节点数,ek为网络的预测输出值yk与期望输出值的差值,aj为隐含层第j个节点的阈值,bk为输出层第k个节点的阈值,a
j*
为更新后隐含层第j个节点的阈值,b
k*
为更新后输出层第k个节点的阈值。
[0045]
与现有技术相比,本发明的有益效果是:该基于遗传模拟退火参数优化的飞灰含碳量预测方法通过从历史数据库中获得影响因素的长期历史数据,采用主元分析法去掉冗余的相关变量和对飞灰含碳量贡献率低的变量,筛选出飞灰含碳量软测量模型的输入变量;改进了遗传模拟退火,有效地抑制了遗传算法过早收敛,提高算法局部寻优的精确性。
附图说明
[0046]
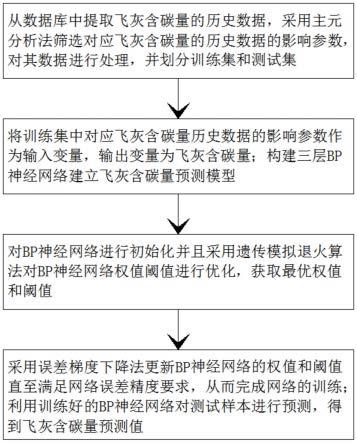
图1为本发明的一种基于遗传模拟退火参数优化的飞灰含碳量预测方法的流程图;
[0047]
图2为本发明一种遗传模拟退火算法优化bp神经网络权值阈值的流程图。
具体实施方式
[0048]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0049]
本发明提供的一种基于遗传模拟退火参数优化的飞灰含碳量预测方法的结构如图1所示,包括如下步骤:
[0050]
s1:从数据库中提取飞灰含碳量的历史数据,采用主元分析法筛选对应飞灰含碳量的历史数据的影响参数,对其数据进行处理,并划分训练集和测试集。
[0051]
进一步度,bp神经网络输入变量降维和数据处理主要包括以下步骤:
[0052]
(1)根据锅炉燃烧运行影响飞灰含碳量的影响因素,初选40个燃烧参数作为飞灰含碳量的影响参数;其中,40个燃烧参数分别为燃尽风门开度、燃烧器摆角、炉膛压力、炉膛温度、灰分、挥发分、一次风速、4项进风的风压、4项煤粉浓度、5项一次风温、4项煤粉细度、热风温度、炉膛出口氧量、5项风率、锅炉负荷、5项二次风门开度、4项磨煤机给煤量;
[0053]
(2)采用主元分析方法得出各参数的贡献率并结合锅炉燃烧工况数据采集实况选定15个燃烧参数作为飞灰含碳量预测模型的输入变量,这15个锅炉燃烧工况参数分别为灰
分、挥发分、锅炉负荷、一次风速、煤粉浓度、一次风率,煤粉细度、热风温度、燃尽风门开度、4项磨煤机给煤量、一次风温、燃烧器摆角;
[0054]
(3)对采集的输入输出变量数据进行异常值剔除、数据归一化并划分网格训练集和测试集。
[0055]
s2:将训练集中对应飞灰含碳量历史数据的影响参数作为输入变量,输出变量为飞灰含碳量;构建三层bp神经网络建立飞灰含碳量预测模型。
[0056]
其中,bp神经网络的结构包括输入层、隐藏层和输出层,其中,根据s1选出的输入变量的个数确定bp神经网络的输入层神经元个数m和输出层神经元个数n,确定隐藏层神经元个数h,隐藏层神经元个数h采用的公式为:
[0057]
其中:α为[0,10]的常数。
[0058]
进一步地,三层bp神经网络的构建的具体步骤如下:
[0059]
(1)确定输入成节点数m,从步骤1可得输入层节点数为15;
[0060]
(2)确定输出层节点数n,网络输出为飞灰含碳量可确定其节点数为1;
[0061]
(3)确定隐含层节点数h,根据公式和实际训练误差可知当隐含层节点数为10时,预测效果最好;
[0062]
(4)确定网络的激励函数为sigmoid型函数
[0063]
(5)设定网络的误差精度为0.01。
[0064]
s3:对bp神经网络进行初始化并且采用遗传模拟退火算法对bp神经网络权值阈值进行优化,获取最优权值和阈值。
[0065]
进一步地,如图2所示,该步骤3的具体过程如下:
[0066]
(1)设定初始种群规模n、最大遗传算法迭代次数gmax、模拟退火初始温度t0、退火速率λ、终止温度tmin,并根据bp神经网络的结构计算染色体编码长度m,该处采用浮点数编码方式,长度m计算方式如下:
[0067]
m=m
×
h+h
×
n+h+n,其中m,h,n分别为输入层、隐含层和输出层神经元个数,染色体编码中的每一段基因都代表着某一神经元的权值或阈值;
[0068]
(2)清零遗传迭代次数;
[0069]
(3)解码染色体,获得bp神经网络权值、阈值数据;
[0070]
(4)输入数据并初始化bp神经网络,进入种群适应度值计算阶段;以更新后的权值、阈值,单次运行bp神经网络,输出结果与期望结果的均方误差的倒数作为该个体的适应度值,计算如下:
[0071]
其中mse(x)为输出结果与期望结果的均方误差,mse(x)的其计算如下;
[0072]
用该方法替代传统遗传算法中的适应度评价函数,适应度值的大小决定该个体的优秀程度;
[0073]
(5)将染色体数据重新编码,采用“轮盘赌”选择法对群体中的个体进行选择,其个
体被选择的概率为pi,其计算如下:
[0074]
其中(i=1,2,
…
,n),fi为某个个体i的适应度;
[0075]
(6)经过选择算子处理后的种群依次进行交叉与变异,其交叉概率与变异概率分别为pc,pm;计算公式如下:
[0076][0077][0078]
其中,fa为种群平均适应度值,fm为种群最大适应度值;k1,k2为设置参数,若则当前最优个体适应度值远离平均值,越小说明种群特征越分散;若则最优个体适应度值接近平均值,越大说明种群特征越集中,该方式可使交叉过程中产生更加多样性的个体丰富种群的同时保留优秀基因遗传,强化全局搜索能力;
[0079]
(7)以改进metropolis准则对种群进行选择和退火操作,产生新种群,其判断方式如下:
[0080][0081]
其中f(xn(i))、f(xo(i))分别为新、旧种群个体i适应度值,t为当前退火温度;若新个体的适应度值大于旧个体,则新个体替换旧个体;若新个体的适应度值小于旧个体,则根据改进metropolis准则的概率p接受该个体,并将该个体的所有染色体片段以0.02的概率发生相互交换,产生改良新个体,进入下一代;
[0082]
(8)当温度t≤t
min
时,终止算法,转至下一步骤(9);当遗传代数g=g
max
时,t=λt并返回上步骤(2);否则g<g
max
,g=g+1,返回上步骤(3);
[0083]
(9)将输出后的最优个体染色体解码,读取数据作为初始权值、阈值,获得算法优化后的bp神经网络。
[0084]
s4:采用误差梯度下降法更新bp神经网络的权值和阈值直至满足网络误差精度要
求,从而完成网络的训练;利用训练好的bp神经网络对测试样本进行预测,得到飞灰含碳量预测值。
[0085]
具体地,利用误差梯度下降法更新bp神经网络的权值和阈值,具体为:
[0086]
权值更新公式:
[0087]
阈值更新公式为:其中,w
ij
为输入层
[0088]
到隐含层的权值,w
jk
为隐含层到输出层的权值,w
jk*
为更新后输入层到隐含层的权值,w
jk*
为更新后隐含层到输出层的权值,η为网络学习率,hj为隐含层输出,xi为输入数据归一化后的值,n为bp神经网络输出层节点数,ek为网络的预测输出值yk与期望输出值的差值,aj为隐含层第j个节点的阈值,bk为输出层第k个节点的阈值,a
j*
为更新后隐含层第j个节点的阈值,b
k*
为更新后输出层第k个节点的阈值。
[0089]
本发明的基于遗传模拟退火参数优化的飞灰含碳量预测方法为:首先,从数据库中提取飞灰含碳量的历史数据,采用主元分析法筛选对应飞灰含碳量的历史数据的影响参数,对其数据进行处理,并划分训练集和测试集。
[0090]
其次,将训练集中对应飞灰含碳量历史数据的影响参数作为输入变量,输出变量为飞灰含碳量;构建三层bp神经网络建立飞灰含碳量预测模型。
[0091]
再次,对bp神经网络进行初始化并且采用遗传模拟退火算法对bp神经网络权值阈值进行优化,获取最优权值和阈值
[0092]
最后,采用误差梯度下降法更新bp神经网络的权值和阈值直至满足网络误差精度要求,从而完成网络的训练;利用训练好的bp神经网络对测试样本进行预测,得到飞灰含碳量预测值。
[0093]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1