基于异构平台的高性能Linpack基准测试程序优化方法和设备
基于异构平台的高性能linpack基准测试程序优化方法和设备
技术领域
1.本发明涉及高性能计算领域,特别涉及基于异构平台的高性能linpack基准测试程序优化方法和设备。
背景技术:
2.近些年来,以超算为工具的计算科学已经渗透到了科学研究和工程设计的各个层面,比如百万兆级运算、人工智能等。单台计算机不能满足高性能计算(highperformancecomputing,hpc)应用的计算需求。因此,研究者们开始应用异构体系结构,该结构已经成为许多实际问题并行化的有效方法,并被认为是未来计算平台的主流体系结构。特别是随着图形处理器(graphicsprocessingunit,gpu)的出现,异构计算已经进入了并行计算的时代,其目的是利用不同类型计算资源的计算潜力来处理各种工作负载。由于异构性逐渐成为主流,许多软件开发人员和硬件制造商开始优化程序,以最大限度地利用以及开发这些平台的计算能力。先前的大部分工作是以cpu为中心的设计模式,即在主机存储器中存储原始数据,并通过pciexpress(pci-e)总线将矩阵运算所需的数据传输到gpu存储器中。然而,并行任务所需的数据量太大,传输如此大规模的数据总是使pci-e带宽成为性能瓶颈,这导致运行开销增加和程序效率低。
3.在异构系统中,一旦将更多的gpu卡插入到每个节点中,cpu和gpu之间的性能差距将会迅速扩大,如何合理地分配cpu和gpu之间的工作负载是hpl在异构系统中的一个重点问题,现有的异构计算平台下的hpl基准测试在算法、通信等等很多方面都存在着瓶颈,无法体现系统的最优性能,优化其在异构平台下的性能则显得非常必要。
技术实现要素:
4.为解决现有技术所存在的技术问题,本发明提供基于异构平台的高性能linpack基准测试程序优化方法和设备,基于openmp的多线程运行方法,可以充分发挥了cpu端的多核性能,使用gpu编程模型中的流(stream)对hpl中的面板分解以及尾随矩阵更新做了流水线化的处理,保证cpu以及gpu在程序运行过程中都处于满载的状态,减少cpu和gpu的空闲时间,加快计算效率。
5.本发明的第一个目的在于提供基于异构平台的高性能linpack基准测试程序优化方法。
6.本发明的第二个目的在于提供一种计算机设备。
7.本发明的第一个目的可以通过采取如下技术方案达到:
8.基于异构平台的高性能linpack基准测试程序优化方法,所述方法包括:
9.s1、根据配置文件初始化hpl的运行参数,使用随机数生成算法生成设定规模的矩阵,矩阵所占用的内存空间完全覆盖参与计算的gpu显存大小;
10.s2、以openmp多线程并行化的方式在cpu上执行面板分解过程,使cpu所有核心的
使用率达到100%;
11.s3、使用基于gpu-aware的ring广播算法将分解完成的面板数据以及矩阵行交换信息广播至位于同一行的其余列进程;
12.s4、gpu接收到矩阵的行交换信息后,根据gpu的合并访存原理以及高速缓存的特点,调用自定义内核对存放在显存中的矩阵完成行交换操作;
13.s5、在gpu里完成行交换操作后,gpu使用接收到的面板矩阵数据更新剩余的矩阵数据,调用dtrsm()函数更新上三角矩阵和优化过的gemm函数更新尾随矩阵;
14.s6、递归执行步骤s2至s5,直至整个矩阵分解完成,调用定时函数计算矩阵完成分解的总时间,同时对结果进行验算,得到异构平台的浮点运算性能。
15.优选的技术方案中,所述步骤s1包括:在运行hpl前将hpl的运行参数写入配置文件中,所述运行参数包括生成矩阵的大小n、分块后的矩阵大小nb、总的行进程数量p、总的列进程数量q、广播算法;根据矩阵的大小n分配n*(n+1)大小的矩阵分布到各个节点中的gpu显存中,再调用gpu的随机数生成算法对矩阵的数据进行初始化。
16.具体地,所述步骤s5具体包括:在hpl中使用深度为1的lookahead算法,在cpu上对矩阵的一个面板panel0进行预分解,对面板之外的矩阵数据进行二次切分,切分成面板panel1和矩阵m1;
17.面板panel1根据已经分解完成的panel0进行上三角矩阵以及尾随矩阵的更新;
18.通过gpu编程模型中的流(stream)对矩阵m1的更新以及面板panel1在cpu上的分解并行化计算。
19.本发明的第二个目的可以通过采取如下技术方案达到:
20.一种计算机设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现上述的基于异构平台的高性能linpack基准测试程序优化方法。
21.本发明与现有技术相比,具有如下优点和有益效果:
22.1、本发明提供基于异构平台的高性能linpack基准测试程序优化方法和设备,通过合理地分配cpu和gpu之间的工作负载解决了在多gpu多节点的异构系统中,将更多gpu插入到每个节点中时造成的cpu和gpu之间的性能差距过大的问题。
23.2、本发明使用了基于openmp的多线程运行方法,充分发挥了cpu端的多核性能。
24.3、本发明充分利用gpu的访问特点,在gpu上高效并行地进行行交换等访问操作。
25.4、本发明流水线化cpu和gpu上的计算任务,降低由于cpu和gpu算力差距大造成的空闲等待时间。
附图说明
26.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。
27.图1是本发明实施例中的基于异构平台的高性能linpack基准测试程序优化方法的流程图;
28.图2是本发明实施例中的基于异构平台的高性能linpack基准测试程序优化方法的数据流程图。
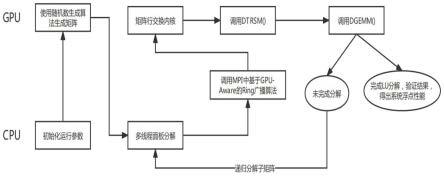
具体实施方式
29.下面将结合附图和实施例,对本发明技术方案做进一步详细描述,显然所描述的实施例是本发明一部分实施例,而不是全部的实施例,本发明的实施方式并不限于此。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
30.高性能linpack(high performance linpack,hpl)基准测试程序,其通过求解一个稠密非线性方程组ax=b,从而得出一个计算系统的浮点计算性能,作为top500排名的重要参考标准之一。hpl主要通过基于部分旋转的高斯消元计算一个n阶线性方程组,这个过程需要2/3n3+2n2+o(n)次双精度浮点加法和乘法。由于矩阵乘法在hpl基准测试中占用了大量的运行时间,而异构系统中的图形处理器gpu擅长处理大量的并行任务,比如矩阵乘法。
31.消息传递接口(message passing interface,mpi)是一个标准化的便携式消息传递接口,用于在各种并行计算架构上运行。它定义了一系列高级接口,使得软件开发过程更加简单,并且隐藏了过程之间通信的复杂性。
32.通过支持图形处理器计算的开源软件堆栈rocm,本发明采用异构/计算机可移植接口(heterogeneous compute interface for portability,hip)来加速大量的并行计算任务如矩阵乘法以及矩阵行交换等操作。hip是amd制作的编程模型,提供了一系列工具包来开发运行在gpu上的代码。该过程通常需要多个设备端执行流(stream)才能达到峰值利用率,流的运行遵循gpu操作时的先进先出(fifo)原则。
33.实施例1:
34.本发明针对异构平台下hpl中cpu和gpu通信延时高、任务调度不合理、访存内核效率较低等问题进行了优化,优化后的hpl首先进行并行化的面板分解,将分解的后的面板进行广播后,调用针对gpu访存特点优化的行交换内核函数以及矩阵乘法(gemm)完成对尾随矩阵的更新,最终对上述过程进行递归以完成整体的计算。此外,本发明还针对hpl中cpu以及gpu通信时延高的特点,使用gpu编程模型中的流(stream)对hpl中的面板分解以及尾随矩阵更新做了流水线化的处理,保证cpu以及gpu在程序运行过程中都处于满载的状态,减少cpu和gpu的空闲时间,进一步加快计算效率。
35.如图1所示,基于异构平台的高性能linpack基准测试程序优化方法的流程图,基于异构平台的高性能linpack基准测试程序优化方法,包括以下步骤:
36.步骤一:根据配置文件初始化hpl的运行参数,使用随机数生成算法生成特定规模的矩阵,矩阵所占用的内存空间完全覆盖参与计算的gpu显存大小;
37.具体地,所述配置文件包含了hpl运行时所需的全部运行参数,在运行hpl前将hpl运行时所需的全部运行参数写入配置文件中,所述运行参数包括生成矩阵的大小n、分块后的矩阵大小nb、总的行进程数量p、总的列进程数量q、广播算法;指定n后即可分配n*(n+1)大小的矩阵并分布到各个节点中的gpu显存中。完成显存空间的分配后再调用gpu的随机数生成算法对矩阵的数据进行初始化,生成随机数的步骤包括:使用rocrand_create_generator()函数初始化随机数生成器,再调用rocrand_set_seed()设置固定的随机种
子,最后调用rocrand_generate_uniform_double()在显存中生成符合均匀分布的双精度浮点随机数。
38.步骤二、以openmp多线程并行化的方式在cpu上执行面板分解过程,使cpu所有核心的使用率达到100%;
39.具体地,以openmp多线程并行化的方式在cpu上执行面板分解过程包括,调用openmp多线程库将该面板的分解并行化计算,令openmp的线程数等于core/p0,其中core等于一个节点中cpu的核心数,p0为当前节点的行进程数量,因此节点中的所有cpu核的使用率可达到100%,实现计算cpu端计算效率的最大化。
40.步骤三、使用基于gpu-aware的ring广播算法将分解完成的面板数据以及矩阵行交换信息广播至位于同一行的其余列进程;
41.具体地,完成面板的分解后,将面板数据广播到处于同一行进程的列进程中,广播面板数据的过程具体包括:将拥有面板数据的进程设置为根进程,由根进程向相邻的单个列进程发送面板数据;相邻的单个列进程收到数据后,再进一步转发给另外的相邻进程,最终以一种“环形”的方式将面板数据广播出去。该广播方式可以有效减少根进程的数据通信量。
42.优选地,优化后的广播算法是基于gpu-aware mpi实现的,由于每个进程绑定一个gpu,因此能够实现点对点的gpu到其它gpu的数据传输而不必要经过cpu进行中转传输,使用基于gpu-aware的ring广播算法将分解完成的面板数据以及矩阵行交换信息广播至位于同一行的其余列进程步骤,具体包括:
43.在一端的gpu使用mpi_send()发送数据,另一端的gpu使用mpi_recv()和mpi_iprobe()接收数据,mpi_send()以及mpi_recv()中的数据缓冲区均使用gpu中的显存地址。
44.步骤四:gpu接收到矩阵的行交换信息后,根据gpu的合并访存原理以及高速缓存的特点,调用自定义内核对存放在显存中的矩阵完成行交换操作;
45.具体地,当gpu收到广播的行交换信息,将行数据存入可编程高速缓存lds(local data share)中,当矩阵的一行数据全部读入lds后,对所有gpu线程进行同步,将相邻存储空间的数据写入gpu的显存里,完成行交换操作。
46.本实施中,当gpu收到广播的行交换信息,可以利用gpu硬件结构中的可编程高速缓存lds来实现高效的行交换操作。lds是gpu中的一块高速缓存,提供了比全局内存更大的读写带宽。由于lds由gpu中同一个线程块中的不同线程共享,它为线程提供了一种协作机制,为不同线程提供同步操作。gpu还拥有合并访存的特点,即相邻线程往相邻的全局内存空间写入数据时,可以减少访问所花费的时钟周期。因此,在hpl的行交换过程中,将矩阵的单行数据存入lds中,待该行数据全部读入lds后,对同一线程块中的所有gpu线程调用__synchtreads()语句进行同步,然后再次利用gpu的合并访存特性将相邻存储空间的数据由lds写入gpu的显存里,从而高效地完成行交换操作。
47.步骤五:在gpu里完成行交换操作后,gpu使用接收到的面板矩阵数据更新剩余的矩阵数据,包括调用dtrsm()函数更新上三角矩阵和优化过的gemm(通用矩阵乘法,general purpose matrix multiplication)函数更新尾随矩阵;
48.具体地,在hpl中使用深度为1的look ahead算法,即在cpu上对矩阵的一个面板
panel0根据步骤二进行预分解,同时对面板之外的矩阵数据进行二次切分,切分成面板panel1和矩阵m1。
49.在look ahead算法中,面板panel1根据已经分解完成的panel0调用dtrsm()函数进行上三角矩阵的更新以及调用gemm()函数进行尾随矩阵的更新。
50.完成面板panel1的更新后,可通过gpu编程模型中的流(stream)对矩阵m1的更新以及面板panel1在cpu上的分解并行化计算,此时cpu与gpu以异步的方式并行计算,计算效率达到最大化。
51.如图2所示,基于异构平台的高性能linpack基准测试程序优化方法的数据流程图,描述了上述步骤的数据处理流程。假设已完成部分一部分数据的lu分解,对由和组成的面板执行面板分解对应了步骤二的数据处理过程。行交换对应步骤四的数据处理过程,完成面板分解以及行交换后,对调用dtrsm()函数以及对a
″i执行gemm()对应步骤五中的数据处理过程。
52.步骤六:递归执行步骤二至步骤五,直至整个矩阵分解完成,调用定时函数计算矩阵完成分解的总时间,同时对结果进行验算,即得到异构平台的浮点运算性能。
53.具体地,当递归完成步骤二至步骤五的计算后,原有的在显存中的矩阵已经被分解为下三角矩阵l以及上三角矩阵u,并覆盖原有矩阵的数据,完成分解后执行hpl_pdtrsv()对方程组求解求解得到方程组的结果,从步骤二至求解出方程组的时间即hpl评估一套系统浮点性能的指标。对方程组的结果进行验算,即得到异构平台的浮点运算性能。
54.综上所述,本发明可以为基于cpu+gpu的异构系统提供高效的hpl运行方案,通过使用openmp多线程执行面板分解的优化方式,以完全发挥cpu的计算能力;使用基于gpu-aware的ring广播算法对分解完成的面板进行广播,减少了数据在主机内存上进行中转的开销;充分利用gpu的访问特点,在gpu上高效并行地进行行交换操作;流水线化cpu和gpu上的计算任务,降低由于cpu和gpu算力差距大造成的空闲等待时间。优化后的异构计算平台下的hpl基准测试能在一定程序上解决算法、通信等等很多方面的瓶颈,更准确地体现了异构系统的最优性能。
55.实施例2:
56.本实施例提供了一种计算机设备,该计算机设备可以是服务器、计算机等,其包括通过系统总线连接的处理器、存储器、输入装置、显示器和网络接口,该处理器用于提供计算和控制能力,该存储器包括非易失性存储介质和内存储器,该非易失性存储介质存储有操作系统、计算机程序和数据库,该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境,处理器执行存储器存储的计算机程序时,实现上述实施例1的基于异构平台的高性能linpack基准测试程序优化方法,如下:
57.s1、根据配置文件初始化hpl的运行参数,使用随机数生成算法生成设定规模的矩阵,矩阵所占用的内存空间完全覆盖参与计算的gpu显存大小;
58.s2、以openmp多线程并行化的方式在cpu上执行面板分解过程,使cpu所有核心的使用率达到100%;
59.s3、使用基于gpu-aware的ring广播算法将分解完成的面板数据以及矩阵行交换信息广播至位于同一行的其余列进程;
60.s4、gpu接收到矩阵的行交换信息后,根据gpu的合并访存原理以及高速缓存的特
点,调用自定义内核对存放在显存中的矩阵完成行交换操作;
61.s5、在gpu里完成行交换操作后,gpu使用接收到的面板矩阵数据更新剩余的矩阵数据,调用dtrsm()函数更新上三角矩阵和优化过的gemm函数更新尾随矩阵;
62.s6、递归执行步骤s2至s5,直至整个矩阵分解完成,调用定时函数计算矩阵完成分解的总时间,同时对结果进行验算,得到异构平台的浮点运算性能。
63.具体地,步骤s1包括:在运行hpl前将hpl的运行参数写入配置文件中,所述运行参数包括生成矩阵的大小n、分块后的矩阵大小nb、总的行进程数量p、总的列进程数量q、广播算法;根据矩阵的大小n分配n*(n+1)大小的矩阵分布到各个节点中的gpu显存中,再调用gpu的随机数生成算法对矩阵的数据进行初始化。
64.所述步骤s5具体包括:在hpl中使用深度为1的lookahead算法,在cpu上对矩阵的一个面板panel0进行预分解,对面板之外的矩阵数据进行二次切分,切分成面板panel1和矩阵m1;
65.面板panel1根据已经分解完成的panel0进行上三角矩阵以及尾随矩阵的更新;
66.通过gpu编程模型中的流(stream)对矩阵m1的更新以及面板panel1在cpu上的分解并行化计算。
67.上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1