使用可压缩决定来预测数据的压缩比的制作方法
1.本发明涉及神经网络加速器,特别涉及使用神经网络的压缩预测和决策。
背景技术:
2.神经网络对网络内的节点使用权重。网络的拓扑结构和连接可以由特征图定义。对于深度神经网络和卷积神经网络,这些权重和特征图可能相当大。
3.神经网络权重和特征图可以在存储或传输之前被压缩。图1显示了一个神经网络,其权重和特征图在存储或传输前进行了压缩。神经网络104可以是图形处理单元(gpu)或专用神经网络处理器。神经网络104可能已经被训练过,其权重和特征图被调整为针对特定问题或数据集进行了优化。这些权重和特征图可以备份或存储在存储器102中。
4.然而,存储器102可以远离神经网络104,例如当神经网络104在便携式设备上并且存储器102是云存储时。神经网络104和存储器102之间的连接在带宽上可能是有限的。压缩器100可以使用无损压缩对来自神经网络104的权重和特征图进行压缩,并且将压缩后的数据发送到存储器102。可以减少存储器102中存储所需的内存量,也可以减少传输所消耗的带宽。
5.存储在存储器102中的压缩权重和特征图可以通过网络链接传输到包括压缩器100的本地设备,压缩器100对权重和特征图进行解压,并将它们加载到神经网络104中,以配置神经网络104用于特定处理任务。
6.有些数据可能是非常随机或无结构的,以至于其压缩效果不佳。最好不要尝试压缩此类数据,因为压缩后的数据可能比原始数据还大。可以使用熵和其他方法来预测数据集的压缩比。预测的压缩比可用于在存储器102中保留存储空间,并决定何时压缩或不压缩数据。
7.然而,基于熵的压缩比预测可能难以在硬件中实现,因为熵计算通常需要对数运算。预测的压缩比可能非常依赖于数据。
8.在一些应用中,存储器102可以不根据预测的压缩比来保留存储空间。那么实际的压缩比就不是真阳性需要的;只有压缩或不压缩数据的决定才是真阳性需要的。可以将预测的压缩比与阈值进行比较,以决定何时压缩数据,但是除了与阈值相比之外,预测的压缩比的值并不真阳性重要。
9.希望有一种更简化的方法来达到压缩/不压缩决定,而不涉及计算预测的压缩比。希望使用神经网络来做出压缩/不压缩决定,而不预测压缩比。在使用预测压缩比的其他应用中,希望使用经过训练的神经网络来计算预测压缩比。希望有一种既可以预测压缩比又可以更快地生成压缩决策的神经网络。希望有一个不使用熵计算或对数运算的压缩预测器。
附图说明
10.图1显示在存储或传输之前对其权重和特征图进行压缩的神经网络。
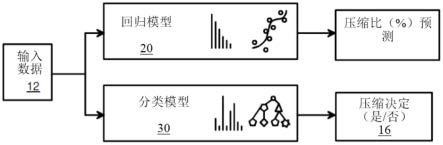
11.图2是压缩预测神经网络的框图。
12.图3更详细地显示了回归模型。
13.图4更详细地显示了分类模型。
14.图5是分类模型使用接受者操作特征(receiver operating characteristic,roc)曲线来设置可压缩决定阈值的图。
15.图6显示混淆矩阵。
16.图7是基于零值个数(number of zeros,nz)的预测的训练数据的图。
17.图8是基于集中度(concentration value,cv)的预测的训练数据的图。
18.图9是基于集中度(cv)乘以零值个数(nz)的预测的训练数据的图。
19.图10是图9的曲线图的放大图。
20.图11a-11b是用于压缩预测和决定的神经网络的运行流程图。
21.图12是使用接受者操作特征(roc)曲线来优化水平阈值thh的流程图。
22.图13是几个接受者操作特征(roc)曲线的图。
23.图14a-14b突出显示了生成roc曲线并选择具有最大约登指数的最佳thh。
具体实施方式
24.本发明涉及对压缩预测神经网络的改进。下面的描述是为了使本领域普通技术人员能够在特定应用及其要求的背景下制造和使用本发明。对优选实施例的各种修改对于本领域的技术人员来说将是显而易见的,并且本文所定义的一般原则可应用于其它实施例。因此,本发明并不打算局限于所示和所述的特定实施例,而是要给予符合本文所公开的原则和新颖特征的最广泛的范围。
25.图2是一个压缩预测神经网络的框图。输入数据12可以是一个或多个要在有限带宽网络上传输的数据块。希望对输入数据12进行压缩。当需要估计压缩数据的大小时,例如为了保留带宽或存储空间,输入数据12被发送到在神经网络上实施的回归模型20。回归模型20输出压缩比预测14。压缩比可以表示为原始文件大小的百分比,其中100%表示不可压缩文件,而较低百分比表示更高压缩的文件。例如,20%的压缩比表示压缩后的文件只有原始数据文件的五分之一大小。
26.当不需要预测压缩百分比时,例如当不根据预测的压缩文件大小来保留存储器带宽时,则不激活回归模型20。相反,输入数据14被发送到分类模型30。分类模型30也由神经网络实施。分类模型30将输入数据分类为可压缩或不可压缩。二元判断可能比预测压缩比更容易和更快获得,因为只有2个可能的输出:是或否。分类模型30输出压缩决定16,它可以是一个单一的二进制比特或布尔值。
27.图3更详细地显示了回归模型。输入数据块被应用于计数器22,该计数器对输入数据中每个可能的符号值出现的符号数进行计数,以获得每个符号的计数或频率。计数器22可以生成直方图或表,例如符号频率表。该符号频率表由符号值(x)索引,并不是根据频率或计数(y)来排序的,因此频率峰值可以出现在频率表的任何地方。
28.然后,排序器24对由计数器22生成的符号频率表中的频率计数进行排序,以获得排序的频率表。该排序的频率表将具有最高计数或频率的符号放在最左边的位置,接着是第二高计数的符号,然后是第三高计数的符号,依此类推。因此,在排序器24生成的排序频
率表中,频率或计数值随着x轴或索引而减少。
29.剪切器26从排序的频率表中删除具有最小计数值的符号条目。例如,对于符号值从1到256的8比特符号,具有最低频率计数的128个符号可以被剪切器26删除。剪切器26只保留出现次数或频率最高的128个符号。剪切减小了数据集的大小,并允许神经网络更快地处理。
30.实施回归模型20的神经网络必须首先使用训练数据进行训练。训练数据可以包括大量的输入数据块,这些输入数据块也有压缩比数据。例如,每个训练输入数据块可以被压缩,以确定压缩比,或者可以使用另一个预测计算器来生成训练数据的压缩比。
31.训练器28可以是一个被配置为线性回归的神经网络。具有其压缩比值的训练输入数据集被输入到训练器28。随着训练器28处理更多训练集,神经网络中的权重及其特征图被调整,直到达到训练终点或收敛。
32.在训练器28已经处理了训练数据并到达终点后,最终的权重被应用到神经网络,以配置其用于压缩预测。经训练的神经网络作为推理器29,使用具有经训练的权重的神经网络来为每个输入数据块生成压缩预测。在训练期间,随着训练数据的处理,计数器22、排序器24、剪切器26和训练器28用于调整神经网络的权重。然后在正常处理期间,计数器22、排序器24、剪切器26和推理器29用于生成预测的压缩比。训练器28和推理器29使用相同的神经网络。当作为推理器29运行时,权重是固定的,但在作为训练器28运行时,权重在训练期间被调整。
33.图4更详细地显示了分类模型。计数器22为每个符号值生成频率计数,可以是回归模型20使用的相同模块。计数器22可以由回归模型20和分类模型30共享。
34.由排序器24(图3)进行的排序是耗时且计算密集的,因此增加了计算延迟。发明人已经意识到,对于二元可压缩决定,不需要进行排序,这比预测压缩比时有更快的决定。
35.集中度计算器34通过对每个频率计数进行平方,然后将所有平方的频率计数相加,来计算输入数据块的集中度。对于符号值为0到255的8比特符号k,和频率计数frequency[k],集中度(concentration value,cv)可以表示为:
[0036][0037]
通过集中度计算器34,可以得到每个数据块的单个集中度(cv)。
[0038]
输入数据块中的零值符号的数量由零值计数器36计数。该计数与计数器22为具有零值的符号生成的频率计数相同,因此零值计数器36可以简单地在由计数器22生成的符号频率表中查找符号值0以获得零值个数(nz)。或者,零值计数器36可以扫描输入数据块,产生一个新的输入数据块中零值符号数量的计数。
[0039]
发明人意识到,许多可压缩数据块包含大量零值符号或具有高集中度的其他符号。不可压缩块通常很少有零值符号,并且缺乏其他符号的集中度,因此它们的cv和nz值会很低。发明人通过乘法将cv和nz结合起来,以用作阈值比较器的输入。
[0040]
比较器38将乘积cv*nz与阈值thh进行比较,以确定输入数据块何时是可压缩的或不可压缩的。比较器38做出的简单的是/否的决定是快速且易于实施的。然而,决定的有用
性和准确性很大程度上取决于阈值thh。
[0041]
图5是分类模型使用接受者操作特征(roc)曲线来设置可压缩决定阈值的图。在训练期间,将训练输入数据应用到计数器22,集中度计算器34计算出集中度(cv),而零值计数器36找到每个训练数据块的零值个数(nz)(出现零值的符号)。
[0042]
绘图器42绘制或制作乘积cv*nz作为压缩器40的压缩比c%的函数的表格。图9是绘图器42生成的绘图的一个示例,其中每个数据点是针对不同的训练数据集。用户设置了一个垂直阈值thv,它是一个被认为是可压缩极限的压缩比%。thv在某种程度上是任意的,可以设置为一个95%之类的值,然后再进行调整。
[0043]
roc生成器44生成接受者操作特征(roc)曲线。roc生成器44测试水平阈值thh的各种值。roc生成器44针对所测试的不同thh值,获得并绘制真阳性率(true positive rate)作为假阳性率(false positive rate)的函数。例如,图14a是roc生成器44生成的表格,图14b是roc生成器44生成的roc曲线图。
[0044]
thh选择器46检查由roc生成器44生成的roc图或表,并选择沿roc曲线产生具有最大约登指数(youden index)的点的thh值。约登指数可以表示为对角线与roc曲线之间的垂直线的距离,如图13所示。约登指数优化了thh的区分能力,对灵敏度和特异度给予同等的重视。
[0045]
因此,水平阈值thh由roc生成器44和thh选择器从训练数据集的cv*nz和c%数据中获得。
[0046]
垂直阈值和水平阈值的单位不同。垂直阈值thv是压缩百分比c%,而水平阈值thh是cv*nz的值。thh用于快速做出压缩决定,而thv用于在训练期间获得可在运行时使用的最佳thh值。
[0047]
图6显示了一个混淆矩阵。混淆矩阵对于评估二元分类模型很有用,例如分类模型30(图2)所使用的。将训练数据应用于图5的装置,以绘制cv*nz与c%的关系图,然后应用一系列thh值和一个vth固定值来评估阈值的有效性。
[0048]
垂直阈值thv被设置为判断真的阳性样本和阴性样本(true positive and negative samples)的基准。水平阈值thh是通过一种方法判断的阳性样本和阴性样本之间的分界线。这意味着有真的阳性和阴性,也有检测到的阳性和阴性。因此,将有四组:真阳性(true positive,tp)、假阳性(false positive,fp)、假阴性(false negative,fn)和真阴性(true negative,tn)。
[0049]
为了获得一个数据集的最佳水平阈值thh,发明人根据混淆矩阵的值绘制roc曲线。最佳水平阈值thh是所有roc曲线的左上角点。最佳c%就是最佳水平阈值。
[0050]
垂直阈值thv表示为压缩百分比%,并将实际的阳性和阴性结果分开。水平阈值thh表示为cv*nz值,而不是压缩百分比%。预测值可以是阳性或阴性。阳性表示不可压缩,而阴性表示可压缩。
[0051]
预测可以是正确的或不正确的。当预测为阳性(不可压缩)且压缩百分比大于垂直阈值c%》thv时,发生真阳性(tp)。当预测为阴性(可压缩)且压缩百分比小于垂直阈值c%《thv时,发生真阴性(tn)。对于tp和tn情况,压缩决定是正确的。
[0052]
不正确的预测发生在假阳性(fp)和假阴性(fn)的情况。当预测为阳性(不可压缩)但c%《thv时,就发生假阳性(fp),因此文件确实是可压缩的(阴性),或低于用户设置的垂
直压缩阈值。当预测为阴性(可压缩)但c%》thv时,发生假阴性(fn),因此文件确实不可压缩(阳性),高于垂直阈值。
[0053]
垂直和水平阈值thv、thh可以被移动或调整以改善预测结果并减少假阳性或假阴性。例如,将垂直阈值vth向右移动会增加真阳性(tp)并减少假阳性(fp),但真阴性(tn)也会减少,而假阴性(fn)会增加。
[0054]
图7是具有基于零值个数(nz)的预测的训练数据图。nz对于压缩预测很有用。
[0055]
图中的每个点代表以一个不同的数据块。当垂直阈值thv62被设置为90%时,可以将水平阈值thh 64设置为低值,以提供大量的真阴性,或具有正确预测的可压缩文件。这个低thh 64也能捕捉到几个真阳性,或被正确预测为不可压缩的数据集。
[0056]
然而,在thv 62和thh 64的右上象限中发现了一些假阴性。这些是不可压缩文件,被错误地预测为可压缩的。左下象限出现很少的假阳性。虽然仅使用nz作为水平阈值是有用的,但仍然有太多的假阴性。
[0057]
图8是具有基于集中度(cv)的预测的训练数据图。cv对于压缩预测也很有用。当垂直阈值thv 62被设置为90%时,水平阈值thh 64可以设置为低值,以提供大量真阴性,或具有正确预测的可压缩文件。这个低thh 64还捕获了许多真阳性,或被正确预测为不可压缩的数据集。
[0058]
然而,由于与nz(图7)相比,数据更倾向于向下弯曲,因此会出现大量假阳性。必须将thh 64设置为非常低的水平才能消除这些假阳。然后真阳性也会减少,而假阴性会增加。仅仅使用cv来设置水平阈值会产生太多假阳性。
[0059]
图9是基于集中度(cv)乘以零值个数(nz)的预测的训练数据图。每个训练数据块的cv*nz的值被绘制在y轴上,作为该块的压缩比c%的函数。与单独的cv或nz曲线相比,乘积cv*nz的曲线更陡峭且更适合(图7-8)。这个更陡峭的图提供了更好的区分预测结果。
[0060]
垂直阈值thv 62可以设置为一个较高的值,例如97%。这允许更多文件被压缩。真阴性增加。水平阈值thh 64可以设置为一个较低的值,以减少假阳性,同时仍能识别真阳性(不可压缩文件)。
[0061]
图10是图9图形的放大图。图10放大了垂直阈值thv 62和水平阈值thh 64的交叉点附近的区域。通过将thv调整到97.5%,几乎消除了假阴性。仍然有一些假阳性,但有更多的真阳性。
[0062]
图11a-11b显示了用于压缩预测和决定的神经网络的运行流程图。在图11a中,在步骤502,接收符号数据集并对所有符号的频率进行计数。在步骤504,当仅需要一个压缩决定时,则过程在图11b中继续。在步骤504,当需要一个压缩预测而不是一个决定时,则在步骤506对符号频率进行排序。当仅需要一个决定时,不需要排序,在图11b,允许更快地做出压缩决定。
[0063]
在图11a中继续,在步骤508,低频符号被剪切和丢弃,从而产生较小的排序的符号频率数据集。由于数据集较小,后续处理可能会减少。
[0064]
在步骤510,使用训练数据训练神经网络,以获得训练的权重。然后在步骤512,神经网络使用经过训练的权重来生成对输入数据集的压缩比的预测。在步骤512处理实际数据集之前,可以对通过步骤502、506、508进行了排序和剪切的许多训练数据集重复执行步骤510。
[0065]
在图11b中,仅需要压缩决定;不需要压缩比预测。符号频率未排序,但用于计算未排序的输入数据集的集中度(cv)(步骤520)和零值个数(nz)(步骤522)。
[0066]
水平阈值thh之前已使用图12的roc过程530获得。在步骤532,cv和nz的乘积(cv*nz)与水平阈值thh进行比较。在步骤534,当cv*nz大于thh时,那么该文件是可压缩的,nocompress标志设置为假。
[0067]
图12是使用接受者操作特征(roc)曲线来优化水平阈值thh的流程图。在实时输入数据集被处理之前,roc过程530在训练期间被执行。在步骤542,每个训练数据块被压缩,以获得实际压缩率c%。例如通过图11b的步骤520、522获得每个数据块的cv和nz。然后在步骤544,将乘积cv*nz作为c%的函数绘制或制成表格。
[0068]
在步骤546,通过确定每个训练数据块何时是真阳性或假阳性,为不同的thh测试值生成roc曲线上的点。在步骤548,通过计算每个thh测试值的约登指数并选择具有最大约登指数的thh测试值,来选择最佳的thh值。在步骤550,返回选择的具有最大约登指数的thh。在运行处理期间,通过将选择的thh与乘积cv*nz进行比较,可以快速做出压缩决定。
[0069]
图13是几个接受者操作特征(roc)曲线的图。许多训练数据块被处理,每个数据块的cv*nz作为c%的函数被绘制或制表。得到一个如图9所示的图形,每个点代表训练数据中的不同数据块。垂直阈值thv被设置为一个用户定义的值,例如95%。但是,水平阈值thh在图中在thh值的范围内上下移动。随着水平阈值thh 64的上移,更多的数据点被分类为假阳性,但也可能有更多的真阳性。水平阈值thh 64下移将增加真阴性并减少假阳性和真阳性。
[0070]
对于thh值的范围,将这些不同的真阳性和假阳性绘制或制成表格,以形成roc曲线122。每条roc曲线代表二元分类器系统的诊断能力。随机分类器产生对角线120。通常,离对角线120较远的roc曲线代表更好的分类器。因此,roc曲线124是比roc曲线122更好的分类器,而roc曲线126不如roc曲线124、122。
[0071]
对于任何特定的神经网络分类器系统,所有训练数据块将仅沿着一条roc曲线产生点。例如,当神经网络对不同的thh测试值沿roc曲线124产生点时,thh的最佳值可以被发现为沿roc曲线124离对角线120最远的那一点。这种优化可以通过为每个thh测试值,或为沿roc曲线124上的每个点寻找约登指数来找到。约登指数最大的点是thh的最佳值。
[0072]
在该示例中,约登指数128是roc曲线124的最大值。约登指数128指向roc曲线124上具有最佳thh值的点。
[0073]
图14a-14b突出显示了生成roc曲线并选择具有最大约登指数的最佳thh。在此示例中,垂直阈值thv设置为95%,因为如果文件在压缩时至少小5%,则认为文件是可压缩的。
[0074]
在图14a中,许多训练数据块已被处理以生成cv*nz值作为c%函数的表格,并在图14a中对thh的各种测试值的真阳性(tp)点、假阳性(fp)点、真阴性(tn)点、假阴性(fn)点进行了统计和列表。thh的测试值范围从0.0到1.0。如图14a的表格中可以看出,随着thh增加,fp增加而tn减少。
[0075]
从图14a中的tp和fn值计算出真阳性率为:
[0076]
tpr=tp/(tp+fn)
[0077]
tpr也称为召回率。根据图14a表中的fp和tn值计算出假阳性率为:
[0078]
fpr=fp/(fp+tn)
[0079]
将计算出的tpr绘制为fpr的函数,以获得图14b中的曲线。表中的每个thh值对应于图14b中roc曲线140中的一个点。roc曲线140上到对角线120的距离最大的那一点具有最大约登指数,是最优点。thh值为0.1的点是这个最佳点,因为它距离对角线120的距离比thh值为0.2、0.3、0.5、0.9等的点更远。roc曲线140上每个点的实际约登指数可以计算为到对角线120的垂直距离。然后可以选择最高的约登指数,并将其对应的thh输出作为优化的thh。替代实施例
[0080]
发明人还补充了若干其他实施例。压缩器40可以确定每个训练数据块的压缩比(c%),例如通过压缩数据并比较压缩前后的文件大小,或者通过使用压缩比算法而不实际压缩数据。另外,c%可以与输入训练数据一起提供,这样就不需要压缩器40了。
[0081]
虽然为了让读者更好地理解,已经显示和描述了图表和曲线图,但是计算机系统可以使用表格或其他数据结构来实现这些曲线或图形。表格可以是计算机实施的图。
[0082]
虽然最优水平阈值thh已被描述为由roc曲线中具有最大约登指数的点找到,但也可以使用次优水平阈值thh,例如由具有第二大约登指数的roc曲线点找到。一些应用程序允许次优阈值。水平阈值thh也可以设置一次,例如在初始化时或在工厂制造期间,并对所有未来的数据集保持不变,尽管为新数据集重新校准水平阈值thh可以产生更好的压缩决定。水平阈值thh也可以根据经验设置或由用户设置。
[0083]
各种参数可以以各种方式和变化来表达。例如,对于不可压缩的文件,压缩比可以定义为100%,对于压缩后缩小80%的文件,压缩比可以定义为20%,或者对于压缩后只缩小20%的文件,压缩比可以定义为20%。其他统计数据同样可以被改变、重新定义、转移、转换等。
[0084]
roc曲线可以用不同的x和y轴定义来生成。真阳性率和假阳性率可以改为其他定义。这些替代的roc曲线上的最佳点可以通过类似于约登指数的其他方法获得,例如图形方法。
[0085]
可以通过使用零值计数器、存储器如半导体或磁盘存储器、输入或从符号频率表中读取来跟踪零值个数(nz)。nz可以存储在零值计数器、存储器、表格、寄存器或处理单元中,并且可以存储在多个位置。
[0086]
可以使用各种块大小和符号大小。块大小可以是固定的或可变的。一个8比特符号和一个8字节块只是众多可能性中的一种。符号值可以被编码为二进制、二进制补码或其他编码代码。
[0087]
一些实施例可能没有使用所有组件。可以添加额外的组件。训练期间收敛的损失函数可以使用各种误差/损失和成本生成器,如防止权重在许多训练优化周期中增长过大的权重衰减项,鼓励节点将其权重归零的稀疏惩罚,以便只使用总节点的一小部分。许多替换、组合和变化都是可能的。损失或成本项的其他变化和种类可以添加到损失函数中。不同成本函数的相对比例因子的值可以被调整,以平衡各种函数的影响。神经网络的训练终点可以针对各种条件组合设置,例如所需的最终精度、精度-硬件成本乘积、目标硬件成本等。
[0088]
神经网络、损失函数和其他组件可以用各种技术实现,使用软件、硬件、固件、例程、模块、功能等的各种组合。最终结果可以从具有最终权重的神经网络中得到,并可能以程序模块实现,或者在专用集成电路(asic)或其他硬件中实现,以提高处理速度和降低功
耗。
[0089]
左、右、上、下等术语是相对的,可以以各种方式进行翻转、旋转、变换或转置。加法器可添加补码值以实施减法。因此,减法和加法可以互换使用。
[0090]
各种交织和映射方案可以改变实际存储位置,以优化带宽或其他设计参数。许多内存安排,无论是物理的还是逻辑的,都是可能的。可以使用各种并行处理技术,以串行方式执行此处描述的基本操作,以便更容易理解。
[0091]
本发明的背景部分可以包含关于本发明问题或环境的背景资料,而不是描述他人的现有技术。因此,在背景技术部分中包含的材料并不是申请人对现有技术的承认。
[0092]
本文描述的任何方法或过程都是机器实施的或计算机实施的,旨在由机器、计算机或其他设备来执行,而不打算在没有机器辅助的情况下仅由人类执行。产生的有形结果可以包括报告或其他机器生成的显示在诸如计算机显示器、投影设备、音频生成设备和相关媒体设备的显示设备上,可以包括也是机器生成的硬拷贝打印输出。其他机器的计算机控制是另一个有形的结果。
[0093]
所述的任何优点和好处不一定适用于本发明的所有实施例。当“装置”一词出现在权利要求元素中时,申请人意在该权利要求元素落入35usc第112节第6款的规定。通常,在“装置”一词之前有一个或多个词的标签。在“装置”一词前面的一个或多个词是一个标签,目的是为了便于权利要求元素的引用,而不是为了表达结构上的限制。这种装置加功能的权利要求不仅要涵盖本文所述的用于执行该功能的结构及其结构等同物,而且要涵盖等效结构。例如,虽然钉子和螺钉具有不同的构造,但它们是等效结构,因为它们都执行紧固功能。未使用“装置”一词的权利要求不落入35usc第112节第6款的规定。信号通常是电子信号,但也可以是光信号,例如可以通过光纤线路传输。
[0094]
对本发明实施例的上述描述是为了说明和描述的目的而提出的。它并不打算是详尽的,也不打算将本发明限制在所公开的精确形式中。根据上述教学,许多修改和变化是可能的。其目的是本发明的范围不受本详细说明的限制,而是受附于权利要求书的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1