一种注意力机制与分解机制耦合的径流量预测方法与流程
本发明属于机器学习领域,具体涉及一种注意力机制与分解机制耦合的径流量预测方法。
背景技术:
1、径流量为某一特定时间范围内(如三日、一周、半月、一月、一季度等)流经河道断面的总流量。在现实生活中,径流量预测技术有着广泛的应用场景。例如,通过对流域内各干流、支流的径流量预测,可为防汛抗旱总体指挥、灌溉与饮用水资源合理调度提供重要的数据支撑。
2、根据历年观测数据可知,自然河道径流量的本质是一种具有强周期性的时间序列。时间序列是按照时间先后排序的数据序列,反映了被观测参量随时间不断演进变化的趋势。当前的径流量预测方法普遍采用时间序列预测的思路,可分为传统径流量预测方法、基于模式识别的径流量预测方法、基于深度学习的径流量预测方法三大类。传统的径流量预测方法利用历史时间序列的统计特征来建立统计学模型并求解,存在参数敏感性高等问题;基于模式识别的径流量预测方法需要利用专业知识对特征进行选择,使用场景的迁移能力不佳;基于深度学习的径流量预测方法,存在着计算复杂度高、历史数据利用不充分等问题。
技术实现思路
1、本发明针对现有技术的不足,提供一种注意力机制与分解机制耦合的径流量预测方法,目的在于挖掘径流量观测数据在月度和季度尺度下的强趋势特性与强周期特性,融合多头自注意力机制和分解机制,实现对径流量的高准确率预测。
2、为达到上述目的,具体技术方案如下:
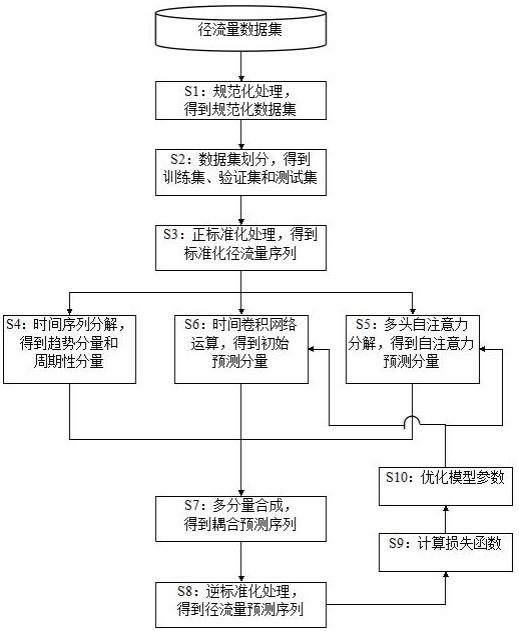
3、一种注意力机制与分解机制耦合的径流量预测方法,包括:对历史观测的径流量数据进行规范化处理,将规范化处理过的径流量数据输入到训练完成的径流量预测模型中,得到径流量预测序列;所述径流量预测模型包括正标准化模块、时间序列分解模块、多头自注意力模块、时间卷积网络模块和逆标准化模块;
4、所述正标准化模块用于对训练集中的径流量序列样本进行正标准化处理,得到标准化径流量序列;
5、所述时间序列分解模块用于对标准化径流量序列进行分解,得到趋势分量和周期性分量;
6、所述多头自注意力模块用于得到自注意力预测分量;
7、所述时间卷积网络模块用于得到初始预测分量;
8、所述逆标准化模块用于对多分量特征融合得到的耦合预测序列进行逆标准化处理,得到径流量预测序列。
9、进一步,所述对径流量预测模型进行训练的过程包括如下步骤:
10、s1:对径流量数据集中的全部数据进行规范化处理;
11、s2:将径流量数据集按照比例划分为训练集、验证集和测试集;
12、s3:将训练集中的径流量序列样本输入到正标准化模块,进行正标准化处理,得到标准化径流量序列;
13、s4:将标准化径流量序列输入到时间序列分解模块中,进行时间序列分解,将分解结果输入至线性层,得到趋势分量和周期性分量;
14、s5:将标准化径流量序列输入到多头自注意力模块中,得到自注意力预测分量;
15、s6:将标准化径流量序列输入到时间卷积网络中,通过多个串联的时间卷积模块得到初始预测分量;
16、s7:将趋势分量、周期性分量、自注意力预测分量和初始预测分量加权相加,得到耦合预测序列;
17、s8:将耦合预测序列输入到逆标准化模块,进行逆标准化处理,得到径流量预测序列;
18、s9:根据径流量预测序列和径流量观测序列,计算径流量预测模型的损失函数;
19、s10:不断调整学习率,根据学习率动态优化模型参数;
20、s11:将训练得到的模型在验证集上进行验证,当损失函数最小时,完成模型训练。
21、其中,步骤s9中损失函数优选均方误差(mean square error,mse);步骤s10中调整学习率的策略优选分段常数衰减,模型优化优选adam算法。
22、进一步,步骤s1中,所述进行规范化处理是计算全部数据的均值和标准差,重新对径流量数据集中各样本进行赋值,使其符合高斯分布。
23、进一步,步骤s3中,所述对训练集中的径流量序列样本进行正标准化处理,可以表示为如下公式:
24、
25、
26、其中,
27、表示i时刻径流量观测值;
28、n表示径流量预测周期的长度;
29、表示径流量观测值的平均值;
30、表示经过正标准化处理后的i时刻径流量观测值。
31、进一步,步骤s4中,所述得到趋势分量和周期性分量的过程包括如下步骤:
32、s4.1:根据平均核大小调整数据两端的补全数据,对补全后的数据进行一维平均池化,获得初始趋势分量;
33、s4.2:将补全数据与初始趋势分量相减,获得初始周期性分量;
34、s4.3:将初始趋势分量和初始周期性分量分别输入至线性层,将输出维度统一至与目标序列相同,得到趋势分量和周期性分量。
35、进一步,步骤s5中,所述得到自注意力预测分量的过程包括如下步骤:
36、s5.1:将标准化径流量序列输入线性层,获得初始时间序列分量;
37、s5.2:将初始时间序列分量分别输入三个不同的线性层,获得查询子分量、键值子分量和数值子分量;
38、s5.3:对查询子分量、键值子分量和数值子分量进行自注意力运算,得到自注意力预测初始分量;
39、s5.4:将自注意力预测初始分量输入线性层,调整输出维度,得到自注意力预测分量。
40、更进一步,所述得到自注意力预测分量的过程,可以表示为如下公式:
41、
42、
43、
44、
45、
46、其中,
47、表示标准化径流量观测值;
48、linear表示线性层;
49、表示初始时间序列分量;
50、wq、wk和wv分别表示查询子分量、键值子分量和数值子分量各自对应的权值矩阵;
51、q、k和v分别表示查询子分量、键值子分量和数值子分量;
52、kt表示键值子分量的转置分量;
53、dk表示模型尺度;
54、softmax表示归一化指数函数;
55、fa表示自注意力预测分量。
56、进一步,步骤s6中,所述得到初始预测分量的过程包括如下步骤:
57、s6.1:构造时间卷积网络,该时间卷积网络包含六个串联的时间卷积模块,每个时间卷积模块包含两个由一维扩张卷积层和剪切层构成的子模块;
58、s6.2:在时间卷积模块中,首先将输入的序列数据进行一维扩张卷积,然后剪切首部多余的数据,以保证预测的信息流单向传递,然后再次进行一维扩张卷积和剪切;
59、s6.3:时间卷积模块的输出将作为下一级时间卷积模块的输入,直至通过六个串联的时间卷积块。
60、更进一步,所述得到初始预测分量的过程,可以表示为如下公式:
61、
62、
63、
64、其中,
65、表示标准化径流量观测值;
66、conv表示一维扩张卷积层;
67、chomp表示剪切层;
68、relu表示非线性激活函数;
69、dropout表示随机失活函数;
70、conv1d表示一维卷积;
71、ft表示经过一个基本扩张卷积层处理过的数据序列;
72、fc表示经过一个时间卷积模块处理过的数据序列;
73、ft表示经过时间卷积网络提取的初始预测分量。
74、进一步,步骤s8中,所述对耦合预测序列进行逆标准化处理,得到径流量预测值的过程,可以表示为如下公式:
75、
76、其中,
77、y表示耦合预测序列;
78、σ表示标准化径流量观测值的标准差;
79、表示标准化径流量观测值的平均值;
80、表示径流量预测序列。
81、本发明的显著效果如下:
82、本发明融合时间序列分解、多头自注意力机制和时间卷积网络,在时间卷积网络的初始预测基础上,耦合趋势特征、周期性特征和自注意力特征,全面高效的挖掘了径流量数据的强趋势特性与强周期特性,同时采用了逆标准化还原,增强了数据的分布一致性,实现了对径流量的高准确率预测。
- 还没有人留言评论。精彩留言会获得点赞!