用于生成图形代码的表示的应用程序编程接口的制作方法
用于生成图形代码的表示的应用程序编程接口
1.优先权声明
2.本技术要求2021年4月15日提交的题为“图形调试信息(graph debugging information)”的美国临时申请no.63/175,193和2022年4月11日提交的题为“用于生成图形代码的表示的应用程序编程接口(application programming interface to generate arepresentation of graph code)”的美国专利申请no.17/718,065的权益,其全部内容通过引用并入本文。
技术领域
3.至少一个实施例涉及用于生成图形代码的描述性表示的处理资源。例如,至少一个实施例涉及用于生成实现本文描述的多种新技术的图形代码的描述性表示的处理器或计算系统。
背景技术:
4.例如图形的工具可用于在计算机程序中提供增加的功能和其他优点。随着此类工具的使用越来越多,它们会变得越来越复杂,使得调试变得越来越困难。此外,此类工具通常以难以获得有用信息的格式来存储。
附图说明
5.图1示出了根据至少一个实施例的描述性表示的示例;
6.图2示出了根据至少一个实施例的描述性表示的另一示例;
7.图3示出了根据至少一个实施例的描述性表示的另一示例;
8.图4示出了根据至少一个实施例的描述性表示的另一示例;
9.图5示出了根据至少一个实施例的图形调试点打印api调用的图;
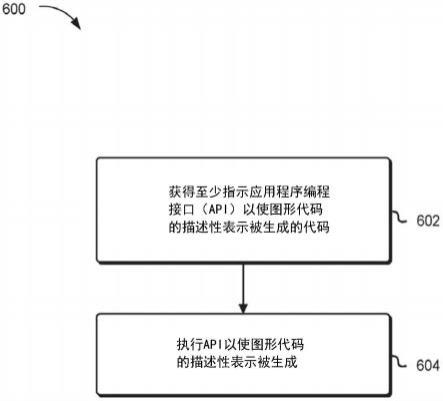
10.图6示出了根据至少一个实施例的导致生成图形代码的描述性表示的过程的示例;
11.图7示出了根据至少一个实施例的示例性数据中心;
12.图8示出了根据至少一个实施例的处理系统;
13.图9示出了根据至少一个实施例的计算机系统;
14.图10示出了根据至少一个实施例的系统;
15.图11示出了根据至少一个实施例的示例性集成电路;
16.图12示出了根据至少一个实施例的计算系统;
17.图13示出了根据至少一个实施例的apu;
18.图14示出了根据至少一个实施例的cpu;
19.图15示出了根据至少一个实施例的示例性加速器集成切片;
20.图16a和16b示出了根据至少一个实施例的示例性图形处理器;
21.图17a示出了根据至少一个实施例的图形核心;
22.图17b示出了根据至少一个实施例的gpgpu;
23.图18a示出了根据至少一个实施例的并行处理器;
24.图18b示出了根据至少一个实施例的处理集群;
25.图18c示出了根据至少一个实施例的图形多处理器;
26.图19示出了根据至少一个实施例的图形处理器;
27.图20示出了根据至少一个实施例的处理器;
28.图21示出了根据至少一个实施例的处理器;
29.图22示出了根据至少一个实施例的图形处理器核心;
30.图23示出了根据至少一个实施例的ppu;
31.图24示出了根据至少一个实施例的gpc;
32.图25示出了根据至少一个实施例的流式多处理器;
33.图26示出了根据至少一个实施例的编程平台的软件栈;
34.图27示出了根据至少一个实施例的图26的软件栈的cuda实现;
35.图28示出了根据至少一个实施例的图26的软件栈的rocm实现;
36.图29示出了根据至少一个实施例的图26的软件栈的opencl实现;
37.图30示出了根据至少一个实施例的由编程平台支持的软件;
38.图31示出了根据至少一个实施例的在图26-29的编程平台上执行的编译代码;
39.图32示出了根据至少一个实施例的在图26-29的编程平台上执行的更详细的编代码;
40.图33示出了根据至少一个实施例的在编译源代码之前转换源代码;
41.图34a示出了根据至少一个实施例的被配置为使用不同类型的处理单元来编译和执行cuda源代码的系统;
42.图34b示出了根据至少一个实施例的被配置为使用cpu和启用cuda的gpu来编译和执行图34a的cuda源代码的系统;
43.图34c示出了根据至少一个实施例的被配置为使用cpu和未启用cuda的gpu来编译和执行图34a的cuda源代码的系统;
44.图35示出了根据至少一个实施例的由图34c的cuda到hip转换工具转换的示例性内核;
45.图36更详细地示出了根据至少一个实施例的图34c的未启用cuda的gpu;
46.图37示出了根据至少一个实施例的示例性cuda网格的线程如何被映射到图36的不同计算单元;以及
47.图38示出了根据至少一个实施例的如何将现有cuda代码迁移到数据并行c++代码。
具体实施方式
48.在至少一个实施例中,一种或更多种编程模型利用一种或更多种表示操作和所述操作之间的依赖关系的数据结构来执行各种操作。在至少一个实施例中,图形是一种表示操作和所述操作之间的依赖关系的数据结构。在至少一个实施例中,虽然本文描述的技术可以涉及图形,但是本文描述的技术可适用于表示、编码或以其他方式存储操作和/或所述
操作之间的依赖关系的任何合适编程模型的任何合适数据结构。在至少一个实施例中,一个或更多个编程模型包括诸如计算统一设备架构(cuda)模型、可移植性异构计算接口(hip)模型、oneapi模型、各种硬件加速器编程模型和/或其变体之类的模型。在至少一个实施例中,所述图形表示在一个或更多个处理单元上执行的一系列操作,例如中央处理单元(cpu)、图形处理单元(gpu)、通用gpu(gpgpu)、并行处理单位(ppu)和/或其变体。在至少一个实施例中,所述图形是数据对象,也称为图形数据结构、图形代码和/或其变体,其定义了通过依赖关系连接的一系列操作,例如内核启动。在至少一个实施例中,所述图形的依赖关系与所述图形的执行分开定义。在至少一个实施例中,所述图形被定义一次并且可以被启动一次或更多次。
49.在至少一个实施例中,操作对应于所述图形中的节点。在至少一个实施例中,操作之间的依赖关系形成所述图形的边。在至少一个实施例中,依赖关系约束操作的执行序列。在至少一个实施例中,一旦所述操作所依赖的节点已经完成(例如,由节点指示的操作已经被实施/执行),所述操作就可以在任何时间被调度。在至少一个实施例中,由节点指示的操作可以包括诸如内核、cpu函数调用、主机函数、设备函数、内存复制操作、内存设置操作、内存管理/操纵操作、等待事件、记录事件、向外部信号量发出信号、等待外部信号量,以及其他图形(例如,子图形)的操作。在至少一个实施例中,通过各种编程模型应用程序编程接口(api)函数来创建和修改图形。在至少一个实施例中,所述图形的操作通过各种编程模型api函数来执行。
50.在至少一个实施例中,通过一个或更多个操作来创建图形,这可以称为流捕获。在至少一个实施例中,定义了一个或更多个操作,其中流捕获被用来捕获所述图形中的所述一个或更多个操作。在至少一个实施例中,一系列一个或更多个操作被称为流。在至少一个实施例中,例如,api调用指示一系列操作的开始,也称为流,并且不同的api调用指示所述系列操作的结束,其中所述系列操作然后被实例化为所述图形。在至少一个实施例中,通过一个或更多个操作来创建图形,这些操作可以被称为图形操作。在至少一个实施例中,通过各种图形api函数来创建和修改图形。在至少一个实施例中,作为说明性示例,图形通过创建所述图形、添加节点(例如,子图节点、空节点、事件记录节点、事件等待节点、外部信号量信号节点、外部信号量等待节点、主机执行节点、内核执行节点、内存复制节点、内存设置节点和/或其变体)到所述图形、将依赖关系添加到所述图形和/或其变体的一个或更多个api函数而被创建。在至少一个实施例中,通过任何合适的api函数对图形执行各种操作,例如添加节点、移除节点、复制图形、删除图形和/或其变体。在至少一个实施例中,使用任何合适的api函数、软件库和/或其变体以任何合适的方式修改或以其他方式管理图形。
51.在至少一个实施例中,所述图形是使用一个或更多个数据结构和/或数据对象来实现的,例如一个或更多个数组、列表和/或其他合适的数据结构。在至少一个实施例中,所述图形被实现为图形数据对象,也称为图形代码,其对操作和所述操作之间的依赖关系进行编码。在至少一个实施例中,本文描述的技术提供将所述图形输出或以其他方式表示为一个或更多个计算机文件和/或表示的能力,所述计算机文件和/或表示包括所述图形的详细视图、图形拓扑、节点几何、属性配置、参数值和/或其变体。
52.在至少一个实施例中,一个或更多个系统,例如一个或更多个编程模型的系统,例如cuda、hip、oneapi和/或其变体,执行本文描述的各种操作和/或技术。在至少一个实施例
中,一个或更多个系统提供一种或更多种功能以将所述图形转换为一种或更多种表示,其中所述一种或更多种表示可以为用户提供有效识别各种图形配置问题、缺陷或其他潜在问题的能力。在至少一个实施例中,一个或更多个系统提供处理所述图形以生成所述图形的表示——也称为描述性表示、输出表示、输出数据、文件表示和/或其变体——的功能,例如图形描述语言(dot)图形或其他合适的表示形式,例如xdot、便携式网络图形(png)、联合图像专家组(jpeg)、jpeg2000、图形交换格式(gif)、便携式文档格式(pdf)、位图(bmp)、硅图形图像(sgi)、javascript对象表示法(json)、xml、yaml、postscript(ps)、封装的postscript(eps)、可缩放矢量图形(svg)、canon、核心图形图像(cgimage)、纯文本、openexr、fig、gd/gd2格式、图标图像文件格式、pict、pic、truevision高级光栅图形适配器(targa)、标记图像文件格式、tk图形、矢量标记语言、无线位图格式、webp格式和/或对与所述图形相关联的信息进行编码对任何合适的表示。
53.在至少一个实施例中,dot是一种图形描述语言,它可以描述图形,例如无向图形、有向图形,以及图形、节点和边的属性。在至少一个实施例中,属性包括诸如颜色、形状、线条样式和/或其他信息的方面。在至少一个实施例中,一个或更多个系统利用使用户能够指定所述图形并将所述图形转换为dot文件表示或本文所述的其他表示的一种或更多种功能。在至少一个实施例中,所述dot文件表示将所述图形的节点表示为不同的形状,其可以被称为基于多边形或形状的节点。在至少一个实施例中,所述dot文件表示将所述图形的节点表示为记录条目,其可以被称为基于记录的节点。在至少一个实施例中,所述dot文件表示将所述图形的节点表示为字符串,其可以基于诸如超文本标记语言(html)的语言。
54.在至少一个实施例中,一个或更多个系统利用一个或更多个api函数。在至少一个实施例中,一个或更多个api函数包括被称为图形调试点打印api函数的驱动程序api函数,其可以表示为“graphdebugdotprint”、“cugraphdebugdotprint”或任何合适的符号,其可以取决于编程模型(例如,cuda、hip、oneapi和/或其变体)。在至少一个实施例中,所述图形调试点打印api函数由“curesult cugraphdebugdotprint(cugraph hgraph,const char*path,unsigned int flags)”或任何合适的符号表示,其可以取决于编程模型(例如,cuda、hip、oneapi和/或其变体),其中“curesult”表示将由所述图形调试点打印api函数返回的数据类型,其指示所述图形调试点打印api函数的状态(例如,错误代码、成功代码和/或其变体),“cugraphdebugdotprint”表示函数标识符或名称,“cugraph hgraph”表示所述图形,“const char*path”表示表示的位置(例如,输出dot文件,或其他合适的表示),并且“unsigned int flags”表示一个或更多个标志的值。在至少一个实施例中,标志是指作为用于确定函数或过程(例如,api函数)的一个或更多个特征的所述函数或过程的信号的值。在至少一个实施例中,当标志的值被设置为1时启用所述标志,并且当所述标志的值被设置为0时禁用所述标志。在至少一个实施例中,利用所述图形调试点打印api函数以将所述图形输出为至少部分地基于使用所述图形调试点打印api函数指示的标志而配置的表示(例如,dot文件或其他合适的表示)。
55.在至少一个实施例中,用于所述图形调试点打印api函数的标志包括以下标志,尽管可以利用其任何变体:
[0056]“cu_graph_debug_dot_flags_verbose”,其是一个标志,当被启用时,输出所有调试数据就像每个标志被启用一样;
[0057]“cu_graph_debug_dot_flags_runtime_types”,其是当被启用时为输出数据使用一个或更多个运行时结构的标志;
[0058]“cu_graph_debug_dot_flags_kernel_node_params”,其是启用时将内核节点参数信息添加到输出数据的标志;
[0059]“cu_graph_debug_dot_flags_memcpy_node_params”,其是当启用时将内存复制节点参数信息添加到输出数据的标志;
[0060]“cu_graph_debug_dot_flags_memset_node_params”,其是当启用时将内存设置节点参数信息添加到输出数据的标志;
[0061]“cu_graph_debug_dot_flags_host_node_params”,其是当启用时将主机节点参数信息添加到输出数据的标志;
[0062]“cu_graph_debug_dot_flags_event_node_params”,其是当启用时将记录和等待节点信息(例如,句柄)添加到输出数据的标志;“cu_graph_debug_dot_flags_ext_semas_signal_node_pa rams”,其是当启用时将外部信号量信号节点参数信息添加到输出数据的标志;
[0063]“cu_graph_debug_dot_flags_ext_semas_wait_node_par ams”,其是当启用时将外部信号量等待节点参数信息添加到输出数据的标志,
[0064]“cu_graph_debug_dot_flags_kernel_node_attributes”,其是当启用时将内核节点属性值信息添加到输出数据的标志;
[0065]“cu_graph_debug_dot_flags_handles”,其是当启用时将节点句柄和内核函数句柄信息添加到输出数据的标志;
[0066]“cu_graph_debug_dot_flags_mem_alloc_node_params”,其是当启用时将内存分配节点参数添加到输出数据的标志;以及“cu_graph_debug_dot_flags_mem_free_node_params”,其是当启用时将空闲内存(例如,解除分配)节点参数添加到输出数据的标志。在至少一个实施例中,用于所述图形调试点打印api函数的标志包括一个或更多个标志,用于指示输出数据的表示类型,例如dot或其他合适的表示。
[0067]
在至少一个实施例中,一个或更多个api函数包括称为所述图形调试点打印api函数的运行时api函数,其可以表示为“graphdebugdotprint”、“cudagraphdebugdotprint”或任何合适的符号,其可以依赖于编程模型(例如,cuda、hip、oneapi和/或其变体)。在至少一个实施例中,所述图形调试点打印api函数由:“__host__cudaerror_t
[0068]
cudagraphdebugdotprint(cudagraph_t graph,const char*path,unsigned int flags)”或任何合适的符号表示,其可以依赖于编程模型(例如,cuda、hip、oneapi和/或其变体),其中“__host__”表示主机(例如,主机处理器,如cpu),“cudaerror_t”表示将由所述图形调试点打印api函数返回的数据类型,指示所述图形调试点打印api函数的状态(例如,错误代码、成功代码和/或其变体),“cudagraphdebugdotprint”表示函数标识符或名称,“cudagraph_t graph”表示所述图形,“const char*path”表示表示(例如,输出dot文件或其他文件表示)的位置,“unsigned int flags”表示一个或更多个标志的值。在至少一个实施例中,所述图形调试点打印api函数用于将所述图形输出为至少部分地基于使用所述图形调试点打印api函数指示的标志而配置的表示(例如,dot文件或其他合适的表示)。
[0069]
在至少一个实施例中,用于所述图形调试点打印api函数的标志包括以下标志,尽
管可以利用其任何变体:
[0070]“cudagraphdebugdotflagsverbose”,其是一个标志,其在启用时输出所有调试数据,好像每个标志都启用一样;
[0071]“cudagraphdebugdotflagskernelnodeparams”,其是当启用时,将内核节点参数信息添加到输出数据的标志;
[0072]“cudagraphdebugdotflagsmemcpynodeparams”,其是当启用时将内存复制节点参数信息添加到输出数据的标志;
[0073]“cudagraphdebugdotflagsmemsetnodeparams”,其是启用时将内存设置节点参数信息添加到输出数据的标志;
[0074]“cudagraphdebugdotflagshostnodeparams”,其是启用时将主机节点参数信息添加到输出数据的标志;
[0075]“cudagraphdebugdotflagseventnodeparams”,其是当启用时将记录和等待节点信息(例如,句柄)添加到输出数据的标志;
[0076]“cudagraphdebugdotflagsextsemassignalnodeparams”,其是当启用时将外部信号量信号节点参数信息添加到输出数据的标志;
[0077]“cudagraphdebugdotflagsextsemaswaitnodepa rams”,其是当启用时将外部信号量等待节点参数信息添加到输出数据的标志;
[0078]“cudagraphdebugdotflagskernelnodeattributes”,其是当启用时将内核节点属性值信息添加到输出数据的标志;以及“cudagraphdebugdotflagshandles”,其是启用时添加节点句柄和内核函数处理信息到输出数据的标志。在至少一个实施例中,用于所述图形调试点打印api函数的标志包括一个或更多个标志,用于指示输出数据的表示类型,例如dot或其他合适的表示。
[0079]
应当注意,api函数可以使用任何合适的术语以任何合适的方式来表示,这可能与或可能不与所述api函数的一个或更多个功能相关。另外,应当注意,虽然本文描述的示例实施例可能涉及cuda编程模型,但是本文描述的技术可以与任何合适的编程模型和/或任何合适的编程模型的任何合适的api一起使用。
[0080]
在至少一个实施例中,一个或更多个实体,例如用户,通过一个或更多个api调用利用一个或更多个api函数。在至少一个实施例中,一个或更多个实体的一个或更多个api调用指定一个或更多个图形、表示的位置(例如,dot文件或其他合适的表示)和/或标志。在至少一个实施例中,一个或更多个系统响应于基于所述图形调试点打印api函数的api调用,写入标头(例如,dot标头,或其他合适的表示标头),迭代所述api调用指示的所述图形的节点,基于由所述api调用指示的标志而将节点信息写入表示(例如,dot文件或其他合适的表示),迭代通过所述图形的边,将图形拓扑和/或边信息写到所述表示和/或写入页脚(例如,dot页脚或其他合适的表示页脚)。在至少一个实施例中,一个或更多个系统解析所述图形以确定编码所述图形的各种信息的所述表示。在至少一个实施例中,所述表示(例如,dot文件或其他合适的表示)包括诸如节点的拓扑、节点类型、节点句柄、节点属性、节点参数和/或由标志指定的附加节点信息之类的信息。在至少一个实施例中,所述表示(例如,dot文件或其他合适的表示)可与一个或更多个调试软件一起使用,该调试软件可以执行分析以确定由所述表示指示的操作的潜在问题。在至少一个实施例中,所述表示可与各种库
一起使用以显示或以其他方式查看图形细节(例如,用于调试),例如gimp toolkit(gtk)库、xlib库、x11库和/或其变体。
[0081]
图1示出了根据至少一个实施例的描述性表示的示例100。在至少一个实施例中,一个或更多个系统处理所述图形(例如,通过执行所述图形调试点打印api)或其他合适的数据结构或数据对象,以生成所述描述性表示。在至少一个实施例中,所述描述性表示是dot文件或其他合适的表示。在至少一个实施例中,图1是所述图形的所述描述性表示的可视化,其中所述描述性表示是包括以下代码的dot文件,尽管代码可以是其任何变体:
[0082]“digraph dot{subgraph cluster_1{label="graph_1"graph[style="dashed"];"graph_1_node_8"[style="solid"shape="rectangle"label="8ext_semas_wait"];
[0083]
"graph_1_node_7"[style="solid"shape="rectangle"label="7ext_semas_signal"];
[0084]
"graph_1_node_5"[style="solid"shape="rectangle"label="5event_record"];
[0085]
"graph_1_node_4"[style="solid"shape="rectangle"label="4graph_3"];"graph_1_node_3"[style="solid"shape="rectangle"label="3
[0086]
host"];"graph_1_node_2"[style="solid"shape="invtrapezium"label="2memset(85,512)"];
[0087]
"graph_1_node_1"[style="solid"shape="trapezium"label="1memcpy(htod,1)"];
[0088]
"graph_1_node_0"[style="bold"shape="octagon"label="0empty_kernel"];"graph_1_node_6"[style="solid"shape="rectangle"label="6event_wait"];
[0089]
"graph_1_node_5"-》"graph_1_node_6";}
[0090]
subgraph cluster_3{label="graph_3"graph[style="dashed"];"graph_3_node_0"[style="solid"shape="rectangle"label="0empty"];}}”其中所述描述性表示是由一个或更多个系统基于指示没有启
[0091]
用标志的api调用生成的。
[0092]
图2示出了根据至少一个实施例的描述性表示的另一示例200。在至少一个实施例中,一个或更多个系统处理所述图形(例如,通过执行所述图形调试点打印api)或其他合适的数据结构或数据对象,以生成所述描述性表示。在至少一个实施例中,所述描述性表示是dot文件或其他合适的表示。在至少一个实施例中,图2是所述图形的所述描述性表示的可视化,其中所述描述性表示是包括以下代码的dot文件,尽管代码可以是其任何变体:
[0093]“digraph dot{subgraph cluster_1{label="graph_1"graph[style="dashed"];"graph_1_node_7"[style="solid"shape="record"label="{ext_semas_wait|{{id|numextsems}|{7|5}}|{{extsemarray[0]|extsemarray[1]|extsemarray[2]|extsemarray[3]|extsemarray[4]}|{0xcccccccccccccccc|0xcccccccccccccccc|0xcccccccccccccccc|0xcccccccccccccccc|0xcccccccccccccccc}}|{{paramsarray[0]|paramsarray[1]|paramsarray[2]|paramsarray[3]|paramsarray[4]}|{value|fence|key
|timeoutms|flags|value|fence|key|timeoutms|flags|value|fence|key|timeoutms|flags|value|fence|key|timeoutms|flags|value|fence|key|timeoutms|flags}|{0|0x0000000000000000|0|0|0|1|0x0000000000000000|1|1|1|2|0x0000000000000000|2|2|2|3|0x0000000000000000|3|3|3|4|0x0000000000000000|4|4|4}}}"];
[0094]
"graph_1_node_6"[style="solid"shape="rectangle"label="6ext_semas_signal"];
[0095]
"graph_1_node_4"[style="solid"shape="rectangle"label="4event_record"];
[0096]
"graph_1_node_3"[style="solid"shape="rectangle"label="3graph_3"];"graph_1_node_2"[style="solid"shape="invtrapezium"label="2memset(85,512)"];
[0097]
"graph_1_node_1"[style="solid"shape="record"label="{memcpy|{{id}|{1}}|{kind|htod(host pageable to device)}|{{srcptr|dstptr}|{pitch|ptr|xsize|ysize|pitch|ptr|xsize|ysize}|{0|0x0000001e4f0fe914|0|0|0|0x0000000701a00000|0|0}}|{{srcpos|{{x|0}|{y|0}|{z|0}}}|{dstpos|{{x|0}|{y|0}|{z|0}}}|{extent|{{width|1}|{height|1}|{depth|1}}}}}"];
[0098]
"graph_1_node_0"[style="bold"shape="octagon"label="0empty_kernel"];
[0099]
"graph_1_node_5"[style="solid"shape="rectangle"label="5event_wait"];
[0100]
"graph_1_node_4"-》"graph_1_node_5";}
[0101]
subgraph cluster_3{label="graph_3"graph[style="dashed"];
[0102]
"graph_3_node_0"[style="solid"shape="rectangle"label="0empty"];}}”[0103]
其中所述描述表示是由一个或更多个系统基于api调用生成的,该
[0104]
api调用至少指示“cudagraphdebugdotflagsmemcpynodeparams”[0105]
标志和“cudagraphdebugdotflagsextsemaswaitnodeparams”标志。
[0106]
图3示出了根据至少一个实施例的描述性表示的另一示例300。在至少一个实施例中,一个或更多个系统处理所述图形(例如,通过执行所述图形调试点打印api)或其他合适的数据结构或数据对象,以生成所述描述性表示。在至少一个实施例中,所述描述性表示是dot文件或其他合适的表示。在至少一个实施例中,图3是所述图形的所述描述性表示的可视化,其中所述描述性表示是包括以下代码的dot文件,尽管代码可以是其任何变体:
[0107]“digraph dot{subgraph cluster_1{label="graph_1"graph[style="dashed"];"graph_1_node_1"[style="bold"shape="record"label="{kernel|{id|1|empty_kernel\《\《\《1,1,0\》\》\》}|{{node handle|func handle}|{0x0000000000000000|0x0000000000000000}}|{accesspolicywindow|{base_ptr|num_bytes|hitratio|hitprop|missprop}|{0x0000000000000000|0|0.000000|n|n}}|{cooperative|0}}"];
[0108]
"graph_1_node_0"[style="bold"shape="record"label="{kernel|{id|0|empty_kernel\《\《\《1,1,0\》\》\》}|{{node handle|func handle}|{0x0000000000000000|0x0000000000000000}}|{accesspolicywindow|{base_ptr|num_bytes|hitratio|hitprop|missprop}|{0x0000000000000000|0|0.000000|n|n}}|{cooperative|0}}"];"
graph_1_node_2"[style="bold"shape="record"label="{kernel|{id|2|empty_kernel\《\《\《1,1,0\》\》\》}|{{node handle|func handle}|{0x0000000000000000|0x0000000000000000}}|{accesspolicywindow|{base_ptr|num_bytes|hitratio|hitprop|missprop}|{0x0000000000000000|0|0.000000|n|n}}|{cooperative|0}}"];
[0109]
"graph_1_node_3"[style="bold"shape="record"label="{kernel|{id|3|empty_kernel\《\《\《1,1,0\》\》\》}|{{node handle|func handle}|{0x0000000000000000|0x0000000000000000}}|{accesspolicywindow|{base_ptr|num_bytes|hitratio|hitprop|missprop}|{0x0000000000000000|0|0.000000|n|n}}|{cooperative|0}}"];
[0110]
"graph_1_node_4"[style="bold"shape="record"label="{kernel|{id|4|empty_kernel\《\《\《1,1,0\》\》\》}|{{node handle|func handle}|{0x0000000000000000|0x0000000000000000}}|{accesspolicywindow|{base_ptr|num_bytes|hitratio|hitprop|missprop}|{0x0000000000000000|0|0.000000|n|n}}|{cooperative|0}}"];
[0111]
"graph_1_node_5"[style="bold"shape="record"label="{kernel|{id|5|empty_kernel\《\《\《1,1,0\》\》\》}|{{node handle|func handle}|{0x0000000000000000|0x0000000000000000}}|{accesspolicywindow|{base_ptr|num_bytes|hitratio|hitprop|missprop}|{0x0000000000000000|0|0.000000|n|n}}|{cooperative|0}}"];
[0112]
"graph_1_node_6"[style="bold"shape="record"label="{kernel|{id|6|empty_kernel\《\《\《1,1,0\》\》\》}|{{node handle|func handle}|{0x0000000000000000|0x0000000000000000}}|{accesspolicywindow|{base_ptr|num_bytes|hitratio|hitprop|missprop}|{0x0000000000000000|0|0.000000|n|n}}|{cooperative|0}}"];
[0113]
"graph_1_node_1"-》"graph_1_node_2";"graph_1_node_0"-》"graph_1_node_2";
[0114]
"graph_1_node_2"-》"graph_1_node_3";"graph_1_node_2"-》"graph_1_node_4";
[0115]
"graph_1_node_2"-》"graph_1_node_5";"graph_1_node_3"-》"graph_1_node_6";
[0116]
"graph_1_node_4"-》"graph_1_node_6";"graph_1_node_5"-》"graph_1_node_6";}}”其中所述描述性表示是由一个或更多个系统基于至少指示“cu_graph_debug_dot_flags_verbose”标志的api调用而生成的。
[0117]
图4示出了根据至少一个实施例的描述性表示的另一示例400。在至少一个实施例中,一个或更多个系统处理所述图形(例如,通过执行所述图形调试点打印api)或其他合适的数据结构或数据对象,以生成所述描述性表示。在至少一个实施例中,所述描述性表示是dot文件或其他合适的表示。在至少一个实施例中,图4是所述图形的所述描述性表示的可视化,其中所述描述性表示是包括以下代码的dot文件,尽管代码可以是其任何变体:
[0118]“digraph dot{subgraph cluster_1{label="graph_1"graph[style="dashed"];"graph_1_node_10"[style="solid"shape="record"label="{memcpy|{{id|node handle}|{2|0x0000000000000000}}|{{src|dst}|{memorytype|array|host|device|xinbytes|y|z|pitch|height|lod|memorytype|array|host|device|xinbytes|y|z|pitch|height|lod}|{unified(device)|0x0000000000000000|0x0000000000000000|
0x0000000000000000|0|0|0|0|0|0|array(device)|0x0000000000000000|0x0000000000000000|0x0000000000000000|0|0|0|0|0|0}}|{extent|{widthinbytes|height|depth}|{1|1|1}}}"];
[0119]
"graph_1_node_3"[style="solid"shape="record"label="{memcpy|{{id|node handle}|{1|0x0000000000000000}}|{{src|dst}|{memorytype|array|host|device|xinbytes|y|z|pitch|height|lod|memorytype|array|host|device|xinbytes|y|z|pitch|height|lod}|{device(device)|0x0000000000000000|0x0000000000000000|0x0000000000000000|0|0|0|0|0|0|host(host pageable)|0x0000000000000000|0x0000000000000000|0x0000000000000000|0|0|0|0|0|0}}|{extent|{widthinbytes|height|depth}|{1|1|1}}}"];
[0120]
"graph_1_node_2"[style="solid"shape="record"label="{memcpy|{{id|node handle}|{0|0x0000000000000000}}|{{src|dst}|{memorytype|array|host|device|xinbytes|y|z|pitch|height|lod|memorytype|array|host|device|xinbytes|y|z|pitch|height|lod}|{host(host pageable)|0x0000000000000000|0x0000000000000000|0x0000000000000000|0|0|0|0|0|0|array(device)|0x0000000000000000|0x0000000000000000|0x0000000000000000|0|0|0|0|0|0}}|{extent|{widthinbytes|height|depth}|{1|1|1}}}"];}}”其中所述描述性表示是由一个或更多个系统基于至少指示
[0121]“cu_graph_debug_dot_flags_verbose”标志的api调用生成的。
[0122]
应当注意,虽然本文描述的示例实施例可以涉及所述cuda编程模型的图形,但本文描述的技术可以与任何合适的编程模型的图形一起使用,例如hip、oneapi和/或其变体。此外,应当注意,虽然本文描述的示例实施例可以涉及图形,但是本文描述的技术可以与任何合适的编程模型的任何合适的数据对象或数据结构一起使用,所述编程模型编码或以其他方式存储指示操作和/或所述操作间依赖关系的信息。例如,在至少一个实施例中,所述描述性表示(例如,dot文件或其他合适的表示)是从编码或以其他方式存储指示操作和/或所述操作间依赖关系的信息的任何合适的编程模型的任何合适的数据对象或数据结构生成的。
[0123]
图5示出了根据至少一个实施例的所述图形调试点打印api函数的图形表示。在至少一个实施例中,所述图形调试点打印api由任何合适的处理器和/或处理器组合执行,例如一个或更多个cpu、gpu、gpgpu、ppu和/或其变体。在至少一个实施例中,尽管图5示出了可以被包括在所述图形调试点打印api函数调用和响应中的特定信息集合,但变体也在本公开的范围内并且所述图形调试点打印api函数调用和响应可以具有更少或更多的信息组件,其可以以任何合适的方式表示。在至少一个实施例中,并非所有使用相同api函数进行的api调用都包括相同的信息组件。在至少一个实施例中,作为说明性示例,一个参数的重要信息的类型和/或存在可以取决于另一参数的值。在至少一个实施例中,响应的组件的重要信息的类型和/或存在取决于另一参数的值和/或触发所述响应的api调用的参数。
[0124]
在至少一个实施例中,所述图形调试点打印api函数,例如本文描述的那些,是驱动程序api或运行时api。在至少一个实施例中,驱动程序api是低级api,其可以参考编程模型(例如,cuda驱动程序api)来引用。在至少一个实施例中,驱动程序api直接与一个或更多
个设备交互。在至少一个实施例中,运行时api是高级api,其可以参考编程模型(例如,cuda运行时api)来引用。在至少一个实施例中,运行时api使用驱动程序api进行操作。关于驱动程序api和运行时api的进一步信息可以在图27的描述中找到。
[0125]
在至少一个实施例中,api调用,例如本文描述的那些,被作为代码执行的一部分进行,该代码至少指示对应于所述api调用的api函数。在至少一个实施例中,作为说明性示例,一个或更多个系统进行api调用并获得响应,作为与一个或更多个编程模型(例如cuda、hip、oneapi和/或其中变体)相关的代码执行的一部分。
[0126]
图5示出了根据至少一个实施例的图形调试点打印api调用的图500。在至少一个实施例中,所述图形调试点打印api被表示为cudagraphdebugdotprint、graphdebugdotprint和/或任何合适的符号,其可以参考编程模型(例如,cuda、hip、oneapi和/或其变体)。在至少一个实施例中,所述图形调试点打印api与结合图1-4和图6和本文其他地方描述的那些一致。在至少一个实施例中,所述图形调试点打印api使一个或更多个编程模型(例如,cuda、hip、oneapi和/或其变体)的一个或更多个系统来处理所述图形并生成所述图形的所述表示。
[0127]
在至少一个实施例中,用于所述图形调试点打印api调用的参数包括“图形”、“路径”、“标志”,并且可以包括进一步定义所述图形和/或所述表示的方面的其他参数。在至少一个实施例中,参数“图形”指示要从中创建所述表示的所述图形。在至少一个实施例中,参数“路径”指示要写入或以其他方式存储所述表示的路径或其他合适的位置。在至少一个实施例中,参数“标志”指示一个或更多个标志,其指的是作为确定函数或过程(例如,api函数)的一个或更多个特征的所述函数或过程的信号的值。在至少一个实施例中,用于所述图形调试点打印api的标志包括一个或更多个标志,例如本文描述的那些。
[0128]
在至少一个实施例中,一个或更多个系统通过至少迭代由所述api调用指示的所述图形的节点,至少部分地基于由所述api调用指示的标志获得所述图形的节点、图形拓扑、边和/或其他合适的信息,以及生成在由所述api调用指示的所述路径或其他合适位置中编码所述信息的所述表示(例如,dot文件或其他合适的表示),来执行所述图形调试点打印api。在至少一个实施例中,对所述图形调试点打印api调用的响应包括状态。在至少一个实施例中,响应于所述图形调试点打印api调用而返回所述状态以指示所述图形调试点打印api调用的状态指示。在至少一个实施例中,所述状态指示表明所述图形调试点打印api的一个或更多个操作是成功、失败还是发生了其他错误。
[0129]
图6示出了根据至少一个实施例的导致图形代码的描述性表示生成的过程600的示例。在至少一个实施例中,过程600(或本文描述的任何其他过程,或其变体和/或组合)中的一些或全部是在配置有计算机可执行指令的一个或更多个计算机系统的控制下执行的并且被实现为由硬件、软件或其组合在一个或更多个处理器上共同执行的代码(例如,计算机可执行指令、一个或更多个计算机程序或一个或更多个应用程序)。在至少一个实施例中,代码以计算机程序的形式存储在计算机可读存储介质上,该计算机程序包括可由一个或更多个处理器执行的多个计算机可读指令。在至少一个实施例中,计算机可读存储介质是非暂时性计算机可读介质。在至少一个实施例中,至少一些可用于执行过程600的计算机可读指令不是仅使用瞬态信号(例如,传播的瞬态电或电磁传输)来存储的。在至少一个实施例中,非暂时性计算机可读介质不一定包括暂时性信号的收发器内的非暂时性数据存储
电路(例如,缓冲器、高速缓存和队列)。
[0130]
在至少一个实施例中,过程600由一个或更多个系统执行,例如在本公开中描述的那些。在至少一个实施例中,过程600由一个或更多个编程模型的系统执行。在至少一个实施例中,过程600的一个或更多个过程以任何合适的顺序被执行,包括顺序、并行和/或其变体,并且使用任何合适的处理单元,例如cpu、gpu、ppu、gpgpu和/或其变体。
[0131]
在至少一个实施例中,执行过程600的至少一部分的所述系统包括用于至少获得602至少指示api以引起图形代码的描述性表示生成的代码的可执行代码。在至少一个实施例中,所述api是例如结合图1-5和本文其他地方所描述的所述图形调试点打印api。在至少一个实施例中,所述api包括诸如结合图5所描述的那些的参数值。在至少一个实施例中,所述api包括至少指示所述图形代码的参数值、所述图形代码的所述描述性表示的路径或位置、以及指示所述描述性表示的一个或更多个特征的多个标志之一(例如,将所述图形代码的哪些数据包括在所述描述性表示中,例如要包括哪些节点参数值)。在至少一个实施例中,所述api包括指示要生成的所述描述性表示的类型或类别的参数值。在至少一个实施例中,所述图形代码指的是所述图形数据对象,或任何合适的编程模型的任何合适的数据对象或数据结构,该编程模型编码或以其他方式存储指示操作和/或所述操作间依赖关系的信息。
[0132]
在至少一个实施例中,执行过程600的至少一部分的所述系统包括用于至少执行604api以引起图形代码的描述性表示被生成的可执行代码。在至少一个实施例中,所述系统执行所述api作为指示所述api的所述代码执行的一部分。在至少一个实施例中,所述系统执行所述api以使得通过至少部分地基于所述图形代码至少生成所述描述性表示来生成所述图形代码的所述描述性表示。在至少一个实施例中,所述系统迭代所述图形代码的节点,至少部分地基于所述一个或更多个标志获得所述图形代码的节点、图形拓扑、边和/或其他合适的信息,并生成在所述路径或位置中编码所述信息的所述描述性表示。在至少一个实施例中,所述系统基于指示要生成的所述描述性表示的类型或类别的所述参数值来生成所述描述性表示。在至少一个实施例中,所述系统基于所述图形代码生成一组描述性表示,其中所述组的特征可以通过所述api的参数值(例如,表示的类型、表示的数量)来指示。
[0133]
在至少一个实施例中,所述描述性表示是对所述信息进行编码的任何合适的表示,例如文本表示、图像表示、特定编程语言的代码表示、视频表示和/或其变体,它们可以通过一个或更多计算机文件来表示,例如对应于dot图、xdot、png、jpeg、jpeg2000、gif、pdf、bmp、sgi、json、xml、yaml、ps、eps、svg、canon、cgimage、纯文本、openexr、fig、gd/gd2格式、图标图像文件格式、pict、pic、targa、标签图像文件格式、tk图形、矢量标记语言、无线位图格式、webp格式和/或编码与所述图形代码相关联的信息的任何合适的表示的那些。
[0134]
在以上和以下的描述中,阐述了许多具体细节以便提供对至少一个实施例的更透彻理解。然而,对于本领域技术人员将显而易见的是,可以在没有这些具体细节中的一个或更多个的情况下实践本发明构思。
[0135]
数据中心
[0136]
图7示出了根据至少一个实施例的示例数据中心700。在至少一个实施例中,数据中心700包括但不限于数据中心基础设施层710、框架层720、软件层730和应用层740。
[0137]
在至少一个实施例中,如图7所示,数据中心基础设施层710可以包括资源协调器
712、分组的计算资源714和节点计算资源(“节点c.r.”)716(1)-716(n),其中“n”代表任何完整的正整数。在至少一个实施例中,节点c.r.716(1)-716(n)可以包括但不限于任意数量的中央处理单元(“cpu”)或其他处理器(包括加速器、现场可编程门阵列(“fpga”)、网络设备中的数据处理单元(dpu)、图形处理器等),存储器设备(例如动态只读存储器),存储设备(例如固态硬盘或磁盘驱动器),网络输入/输出(“nw i/o”)设备,网络交换机,虚拟机(“vm”),电源模块和冷却模块等。在至少一个实施例中,节点c.r.716(1)-716(n)中的一个或更多个节点c.r.可以是具有一个或更多个上述计算资源的服务器。
[0138]
在至少一个实施例中,分组的计算资源714可以包括容纳在一个或更多个机架内的节点c.r.的单独分组(未示出),或者容纳在各个地理位置的数据中心内的许多机架(也未示出)。分组的计算资源714内的节点c.r.的单独分组可以包括可以被配置或分配为支持一个或更多个工作负载的分组的计算、网络、内存或存储资源。在至少一个实施例中,可以将包括cpu或处理器的几个节点c.r.分组在一个或更多个机架内,以提供计算资源来支持一个或更多个工作负载。在至少一个实施例中,一个或更多个机架还可以包括任意数量的电源模块、冷却模块和网络交换机,以任意组合。
[0139]
在至少一个实施例中,资源协调器712可以配置或以其他方式控制一个或更多个节点c.r.716(1)-716(n)和/或分组的计算资源714。在至少一个实施例中,资源协调器712可以包括用于数据中心700的软件设计基础结构(“sdi”)管理实体。在至少一个实施例中,资源协调器712可以包括硬件、软件或其某种组合。
[0140]
在至少一个实施例中,如图7所示,框架层720包括但不限于作业调度器732、配置管理器734、资源管理器736和分布式文件系统738。在至少一个实施例中,框架层720可以包括支持软件层730的软件752和/或应用程序层740的一个或更多个应用程序742的框架。在至少一个实施例中,软件752或应用程序742可以分别包括基于web的服务软件或应用程序,例如由amazon web services,google cloud和microsoft azure提供的服务或应用程序。在至少一个实施例中,框架层720可以是但不限于一种免费和开放源软件网络应用框架,例如可以利用分布式文件系统738来进行大范围数据处理(例如“大数据”)的apache spark
tm
(以下称为“spark”)。在至少一个实施例中,作业调度器732可以包括spark驱动器,以促进对数据中心700的各个层所支持的工作负载进行调度。在至少一个实施例中,配置管理器734可以能够配置不同的层,例如软件层730和包括spark和用于支持大规模数据处理的分布式文件系统738的框架层720。在至少一个实施例中,资源管理器736能够管理映射到或分配用于支持分布式文件系统738和作业调度器732的集群或分组计算资源。在至少一个实施例中,集群或分组计算资源可以包括数据中心基础设施层710上的分组的计算资源714。在至少一个实施例中,资源管理器736可以与资源协调器712协调以管理这些映射的或分配的计算资源。
[0141]
在至少一个实施例中,包括在软件层730中的软件752可以包括由节点c.r.716(1)-716(n)的至少一部分,分组计算资源714和/或框架层720的分布式文件系统738使用的软件。一种或更多种类型的软件可以包括但不限于internet网页搜索软件、电子邮件病毒扫描软件、数据库软件和流视频内容软件。
[0142]
在至少一个实施例中,应用层740中包括的一个或更多个应用程序742可以包括由节点c.r.716(1)-716(n)的至少一部分、分组的计算资源714和/或框架层720的分布式文件
系统738使用的一种或更多种类型的应用程序。一种或更多种类型的应用程序可以包括但不限于cuda应用程序。
[0143]
在至少一个实施例中,配置管理器734、资源管理器736和资源协调器712中的任何一个可以基于以任何技术上可行的方式获取的任意数量和类型的数据来实现任意数量和类型的自我修改动作。在至少一个实施例中,自我修改动作可以减轻数据中心700的数据中心操作员做出可能不好的配置决定并且可以避免数据中心的未充分利用和/或执行差的部分。
[0144]
在至少一个实施例中,利用图7中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图7中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0145]
基于计算机的系统
[0146]
以下各图提出但不限于可用于实现至少一个实施例的示例性的基于计算机的系统。
[0147]
图8示出了根据至少一个实施例的处理系统800。在至少一个实施例中,系统800包括一个或更多个处理器802和一个或更多个图形处理器808,并且可以是单处理器台式机系统、多处理器工作站系统或具有大量处理器802或处理器核心807的服务器系统。在至少一个实施例中,处理系统800是结合在片上系统(soc)集成电路内的处理平台,以用于移动、手持或嵌入式设备。
[0148]
在至少一个实施例中,处理系统800可以包括或结合在基于服务器的游戏平台中,包括游戏和媒体控制台的游戏控制台、移动游戏控制台、手持游戏控制台或在线游戏控制台。在至少一个实施例中,处理系统800是移动电话、智能电话、平板计算设备或移动互联网设备。在至少一个实施例中,处理系统800还可包括与可穿戴设备耦合或集成在可穿戴设备中,例如智能手表可穿戴设备、智能眼镜设备、增强现实设备或虚拟现实设备。在至少一个实施例中,处理系统800是电视或机顶盒设备,其具有一个或更多个处理器802以及由一个或更多个图形处理器808生成的图形界面。
[0149]
在至少一个实施例中,一个或更多个处理器802每个包括一个或更多个处理器核心807,以处理指令,该指令在被执行时执行针对系统和用户软件的操作。在至少一个实施例中,一个或更多个处理器核心807中的每一个被配置为处理特定指令集809。在至少一个实施例中,指令集809可以促进复杂指令集计算(cisc)、精简指令集计算(risc),或通过超长指令字(vliw)进行计算。在至少一个实施例中,多个处理器核心807可以各自处理不同的指令集809,该指令集809可以包括有助于仿真其他指令集的指令。在至少一个实施例中,处理器核心807还可以包括其他处理设备,例如数字信号处理器(“dsp”)。
[0150]
在至少一个实施例中,处理器802包括高速缓存存储器(cache)804。在至少一个实施例中,处理器802可以具有单个内部高速缓存或多个级别的内部高速缓存。在至少一个实施例中,高速缓存存储器在处理器802的各个组件之间共享。在至少一个实施例中,处理器802还使用外部高速缓存(例如,三级(l3)高速缓存或最后一级高速缓存(llc))(未示出),其可以使用已知的高速缓存一致性技术在处理器核心807之间共享该逻辑。在至少一个实施例中,处理器802中另外包括寄存器文件806,处理器802可以包括用于存储不同类型的数据的不同类型的寄存器(例如,整数寄存器、浮点寄存器、状态寄存器和指令指针寄存器)。
在至少一个实施例中,寄存器文件806可以包括通用寄存器或其他寄存器。
[0151]
在至少一个实施例中,一个或更多个处理器802与一个或更多个接口总线810耦合,以在处理器802与系统800中的其他组件之间传输通信信号,例如地址、数据或控制信号。在至少一个实施例中,接口总线810在一个实施例中可以是处理器总线,例如直接媒体接口(dmi)总线的版本。在至少一个实施例中,接口总线810不限于dmi总线,并且可以包括一个或更多个外围组件互连总线(例如,pci,pci express)、存储器总线或其他类型的接口总线。在至少一个实施例中,处理器802包括集成存储器控制器816和平台控制器集线器830。在至少一个实施例中,存储器控制器816促进存储设备与处理系统800的其他组件之间的通信,而平台控制器集线器(pch)830通过本地i/o总线提供到输入/输出(i/o)设备的连接。
[0152]
在至少一个实施例中,存储设备820可以是动态随机存取存储器(“dram”)设备、静态随机存取存储器(“sram”)设备、闪存设备、相变存储设备或具有适当的性能以用作处理器存储器。在至少一个实施例中,存储设备820可以用作处理系统800的系统存储器,以存储数据822和指令821,以在一个或更多个处理器802执行应用或过程时使用。在至少一个实施例中,存储器控制器816还与可选的外部图形处理器812耦合,其可以与处理器802中的一个或更多个图形处理器808通信以执行图和媒体操作。在至少一个实施例中,显示设备811可以连接至处理器802。在至少一个实施例中,显示设备811可以包括内部显示设备中的一个或更多个,例如在移动电子设备或便携式计算机设备或通过显示器接口(例如显示端口(displayport)等)连接的外部显示设备。在至少一个实施例中,显示设备811可以包括头戴式显示器(hmd),诸如用于虚拟现实(vr)应用或增强现实(ar)应用中的立体显示设备。
[0153]
在至少一个实施例中,平台控制器集线器830使外围设备能够通过高速i/o总线连接到存储设备820和处理器802。在至少一个实施例中,i/o外围设备包括但不限于音频控制器846、网络控制器834、固件接口828、无线收发器826、触摸传感器825、数据存储设备824(例如,硬盘驱动器、闪存等)。在至少一个实施例中,数据存储设备824可以经由存储器接口(例如,sata)或经由外围总线来连接,诸如外围组件互连总线(例如,pci、pcie)。在至少一个实施例中,触摸传感器825可以包括触摸屏传感器、压力传感器或指纹传感器。在至少一个实施例中,无线收发器826可以是wi-fi收发器、蓝牙收发器或移动网络收发器,诸如3g、4g或长期演进(lte)收发器。在至少一个实施例中,固件接口828使能与系统固件的通信,并且可以是例如统一的可扩展固件接口(uefi)。在至少一个实施例中,网络控制器834可以启用到有线网络的网络连接。在至少一个实施例中,高性能网络控制器(未示出)与接口总线810耦合。在至少一个实施例中,音频控制器846是多通道高清晰度音频控制器。在至少一个实施例中,处理系统800包括可选的传统(legacy)i/o控制器840,用于将遗留(例如,个人系统2(ps/2))设备耦合到处理系统800。在至少一个实施例中,平台控制器集线器830还可以连接到一个或更多个通用串行总线(usb)控制器842,该控制器连接输入设备,诸如键盘和鼠标843组合、相机844或其他usb输入设备。
[0154]
在至少一个实施例中,存储器控制器816和平台控制器集线器830的实例可以集成到离散的外部图形处理器中,例如外部图形处理器812。在至少一个实施例中,平台控制器集线器830和/或存储控制器816可以在一个或更多个处理器802的外部。例如,在至少一个实施例中,处理系统800可以包括外部存储控制器816和平台控制器集线器830,其可以配置
成在与处理器802通信的系统芯片组中的存储器控制器集线器和外围控制器集线器。
[0155]
在至少一个实施例中,利用图8中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图8中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0156]
图9示出了根据至少一个实施例的计算机系统900。在至少一个实施例中,计算机系统900可以是具有互连的设备和组件,soc,或某种组合的系统。在至少一个实施例中,计算机系统900由处理器902形成,该处理器902可以包括用于执行指令的执行单元。在至少一个实施例中,计算机系统900可以包括但不限于组件,例如处理器902,其采用包括逻辑的执行单元以执行用于过程数据的算法。在至少一个实施例中,计算机系统900可以包括处理器,例如可从加利福尼亚圣塔克拉拉的英特尔公司(intel corporation of santa clara,california)获得的处理器家族、xeontm、xscaletm和/或strongarmtm,core
tm
或或nervana
tm
微处理器,尽管也可以使用其他系统(包括具有其他微处理器的pc、工程工作站、机顶盒等)。在至少一个实施例中,计算机系统900可以执行可从华盛顿州雷蒙德市的微软公司(microsoft corporation of redmond,wash.)获得的windows操作系统版本,尽管其他操作系统(例如unix和linux)、嵌入式软件和/或图形用户界面也可以使用。
[0157]
在至少一个实施例中,计算机系统900可以用在其他设备中,例如手持设备和嵌入式应用。手持设备的一些示例包括蜂窝电话、互联网协议(internet protocol)设备、数码相机、个人数字助理(“pda”)和手持pc。在至少一个实施例中,嵌入式应用可以包括微控制器、数字信号处理器(“dsp”)、soc、网络计算机(“netpc”)、机顶盒、网络集线器、广域网(“wan”)交换机,或根据至少一个实施例可以执行一个或更多个指令的任何其他系统。
[0158]
在至少一个实施例中,计算机系统900可包括但不限于处理器902,该处理器902可包括但不限于一个或更多个执行单元908,其可以配置为执行计算统一设备架构(“cuda”)(由加利福尼亚州圣克拉拉的nvidia corporation开发)程序。在至少一个实施例中,cuda程序是用cuda编程语言编写的软件应用程序的至少一部分。在至少一个实施例中,计算机系统900是单处理器台式机或服务器系统。在至少一个实施例中,计算机系统900可以是多处理器系统。在至少一个实施例中,处理器902可以包括但不限于cisc微处理器、risc微处理器、vliw微处理器、实现指令集组合的处理器,或任何其他处理器设备,例如数字信号处理器。在至少一个实施例中,处理器902可以耦合到处理器总线910,该处理器总线910可以在处理器902与计算机系统900中的其他组件之间传输数据信号。
[0159]
在至少一个实施例中,处理器902可以包括但不限于1级(“l1”)内部高速缓存存储器(“cache”)904。在至少一个实施例中,处理器902可以具有单个内部高速缓存或多级内部缓存。在至少一个实施例中,高速缓存存储器可以驻留在处理器902的外部。在至少一个实施例中,处理器902可以包括内部和外部高速缓存的组合。在至少一个实施例中,寄存器文件906可以在各种寄存器中存储不同类型的数据,包括但不限于整数寄存器、浮点寄存器、状态寄存器和指令指针寄存器。
[0160]
在至少一个实施例中,包括但不限于执行整数和浮点运算的逻辑的执行单元908,其也位于处理器902中。处理器902还可以包括微码(“ucode”)只读存储器(“rom”),用于存
储某些宏指令的微代码。在至少一个实施例中,执行单元908可以包括用于处理封装指令集909的逻辑。在至少一个实施例中,通过将封装指令集909包括在通用处理器902的指令集中,以及要执行指令的相关电路,可以使用通用处理器902中的封装数据来执行许多多媒体应用程序使用的操作。在至少一个实施例中,可以通过使用处理器的数据总线的全宽度来在封装的数据上执行操作来加速和更有效地执行许多多媒体应用程序,这可能不需要在处理器的数据总线上传输较小的数据单元来一次对一个数据元素执行一个或更多个操作。
[0161]
在至少一个实施例中,执行单元908也可以用在微控制器、嵌入式处理器、图形设备、dsp和其他类型的逻辑电路中。在至少一个实施例中,计算机系统900可以包括但不限于存储器920。在至少一个实施例中,存储器920可以被实现为dram设备、sram设备、闪存设备或其他存储设备。存储器920可以存储由处理器902可以执行的由数据信号表示的指令919和/或数据921。
[0162]
在至少一个实施例中,系统逻辑芯片可以耦合到处理器总线910和存储器920。在至少一个实施例中,系统逻辑芯片可以包括但不限于存储器控制器集线器(“mch”)916,并且处理器902可以经由处理器总线910与mch 916通信。在至少一个实施例中,mch 916可以提供到存储器920的高带宽存储器路径918以用于指令和数据存储以及用于图形命令、数据和纹理的存储。在至少一个实施例中,mch 916可以在处理器902、存储器920和计算机系统900中的其他组件之间启动数据信号,并且在处理器总线910、存储器920和系统i/o 922之间桥接数据信号。在至少一个实施例中,系统逻辑芯片可以提供用于耦合到图形控制器的图形端口。在至少一个实施例中,mch 916可以通过高带宽存储器路径918耦合到存储器920,并且图形/视频卡912可以通过加速图形端口(accelerated graphics port)(“agp”)互连914耦合到mch 916。
[0163]
在至少一个实施例中,计算机系统900可以使用系统i/o 922作为专有集线器接口总线来将mch 916耦合到i/o控制器集线器(“ich”)930。在至少一个实施例中,ich 930可以通过本地i/o总线提供与某些i/o设备的直接连接。在至少一个实施例中,本地i/o总线可以包括但不限于用于将外围设备连接到存储器920、芯片组和处理器902的高速i/o总线。示例可以包括但不限于音频控制器929、固件集线器(“flash bios”)928、无线收发器926、数据存储924、包含用户输入925的传统i/o控制器923和键盘接口、串行扩展端口927(例如usb)和网络控制器934。数据存储924可以包括硬盘驱动器、软盘驱动器、cd-rom设备、闪存设备或其他大容量存储设备。
[0164]
在至少一个实施例中,图9示出了包括互连的硬件设备或“芯片”的系统。在至少一个实施例中,图9可以示出示例性soc。在至少一个实施例中,图9中示出的设备可以与专有互连、标准化互连(例如,pcie)或其某种组合互连。在至少一个实施例中,系统900的一个或更多个组件使用计算快速链路(“cxl”)互连来互连。
[0165]
在至少一个实施例中,利用图9中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图9中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0166]
图10示出了根据至少一个实施例的系统1000。在至少一个实施例中,系统1000是利用处理器1010的电子设备。在至少一个实施例中,系统1000可以是,例如但不限于,笔记本电脑、塔式服务器、机架服务器、刀片服务器、通信地耦合至一个或更多个本地或云服务
提供商的边缘设备、膝上型计算机、台式机、平板电脑、移动设备、电话、嵌入式计算机或任何其他合适的电子设备。
[0167]
在至少一个实施例中,系统1000可以包括但不限于通信地耦合到任何合适数量或种类的组件、外围设备、模块或设备的处理器1010。在至少一个实施例中,处理器1010使用总线或接口耦合,诸如i2c总线、系统管理总线(“smbus”)、低引脚数(lpc)总线、串行外围接口(“spi”)、高清音频(“hda”)总线、串行高级技术附件(“sata”)总线、usb(1、2、3版)或通用异步接收器/发送器(“uart”)总线。在至少一个实施例中,图10示出了系统,该系统包括互连的硬件设备或“芯片”。在至少一个实施例中,图10可以示出示例性soc。在至少一个实施例中,图10中所示的设备可以与专有互连线、标准化互连(例如,pcie)或其某种组合互连。在至少一个实施例中,图10的一个或更多个组件使用计算快速链路(cxl)互连线来互连。
[0168]
在至少一个实施例中,图10可以包括显示器1024、触摸屏1025、触摸板1030、近场通信单元(“nfc”)1045、传感器集线器1040、热传感器1046、快速芯片组(“ec”)1035、可信平台模块(“tpm”)1038、bios/固件/闪存(“bios,fw flash”)1022、dsp 1060、固态磁盘(“ssd”)或硬盘驱动器(“hdd”)1020、无线局域网单元(“wlan”)1050、蓝牙单元1052、无线广域网单元(“wwan”)1056、全球定位系统(gps)1055、相机(“usb 3.0相机”)1054(例如usb 3.0相机)或以例如lpddr3标准实现的低功耗双倍数据速率(“lpddr”)存储器单元(“lpddr3”)1015。这些组件可以各自以任何合适的方式实现。
[0169]
在至少一个实施例中,其他组件可以通过以上讨论的组件通信地耦合到处理器1010。在至少一个实施例中,加速度计1041、环境光传感器(“als”)1042、罗盘1043和陀螺仪1044可以可通信地耦合到传感器集线器1040。在至少一个实施例中,热传感器1039、风扇1037、键盘1036和触摸板1030可以通信地耦合到ec 1035。在至少一个实施例中,扬声器1063、耳机1064和麦克风(“mic”)1065可以通信地耦合到音频单元(“音频编解码器和d类放大器”)1062,其又可以通信地耦合到dsp 1060。在至少一个实施例中,音频单元1062可以包括例如但不限于音频编码器/解码器(“编解码器”)和d类放大器。在至少一个实施例中,sim卡(“sim”)1057可以通信地耦合到wwan单元1056。在至少一个实施例中,组件(诸如wlan单元1050和蓝牙单元1052以及wwan单元1056)可以被实现为下一代形式因素(ngff)。
[0170]
在至少一个实施例中,利用图10中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图10中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0171]
图11示出了根据至少一个实施例的示例性集成电路1100。在至少一个实施例中,示例性集成电路1100是soc,其可使用一个或更多个ip核心制造。在至少一个实施例中,集成电路1100包括一个或更多个应用处理器1105(例如,cpu、dpu)、至少一个图形处理器1110,并且可以另外包括图像处理器1115和/或视频处理器1120,其中任意一个可能是模块化ip核心。在至少一个实施例中,集成电路1100包括外围或总线逻辑,其包括usb控制器1125、uart控制器1130、spi/sdio控制器1135和i2s/i2c控制器1140。在至少一个实施例中,集成电路1100可以包括显示设备1145耦合到高清多媒体接口(“hdmi”)控制器1150和移动工业处理器接口(“mipi”)显示接口1155中的一个或更多个。在至少一个实施例中,存储可以由闪存子系统1160提供,包括闪存和闪存控制器。在至少一个实施例中,可以经由存储器控制器1165提供存储器接口以用于访问sdram或sram存储器设备。在至少一个实施例中,一
些集成电路还包括嵌入式安全引擎1170。
[0172]
在至少一个实施例中,利用图11中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图11中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0173]
图12示出了根据至少一个实施例的计算系统1200。在至少一个实施例中,计算系统1200包括处理子系统1201,其具有经由可以包括存储器集线器1205的互连路径通信的一个或更多个处理器1202和系统存储器1204。在至少一个实施例中,存储器集线器1205可以是芯片组组件内的单独组件,也可以集成在一个或更多个处理器1202内。在至少一个实施例中,存储器集线器1205通过通信链路1206与i/o子系统1211耦合。在至少一个实施例中,i/o子系统1211包括i/o集线器1207,其可以使计算系统1200能够接收来自一个或更多个输入设备1208的输入。在至少一个实施例中,i/o集线器1207可以使能显示控制器,其包括在一个或更多个处理器1202中,用于向一个或更多个显示设备1210a提供输出。在至少一个实施例中,与i/o集线器1207耦合的一个或更多个显示设备1210a可以包括本地、内部或嵌入式显示设备。
[0174]
在至少一个实施例中,处理子系统1201包括经由总线或其他通信链路1213耦合到存储器集线器1205的一个或更多个并行处理器1212。在至少一个实施例中,通信链路1213可以是许多基于标准的通信链路技术或协议中的一种,例如但不限于pcie,或者可以是针对供应商的通信接口或通信结构。在至少一个实施例中,一个或更多个并行处理器1212形成计算集中的并行或向量处理系统,该系统可以包括大量的处理核心和/或处理集群,例如多集成核心(mic)处理器。在至少一个实施例中,一个或更多个并行处理器1212形成可以将像素输出到经由i/o集线器1207耦合的一个或更多个显示设备1210a之一的图形处理子系统。在至少一个实施例中,一个或更多个并行处理器1212还可以包括显示控制器和显示接口(未示出),以使得能够直接连接到一个或更多个显示设备1210b。
[0175]
在至少一个实施例中,系统存储单元1214可以连接到i/o集线器1207,以提供用于计算系统1200的存储机制。在至少一个实施例中,i/o交换机1216可以用于提供接口机制,以实现i/o集线器1207与其他组件之间的连接,例如可以集成到平台中的网络适配器1218和/或无线网络适配器1219,以及可以通过一个或更多个附加设备1220添加的各种其他设备。在至少一个实施例中,网络适配器1218可以是以太网适配器或另一有线网络适配器。在至少一个实施例中,无线网络适配器1219可以包括wi-fi、蓝牙、nfc的一个或更多个或其他包括一个或更多个无线电的网络设备。
[0176]
在至少一个实施例中,计算系统1200可以包括未明确示出的其他组件,包括usb或其他端口连接、光存储驱动器、视频捕获设备等,也可以连接到i/o集线器1207。在至少一个实施例中,对图12中的各个组件进行互连的通信路径可以使用任何合适的协议来实现,诸如基于pci(外围组件互连)的协议(例如,pcie),或其他总线或点对点通信接口和/或协议(例如,nvlink高速互连或互连协议)。
[0177]
在至少一个实施例中,一个或更多个并行处理器1212包括针对图形和视频处理而优化的电路(包括例如视频输出电路),并构成图形处理单元(gpu)。在至少一个实施例中,一个或更多个并行处理器1212包括针对通用处理而优化的电路。在至少一个实施例中,计算系统1200的组件可以与单个集成电路上的一个或更多个其他系统元件集成。例如,在至
少一个实施例中,一个或更多个并行处理器1212、存储器集线器1205、处理器1202和i/o集线器1207可以被集成到片上系统(soc)集成电路中。在至少一个实施例中,计算系统1200的组件可以被集成到单个封装中以形成系统级封装(sip)配置。在至少一个实施例中,计算系统1200的组件的至少一部分可以被集成到多芯片模块(mcm)中,该多芯片模块可以与其他多芯片模块互连到模块化计算系统中。在至少一个实施例中,从计算系统1200中省略了i/o子系统1211和显示设备1210b。
[0178]
在至少一个实施例中,利用图12中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图12中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0179]
处理系统
[0180]
以下各图阐述了但不限于可用于实现至少一个实施例的示例性处理系统。
[0181]
图13示出了根据至少一个实施例的加速处理单元(“apu”)1300。在至少一个实施例中,apu 1300由加利福尼亚州圣克拉拉市的amd公司开发。在至少一个实施例中,apu 1300可以被配置为执行应用程序,诸如cuda程序。在至少一个实施例中,apu 1300包括但不限于核心复合体1310、图形复合体1340、结构1360、i/o接口1370、存储器控制器1380、显示控制器1392和多媒体引擎1394。在至少一个实施例中,apu 1300可以包括但不限于任意数量的核心复合体1310、任意数量的图形复合体1350、任意数量的显示控制器1392和任意数量的多媒体引擎1394的任何组合。为了说明的目的,在本文中用附图标记表示相似对象的多个实例,其中附图标记标识该对象,并且括号中的数字标识所需要的实例。
[0182]
在至少一个实施例中,核心复合体1310是cpu,图形复合体1340是gpu,并且apu 1300是将不限于核心复合体1310和图形复合体1340集成到单个芯片上的处理单元。在至少一个实施例中,一些任务可以被分配给核心复合体1310,而其他任务可以被分配给图形复合体1340。在至少一个实施例中,核心复合体1310被配置为执行与apu 1300相关联的主控制软件,例如操作系统。在至少一个实施例中,核心复合体1310是apu 1300的主处理器,其控制和协调其他处理器的操作。在至少一个实施例中,核心复合体1310发出控制图形复合体1340的操作的命令。在至少一个实施例中,核心复合体1310可以被配置为执行从cuda源代码派生的主机可执行代码,并且图形复合体1340可以被配置为执行从cuda源代码派生的设备可执行代码。
[0183]
在至少一个实施例中,核心复合体1310包括但不限于核心1320(1)-1320(4)和l3高速缓存1330。在至少一个实施例中,核心复合体1310可以包括但不限于任何组合的任意数量的核心1320以及任意数量和类型的高速缓存。在至少一个实施例中,核心1320被配置为执行特定指令集架构(“isa”)的指令。在至少一个实施例中,每个核心1320是cpu核心。
[0184]
在至少一个实施例中,每个核心1320包括但不限于获取/解码单元1322、整数执行引擎1324、浮点执行引擎1326和l2高速缓存1328。在至少一个实施例中,获取/解码单元1322获取指令,对这些指令进行解码,生成微操作,并将单独的微指令分派给整数执行引擎1324和浮点执行引擎1326。在至少一个实施例中,获取/解码单元1322可以同时分派一个微指令到整数执行引擎1324和另一微指令到浮点执行引擎1326。在至少一个实施例中,整数执行引擎1324执行不限于整数和存储器操作。在至少一个实施例中,浮点引擎1326执行不限于浮点和向量运算。在至少一个实施例中,获取-解码单元1322将微指令分派给单个执行
引擎,该执行引擎代替整数执行引擎1324和浮点执行引擎1326两者。
[0185]
在至少一个实施例中,每个核心1320(i)可以访问在核心1320(i)中包括的l2高速缓存1328(i),其中i是表示核心1320的特定实例的整数。在至少一个实施例中,在核心复合体1310(j)中包括的每个核心1320经由在核心复合体1310(j)中包括的l3高速缓存1330(j)连接到在核心复合体1310(j)中包括的其他核心1320,其中j是表示核心复合体1310的特定实例的整数。在至少一个实施例中,在核心复合体1310(j)中包括的核心1320可以访问在核心复合体1310(j)中包括的所有l3高速缓存1330(j),其中j是表示核心复合体1310的特定实例的整数。在至少一个实施例中,l3高速缓存1330可以包括但不限于任意数量的切片(slice)。
[0186]
在至少一个实施例中,图形复合体1340可以被配置为以高度并行的方式执行计算操作。在至少一个实施例中,图形复合体1340被配置为执行图形管线操作,诸如绘制命令、像素操作、几何计算以及与将图像渲染至显示器相关联的其他操作。在至少一个实施例中,图形复合体1340被配置为执行与图形无关的操作。在至少一个实施例中,图形复合体1340被配置为执行与图形有关的操作和与图形无关的操作。
[0187]
在至少一个实施例中,图形复合体1340包括但不限于任意数量的计算单元1350和l2高速缓存1342。在至少一个实施例中,计算单元1350共享l2高速缓存1342。在至少一个实施例中,l2高速缓存1342被分区。在至少一个实施例中,图形复合体1340包括但不限于任意数量的计算单元1350以及任意数量(包括零)和类型的高速缓存。在至少一个实施例中,图形复合体1340包括但不限于任意数量的专用图形硬件。
[0188]
在至少一个实施例中,每个计算单元1350包括但不限于任意数量的simd单元1352和共享存储器1354。在至少一个实施例中,每个simd单元1352实现simd架构并且被配置为并行执行操作。在至少一个实施例中,每个计算单元1350可以执行任意数量的线程块,但是每个线程块在单个计算单元1350上执行。在至少一个实施例中,线程块包括但不限于任意数量的执行线程。在至少一个实施例中,工作组是线程块。在至少一个实施例中,每个simd单元1352执行不同的线程束(warp)。在至少一个实施例中,线程束是一组线程(例如16个线程),其中线程束中的每个线程属于单个线程块,并且被配置为基于单个指令集来处理不同的数据集。在至少一个实施例中,可以使用预测(predication)来禁用线程束中的一个或更多个线程。在至少一个实施例中,通道是线程。在至少一个实施例中,工作项是线程。在至少一个实施例中,波前是线程束。在至少一个实施例中,线程块中的不同波前可一起同步并经由共享存储器1354进行通信。
[0189]
在至少一个实施例中,结构1360是系统互连,其促进跨核心复合体1310、图形复合体1340、i/o接口1370、存储器控制器1380、显示控制器1392和多媒体引擎1394的数据和控制传输。在至少一个实施例中,除了结构1360之外或代替结构1360,apu 1300还可以包括但不限于任意数量和类型的系统互连,其促进跨可以在apu 1300内部或外部的任意数量和类型的直接或间接链接的组件的数据和控制传输。在至少一个实施例中,i/o接口1370表示任意数量和类型的i/o接口(例如,pci、pci-extended(“pci-x”)、pcie、千兆位以太网(“gbe”)、usb等)。在至少一个实施例中,各种类型的外围设备耦合到i/o接口1370。在至少一个实施例中,耦合到i/o接口1370的外围设备可以包括但不限于键盘、鼠标、打印机、扫描仪、操纵杆或其他类型的游戏控制器、媒体记录设备、外部存储设备、网络接口卡等。
[0190]
在至少一个实施例中,显示控制器amd92在一个或更多个显示设备(例如液晶显示器(lcd)设备)上显示图像。在至少一个实施例中,多媒体引擎1394包括但不限于任意数量和类型的与多媒体相关的电路,例如视频解码器、视频编码器、图像信号处理器等。在至少一个实施例中,存储器控制器1380促进apu 1300与统一系统存储器1390之间的数据传输。在至少一个实施例中,核心复合体1310和图形复合体1340共享统一系统存储器1390。
[0191]
在至少一个实施例中,apu 1300实现存储器子系统,其包括但不限于任意数量和类型的存储器控制器1380和可以专用于一个组件或在多个组件之间共享的存储器设备(例如,共享存储器1354)。在至少一个实施例中,apu 1300实现高速缓存子系统,其包括但不限于一个或更多个高速缓存存储器(例如,l2高速缓存1428、l3高速缓存1330和l2高速缓存1342),每个高速缓存存储器可以是私有的或在任意数量的组件(例如,核心1320、核心复合体1310、simd单元1352、计算单元1350和图形复合体1340)之间共享。
[0192]
在至少一个实施例中,利用图13中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图13中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0193]
图14示出了根据至少一个实施例的cpu 1400。在至少一个实施例中,cpu 1400由加利福尼亚州圣克拉拉市的amd公司开发。在至少一个实施例中,cpu 1400可以被配置为执行应用程序。在至少一个实施例中,cpu 1400被配置为执行主控制软件,例如操作系统。在至少一个实施例中,cpu 1400发出控制外部gpu(未示出)的操作的命令。在至少一个实施例中,cpu 1400可以被配置为执行从cuda源代码派生的主机可执行代码,并且外部gpu可以被配置为执行从这种cuda源代码派生的设备可执行代码。在至少一个实施例中,cpu 1400包括但不限于任意数量的核心复合体1410、结构1460、i/o接口1470和存储器控制器1480。
[0194]
在至少一个实施例中,核心复合体1410包括但不限于核心1420(1)-1420(4)和l3高速缓存1430。在至少一个实施例中,核心复合体1410可以包括但不限于任意数量的核心1420以及任意数量和类型的高速缓存的任何组合。在至少一个实施例中,核心1420被配置为执行特定isa的指令。在至少一个实施例中,每个核心1420是cpu核心。
[0195]
在至少一个实施例中,每个核心1420包括但不限于获取/解码单元1422,整数执行引擎1424,浮点执行引擎1426和l2高速缓存1428。在至少一个实施例中,获取/解码单元1422获取指令,对这些指令进行解码,生成微操作,并将单独的微指令分派给整数执行引擎1424和浮点执行引擎1426。在至少一个实施例中,获取/解码单元1422可以同时分派一个微指令到整数执行引擎1424和另一微指令到浮点执行引擎1426。在至少一个实施例中,整数执行引擎1424执行不限于整数和存储器操作。在至少一个实施例中,浮点引擎1426执行不限于浮点和向量运算。在至少一个实施例中,获取-解码单元1422将微指令分派给单个执行引擎,该执行引擎代替整数执行引擎1424和浮点执行引擎1426两者。
[0196]
在至少一个实施例中,每个核心1420(i)可以访问包括在核心1420(i)中的l2高速缓存1428(i),其中i是表示核心1420的特定实例的整数。在至少一个实施例中,包括在核心复合体1410(j)中的每个核心1420经由包括在核心复合体1410(j)中的l3高速缓存1430(j)连接到包括在核心复合体1410(j)中的其他核心1420,其中j是表示核心复合体1410的特定实例的整数。在至少一个实施例中,包括在核心复合体1410(j)中的核心1420可以访问包括在核心复合体1410(j)中的所有l3高速缓存1430(j),其中j是表示核心复合体1410的特定
实例的整数。在至少一个实施例中,l3高速缓存1430可以包括但不限于任意数量的切片。
[0197]
在至少一个实施例中,结构1460是系统互连,其促进跨核心复合体1410(1)-1410(n)(其中n是大于零的整数)、i/o接口1470和存储器控制器1480的数据和控制传输。在至少一个实施例中,除了结构1460之外或代替结构1460,cpu 1400还可以包括但不限于任意数量和类型的系统互连,该结构1460促进跨可以在cpu 1400内部或外部的任意数量和类型的直接或间接链接的组件的数据和控制传输。在至少一个实施例中,i/o接口1470表示任意数量和类型的i/o接口(例如,pci、pci-x、pcie、gbe、usb等)。在至少一个实施例中,各种类型的外围设备耦合到i/o接口1470。在至少一个实施例中,耦合到i/o接口1470的外围设备可以包括但不限于显示器、键盘,鼠标、打印机、扫描仪、操纵杆或其他类型的游戏控制器、媒体记录设备、外部存储设备、网络接口卡等。
[0198]
在至少一个实施例中,存储器控制器1480促进cpu 1400与系统存储器1490之间的数据传输。在至少一个实施例中,核心复合体1410和图形复合体1440共享系统存储器1490。在至少一个实施例中,cpu 1400实现存储器子系统,其包括但不限于任意数量和类型的存储器控制器1480和可以专用于一个组件或在多个组件之间共享的存储器设备。在至少一个实施例中,cpu 1400实现了高速缓存子系统,其包括但不限于一个或更多个高速缓存存储器(例如,l2高速缓存1428和l3高速缓存1430),每个高速缓存存储器可以是组件私有的或在任意数量的组件(例如,核心1420和核心复合体1410)之间共享。
[0199]
在至少一个实施例中,利用图14中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图14中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0200]
图15示出了根据至少一个实施例的示例性加速器集成切片1590。如本文所使用的,“切片”包括加速器集成电路的处理资源的指定部分。在至少一个实施例中,加速器集成电路代表多个图形加速模块种的多个图形处理引擎提供高速缓存管理、存储器访问、环境管理和中断管理服务。图形处理引擎可以各自包括单独的gpu。可选地,图形处理引擎可包括gpu内的不同类型的图形处理引擎,例如图形执行单元、媒体处理引擎(例如,视频编码器/解码器)、采样器和blit引擎。在至少一个实施例中,图形加速模块可以是具有多个图形处理引擎的gpu。在至少一个实施例中,图形处理引擎可以是集成在通用封装、线卡或芯片上的各个gpu。
[0201]
系统存储器1514内的应用程序有效地址空间1582存储进程元素1583。在一个实施例中,响应于来自处理器1507上执行的应用程序1580的gpu调用1581而存储进程元素1583。进程元素1583包含对应应用程序1580的处理状态。包含在进程元素1583中的工作描述符(“wd”)1584可以是应用程序请求的单个作业或可能包含指向作业队列的指针。在至少一个实施例中,wd 1584是指向应用程序有效地址空间1582中的作业请求队列的指针。
[0202]
图形加速模块1546和/或各个图形处理引擎可以由系统中的全部或部分进程共享。在至少一个实施例中,可以包括用于建立处理状态并将wd 1584发送到图形加速模块1546以在虚拟化环境中开始作业的基础设施。
[0203]
在至少一个实施例中,专用进程编程模型是针对实现的。在该模型中,单个进程拥有图形加速模块1546或个体图形处理引擎。由于图形加速模块1546由单个进程拥有,因此管理程序为拥有的分区初始化加速器集成电路,并且当分配图形加速模块1546时操作系统
对加速器集成电路进行初始化以用于拥有的分区。
[0204]
在操作中,加速器集成切片1590中的wd获取单元1591获取下一个wd 1584,其中包括要由图形加速模块1546的一个或更多个图形处理引擎完成的工作的指示。来自wd 1584的数据可以存储在寄存器1545被存储器管理单元(“mmu”)1539、中断管理电路1547和/或环境管理电路1548使用,如图所示。例如,mmu 1539的一个实施例包括用于访问os虚拟地址空间1585内的段/页表1586的段/页面漫游电路。中断管理电路1547可以处理从图形加速模块1546接收到的中断事件(int)1592。当执行图操作时,由图形处理引擎产生的有效地址1593由mmu 1539转换为实际地址。
[0205]
在一个实施例中,为每个图形处理引擎和/或图形加速模块1546复制相同的寄存器组1545,并且可以由系统管理程序或操作系统来初始化。这些复制的寄存器中的每一个都可以包含在加速器集成切片1590中。表1中显示了可由管理程序初始化的示例性寄存器。
[0206]
表1-管理程序初始化的寄存器
[0207]
1切片控制寄存器2实地址(ra)计划的处理区域指针3授权掩码覆盖寄存器4中断向量表输入偏移5中断向量表入口限制6状态寄存器7逻辑分区id8实地址(ra)管理程序加速器利用率记录指针9存储描述寄存器
[0208]
表2中示出了可以由操作系统初始化的示例性寄存器。
[0209]
表2-操作系统初始化寄存器
[0210][0211][0212]
在一个实施例中,每个wd 1584特定于特定的图形加速模块1546和/或特定图形处理引擎。它包含图形处理引擎进行工作或工作所需的所有信息,或者它可以是指向存储器位置的指针,其中应用程序建立了要完成的工作的命令队列。
[0213]
在至少一个实施例中,利用图15中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图15中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0214]
图16a-16b示出了根据本文至少一个实施例的示例性图形处理器。在至少一个实施例中,任何示例性图形处理器可以使用一个或更多个ip核心来制造。除了图示之外,在至少一个实施例中可以包括其他逻辑和电路,包括附加的图形处理器/核心、外围接口控制器或通用处理器核心。在至少一个实施例中,示例性图形处理器用于soc内。
[0215]
图16a示出了根据至少一个实施例的soc集成电路的示例性图形处理器1610,其可以使用一个或更多个ip核心来制造。图16b示出了根据至少一个实施例的soc集成电路的的附加示例性图形处理器1640,其可以使用一个或更多个ip核心来制造。在至少一个实施例中,图16a的图形处理器1610是低功耗图形处理器核心。在至少一个实施例中,图16b的图形处理器1640是更高性能的图形处理器核心。在至少一个实施例中,每个图形处理器1610、1640可以是图11的图形处理器1110的变体。
[0216]
在至少一个实施例中,图形处理器1610包括顶点处理器1605和一个或更多个片段处理器1615a-1615n(例如1615a、1615b、1615c、1615d至1615n-1和1615n)。在至少一个实施例中,图形处理器1610可以经由单独的逻辑来执行不同的着色器程序,使得顶点处理器1605被优化以执行针对顶点着色器程序的操作,而一个或更多个片段处理器1615a-1615n执行片段(例如,像素)着色操作用于片段或像素或着色器程序。在至少一个实施例中,顶点处理器1605执行3d图形管线的顶点处理阶段并生成图元和顶点数据。在至少一个实施例中,片段处理器1615a-1615n使用由顶点处理器1605生成的图元和顶点数据来生成在显示设备上显示的帧缓冲区。在至少一个实施例中,片段处理器1615a-1615n被优化以执行如在opengl api中所提供的片段着色器程序,其可以用于执行与在direct 3d api中所提供的像素着色器程序类似的操作。
[0217]
在至少一个实施例中,图形处理器1610附加地包括一个或更多个mmu 1620a-1620b、高速缓存1625a-1625b和电路互连1630a-1630b。在至少一个实施例中,一个或更多个mmu 1620a-1620b提供用于图形处理器1610的虚拟到物理地址的映射,包括用于顶点处理器1605和/或片段处理器1615a-1615n,其可以引用存储在存储器中的顶点或图像/纹理数据,除了存储在一个或更多个高速缓存1625a-1625b中的顶点或图像/纹理数据之外。在至少一个实施例中,一个或更多个mmu 1620a-1620b可以与系统内的其他mmu同步,包括与图11的一个或更多个应用处理器1105、图像处理器1115和/或视频处理器1120相关联的一个或更多个mmu,使得每个处理器1105-1120可以参与共享或统一的虚拟存储器系统。在至少一个实施例中,一个或更多个电路互连1630a-1630b使图形处理器1610能够经由soc的内部总线或经由直接连接与soc内的其他ip核心相连接。
[0218]
在至少一个实施例中,图形处理器1640包括图16a的图形处理器1610的一个或更多个mmu 1620a-1620b、高速缓存1625a-1625b和电路互连1630a-1630b。在至少一个实施例中,图形处理器1640包括一个或更多个着色器核心1655a-1655n(例如,1655a、1655b、1655c、1655d、1655e、1655f、至1655n-1和1655n),其提供了统一的着色器核心架构,其中单个核心或类型或核心可以执行所有类型的可编程着色器代码,包括用于实现顶点着色器、片段着色器和/或计算着色器的着色器程序代码。在至少一个实施例中,多个着色器核心可
以变化。在至少一个实施例中,图形处理器1640包括核心间任务管理器1645,其充当线程分派器以将执行线程分派给一个或更多个着色器核心1655a-1655n和分块单元1658,以加速基于图块渲染的分块操作,其中在图像空间中细分了场景的渲染操作,例如,以利用场景内的局部空间一致性或优化内部缓存的使用。
[0219]
在至少一个实施例中,利用图16a-16b中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图16a-16b中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0220]
图17a示出了根据至少一个实施例的图形核心1700。在至少一个实施例中,图形核心1700可以包括在图11的图形处理器1110内。在至少一个实施例中,图形核心1700可以是图16b中统一的着色器核心1655a-1655n。在至少一个实施例中,图形核心1700包括共享指令高速缓存1702、纹理单元1718和高速缓存/共享存储器1720,它们是图形核心1700内的执行资源所共有的。在至少一个实施例中,图形核心1700可以包括多个切片(slice)1701a-1701n或每个核心的分区,图形处理器可以包括图形核心1700的多个实例。切片1701a-1701n可以包括支持逻辑,该支持逻辑包括本地指令高速缓存1704a-1704n、线程调度器1706a-1706n、线程分派器1708a-1708n和一组寄存器1710a-1710n。在至少一个实施例中,切片1701a-1701n可以包括一组附加功能单元(“afu
‘
)1712a-1712n、浮点单元(“fpu”)1714a-1714n、整数算术逻辑单元(“alu”)1716a-1716n、地址计算单元(“acu”)1713a-1713n、双精度浮点单元(“dpfpu”)1715a-1715n和矩阵处理单元(“mpu”)1717a-1717n。
[0221]
在一个实施例中,fpu 1714a-1714n可以执行单精度(32位)和半精度(16位)浮点运算,而dpfpu 1715a-1715n可以执行双精度(64位)浮点运算点操作。在至少一个实施例中,alu 1716a-1716n可以以8位、16位和32位精度执行可变精度整数运算,并且可以被配置用于混合精度运算。在至少一个实施例中,mpu 1717a-1717n还可被配置用于混合精度矩阵运算,包括半精度浮点运算和8位整数运算。在至少一个实施例中,mpu 1717a-1717n可以执行各种矩阵操作以加速cuda程序,包括使得能够支持加速的通用矩阵到矩阵乘法(gemm)。在至少一个实施例中,afu 1712a-1712n可以执行浮点数或整数单元不支持的附加逻辑运算,包括三角运算(例如,sine、cosine等)。
[0222]
图17b示出了在至少一个实施例中的通用图形处理单元(gpgpu)1730。在至少一个实施例中,gpgpu 1730是高度并行的并且适合于部署在多芯片模块上。在至少一个实施例中,gpgpu 1730可以被配置为使得高度并行的计算操作能够由gpu阵列来执行。在至少一个实施例中,gpgpu 1730可以直接链路到gpgpu 1730的其他实例,以创建多gpu集群以提高用于cuda程序的执行时间。在至少一个实施例中,gpgpu 1730包括主机接口1732以实现与主机处理器的连接。在至少一个实施例中,主机接口1732是pcie接口。在至少一个实施例中,主机接口1732可以是厂商专用的通信接口或通信结构。在至少一个实施例中,gpgpu 1730从主机处理器接收命令,并使用全局调度器1734将与那些命令相关联的执行线程分派给一组计算集群1736a-1736h。在至少一个实施例中,计算集群1736a-1736h共享高速缓存存储器1738。在至少一个实施例中,高速缓存存储器1738可以用作计算集群1736a-1736h内的高速缓存存储器的高级高速缓存。
[0223]
在至少一个实施例中,gpgpu 1730包括经由一组存储器控制器1742a-1742b与计算集群1736a-1736h耦合的存储器1744a-1744b。在至少一个实施例中,存储器1744a-1744b
可以包括各种类型的存储器设备,包括动态随机存取存储器(dram)或图形随机存取存储器,例如同步图形随机存取存储器(“sgram”),包括图形双倍数据速率(“gddr”)存储器。
[0224]
在至少一个实施例中,计算集群1736a-1736h各自包括一组图形核心,诸如图17a的图形核心1700,其可以包括多种类型的整数和浮点逻辑单元,可以以各种精度执行计算操作,包括适合与cuda程序相关的计算。例如,在至少一个实施例中,每个计算集群1736a-1736h中的浮点单元的至少一个子集可以配置为执行16位或32位浮点运算,而不同的浮点单元的子集可以配置为执行64位浮点运算。
[0225]
在至少一个实施例中,gpgpu 1730的多个实例可以被配置为操作为计算集群。计算集群1736a-1736h可以实现用于同步和数据交换的任何技术上可行的通信技术。在至少一个实施例中,gpgpu 1730的多个实例通过主机接口1732进行通信。在至少一个实施例中,gpgpu 1730包括i/o集线器1739,其将gpgpu 1730与gpu链路1740耦合,使得能够直接连接至gpgpu1730的其他的实例。在至少一个实施例中,gpu链路1740耦合到专用gpu到gpu桥接器,其使得能够在gpgpu 1730的多个实例之间进行通信和同步。在至少一个实施例中,gpu链路1740与高速互连耦合,以向其他gpgpu或并行处理器发送和接收数据。在至少一个实施例中,gpgpu1730的多个实例位于单独的数据处理系统中,并经由可经由主机接口1732访问的网络设备进行通信。在至少一个实施例中,gpu链路1740可被配置为能够连接到主机处理器,附加或替代主机接口1732。在至少一个实施例中,gpgpu 1730可以配置为执行cuda程序。
[0226]
在至少一个实施例中,利用图17a-17b中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图17a-17b中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0227]
图18a示出了根据至少一个实施例的并行处理器1800。在至少一个实施例中,并行处理器1800的各种组件可以使用一个或更多个集成电路设备来实现,例如可编程处理器、专用集成电路(“asic”)或fpga。
[0228]
在至少一个实施例中,并行处理器1800包括并行处理单元1802。在至少一个实施例中,并行处理单元1802包括i/o单元1804,其使得能够与其他设备进行通信,包括并行处理单元1802的其他实例。在至少一个实施例中,i/o单元1804可以直接连接到其他设备。在至少一个实施例中,i/o单元1804通过使用集线器或交换机接口(例如,存储器集线器1805)与其他设备连接。在至少一个实施例中,存储器集线器1805与i/o单元1804之间的连接形成通信链路。在至少一个实施例中,i/o单元1804与主机接口1806和存储器交叉开关1816连接,其中主机接口1806接收用于执行处理操作的命令,而存储器交叉开关1816接收用于执行存储器操作的命令。
[0229]
在至少一个实施例中,当主机接口1806经由i/o单元1804接收命令缓冲区时,主机接口1806可以引导工作操作以执行那些命令到前端1808。在至少一个实施例中,前端1808与调度器1810耦合,调度器1810配置成将命令或其他工作项分配给处理阵列1812。在至少一个实施例中,调度器1810确保在将任务分配给处理阵列1812中的处理阵列1812之前,处理阵列1812被正确地配置并且处于有效状态。在至少一个实施例中,调度器1810通过在微控制器上执行的固件逻辑来实现。在至少一个实施例中,微控制器实现的调度器1810可配置成以粗粒度和细粒度执行复杂的调度和工作分配操作,从而实现对在处理阵列1812上执
行的线程的快速抢占和环境切换。在至少一个实施例中,主机软件可以证明用于通过多个图形处理门铃之一在处理阵列1812上进行调度的工作负载。在至少一个实施例中,工作负载然后可以由包括调度器1810的微控制器内的调度器1810逻辑在处理阵列1812上自动分配。
[0230]
在至少一个实施例中,处理阵列1812可以包括多达“n”个处理集群(例如,集群1814a、集群1814b到集群1814n)。在至少一个实施例中,处理阵列1812的每个集群1814a-1814n可以执行大量并发线程。在至少一个实施例中,调度器1810可以使用各种调度和/或工作分配算法将工作分配给处理阵列1812的集群1814a-1814n,其可以根据每种程序或计算类型产生的工作负载而变化。在至少一个实施例中,调度可以由调度器1810动态地处理,或者可以在配置为由处理阵列1812执行的程序逻辑的编译期间部分地由编译器逻辑来辅助。在至少一个实施例中,可将处理阵列1812的不同的集群1814a-1814n分配用于处理不同类型的程序或用于执行不同类型的计算。
[0231]
在至少一个实施例中,处理阵列1812可以配置成执行各种类型的并行处理操作。在至少一个实施例中,处理阵列1812配置成执行通用并行计算操作。例如,在至少一个实施例中,处理阵列1812可以包括执行处理任务的逻辑,该处理任务包括对视频和/或音频数据的过滤,执行建模操作,包括物理操作以及执行数据转换。
[0232]
在至少一个实施例中,处理阵列1812配置成执行并行图形处理操作。在至少一个实施例中,处理阵列1812可以包括附加逻辑以支持这种图形处理操作的执行,包括但不限于执行纹理操作的纹理采样逻辑,以及镶嵌逻辑和其他顶点处理逻辑。在至少一个实施例中,处理阵列1812可以配置成执行与图形处理有关的着色器程序,例如但不限于顶点着色器、曲面细分着色器、几何着色器和像素着色器。在至少一个实施例中,并行处理单元1802可以经由i/o单元1804从系统存储器传送数据以进行处理。在至少一个实施例中,在处理期间,可以在处理期间将传送的数据存储到片上存储器(例如,并行处理器存储器1822),然后将其写回到系统存储器。
[0233]
在至少一个实施例中,当并行处理单元1802用于执行图处理时,调度器1810可以配置成将处理工作负载划分为近似相等大小的任务,以更好地将图形处理操作分配给处理阵列1812的多个集群1814a-1814n。在至少一个实施例中,处理阵列1812的部分可以配置成执行不同类型的处理。例如,在至少一个实施例中,第一部分可以配置成执行顶点着色和拓扑生成,第二部分可以配置成执行镶嵌和几何着色,并且第三部分可以配置成执行像素着色或其他屏幕空间操作,以生成用于显示的渲染图像。在至少一个实施例中,可以将由集群1814a-1814n中的一个或更多个产生的中间数据存储在缓冲区中,以允许在集群1814a-1814n之间传输中间数据以进行进一步处理。
[0234]
在至少一个实施例中,处理阵列1812可以经由调度器1810接收要执行的处理任务,该调度器1810从前端1808接收定义处理任务的命令。在至少一个实施例中,处理任务可以包括要被处理的数据的索引,例如可以包括表面(补丁)数据、原始数据、顶点数据和/或像素数据,以及状态参数和定义如何处理数据的命令(例如,要执行什么程序)。在至少一个实施例中,调度器1810可以配置成获取与任务相对应的索引,或者可以从前端1808接收索引。在至少一个实施例中,前端1808可以配置成确保在启动由传入命令缓冲区(例如,批缓冲区(batch-buffer)、推送缓冲区等)指定的工作负载之前,处理阵列1812配置成有效状
态。
[0235]
在至少一个实施例中,并行处理单元1802的一个或更多个实例中的每一个可以与并行处理器存储器1822耦合。在至少一个实施例中,可以经由存储器交叉开关1816访问并行处理器存储器1822,所述存储器交叉开关1816可以接收来自处理阵列1812以及i/o单元1804的存储器请求。在至少一个实施例中,存储器交叉开关1816可以经由存储器接口1818访问并行处理器存储器1822。在至少一个实施例中,存储器接口1818可以包括多个分区单元(例如,分区单元1820a、分区单元1820b到分区单元1820n),其可各自耦合至并行处理器存储器1822的一部分(例如,存储器单元)。在至少一个实施例中,多个分区单元1820a-1820n为配置为等于存储器单元的数量,使得第一分区单元1820a具有对应的第一存储器单元1824a,第二分区单元1820b具有对应的存储器单元1824b,第n分区单元1820n具有对应的第n存储器单元1824n。在至少一个实施例中,分区单元1820a-1820n的数量可以不等于存储器设备的数量。
[0236]
在至少一个实施例中,存储器单元1824a-1824n可以包括各种类型的存储器设备,包括动态随机存取存储器(dram)或图形随机存取存储器,例如同步图形随机存取存储器(sgram),包括图形双倍数据速率(gddr)存储器。在至少一个实施例中,存储器单元1824a-1824n还可包括3d堆叠存储器,包括但不限于高带宽存储器(hbm)。在至少一个实施例中,可以跨存储器单元1824a-1824n来存储诸如帧缓冲区或纹理映射的渲染目标,从而允许分区单元1820a-1820n并行地写入每个渲染目标的部分,以有效地使用并行处理器存储器1822的可用带宽。在至少一个实施例中,可以排除并行处理器存储器1822的本地实例,以有利于利用系统存储器与本地高速缓存存储器结合的统一存储器设计。
[0237]
在至少一个实施例中,处理阵列1812的集群1814a-1814n中的任何一个都可以处理将被写入并行处理器存储器1822内的任何存储器单元1824a-1824n中的数据。在至少一个实施例中,存储器交叉开关1816可以配置为将每个集群1814a-1814n的输出传输到任何分区单元1820a-1820n或另一个集群1814a-1814n,集群1814a-1814n可以对输出执行其他处理操作。在至少一个实施例中,每个集群1814a-1814n可以通过存储器交叉开关1816与存储器接口1818通信,以从各种外部存储设备读取或写入各种外部存储设备。在至少一个实施例中,存储器交叉开关1816具有到存储器接口1818的连接以与i/o单元1804通信,以及到并行处理器存储器1822的本地实例的连接,从而使不同处理集群1814a-1814n内的处理单元与系统存储器或不是并行处理单元1802本地的其他存储器进行通信。在至少一个实施例中,存储器交叉开关1816可以使用虚拟通道来分离集群1814a-1814n和分区单元1820a-1820n之间的业务流。
[0238]
在至少一个实施例中,可以在单个插入卡上提供并行处理单元1802的多个实例,或者可以将多个插入卡互连。在至少一个实施例中,并行处理单元1802的不同实例可以配置成相互操作,即使不同实例具有不同数量的处理核心,不同数量的本地并行处理器存储器和/或其他配置差异。例如,在至少一个实施例中,并行处理单元1802的一些实例可以包括相对于其他实例而言更高精度的浮点单元。在至少一个实施例中,结合并行处理单元1802或并行处理器1800的一个或更多个实例的系统可以以各种配置和形式因素来实现,包括但不限于台式机、膝上型计算机或手持式个人计算机、服务器、工作站、游戏机和/或嵌入式系统。
[0239]
图18b示出了根据至少一个实施例的处理集群1894。在至少一个实施例中,处理集群1894被包括在并行处理单元内。在至少一个实施例中,处理集群1894是图18的处理集群1814a-1814n之一的实例。在至少一个实施例中,处理集群1894可以配置成并行执行许多线程,其中术语“线程”是指在特定的一组输入数据上执行的特定程序的实例。在至少一个实施例中,单指令多数据(simd)指令发布技术用于支持大量线程的并行执行而无需提供多个独立的指令单元。在至少一个实施例中,使用单指令多线程(simt)技术来支持并行执行大量一般同步的线程,这使用了公共指令单元,该公共指令单元配置成向每个处理集群1894内的一组处理引擎发出指令。
[0240]
在至少一个实施例中,可以通过将处理任务分配给simt并行处理器的管线管理器1832来控制处理集群1894的操作。在至少一个实施例中,管线管理器1832从图18的调度器1810接收指令,通过图形多处理器1834和/或纹理单元1836管理这些指令的执行。在至少一个实施例中,图形多处理器1834是simt并行处理器的示例性实例。然而,在至少一个实施例中,处理集群1894内可以包括不同架构的各种类型的simt并行处理器。在至少一个实施例中,在处理集群1894内可以包括图形多处理器1834的一个或更多个实例。在至少一个实施例中,图形多处理器1834可以处理数据,并且数据交叉开关1840可以用于将处理后的数据分发到多个可能的目的(包括其他着色器单元)地之一。在至少一个实施例中,管线管理器1832可以通过指定要经由数据交叉开关1840分配的处理后的数据的目的地来促进处理后的数据的分配。
[0241]
在至少一个实施例中,处理集群1894内的每个图形多处理器1834可以包括相同的一组功能执行逻辑(例如,算术逻辑单元、加载存储单元(lsu)等)。在至少一个实施例中,可以以管线方式配置功能执行逻辑,其中可以在先前的指令完成之前发出新的指令。在至少一个实施例中,功能执行逻辑支持多种运算,包括整数和浮点算术、比较操作、布尔运算、移位和各种代数函数的计算。在至少一个实施例中,可以利用相同的功能单元硬件来执行不同的操作,并且可以存在功能单元的任何组合。
[0242]
在至少一个实施例中,传送到处理集群1894的指令构成线程。在至少一个实施例中,跨一组并行处理引擎执行的一组线程是线程组。在至少一个实施例中,线程组在不同的输入数据上执行程序。在至少一个实施例中,线程组内的每个线程可被分配给图形多处理器1834内的不同处理引擎。在至少一个实施例中,线程组可包括比图形多处理器1834内的多个处理引擎更少的线程。在至少一个实施例中,当线程组包括的线程数少于处理引擎的数量时,一个或更多个处理引擎在正在处理该线程组的循环期间可能是空闲的。在至少一个实施例中,线程组还可以包括比图形多处理器1834内的多个处理引擎更多的线程。在至少一个实施例中,当线程组包括比图形多处理器1834内的处理引擎的数量更多的线程时,可以在连续的时钟周期内执行处理。在至少一个实施例中,可以在图形多处理器1834上同时执行多个线程组。
[0243]
在至少一个实施例中,图形多处理器1834包括内部高速缓存存储器,以执行加载和存储操作。在至少一个实施例中,图形多处理器1834可以放弃内部高速缓存并使用处理集群1894内的高速缓存存储器(例如,l1高速缓存1848)。在至少一个实施例中,每个图形多处理器1834还可以访问分区单元(例如,图18a的分区单元1820a-1820n)内的l2高速缓存,这些分区单元在所有处理集群1894之间共享并且可以用于在线程之间传输数据。在至少一
个实施例中,图形多处理器1834还可以访问片外全局存储器,其可以包括本地并行处理器存储器和/或系统存储器中的一个或更多个。在至少一个实施例中,并行处理单元1802外部的任何存储器都可以用作全局存储器。在至少一个实施例中,处理集群1894包括图形多处理器1834的多个实例,它们可以共享可以存储在l1高速缓存1848中的公共指令和数据。
[0244]
在至少一个实施例中,每个处理集群1894可以包括配置成将虚拟地址映射为物理地址的mmu 1845。在至少一个实施例中,mmu 1845的一个或更多个实例可以驻留在图18的存储器接口1818内。在至少一个实施例中,mmu 1845包括一组页表条目(pte),其用于将虚拟地址映射到图块(谈论有关图块的更多信息)的物理地址以及可选地映射到高速缓存行索引。在至少一个实施例中,mmu 1845可以包括地址转换后备缓冲区(tlb)或可以驻留在图形多处理器1834或l1高速缓存1848或处理集群1894内的高速缓存。在至少一个实施例中,处理物理地址以分配表面数据访问局部性,以便在分区单元之间进行有效的请求交织。在至少一个实施例中,高速缓存行索引可以用于确定对高速缓存线的请求是命中还是未命中。
[0245]
在至少一个实施例中,可以配置处理集群1894,使得每个图形多处理器1834耦合到纹理单元1836,以执行纹理映射操作,例如,可以涉及确定纹理样本位置、读取纹理数据以及过滤纹理数据。在至少一个实施例中,根据需要从内部纹理l1高速缓存(未示出)或从图形多处理器1834内的l1高速缓存中读取纹理数据,并从l2高速缓存、本地并行处理器存储器或系统存储器中获取纹理数据。在至少一个实施例中,每个图形多处理器1834将处理后的任务输出到数据交叉开关1840,以将处理后的任务提供给另一处理集群1894以进行进一步处理或将处理后的任务存储在l2高速缓存、本地并行处理器存储器、或经由存储器交叉开关1816的系统存储器中。在至少一个实施例中,光栅前操作单元(“prerop”)1842配置成从图形多处理器1834接收数据,将数据引导至rop单元,该rop单元可以与本文所述的分区单元(例如,图18的分区单元1820a-1820n)一起定位。在至少一个实施例中,prerop1842单元可以执行用于颜色混合的优化、组织像素颜色数据以及执行地址转换。
[0246]
图18c示出了根据至少一个实施例的图形多处理器1896。在至少一个实施例中,图形多处理器1896是图18b的图形多处理器1834。在至少一个实施例中,图形多处理器1896与处理集群1894的管线管理器1832耦合。在至少一个实施例中,图形多处理器1896具有执行管线,该执行管线包括但不限于指令高速缓存1852、指令单元1854、地址映射单元1856、寄存器文件1858、一个或更多个gpgpu核心1862和一个或更多个lsu1866。gpgpu核心1862和lsu 1866与高速缓存存储器1872和共享存储器1870通过存储器和高速缓存互连1868耦合。
[0247]
在至少一个实施例中,指令高速缓存1852从管线管理器1832接收要执行的指令流。在至少一个实施例中,将指令高速缓存在指令高速缓存1852中并将其分派以供指令单元1854执行。在一个实施例中,指令单元1854可以分派指令作为线程组(例如,线程束),将线程组的每个线程分配给gpgpu核心1862内的不同执行单元。在至少一个实施例中,指令可以通过在统一地址空间内指定地址来访问任何本地、共享或全局地址空间。在至少一个实施例中,地址映射单元1856可以用于将统一地址空间中的地址转换成可以由lsu 1866访问的不同的存储器地址。
[0248]
在至少一个实施例中,寄存器文件1858为图形多处理器1896的功能单元提供了一组寄存器。在至少一个实施例中,寄存器文件1858为连接到图形多处理器1896的功能单元
(例如,gpgpu核心1862、lsu 1866)的数据路径的操作数提供了临时存储。在至少一个实施例中,在每个功能单元之间划分寄存器文件1858,使得为每个功能单元分配寄存器文件1858的专用部分。在至少一个实施例中,寄存器文件1858在图形多处理器1896正在执行的不同线程组之间划分。
[0249]
在至少一个实施例中,gpgpu核心1862可以各自包括用于执行图多处理器1896的指令的fpu和/或alu。gpgpu核心1862在架构上可以相似或架构可能有所不同。在至少一个实施例中,gpgpu核心1862的第一部分包括单精度fpu和整数alu,而gpgpu核心1862的第二部分包括双精度fpu。在至少一个实施例中,fpu可以实现用于浮点算法的ieee754-2008标准或启用可变精度浮点算法。在至少一个实施例中,图形多处理器1896可以另外包括一个或更多个固定功能或特殊功能单元,以执行特定功能,诸如复制矩形或像素混合操作。在至少一个实施例中,gpgpu核心1862中的一个或更多个也可以包括固定或特殊功能逻辑。
[0250]
在至少一个实施例中,gpgpu核心1862包括能够对多组数据执行单个指令的simd逻辑。在至少一个实施例中,gpgpu核心1862可以物理地执行simd4、simd8和simd9指令,并且在逻辑上执行simd1、simd2和simd32指令。在至少一个实施例中,用于gpgpu核心的simd指令可以在编译时由着色器编译器生成,或者在执行针对单程序多数据(spmd)或simt架构编写和编译的程序时自动生成。在至少一个实施例中,可以通过单个simd指令来执行为simt执行模型配置的程序的多个线程。例如,在至少一个实施例中,可以通过单个simd8逻辑单元并行执行执行相同或相似操作的八个simt线程。
[0251]
在至少一个实施例中,存储器和高速缓存互连1868是将图形多处理器1896的每个功能单元连接到寄存器文件1858和共享存储器1870的互连网络。在至少一个实施例中,存储器和高速缓存互连1868是交叉开关互连,其允许lsu 1866在共享存储器1870和寄存器文件1858之间实现加载和存储操作。在至少一个实施例中,寄存器文件1858可以以与gpgpu核心1862相同的频率操作,从而在gpgpu核心1862和寄存器文件1858之间进行数据传输的延迟非常低。在至少一个实施例中,共享存储器1870可以用于启用在图形多处理器1896内的功能单元上执行的线程之间的通信。在至少一个实施例中,高速缓存存储器1872可以用作例如数据高速缓存,以高速缓存在功能单元和纹理单元1836之间通信的纹理数据。在至少一个实施例中,共享存储器1870也可以用作程序管理的高速缓存。在至少一个实施例中,除了存储在高速缓存存储器1872中的自动高速缓存的数据之外,在gpgpu核心1862上执行的线程还可以以编程方式将数据存储在共享存储器中。
[0252]
在至少一个实施例中,如本文所述的并行处理器或gpgpu通信地耦合到主机/处理器核心,以加速图形操作、机器学习操作、图案分析操作以及各种通用gpu(gpgpu)功能。在至少一个实施例中,gpu可以通过总线或其他互连(例如,诸如pcie或nvlink的高速互连)通信地耦合到主机处理器/核心。在至少一个实施例中,gpu可以与核心集成在相同的封装或芯片上,并通过内部处理器总线/互连(即,封装或芯片的内部)通信地耦合到核心。在至少一个实施例中,不管gpu连接的方式如何,处理器核心可以以wd包含的命令/指令序列的形式向gpu分配工作。在至少一个实施例中,gpu然后使用专用电路/逻辑来有效地处理这些命令/指令。
[0253]
在至少一个实施例中,利用图18a-18c中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图18a-18c中所描绘的一个
或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0254]
图19示出了根据至少一个实施例的图形处理器1900。在至少一个实施例中,图形处理器1900包括环形互连1902、管线前端1904、媒体引擎1937和图形核心1980a-1980n。在至少一个实施例中,环形互连1902将图形处理器1900耦合到其他处理单元,包括其他图形处理器或一个或更多个通用处理器核心。在至少一个实施例中,图形处理器1900是集成在多核心处理系统内的许多处理器之一。
[0255]
在至少一个实施例中,图形处理器1900经由环形互连1902接收多批命令。在至少一个实施例中,输入命令由管线前端1904中的命令流转化器1903解释。在至少一个实施例中,图形处理器1900包括可缩放执行逻辑,以经由图形核心1980a-1980n执行3d几何处理和媒体处理。在至少一个实施例中,对于3d几何处理命令,命令流转化器1903将命令提供给几何管线1936。在至少一个实施例中,对于至少一些媒体处理命令,命令流转化器1903将命令提供给视频前端1934,其与媒体引擎1937耦合。在至少一个实施例中,媒体引擎1937包括用于视频和图像后处理的视频质量引擎(vqe)1930,以及用于提供硬件加速媒体数据编码和解码的多格式编码/解码(mfx)1933引擎。在至少一个实施例中,几何管线1936和媒体引擎1937各自生成用于由至少一个图形核心1980a提供的线程执行资源的执行线程。
[0256]
在至少一个实施例中,图形处理器1900包括以模块化图形核心1980a-1980n(有时称为核心切片)为特征的可缩放线程执行资源,每个模块核心具有多个子核心1950a-550n、1960a-1960n(有时称为核心子切片)。在至少一个实施例中,图形处理器1900可以具有任意数量的图形核心1980a至1980n。在至少一个实施例中,图形处理器1900包括具有至少第一子核心1950a和第二子核心1960a的图形核心1980a。在至少一个实施例中,图形处理器1900是具有单个子核心(例如1950a)的低功率处理器。在至少一个实施例中,图形处理器1900包括多个图形核心1980a-1980n,每个图形核心包括一组第一子核心1950a-1950n和一组第二子核心1960a-1960n。在至少一个实施例中,第一子核心1950a-1950n中的每个子核心至少包括第一组执行单元(eu)1952a-1952n和媒体/纹理采样器1954a-1954n。在至少一个实施例中,第二子核心1960a-1960n中的每个子核心至少包括第二组执行单元1962a-1962n和采样器1964a-1964n。在至少一个实施例中,每个子核心1950a-1950n、1960a-1960n共享一组共享资源1970a-1970n。在至少一个实施例中,共享资源包括共享高速缓冲存储器和像素操作逻辑。
[0257]
在至少一个实施例中,利用图19中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图19中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0258]
图20示出了根据至少一个实施例的处理器2000。在至少一个实施例中,处理器2000可以包括但不限于执行指令的逻辑电路。在至少一个实施例中,处理器2000可以执行指令,包括x86指令、arm指令、用于asic的专用指令等。在至少一个实施例中,处理器2010可以包括用于存储封装数据的寄存器,例如作为加利福尼亚州圣克拉拉市英特尔公司采用mmx技术启用的微处理器中的64位宽mmxtm寄存器。在至少一个实施例中,整数和浮点数形式可用的mmx寄存器可以与封装的数据元素一起运行,所述封装的数据元素伴随simd和流式simd扩展(“sse”)指令。在至少一个实施例中,与sse2、sse3、sse4、avx或更高版本(一般称为“ssex”)技术有关的128位宽xmm寄存器可以保存此类封装数据操作数。在至少一个实
施例中,处理器2010可以执行指令以加速cuad程序。
[0259]
在至少一个实施例中,处理器2000包括有序前端(“前端”)2001,以提取要执行的指令并准备稍后在处理器管线中使用的指令。在至少一个实施例中,前端2001可以包括几个单元。在至少一个实施例中,指令预取器2026从存储器中获取指令并将指令提供给指令解码器2028,指令解码器2028又对指令进行解码或解释。例如,在至少一个实施例中,指令解码器2028将接收到的指令解码用于执行的所谓的“微指令”或“微操作”(也称为“微操作”或“微指令”)的一个或更多个操作。在至少一个实施例中,指令解码器2028将指令解析为操作码以及相应的数据和控制字段,其可以由微架构用来使用以执行操作。在至少一个实施例中,跟踪高速缓存2030可以将解码的微指令组装成微指令队列2034中的程序排序的序列或追踪以供执行。在至少一个实施例中,当追踪高速缓存2030遇到复杂指令时,微码rom 2032提供完成操作所需的微指令。
[0260]
在至少一个实施例中,可以将一些指令转换成单个微操作,而另一些指令则需要几个微操作来完成全部操作。在至少一个实施例中,如果需要多于四个的微指令来完成一条指令,则指令解码器2028可以访问微码rom 2032以执行指令。在至少一个实施例中,可以将指令解码为少量的微指令以在指令解码器2028处进行处理。在至少一个实施例中,如果需要多个微指令完成操作,则可以将指令存储在微码rom 2032中。在至少一个实施例中,追踪高速缓存器2030参考入口点可编程逻辑阵列(“pla”)以确定正确的微指令指针,用于根据至少一个实施例从微码rom 2032读取微码序列以完成一个或更多个指令。在至少一个实施例中,在微码rom2032完成对指令的微操作排序之后,机器的前端2001可以恢复从追踪高速缓存2030获取微操作。
[0261]
在至少一个实施例中,乱序执行引擎(“乱序引擎”)2003可以准备用于执行的指令。在至少一个实施例中,乱序执行逻辑具有多个缓冲区,以使指令流平滑并重新排序,以在指令沿管线下降并被调度执行时优化性能。乱序执行引擎2003包括但不限于分配器/寄存器重命名器2040、存储器微指令队列2042、整数/浮点微指令队列2044、存储器调度器2046、快速调度器2002、慢速/通用浮点调度器(“慢速/通用fp调度器”)2004和简单浮点调度器(“简单fp调度器”)2006。在至少一个实施例中,快速调度器2002、慢速/通用浮点调度器2004和简单浮点调度器2006也统称为“微指令调度器2002、2004、2006”。分配器/寄存器重命名器2040分配每个微指令按顺序执行所需要的机器缓冲区和资源。在至少一个实施例中,分配器/寄存器重命名器2040将逻辑寄存器重命名为寄存器文件中的条目。在至少一个实施例中,分配器/寄存器重命名器2040还为两个微指令队列之一中的每个微指令分配条目,存储器微指令队列2042用于存储器操作和整数/浮点微指令队列2044用于非存储器操作,在存储器调度器2046和微指令调度器2002、2004、2006的前面。在至少一个实施例中,微指令调度器2002、2004、2006基于它们的从属输入寄存器操作数源的就绪性和需要完成的执行资源微指令的可用性来确定何时准备好执行微指令。在至少一个实施例中,至少一个实施例的快速调度器2002可以在主时钟周期的每个一半上调度,而慢速/通用浮点调度器2004和简单浮点调度器2006可以在每个主处理器时钟周期调度一次。在至少一个实施例中,微指令调度器2002、2004、2006对调度端口进行仲裁,以调度用于执行的微指令。
[0262]
在至少一个实施例中,执行块2011包括但不限于整数寄存器文件/支路网络2008、浮点寄存器文件/支路网络(“fp寄存器文件/支路网络”)2010、地址生成单元(“agu”)2012
和2014、快速算术逻辑单元(“快速alu”)2016和2018、慢速alu 2020、浮点alu(“fp”)2022和浮点移动单元(“fp移动”)2024。在至少一个实施例中,整数寄存器文件/支路网络2008和浮点寄存器文件/旁路网络2010在本文中也称为“寄存器文件2008、2010”。在至少一个实施例中,agus 2012和2014、快速alu 2016和2018、慢速alu 2020、浮点alu 2022和浮点移动单元2024在本文中也称为“执行单元2012、2014、2016、2018、2020、2022和2024”。在至少一个实施例中,执行框可以包括但不限于任意数量(包括零)和类型的寄存器文件、支路网络、地址生成单元和执行单元(以任何组合)。
[0263]
在至少一个实施例中,寄存器文件2008、2010可以布置在微指令调度器2002、2004、2006与执行单元2012、2014、2016、2018、2020、2022和2024之间。在至少一个实施例中,整数寄存器文件/支路网络2008执行整数运算。在至少一个实施例中,浮点寄存器文件/支路网络2010执行浮点操作。在至少一个实施例中,寄存器文件2008、2010中的每一个可以包括但不限于支路网络,该支路网络可以绕过或转发尚未写入寄存器文件中的刚刚完成的结果到新的从属对象。在至少一个实施例中,寄存器文件2008、2010可以彼此通信数据。在至少一个实施例中,整数寄存器文件/支路网络2008可以包括但不限于两个单独的寄存器文件、一个寄存器文件用于低阶32位数据,第二寄存器文件用于高阶32位数据。在至少一个实施例中,浮点寄存器文件/支路网络2010可以包括但不限于128位宽的条目,因为浮点指令通常具有宽度为64至128位的操作数。
[0264]
在至少一个实施例中,执行单元2012、2014、2016、2018、2020、2022、2024可以执行指令。在至少一个实施例中,寄存器文件2008、2010存储微指令需要执行的整数和浮点数据操作数值。在至少一个实施例中,处理器2000可以包括但不限于任意数量的执行单元2012、2014、2016、2018、2020、2022、2024及其组合。在至少一个实施例中,浮点alu 2022和浮点移动单元2024,可以执行浮点、mmx、simd、avx和sse或其他操作,包括专门的机器学习指令。在至少一个实施例中,浮点alu 2022可以包括但不限于64位乘64位浮点除法器,以执行除法、平方根和余数微操作。在至少一个实施例中,可以用浮点硬件来处理涉及浮点值的指令。在至少一个实施例中,可以将alu操作传递给快速alu 2016、2018。在至少一个实施例中,快速alus 2016、2018可以以半个时钟周期的有效延迟执行快速操作。在至少一个实施例中,大多数复杂的整数运算进入慢速alu 2020,因为慢速alu 2020可以包括但不限于用于长延迟类型操作的整数执行硬件,例如乘法器、移位、标志逻辑和分支处理。在至少一个实施例中,存储器加载/存储操作可以由agus 2012、2014执行。在至少一个实施例中,快速alu 2016、快速alu 2018和慢速alu 2020可以对64位数据操作数执行整数运算。在至少一个实施例中,可以实现快速alu 2016、快速alu 2018和慢速alu 2020以支持包括16、32、128、256等的各种数据位大小。在至少一个实施例中,浮点alu 2022和浮点移动单元2024可以实现为支持具有各种宽度的位的一定范围的操作数。在至少一个实施例中,浮点alu 2022和浮点移动单元2024可以结合simd和多媒体指令对128位宽封装数据操作数进行操作。
[0265]
在至少一个实施例中,微指令调度器2002、2004、2006在父加载完成执行之前调度从属操作。在至少一个实施例中,由于可以在处理器2000中推测性地调度和执行微指令,处理器2000还可以包括用于处理存储器未命中的逻辑。在至少一个实施例中,如果数据高速缓存中的数据加载未命中,则可能存在在管线中正在运行的从属操作,其使调度器暂时没有正确的数据。在至少一个实施例中,一种重放机制追踪踪并重新执行使用不正确数据的
指令。在至少一个实施例中,可能需要重放从属操作并且可以允许完成独立操作。在至少一个实施例中,处理器的至少一个实施例的调度器和重放机制也可以设计为捕获用于文本串比较操作的指令序列。
[0266]
在至少一个实施例中,术语“寄存器”可以指代可以用作识别操作数的指令的一部分的机载处理器存储位置。在至少一个实施例中,寄存器可以是那些可以从处理器外部使用的寄存器(从程序员的角度来看)。在至少一个实施例中,寄存器可能不限于特定类型的电路。相反,在至少一个实施例中,寄存器可以存储数据、提供数据并执行本文描述的功能。在至少一个实施例中,本文描述的寄存器可以通过处理器内的电路使用多种不同技术来实现,例如专用物理寄存器、使用寄存器重命名动态分配的物理寄存器、专用和动态分配的物理寄存器的组合等。在至少一个实施例中,整数寄存器存储32位整数数据。至少一个实施例的寄存器文件还包含八个用于封装数据的多媒体simd寄存器。
[0267]
在至少一个实施例中,利用图20中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图20中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0268]
图21示出了根据至少一个实施例的处理器2100。在至少一个实施例中,处理器2100包括但不限于一个或更多个处理器核心(核心)2102a-2102n、集成存储器控制器2114和集成图形处理器2108。在至少一个实施例中,处理器2100可以包括直至并包括由虚线框表示的附加处理器核心2102n的附加核心。在至少一个实施例中,每个处理器核心2102a-2102n包括一个或更多个内部高速缓存单元2104a-2104n。在至少一个实施例中,每个处理器核心还可以访问一个或更多个共享高速缓存的单元2106。
[0269]
在至少一个实施例中,内部高速缓存单元2104a-2104n和共享高速缓存单元2106表示处理器2100内的高速缓存存储器层次结构。在至少一个实施例中,高速缓存存储器单元2104a-2104n可以包括每个处理器核心内的至少一级指令和数据以及共享中级缓存中的一级或更多级缓存,例如l2、l3、4级(l4)或其他级别的缓存,其中在外部存储器之前将最高级别的缓存归类为llc。在至少一个实施例中,高速缓存一致性逻辑维持各种高速缓存单元2106和2104a-2104n之间的一致性。
[0270]
在至少一个实施例中,处理器2100还可包括一组一个或更多个总线控制器单元2116和系统代理核心2110。在至少一个实施例中,一个或更多个总线控制器单元2116管理一组外围总线,例如一个或更多个pci或pci express总线。在至少一个实施例中,系统代理核心2110为各种处理器组件提供管理功能。在至少一个实施例中,系统代理核心2110包括一个或更多个集成存储器控制器2114,以管理对各种外部存储器设备(未示出)的访问。
[0271]
在至少一个实施例中,一个或更多个处理器核心2102a-2102n包括对多线程同时进行的支持。在至少一个实施例中,系统代理核心2110包括用于在多线程处理期间协调和操作处理器核心2102a-2102n的组件。在至少一个实施例中,系统代理核心2110可以另外包括电源控制单元(pcu),该电源控制单元包括逻辑和组件以调节处理器核心2102a-2102n和图形处理器2108的一个或更多个电源状态。
[0272]
在至少一个实施例中,处理器2100另外包括图形处理器2108以执行图处理操作。在至少一个实施例中,图形处理器2108与共享高速缓存单元2106和包括一个或更多个集成存储器控制器2114的系统代理核心2110耦合。在至少一个实施例中,系统代理核心2110还
包括用于驱动图形处理器输出到一个或更多个耦合的显示器的显示器控制器2111。在至少一个实施例中,显示器控制器2111也可以是经由至少一个互连与图形处理器2108耦合的独立模块,或者可以集成在图形处理器2108内。
[0273]
在至少一个实施例中,基于环的互连单元2112用于耦合处理器2100的内部组件。在至少一个实施例中,可以使用替代性互连单元,例如点对点互连、交换互连或其他技术。在至少一个实施例中,图形处理器2108经由i/o链路2113与环形互连2112耦合。
[0274]
在至少一个实施例中,i/o链路2113代表多种i/o互连中的至少一种,包括促进各种处理器组件与高性能嵌入式存储器模块2118(例如edram模块)之间的通信的封装i/o互连。在至少一个实施例中,处理器核心2102a-2102n和图形处理器2108中的每一个使用嵌入式存储器模块2118作为共享的llc。
[0275]
在至少一个实施例中,处理器核心2102a-2102n是执行公共指令集架构的同质核心。在至少一个实施例中,处理器核心2102a-2102n在isa方面是异构的,其中一个或更多个处理器核心2102a-2102n执行公共指令集,而一个或更多个其他处理器核心2102a-2102n执行公共指令集或不同指令集的子集。在至少一个实施例中,就微架构而言,处理器核心2102a-2102n是异构的,其中具有相对较高功耗的一个或更多个核心与具有较低功耗的一个或更多个功率核心耦合。在至少一个实施例中,处理器2100可以实现在一个或更多个芯片上或被实现为soc集成电路。
[0276]
在至少一个实施例中,利用图21中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图21中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0277]
图22示出了根据所描述的至少一个实施例的图形处理器核心2200。在至少一个实施例中,图形处理器核心2200被包括在图形核心阵列内。在至少一个实施例中,图形处理器核心2200(有时称为核心切片)可以是模块化图形处理器内的一个或更多个图形核心。在至少一个实施例中,图形处理器核心2200是一个图形核心切片的示例,并且本文所述的图形处理器可以基于目标功率和性能包络线包括多个图形核心切片。在至少一个实施例中,每个图形核心2200可以包括与多个子核心2201a-2201f耦合的固定功能块2230,也称为子切片,其包括通用和固定功能逻辑的模块块。
[0278]
在至少一个实施例中,固定功能块2230包括几何/固定功能管线2236,例如,在较低性能和/或较低功率的图形处理器实施方式中,该几何/固定功能管线2236可以由图形处理器2200中的所有子核心共享。在至少一个实施例中,几何/固定功能管线2236包括3d固定功能管线、视频前端单元,线程产生器和线程分派器以及管理统一返回缓冲区的统一返回缓冲区管理器。
[0279]
在至少一个实施例中,固定功能块2230还包括图形soc接口2237、图形微控制器2238和媒体管线2239。图形soc接口2237提供了图形核心2200以及soc集成电路系统中的其他处理器核心之间的接口。在至少一个实施例中,图形微控制器2238是可编程子处理器,其可配置为管理图形处理器2200的各种功能,包括线程分派、调度和抢占。在至少一个实施例中,媒体管线2239包括有助于对包括图像和视频数据的多媒体数据进行解码、编码、预处理和/或后处理的逻辑。在至少一个实施例中,媒体管线2239经由对子核心2201-2201f内的计算或采样逻辑的请求来实现媒体操作。
[0280]
在至少一个实施例中,soc接口2237使图形核心2200能够与通用应用处理器核心(例如,cpu)和/或soc内的其他组件通信,包括存储器层次结构元素,诸如共享的llc存储器、系统ram和/或嵌入式片上或封装dram。在至少一个实施例中,soc接口2237还可以使得能够与soc内的固定功能设备(例如,相机成像管线)进行通信,并且使得能够使用和/或实现可以在图形核心2200和soc内部的cpu之间共享的全局存储器原子。在至少一个实施例中,soc接口2237还可以实现用于图形核心2200的电源管理控制,并且启用图形核心2200的时钟域与soc内的其他时钟域之间的接口。在至少一个实施例中,soc接口2237使得能够从命令流转化器和全局线程分派器接收命令缓冲区,其配置为向图形处理器内的一个或更多个图形核心中的每一个提供命令和指令。在至少一个实施例中,当要执行媒体操作时,可以将命令和指令分派给媒体管线2239,或者当要执行图处理操作时,可以将其分配给几何形状和固定功能管线(例如,几何形状和固定功能管线2236、几何形状和固定功能管线2214)。
[0281]
在至少一个实施例中,图形微控制器2238可以配置为对图形核心2200执行各种调度和管理任务。在至少一个实施例中,图形微控制器2238可以在子核心2201a-2201f中的执行单元(eu)阵列2202a-2202f、2204a-2204f内的各种图形并行引擎上执行图和/或计算工作负载调度。在至少一个实施例中,在包括图形核心2200的soc的cpu核心上执行的主机软件可以提交多个图形处理器门铃之一的工作负载,其调用适当的图形引擎上的调度操作。在至少一个实施例中,调度操作包括确定接下来要运行哪个工作负载、将工作负载提交给命令流转化器、抢先在引擎上运行的现有工作负载、监控工作负载的进度以及在工作负载完成时通知主机软件。在至少一个实施例中,图形微控制器2238还可以促进图形核心2200的低功率或空闲状态,从而为图形核心2200提供在图形核心2200内独立于操作系统和/或系统上的图形驱动器软件的跨低功率状态转换的保存和恢复寄存器的能力。
[0282]
在至少一个实施例中,图形核心2200可以具有比所示的子核心2201a-2201f更多或更少的子核心,达n个模块化子核心。对于每组n个子核心,在至少一个实施例中,图形核心2200还可以包括共享功能逻辑2210、共享和/或高速缓存存储器2212、几何/固定功能管线2214以及附加的固定功能逻辑2216以加速各种图形和计算处理操作。在至少一个实施例中,共享功能逻辑2210可以包括可由图形核心2200内的每个n个子核心共享的逻辑单元(例如,采样器、数学和/或线程间通信逻辑)。共享和/或高速缓存存储器2212可以是图形核心2200内的n个子核心2201a-2201f的llc,并且还可以用作可由多个子核心访问的共享存储器。在至少一个实施例中,可以包括几何/固定功能管线2214来代替固定功能块2230内的几何/固定功能管线2236,并且可以包括相同或相似的逻辑单元。
[0283]
在至少一个实施例中,图形核心2200包括附加的固定功能逻辑2216,其可以包括供图形核心2200使用的各种固定功能加速逻辑。在至少一个实施例中,附加的固定功能逻辑2216包括用于仅位置着色中使用的附加的几何管线。在仅位置着色中,存在至少两个几何管线,而在几何/固定功能管线2216、2236内的完整几何管线和剔除管线中,其是可以包括在附加的固定功能逻辑2216中的附加几何管线。在至少一个实施例中,剔除管线是完整几何管线的修整版。在至少一个实施例中,完整管线和剔除管线可以执行应用程序的不同实例,每个实例具有单独的环境。在至少一个实施例中,仅位置着色可以隐藏被丢弃的三角形的长剔除运行,从而在某些情况下可以更早地完成着色。例如,在至少一个实施例中,附加固定功能逻辑2216中的剔除管线逻辑可以与主应用程序并行执行位置着色器,并且通常
比完整管线更快地生成关键结果,因为剔除管线获取并遮蔽顶点的位置属性,无需执行光栅化和将像素渲染到帧缓冲区。在至少一个实施例中,剔除管线可以使用生成的临界结果来计算所有三角形的可见性信息,而与这些三角形是否被剔除无关。在至少一个实施例中,完整管线(在这种情况下可以称为重播管线)可以消耗可见性信息来跳过剔除的三角形以仅遮盖最终传递到光栅化阶段的可见三角形。
[0284]
在至少一个实施例中,附加的固定功能逻辑2216还可包括通用目标处理加速逻辑,例如固定功能矩阵乘法逻辑,用于实现减速cuad程序。
[0285]
在至少一个实施例中,在每个图形子核心2201a-2201f内包括一组执行资源,其可用于响应于图形管线、媒体管线或着色器程序的请求来执行图、媒体和计算操作。在至少一个实施例中,图形子核心2201a-2201f包括多个eu阵列2202a-2202f、2204a-2204f,线程分派和线程间通信(td/ic)逻辑2203a-2203f,3d(例如,纹理)采样器2205a-2205f,媒体采样器2206a-2206f,着色器处理器2207a-2207f和共享本地存储器(slm)2208a-2208f。eu阵列2202a-2202f、2204a-2204f每个都包含多个执行单元,这些执行单元是gugpu,能够为图形、媒体或计算操作提供服务,执行浮点和整数/定点逻辑运算,包括图形、媒体或计算着色器程序。在至少一个实施例中,td/ic逻辑2203a-2203f为子核心内的执行单元执行本地线程分派和线程控制操作,并促进在子核心的执行单元上执行的线程之间的通信。在至少一个实施例中,3d采样器2205a-2205f可以将与纹理或其他3d图形相关的数据读取到存储器中。在至少一个实施例中,3d采样器可以基于与给定纹理相关联的配置的采样状态和纹理格式来不同地读取纹理数据。在至少一个实施例中,媒体采样器2206a-2206f可以基于与媒体数据相关联的类型和格式来执行类似的读取操作。在至少一个实施例中,每个图形子核心2201a-2201f可以可替代地包括统一的3d和媒体采样器。在至少一个实施例中,在每个子核心2201a-2201f内的执行单元上执行的线程可以利用每个子核心内的共享本地存储器2208a-2208f,以使在线程组内执行的线程能够使用片上存储器的公共池来执行。
[0286]
在至少一个实施例中,利用图22中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图22中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0287]
图23示出了根据至少一个实施例的并行处理单元(“ppu”)2300。在至少一个实施例中,ppu 2300配置有机器可读代码,该机器可读代码如果由ppu 2300执行,则使得ppu 2300执行贯穿本文描述的一些或全部过程和技术。在至少一个实施例中,ppu 2300是在一个或更多个集成电路设备上实现的多线程处理器,并且利用多线程作为被设计为处理在多个线程上并行执行的计算机可读指令(也称为机器可读指令或简单的指令)的延迟隐藏技术。在至少一个实施例中,线程是指执行线程,并且是被配置为由ppu 2300执行的一组指令的实例。在至少一个实施例中,ppu 2300是图形处理单元(“gpu”),图形处理单元配置为实现用于处理三维(“3d”)图形数据的图形渲染管线,以便生成用于在显示设备(诸如lcd设备)上显示的二维(“2d”)图像数据。在至少一个实施例中,ppu 2300用于执行计算,诸如线性代数运算和机器学习运算。图23仅出于说明性目的示出了示例并行处理器,并且应被解释为在至少一个实施例中实现的处理器架构的非限制性示例。
[0288]
在至少一个实施例中,一个或更多个ppu 2300配置成加速高性能计算(“hpc”)、数据中心和机器学习应用程序。在至少一个实施例中,一个或更多个ppu 2300配置成加速
cuda程序。在至少一个实施例中,ppu2300包括但不限于i/o单元2306、前端单元2310、调度器单元2312、工作分配单元2314、集线器2316、交叉开关(“xbar”)2320、一个或更多个通用处理集群(“gpc”)2318和一个或更多个分区单元(“存储器分区单元”)2322。在至少一个实施例中,ppu 2300通过一个或更多个高速gpu互连(“gpu互连”)2308连接到主机处理器或其他ppu 2300。在至少一个实施例中,ppu 2300通过系统总线或互连2302连接到主机处理器或其他外围设备。在一实施例中,ppu 2300连接到包括一个或更多个存储器设备(“存储器”)2304的本地存储器。在至少一个实施例中,存储器设备2304包括但不限于一个或更多个动态随机存取存储器(“dram”)设备。在至少一个实施例中,一个或更多个dram设备配置和/或可配置为高带宽存储器(“hbm”)子系统,并且在每个设备内堆叠有多个dram管芯。
[0289]
在至少一个实施例中,高速gpu互连2308可以指代系统使用其来进行缩放的基于线的多通道通信链路,并包括与一个或更多个cpu结合的一个或更多个ppu 2300(“cpu”),支持ppu 2300和cpu之间的高速缓存一致性以及cpu主控。在至少一个实施例中,高速gpu互连2308通过集线器2316将数据和/或命令传输到ppu 2300的其他单元,例如一个或更多个复制引擎、视频编码器、视频解码器、电源管理单元和/或在图23中可能未明确示出的其他组件。
[0290]
在至少一个实施例中,i/o单元2306配置为通过系统总线2302从主机处理器(图23中未示出)发送和接收通信(例如,命令、数据)。在至少一个实施例中,i/o单元2306直接通过系统总线2302或通过一个或更多个中间设备(例如内存桥)与主机处理器通信。在至少一个实施例中,i/o单元2306可以经由系统总线2302与一个或更多个其他处理器(例如一个或更多个ppu 2300)通信。在至少一个实施例中,i/o单元2306实现pcie接口,用于通过pcie总线进行通信。在至少一个实施例中,i/o单元2306实现用于与外部设备通信的接口。
[0291]
在至少一个实施例中,i/o单元2306对经由系统总线2302接收的分组进行解码。在至少一个实施例中,至少一些分组表示被配置为使ppu 2300执行各种操作的命令。在至少一个实施例中,i/o单元2306如命令所指定的那样将解码的命令发送到ppu 2300的各种其他单元。在至少一个实施例中,命令被发送到前端单元2310和/或被发送到集线器2316或ppu 2300的其他单元,例如一个或更多个复制引擎、视频编码器、视频解码器、电源管理单元等(图23中未明确示出)。在至少一个实施例中,i/o单元2306配置为在ppu 2300的各种逻辑单元之间路由通信。
[0292]
在至少一个实施例中,由主机处理器执行的程序在缓冲区中对命令流进行编码,该缓冲区将工作负载提供给ppu 2300以进行处理。在至少一个实施例中,工作负载包括指令和要由那些指令处理的数据。在至少一个实施例中,缓冲区是可由主机处理器和ppu 2300两者访问(例如,读/写)的存储器中的区域—主机接口单元可以配置为访问经由i/o单元2306通过系统总线2302传输的存储器请求连接到系统总线2302的系统存储器中的缓冲区。在至少一个实施例中,主机处理器将命令流写入缓冲区,然后将指示命令流开始的指针发送给ppu 2300,使得前端单元2310接收指向一个或更多个命令流指针并管理一个或更多个命令流,从命令流中读取命令并将命令转发到ppu 2300的各个单元。
[0293]
在至少一个实施例中,前端单元2310耦合到调度器单元2312,该调度器单元2312配置各种gpc 2318以处理由一个或更多个命令流定义的任务。在至少一个实施例中,调度器单元2312配置为跟踪与调度器单元2312管理的各种任务有关的状态信息,其中状态信息
可以指示任务被分配给哪个gpc 2318,任务是活跃的还是非活跃的,与任务相关联的优先级等等。在至少一个实施例中,调度器单元2312管理在一个或更多个gpc 2318上执行的多个任务。
[0294]
在至少一个实施例中,调度器单元2312耦合到工作分配单元2314,该工作分配单元2314配置为分派任务以在gpc 2318上执行。在至少一个实施例中,工作分配单元2314跟踪从调度器单元2312接收到的多个调度任务并且工作分配单元2314管理每个gpc 2318的待处理任务池和活跃任务池。在至少一个实施例中,待处理任务池包括多个时隙(例如32个时隙),这些时隙包含分配给要由特定的gpc 2318处理的任务;活跃任务池可包括用于由gpc 2318主动处理的任务的多个时隙(例如4个时隙),以使随着gpc 2318中的一个完成任务的执行,该任务将从gpc 2318的活动任务池中逐出,并且从待处理任务池中选择其他任务之一,并安排其在gpc2318上执行。在至少一个实施例中,如果活跃任务在gpc 2318上处于空闲状态,例如在等待数据依赖性解决时,则活跃任务从gpc 2318中驱逐并返回到待处理任务池,同时选择了待处理任务池中的另一个任务并调度在gpc 2318上执行。
[0295]
在至少一个实施例中,工作分配单元2314经由xbar 2320与一个或更多个gpc 2318通信。在至少一个实施例中,xbar 2320是互连网络,其将ppu 2300的许多单元耦合到ppu 2300的其他单元,并且可以配置为将工作分配单元2314耦合到特定的gpc2318。在至少一个实施例中,一个或更多个ppu 2300的其他单元也可以通过集线器2316连接到xbar 2320。
[0296]
在至少一个实施例中,任务由调度器单元2312管理,并由工作分配单元2314分配给gpc 2318之一。gpc 2318配置为处理任务并产生结果。在至少一个实施例中,结果可以由gpc 2318中的其他任务消耗,通过xbar2320路由到不同的gpc 2318或存储在存储器2304中。在至少一个实施例中,结果可以通过分区单元2322写到存储器2304中,其实现了用于向存储器2304写入数据或从存储器2304读取数据的存储器接口。在至少一个实施例中,结果可以经由高速gpu互连2308传输到另一ppu 2300或cpu。在至少一个实施例中,ppu 2300包括但不限于u个分区单元2322,其等于耦合到ppu 2300的分离且不同的存储器设备2304的数量。
[0297]
在至少一个实施例中,主机处理器执行驱动器核心,该驱动器核心实现应用程序编程接口(api),该应用程序编程接口使在主机处理器上执行的一个或更多个应用程序能够调度操作以在ppu 2300上执行。在一个实施例中,多个计算应用由ppu 2300同时执行,并且ppu 2300为多个计算应用程序提供隔离、服务质量(“qos”)和独立的地址空间。在至少一个实施例中,应用程序生成指令(例如,以api调用的形式),该指令使驱动器核心生成一个或更多个任务以供ppu 2300执行,并且驱动器核心将任务输出至由ppu 2300处理的一个或更多个流。在至少一个实施例中,每个任务包括一个或更多个相关线程组,其可以被称为线程束(warp)。在至少一个实施例中,线程束包括可以并行执行的多个相关线程(例如32个线程)。在至少一个实施例中,协作线程可以指代多个线程,包括用于执行任务并且通过共享存储器交换数据的指令。
[0298]
在至少一个实施例中,利用图23中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图23中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0299]
图24示出了根据至少一个实施例的gpc 2400。在至少一个实施例中,gpc 2400是图23的gpc 2318。在至少一个实施例中,每个gpc 2400包括但不限于用于处理任务的多个硬件单元,并且每个gpc 2400包括但不限于管线管理器2402、预光栅操作单元(“prop”)2404、光栅引擎2408、工作分配交叉开关(“wdx”)2416、存储器管理单元(“mmu”)2418、一个或更多个数据处理集群(“dpc”)2406,以及部件的任何合适组合。
[0300]
在至少一个实施例中,gpc 2400的操作由管线管理器2402控制。在至少一个实施例中,管线管理器2402管理一个或更多个dpc 2406的配置,以处理分配给gpc 2400的任务。在至少一个实施例中,管线管理器2402配置一个或更多个dpc 2406中的至少一个以实现图形渲染管线的至少一部分。在至少一个实施例中,dpc 2406配置为在可编程流式多处理器(“sm”)2414上执行顶点着色器程序。在至少一个实施例中,管线管理器2402配置为将从工作分配单元接收的数据包路由到gpc 2400内的适当逻辑单元,以及在至少一个实施例中,可以将一些数据包路由到prop 2404和/或光栅引擎2408中的固定功能硬件单元,而可以将其他数据包路由到dpc 2406以由原始引擎2412或sm 2414进行处理。在至少一个实施例中,管线管理器2402配置dpc 2406中的至少一个以实现神经网络模型和/或计算管线。在至少一个实施例中,管线管理器2402配置dpc 2406中的至少一个以执行cuda程序的至少一部分。
[0301]
在至少一个实施例中,prop单元2404配置为将由光栅引擎2408和dpc 2406生成的数据路由到分区单元中的光栅操作(“rop”)单元,例如上面结合图23更详细描述的存储器分区单元2322等。在至少一个实施例中,prop单元2404配置为执行用于颜色混合的优化、组织像素数据、执行地址转换等等。在至少一个实施例中,光栅引擎2408包括但不限于配置为执行各种光栅操作的多个固定功能硬件单元,并且在至少一个实施例中,光栅引擎2408包括但不限于设置引擎、粗光栅引擎、剔除引擎、裁剪引擎、精细光栅引擎、图块聚合引擎及其任意合适的组合。在至少一个实施例中,设置引擎接收变换后的顶点并生成与由顶点定义的几何图元相关联的平面方程;平面方程式被传送到粗光栅引擎以生成基本图元的覆盖信息(例如,图块的x、y覆盖范围掩码);粗光栅引擎的输出将传输到剔除引擎,在剔除引擎中与z测试失败的图元相关联的片段将被剔除,并传输到剪切引擎,在剪切引擎中剪切位于视锥范围之外的片段。在至少一个实施例中,将经过裁剪和剔除的片段传递给精细光栅引擎,以基于设置引擎生成的平面方程式生成像素片段的属性。在至少一个实施例中,光栅引擎2408的输出包括将由任何适当的实体(例如,由在dpc 2406内实现的片段着色器)处理的片段。
[0302]
在至少一个实施例中,包括在gpc 2400中的每个dpc 2406包括但不限于m管线控制器(“mpc”)2410;图元引擎2412;一个或更多个sm 2414;及其任何合适的组合。在至少一个实施例中,mpc 2410控制dpc 2406的操作,将从管线管理器2402接收的分组路由到dpc 2406中的适当单元。在至少一个实施例中,将与顶点相关联的分组路由到图元引擎2412,图元引擎2412配置为从存储器中获取与顶点关联的顶点属性;相反,可以将与着色器程序相关联的数据包发送到sm 2414。
[0303]
在至少一个实施例中,sm 2414包括但不限于可编程流式处理器,其配置为处理由多个线程表示的任务。在至少一个实施例中,sm 2414是多线程的并且配置为同时执行来自特定线程组的多个线程(例如32个线程),并且实现单指令、多数据(“simd”)架构,其中将一
组线程(例如,线程束)中的每个线程配置为基于相同的指令集来处理不同的数据集。在至少一个实施例中,线程组中的所有线程执行相同的指令。在至少一个实施例中,sm 2414实施单指令、多线程(“simt”)架构,其中一组线程中的每个线程配置为基于相同的指令集来处理不同的数据集,但是其中线程组中的各个线程允许在执行期间发散。在至少一个实施例中,为每个线程束维护程序计数器、调用栈和执行状态,从而当线程束中的线程发散时,实现线程束和线程束内的串行执行之间的并发性。在另一个实施例中,为每个单独的线程维护程序计数器、调用栈和执行状态,从而使得在线程束内和线程束之间的所有线程之间具有相等的并发性。在至少一个实施例中,为每个单独的线程维持执行状态,并且可以收敛并并行地执行执行相同指令的线程以提高效率。下面结合图25更详细地描述sm 2414的至少一个实施例。
[0304]
在至少一个实施例中,mmu 2418在gpc 2400和存储器分区单元(例如,图23的分区单元2322)之间提供接口,并且mmu 2418提供虚拟地址到物理地址的转换、存储器保护以及存储器请求的仲裁。在至少一个实施例中,mmu 2418提供一个或更多个转换后备缓冲区(“tlb”),用于执行虚拟地址到存储器中的物理地址的转换。
[0305]
在至少一个实施例中,利用图24中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图24中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0306]
图25示出了根据至少一个实施例的流式多处理器(“sm”)2500。在至少一个实施例中,sm 2500是图24的sm 2414。在至少一个实施例中,sm 2500包括但不限于指令高速缓存2502;一个或更多个调度器单元2504;寄存器文件2508;一个或更多个处理核心(“核心”)2510;一个或更多个特殊功能单元(“sfu”)2512;一个或更多个加载/存储单元(“lsu”)2514;互连网络2516;共享存储器/一级(“l1”)高速缓存2518;及其任何合适的组合。在至少一个实施例中,工作分配单元调度任务以在并行处理单元(“ppu”)的通用处理集群(“gpc”)上执行,并且每个任务被分配给gpc内部的特定数据处理集群(“dpc”),并且如果任务与着色器程序相关联,则将任务分配给sm 2500之一。在至少一个实施例中,调度器单元2504从工作分配单元接收任务并管理分配给sm 2500的一个或更多个线程块的指令调度。在至少一个实施例中,调度器单元2504调度线程块以作为并行线程的线程束来执行,其中,每个线程块被分配至少一个线程束。在至少一个实施例中,每个线程束执行线程。在至少一个实施例中,调度器单元2504管理多个不同的线程块,将线程束分配给不同的线程块,然后在每个时钟周期内将来自多个不同的协作组的指令分派给各种功能单元(例如,处理核心2510、sfu 2512和lsu 2514)。
[0307]
在至少一个实施例中,“合作组”可以指用于组织通信线程组的编程模型,其允许开发人员表达线程正在通信的粒度,从而能够表达更丰富、更有效的并行分解。在至少一个实施例中,协作启动api支持线程块之间的同步以执行并行算法。在至少一个实施例中,常规编程模型的api提供了用于同步协作线程的单一、简单的构造:跨线程块的所有线程的屏障(例如,syncthreads()函数)。但是,在至少一个实施例中,程序员可以在小于线程块粒度的情形下来定义线程组,并在所定义的组内进行同步,以实现更高的性能、设计灵活性以及以集合组范围功能接口的形式实现软件重用。在至少一个实施例中,协作组使程序员能够以子块和多块粒度明确定义线程组,并执行集合操作,例如对协作组中的线程进行同步。
在至少一个实施例中,子块粒度与单个线程一样小。在至少一个实施例中,编程模型支持跨软件边界的干净组合,从而库和实用程序功能可以在其本地环境中安全地同步,而不必进行关于收敛的假设。在至少一个实施例中,协作组图元使协作并行的新图案成为可能,包括但不限于生产者-消费者并行,机会主义并行以及整个线程块网格上的全局同步。
[0308]
在至少一个实施例中,分派单元2506配置为将指令发送到功能单元中的一个或更多个,并且调度器单元2504包括但不限于两个分派单元2506,该两个分派单元2506使得来自相同线程束的两个不同指令能够在每个时钟周期被分派。在至少一个实施例中,每个调度器单元2504包括单个分派单元2506或附加分派单元2506。
[0309]
在至少一个实施例中,每个sm 2500在至少一个实施例中包括但不限于寄存器文件2508,该寄存器文件2508为sm 2500的功能单元提供了一组寄存器。在至少一个实施例中,寄存器文件2508在每个功能单元之间划分,从而为每个功能单元分配寄存器文件2508的专用部分。在至少一个实施例中,寄存器文件2508在由sm 2500执行的不同线程束之间划分,并且寄存器文件2508为连接到功能单元的数据路径的操作数提供临时存储。在至少一个实施例中,每个sm 2500包括但不限于多个l个处理核心2510。在至少一个实施例中,sm 2500包括但不限于大量(例如128个或更多)不同的处理核心2510。在至少一个实施例中,每个处理核心2510在至少一个实施例中包括但不限于全管线、单精度、双精度和/或混合精度处理单元,其包括但不限于浮点算术逻辑单元和整数算术逻辑单元。在至少一个实施例中,浮点算术逻辑单元实现用于浮点算术的ieee 754-2008标准。在至少一个实施例中,处理核心2510包括但不限于64个单精度(32位)浮点核心、64个整数核心、32个双精度(64位)浮点核心和8个张量核心。
[0310]
在至少一个实施例中,张量核心配置为执行矩阵运算。在至少一个实施例中,一个或更多个张量核心包括在处理核心2510中。在至少一个实施例中,张量核心配置为执行深度学习矩阵算术,例如用于神经网络训练和推理的卷积运算。在至少一个实施例中,每个张量核心在4
×
4矩阵上操作并且执行矩阵乘法和累加运算d=a
×
b+c,其中a、b、c和d是4
×
4矩阵。
[0311]
在至少一个实施例中,矩阵乘法输入a和b是16位浮点矩阵,并且累加矩阵c和d是16位浮点或32位浮点矩阵。在至少一个实施例中,张量核心对16位浮点输入数据进行32位浮点累加运算。在至少一个实施例中,16位浮点乘法使用64个运算,并得到全精度乘积,然后使用32位浮点加法与其他中间乘积累加起来,以进行4x4x4矩阵乘法。在至少一个实施例中,张量核心用于执行由这些较小的元件构成的更大的二维或更高维度的矩阵运算。在至少一个实施例中,api(诸如cuda-c++api)公开专门的矩阵加载、矩阵乘法和累加以及矩阵存储操作,以有效地使用来自cuda-c++程序的张量核心。在至少一个实施例中,在cuda级别,线程束级别接口假定跨越所有32个线程束线程的16
×
16大小的矩阵。
[0312]
在至少一个实施例中,每个sm 2500包括但不限于执行特殊功能(例如,属性评估、倒数平方根等)的m个sfu 2512。在至少一个实施例中,sfu 2512包括但不限于配置为遍历分层树数据结构的树遍历单元。在至少一个实施例中,sfu 2512包括但不限于配置为执行纹理映射过滤操作的纹理单元。在至少一个实施例中,纹理单元配置为从存储器中加载纹理映射(例如,纹理像素的2d阵列)和采样纹理映射,以产生采样的纹理值以供由sm 2500执行的着色器程序使用。在至少一个实施例中,将纹理映射存储在共享存储器/l1高速缓存
2518中。在至少一个实施例中,纹理单元使用mip映射(mip-maps)(例如,细节级别不同的纹理映射)来实现纹理操作(诸如过滤操作)。在至少一个实施例中,每个sm 2500包括但不限于两个纹理单元。
[0313]
在至少一个实施例中,每个sm 2500包括但不限于实现共享存储器/l1高速缓存2518与寄存器文件2508之间的加载和存储操作的n个lsu 2514。在至少一个实施例中,每个sm 2500包括但不限于互连网络2516,互连网络2516将每个功能单元连接到寄存器文件2508,并且lsu 2514连接到寄存器文件2508和共享存储器/l1高速缓存2518。在至少一个实施例中,互连网络2516是交叉开关,其可以配置为将任何功能单元连接到寄存器文件2508中的任何寄存器,并且将lsu 2514连接到寄存器文件2508和共享存储器/l1高速缓存2518中的存储器位置。
[0314]
在至少一个实施例中,共享存储器/l1高速缓存2518是片上存储器的阵列,其在至少一个实施例中允许sm 2500与图元引擎之间以及sm 2500中的线程之间的数据存储和通信。在至少一个实施例中,共享存储器/l1高速缓存2518包括但不限于128kb的存储容量,并且位于从sm 2500到分区单元的路径中。在至少一个实施例中,共享存储器/l1高速缓存2518在至少一个实施例中用于高速缓存读取和写入。在至少一个实施例中,共享存储器/l1高速缓存2518、l2高速缓存和存储器中的一个或更多个是后备存储。
[0315]
在至少一个实施例中,将数据高速缓存和共享存储器功能组合到单个存储器块中,为两种类型的存储器访问提供了改进的性能。在至少一个实施例中,容量由不使用共享存储器的程序使用或将其用作高速缓存,例如如果共享存储器配置为使用一半容量,则纹理和加载/存储操作可以使用剩余容量。根据至少一个实施例,在共享存储器/l1高速缓存2518内的集成使共享存储器/l1高速缓存2518能够用作用于流传输数据的高吞吐量管线,同时提供对频繁重用的数据的高带宽和低延迟访问。在至少一个实施例中,当配置用于通用并行计算时,与图形处理相比,可以使用更简单的配置。在至少一个实施例中,绕过固定功能gpu,从而创建了更加简单的编程模型。在至少一个实施例中,在通用并行计算配置中,工作分配单元直接将线程的块分配和分布给dpc。在至少一个实施例中,块中的线程执行相同的程序,在计算中使用唯一的线程id以确保每个线程生成唯一的结果,使用sm 2500执行程序并执行计算,使用共享存储器/l1高速缓存2518在线程之间进行通信,以及使用lsu 2514通过共享存储器/l1高速缓存2518和存储器分区单元来读写全局存储器。在至少一个实施例中,当被配置用于通用并行计算时,sm 2500向调度器单元2504写入可以用来在dpc上启动新工作的命令。
[0316]
在至少一个实施例中,ppu被包括在台式计算机、膝上型计算机、平板电脑、服务器、超级计算机、智能电话(例如,无线、手持设备)、pda、数码相机、车辆、头戴式显示器、手持式电子设备等中或与之耦合。在至少一个实施例中,ppu被实现在单个半导体衬底上。在至少一个实施例中,ppu与一个或更多个其他设备(例如附加的ppu、存储器、risccpu,mmu、数模转换器(“dac”)等)一起被包括在片上系统(“soc”)中。
[0317]
在至少一个实施例中,ppu可以被包括在包括一个或更多个存储设备的图形卡上。图形卡可以配置为与台式计算机主板上的pcie插槽相连接。在至少一个实施例中,ppu可以是包括在主板的芯片组中的集成gpu(“igpu”)。
[0318]
在至少一个实施例中,利用图25中所描绘的一个或更多个系统来执行api以引起
图形代码的描述性表示被生成。在至少一个实施例中,利用图25中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0319]
通用计算的软件构造
[0320]
以下各图阐述但不限于用于实现至少一个实施例的示例性软件构造。
[0321]
图26示出了根据至少一个实施例的编程平台的软件栈。在至少一个实施例中,编程平台是用于利用计算系统上的硬件来加速计算任务的平台。在至少一个实施例中,软件开发人员可以通过库、编译器指令和/或对编程语言的扩展来访问编程平台。在至少一个实施例中,编程平台可以是但不限于cuda,radeon开放计算平台(“rocm”),opencl(由khronos group开发的opencl
tm
),sycl或intel one api。
[0322]
在至少一个实施例中,编程平台的软件栈2600为应用程序2601提供执行环境。在至少一个实施例中,应用程序2601可以包括能够在软件栈2600上启动的任何计算机软件。在至少一个实施例中,应用程序2601可以包括但不限于人工智能(“ai”)/机器学习(“ml”)应用程序,高性能计算(“hpc”)应用程序,虚拟桌面基础架构(“vdi”)或数据中心工作负载。
[0323]
在至少一个实施例中,应用程序2601和软件栈2600在硬件2607上运行。在至少一个实施例中,硬件2607可以包括一个或更多个gpu,cpu,fpga,ai引擎和/或支持编程平台的其他类型的计算设备。在至少一个实施例中,例如采用cuda,软件栈2600可以是厂商专用的,并且仅与来自特定厂商的设备兼容。在至少一个实施例中,例如在采用opencl中,软件栈2600可以与来自不同供应商的设备一起使用。在至少一个实施例中,硬件2607包括连接到一个或更多个设备的主机,该设备可经由应用程序编程接口(api)调用被访问以执行计算任务。在至少一个实施例中,与硬件2607内的主机相比,其可以包括但不限于cpu(但还可以包括计算设备)及其存储器,硬件2607内的设备可以包括但不限于gpu,fpga,ai引擎或其他计算设备(但还可以包括cpu)及其存储器。
[0324]
在至少一个实施例中,编程平台的软件栈2600包括但不限于多个库2603,运行时(runtime)2605和设备内核驱动器2606。在至少一个实施例中,库2603中的每个库可以包括可以由计算机程序使用并在软件开发期间利用的数据和编程代码。在至少一个实施例中,库2603可以包括但不限于预写的代码和子例程,类,值,类型规范,配置数据,文档,帮助数据和/或消息模板。在至少一个实施例中,库2603包括被优化用于在一种或更多种类型的设备上执行的函数。在至少一个实施例中,库2603可以包括但不限于用于在设备上执行数学、深度学习和/或其他类型的运算的函数。在至少一个实施例中,库2603与对应的api 2602相关联,api 2602可包括一个或更多个api,其暴露在库2603中实现的函数。
[0325]
在至少一个实施例中,将应用程序2601编写为源代码,该源代码被编译成可执行代码,如下面结合图31-33更详细讨论的。在至少一个实施例中,应用程序2601的可执行代码可以至少部分地在由软件栈2600提供的执行环境上运行。在至少一个实施例中,在应用程序2601的执行期间,可以得到需要在设备(与主机相比)上运行的代码。在这种情况下,在至少一个实施例中,可以调用运行时2605以在设备上加载和启动必需的代码。在至少一个实施例中,运行时2605可以包括能够支持应用程序2601的执行的任何技术上可行的运行时系统。
[0326]
在至少一个实施例中,运行时2605被实现为与对应的api(其被示为api 2604)相关联的一个或更多个运行时库。在至少一个实施例中,一个或更多个这样的运行时库可以
包括但不限于用于存储器管理,执行控制,设备管理,错误处理和/或同步等等的函数。在至少一个实施例中,存储器管理函数可以包括但不限于用于分配、解除分配和复制设备存储器以及在主机存储器和设备存储器之间传输数据的函数。在至少一个实施例中,执行控制函数可以包括但不限于在设备上启动函数(当函数是可从主机调用的全局函数时,有时称为“内核”)的函数,和用于在运行时库为要在设备上执行的给定函数维护的缓冲区中设置属性值的函数。
[0327]
在至少一个实施例中,可以任何技术上可行的方式来实现运行时库和相应的api 2604。在至少一个实施例中,一个(或任意数量的)api可以公开用于设备的细粒度控制的低级函数集,而另一(或任意数量的)api可以公开这样的较高级的函数集。在至少一个实施例中,可以在低级api之上构建高级运行时api。在至少一个实施例中,一个或更多个运行时api可以是在与语言无关的运行时api之上分层的特定于语言的api。
[0328]
在至少一个实施例中,设备内核驱动器2606被配置为促进与底层设备的通信。在至少一个实施例中,设备内核驱动器2606可以提供诸如api 2604之类的api和/或其他软件所依赖的低级函数。在至少一个实施例中,设备内核驱动器2606可以被配置为在运行时将中间表示(“ir”)代码编译成二进制代码。在至少一个实施例中,对于cuda,设备内核驱动器2606可以在运行时将非硬件专用的并行线程执行(“ptx”)ir代码编译为用于特定目标设备的二进制代码(高速缓存已编译的二进制代码),其有时也称为“最终”代码。在至少一个实施例中,这样做可以允许最终代码在目标设备上运行,而当源代码最初被编译为ptx代码时,该目标设备可能不存在。备选地,在至少一个实施例中,设备源代码可以离线地编译成二进制代码,而不需要设备内核驱动器2606在运行时编译ir代码。
[0329]
在至少一个实施例中,利用图26中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图26中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0330]
图27示出了根据至少一个实施例的图26的软件栈2600的cuda实现。在至少一个实施例中,可在其上启动应用程序2701的cuda软件栈2700包括cuda库2703,cuda运行时2705,cuda驱动器2707和设备内核驱动器2708。在至少一个实施例中,cuda软件栈2700在硬件2709上执行,该硬件2709可以包括支持cuda的gpu,其由加利福尼亚州圣克拉拉市的nvidia公司开发。
[0331]
在至少一个实施例中,应用程序2701、cuda运行时2705和设备内核驱动器2708可以分别执行与应用程序2601、运行时2605和设备内核驱动器2606类似的功能,以上结合图26对其进行了描述。在至少一个实施例中,cuda驱动器2707包括实现cuda驱动器api 2706的库(libcuda.so)。在至少一个实施例中,类似于由cuda运行时库(cudart)实现的cuda运行时api 2704,cuda驱动器api 2706可以公开但不限于用于存储器管理、执行控制、设备管理、错误处理、同步和/或图形互操作性等的函数。在至少一个实施例中,cuda驱动器api 2706与cuda运行时api 2704的不同之处在于,cuda运行时api 2704通过提供隐式初始化、上下文(类似于进程)管理和模块(类似于动态加载的库)管理来简化设备代码管理。与高级cuda运行时api 2704相反,在至少一个实施例中,cuda驱动器api 2706是提供对设备的更细粒度控制的低级api,特别是关于上下文和模块加载。在至少一个实施例中,cuda驱动器api 2706可以公开没有由cuda运行时api 2704公开的用于上下文管理的函数。在至少一个
实施例中,cuda驱动器api 2706也与语言无关,并且除了支持cuda运行时api2704之外,还支持例如opencl。此外,在至少一个实施例中,包括cuda运行时2705在内的开发库可被视为与驱动器组件分离,包括用户模式的cuda驱动器2707和内核模式的设备驱动器2708(有时也称为“显示”驱动器)。
[0332]
在至少一个实施例中,cuda库2703可以包括但不限于数学库,深度学习库,并行算法库和/或信号/图像/视频处理库,并行计算应用程序(例如应用程序2701)可以利用这些库。在至少一个实施例中,cuda库2703可包括数学库,例如cublas库,其是用于执行线性代数运算的基本线性代数子程序(“blas”)的实现;用于计算快速傅立叶变换(“fft”)的cufft库,以及用于生成随机数的curand库等。在至少一个实施例中,cuda库2703可以包括深度学习库,诸如用于深度神经网络的基元的cudnn库和用于高性能深度学习推理的tensorrt平台等等。
[0333]
在至少一个实施例中,利用图27中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图27中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0334]
图28示出了根据至少一个实施例的图26的软件栈2600的rocm实现。在至少一个实施例中,可在其上启动应用程序2801的rocm软件栈2800包括语言运行时2803,系统运行时2805,thunk 2807和rocm内核驱动器2808。在至少一个实施例中,rocm软件栈2800在硬件2809上执行,硬件2809可以包括支持rocm的gpu,其由加利福尼亚州圣克拉拉市的amd公司开发。
[0335]
在至少一个实施例中,应用程序2801可以执行与以上结合图26讨论的应用程序2601类似的功能。另外,在至少一个实施例中,语言运行时2803和系统运行时2805可以执行与以上结合图26讨论的运行时2605类似的功能。在至少一个实施例中,语言运行时2803和系统运行时2805的不同之处在于,系统运行时2805是实现rocr系统运行时api 2804并利用异构系统架构(“hsa”)运行时api的语言无关运行时。在至少一个实施例中,hsa运行时api是一种瘦用户模式api,它公开接口以供访问和与amdgpu交互,包括用于存储器管理、通过架构分派内核的执行控制、错误处理、系统和代理信息以及运行时初始化和关闭等的函数。在至少一个实施例中,与系统运行时2805相比,语言运行时2803是rocr系统运行时api 2804之上分层的特定于语言的运行时api 2802的实现。在至少一个实施例中,语言运行时api可以包括但不限于可移植异构计算接口(“hip”)语言运行时api,异构计算编译器(“hcc”)语言运行时api或opencl api等等。特别是,hip语言是c++编程语言的扩展,具有cuda机制的功能相似版本,并且在至少一个实施例中,hip语言运行时api包括与以上结合图27讨论的cuda运行时api 2704相似的函数,例如用于存储器管理、执行控制、设备管理、错误处理和同步等的函数。
[0336]
在至少一个实施例中,thunk(roct)2807是可用于与底层rocm驱动器2808交互的接口2806。在至少一个实施例中,rocm驱动器2808是rock驱动器,其是amdgpu驱动器和hsa内核驱动器(amdkfd)的组合。在至少一个实施例中,amdgpu驱动器是由amd开发的用于gpu的设备内核驱动器,其执行与以上结合图26讨论的设备内核驱动器2606类似的功能。在至少一个实施例中,hsa内核驱动器是允许不同类型的处理器经由硬件特征更有效地共享系统资源的驱动器。
[0337]
在至少一个实施例中,各种库(未示出)可以被包括在语言运行时2803上方的rocm软件栈2800中,并且提供与以上结合图27讨论的cuda库2703相似的功能。在至少一个实施例中,各种库可以包括但不限于数学、深度学习和/或其他库,例如实现与cuda cublas类似的函数的hipblas库,类似于cuda cufft用于计算fft的rocfft库等。
[0338]
在至少一个实施例中,利用图28中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图28中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0339]
图29示出了根据至少一个实施例的图26的软件栈2600的opencl实现。在至少一个实施例中,可以在其上启动应用程序2901的opencl软件栈2900包括opencl框架2910,opencl运行时2906和驱动器2907。在至少一个实施例中,opencl软件栈2900在不是特定于供应商的硬件2709上执行。在至少一个实施例中,由于由不同厂商开发的设备支持opencl,因此可能需要特定的opencl驱动器才能与来自此类厂商的硬件进行互操作。
[0340]
在至少一个实施例中,应用程序2901,opencl运行时2906,设备内核驱动器2907和硬件2908可以分别执行与上面结合图26讨论的应用程序2601、运行时2605、设备内核驱动器2606和硬件2607类似的功能。在至少一个实施例中,应用程序2901还包括具有将在设备上执行的代码的opencl内核2902。
[0341]
在至少一个实施例中,opencl定义了一种“平台”,其允许主机控制连接到该主机的设备。在至少一个实施例中,opencl框架提供平台层api和运行时api,示出为平台api 2903和运行时api 2905。在至少一个实施例中,运行时api 2905使用上下文来管理设备上内核的执行。在至少一个实施例中,每个标识的设备可以与各自的上下文相关联,运行时api2905可以使用该上下文来管理该设备的命令队列、程序对象和内核对象、共享存储器对象等。在至少一个实施例中,平台api 2903公开了允许设备上下文用于选择和初始化设备,经由命令队列将工作提交给设备,以及使得能够进行来自和去往设备的数据传输等的函数。另外,在至少一个实施例中,opencl框架提供各种内置函数(未示出),包括数学函数、关系函数和图像处理函数等。
[0342]
在至少一个实施例中,编译器2904也被包括在opencl框架2910中。在至少一个实施例中,源代码可以在执行应用程序之前被离线编译或者在执行应用程序期间被在线编译。与cuda和rocm相反,至少一个实施例中的opencl应用程序可以由编译器2904在线编译,编译器2904被包括以代表可以用于将源代码和/或ir代码(例如标准可移植中间表示(“spir-v”)代码)编译为二进制代码的任意数量的编译器。可替代地,在至少一个实施例中,可以在执行这样的应用程序之前离线编译opencl应用程序。
[0343]
在至少一个实施例中,利用图29中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图29中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0344]
图30示出了根据至少一个实施例的由编程平台支持的软件。在至少一个实施例中,编程平台3004被配置为支持应用程序3000可以依赖的各种编程模型3003,中间件和/或库3002以及框架3001。在至少一个实施例中,应用程序3000可以是使用例如深度学习框架(例如,mxnet,pytorch或tensorflow)实现的ai/ml应用,其可以依赖于诸如cudnn,nvidia collective communications library(“nccl”)”和/或nvidia开发人员数据加载库
(“dali”)cuda库之类的库,以在底层硬件上提供加速的计算。
[0345]
在至少一个实施例中,编程平台3004可以是以上分别结合图27、图28和图29描述的cuda、rocm或opencl平台之一。在至少一个实施例中,编程平台3004支持多个编程模型3003,其是底层计算系统的抽象,其允许算法和数据结构的表达。在至少一个实施例中,编程模型3003可以暴露底层硬件的特征以便改善性能。在至少一个实施例中,编程模型3003可以包括但不限于cuda,hip,opencl,c++加速大规模并行性(“c++amp”),开放多处理(“openmp”),开放加速器(“openacc”)和/或vulcan计算(vulcan compute)。
[0346]
在至少一个实施例中,库和/或中间件3002提供编程模型3004的抽象的实现。在至少一个实施例中,这样的库包括可由计算机程序使用并在软件开发期间利用的数据和编程代码。在至少一个实施例中,除了可以从编程平台3004获得的那些之外,这样的中间件还包括向应用程序提供服务的软件。在至少一个实施例中,库和/或中间件3002可以包括但不限于cublas、cufft、curand和其他cuda库,或rocblas、rocfft、rocrand和其他rocm库。另外,在至少一个实施例中,库和/或中间件3002可以包括nccl和rocm通信集合库(“rccl”)库,其提供用于gpu的通信例程,用于深度学习加速的miopen库和/或用于线性代数、矩阵和向量运算、几何变换、数值求解器以及相关算法的本征库。
[0347]
在至少一个实施例中,应用程序框架3001依赖于库和/或中间件3002。在至少一个实施例中,每个应用程序框架3001是用于实现应用软件的标准结构的软件框架。回到上面讨论的ai/ml示例,在至少一个实施例中,可以使用框架(诸如caffe,caffe2,tensorflow,keras,pytorch或mxnet深度学习框架)来实现ai/ml应用。
[0348]
在至少一个实施例中,利用图30中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图30中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0349]
图31示出了根据至少一个实施例的编译代码以在图26-29的编程平台之一上执行。在至少一个实施例中,编译器3101接收源代码3100,其包括主机代码以及设备代码两者。在至少一个实施例中,编译器3101被配置为将源代码3100转换为用于在主机上执行的主机可执行代码3102以及用于在设备上执行的设备可执行代码3103。在至少一个实施例中,源代码3100可以在执行应用程序之前离线编译,或者在执行应用程序期间在线编译。
[0350]
在至少一个实施例中,源代码3100可以包括编译器3101支持的任何编程语言的代码,例如c++、c、fortran等。在至少一个实施例中,源代码3100可以包括在单一源(single-source)文件中,其具有主机代码和设备代码的混合,并在其中指示了设备代码的位置。在至少一个实施例中,单一源文件可以是包括cuda代码的.cu文件或包括hip代码的.hip.cpp文件。备选地,在至少一个实施例中,源代码3100可以包括多个源代码文件,而不是单一源文件,在该单一源文件中主机代码和设备代码是分开的。
[0351]
在至少一个实施例中,编译器3101被配置为将源代码3100编译成用于在主机上执行的主机可执行代码3102和用于在设备上执行的设备可执行代码3103。在至少一个实施例中,编译器3101执行操作,包括将源代码3100解析为抽象系统树(ast),执行优化以及生成可执行代码。在源代码3100包括单一源文件的至少一个实施例中,编译器3101可以将设备代码与主机代码在这种单一源文件中分开,将设备代码和主机代码分别编译成设备可执行代码3103和主机可执行代码3102,以及将设备可执行代码3103和主机可执行代码3102在单
个文件中链接到一起,如下面关于图32更详细讨论的。
[0352]
在至少一个实施例中,主机可执行代码3102和设备可执行代码3103可以是任何合适的格式,例如二进制代码和/或ir代码。在cuda的情况下,在至少一个实施例中,主机可执行代码3102可以包括本地对象代码,而设备可执行代码3103可以包括ptx中间表示的代码。在至少一个实施例中,在rocm的情况下,主机可执行代码3102和设备可执行代码3103都可以包括目标二进制代码。
[0353]
在至少一个实施例中,利用图31中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图31中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0354]
图32是根据至少一个实施例的编译代码以在图26-29的编程平台之一上执行的更详细图示。在至少一个实施例中,编译器3201被配置为接收源代码3200,编译源代码3200,并输出可执行文件3210。在至少一个实施例中,源代码3200是单一源文件,例如.cu文件,.hip.cpp文件或其他格式的文件,其包括主机代码和设备代码两者。在至少一个实施例中,编译器3201可以是但不限于用于在.cu文件中编译cuda代码的nvidiacuda编译器(“nvcc”),或用于在.hip.cpp文件中编译hip代码的hcc编译器。
[0355]
在至少一个实施例中,编译器3201包括编译器前端3202,主机编译器3205,设备编译器3206和链接器3209。在至少一个实施例中,编译器前端3202被配置为在源代码3200中将设备代码3204与主机代码3203分开。在至少一个实施例中,设备代码3204由设备编译器3206编译成设备可执行代码3208,如所描述的,其可以包括二进制代码或ir代码。在至少一个实施例中,主机代码3203由主机编译器3205单独地编译成主机可执行代码3207。在至少一个实施例中,对于nvcc,主机编译器3205可以是但不限于输出本机目标代码的通用c/c++编译器,而设备编译器3206可以是但不限于基于低级虚拟机(“llvm”)的编译器,其将llvm编译器基础架构分叉,并输出ptx代码或二进制代码。在至少一个实施例中,对于hcc,主机编译器3205和设备编译器3206两者可以是但不限于输出目标二进制代码的基于llvm的编译器。
[0356]
在至少一个实施例中,在将源代码3200编译成主机可执行代码3207和设备可执行代码3208之后,链接器3209将主机和设备可执行代码3207和3208在可执行文件3210中链接到一起。在至少一个实施例中,主机和ptx的本机目标代码或设备的二进制代码可以在可执行和可链接格式(“elf”)文件中链接在一起,该文件是用于存储目标代码的容器格式。
[0357]
在至少一个实施例中,利用图32中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图32中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0358]
图33示出了根据至少一个实施例的在编译源代码之前转换源代码。在至少一个实施例中,源代码3300通过转换工具3301传递,转换工具3301将源代码3300转换成转换后的源代码3302。在至少一个实施例中,编译器3303用于将转换后的源代码3302编译成主机可执行代码3304和设备可执行代码3305,其过程类似于由编译器3101将源代码3100编译成主机可执行代码3102和设备可执行代码3103的过程,如以上结合图31所讨论的。
[0359]
在至少一个实施例中,由转换工具3301执行的转换被用于移植(port)源代码3300,以在与最初打算在其上运行的不同的环境中执行。在至少一个实施例中,转换工具
3301可以包括但不限于hip转换器,其用于将用于cuda平台的cuda代码“移植(hipify)”为可以在rocm平台上编译和执行的hip代码。在至少一个实施例中,源代码3300的转换可以包括:解析源代码3300,并将对由一个编程模型(例如,cuda)提供的api的调用转换为对由另一编程模型(例如,例如,hip)提供的api的相应调用,如下面结合图34a和图35更详细地讨论的。返回到移植cuda代码的示例,在至少一个实施例中,对cuda运行时api、cuda驱动器api和/或cuda库的调用可以被转换为对应的hip api调用。在至少一个实施例中,由转换工具3301执行的自动转换有时可能是不完整的,需要额外的人工来完全移植源代码3300。
[0360]
在至少一个实施例中,利用图33中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图33中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0361]
配置gpu用于通用计算
[0362]
以下各图阐述但不限于根据至少一个实施例的用于编译和执行计算源代码的示例性架构。
[0363]
图34a示出了根据至少一个实施例的被配置为使用不同类型的处理单元来编译和执行cuda源代码3410的系统3400。在至少一个实施例中,系统3400包括但不限于cuda源代码3410,cuda编译器3450,主机可执行代码3470(1),主机可执行代码3470(2),cuda设备可执行代码3484,cpu 3490,启用cuda的gpu 3494,gpu 3492,cuda到hip转换工具3420,hip源代码3430,hip编译器驱动器3440,hcc 3460和hcc设备可执行代码3482。
[0364]
在至少一个实施例中,cuda源代码3410是cuda编程语言的人类可读代码的集合。在至少一个实施例中,cuda代码是cuda编程语言的人类可读代码。在至少一个实施例中,cuda编程语言是c++编程语言的扩展,其包括但不限于定义设备代码以及区分设备代码和主机代码的机制。在至少一个实施例中,设备代码是在编译之后可在设备上并行执行的源代码。在至少一个实施例中,设备可以是针对并行指令处理而优化的处理器,例如启用cuda的gpu 3490、gpu 3492或另一gpgpu等。在至少一个实施例中,主机代码是在编译后可以在主机上执行的源代码。在至少一个实施例中,主机是针对顺序指令处理而优化的处理器,例如cpu 3490。
[0365]
在至少一个实施例中,cuda源代码3410包括但不限于,任意数量(包括零)的全局函数3412,任意数量(包括零)的设备函数3414,任意数量(包括零)的主机函数3416,以及任意数量(包括零)的主机/设备函数3418。在至少一个实施例中,全局函数3412,设备函数3414,主机函数3416和主机/设备函数3418在cuda源代码3410中可以混合。在至少一个实施例中,每个全局函数3412可在设备上执行并且可从主机调用。因此,在至少一个实施例中,全局函数3412中的一个或更多个可以充当设备的入口点。在至少一个实施例中,每个全局函数3412是内核。在至少一个实施例中以及在一种称为动态并行性的技术中,一个或更多个全局函数3412定义了一内核,该内核可以在设备上执行并且可以从这样的设备调用。在至少一个实施例中,内核在执行期间由设备上的n个不同线程并行执行n次(其中n为任何正整数)。
[0366]
在至少一个实施例中,每个设备函数3414在设备上执行并且只能从这样的设备调用。在至少一个实施例中,每个主机函数3416在主机上执行并且只能从这样的主机调用。在至少一个实施例中,每个主机/设备函数3416既定义了在主机上可执行并且只能从这样的
主机调用的函数的主机版本,也定义了在设备上可执行并且只能从这样的设备调用的函数的设备版本。
[0367]
在至少一个实施例中,cuda源代码3410还可包括但不限于对通过cuda运行时api 3402定义的任意数量的函数的任意数量的调用。在至少一个实施例中,cuda运行时api 3402可以包括但不限于在主机上执行的任意数量的函数,用于分配和解除分配设备存储器,在主机存储器和设备存储器之间传输数据,管理具有多个设备的系统等。在至少一个实施例中,cuda源代码3410还可以包括对在任意数量的其他cuda api中指定的任意数量的函数的任意数量的调用。在至少一个实施例中,cuda api可以是被设计为由cuda代码使用的任何api。在至少一个实施例中,cuda api包括但不限于cuda运行时api 3402,cuda驱动器api,用于任意数量的cuda库的api等。在至少一个实施例中并且相对于cuda运行时api 3402,cuda驱动器api是较低级别的api,但可以提供对设备的更细粒度的控制。在至少一个实施例中,cuda库的示例包括但不限于cublas,cufft,curand,cudnn等。
[0368]
在至少一个实施例中,cuda编译器3450编译输入的cuda代码(例如,cuda源代码3410)以生成主机可执行代码3470(1)和cuda设备可执行代码3484。在至少一个实施例中,cuda编译器3450是nvcc。在至少一个实施例中,主机可执行代码3470(1)是在cpu 3490上可执行的输入源代码中包括的主机代码的编译版本。在至少一个实施例中,cpu3490可以是针对顺序指令处理而优化的任何处理器。
[0369]
在至少一个实施例中,cuda设备可执行代码3484是在启用cuda的gpu 3494上可执行的输入源代码中包括的设备代码的编译版本。在至少一个实施例中,cuda设备可执行代码3484包括但不限于二进制代码。在至少一个实施例中,cuda设备可执行代码3484包括但不限于ir代码,例如ptx代码,该ir代码在运行时被设备驱动器进一步编译为用于特定目标设备(例如,启用cuda的gpu 3494)的二进制代码。在至少一个实施例中,启用cuda的gpu 3494可以是针对并行指令处理而优化并且支持cuda的任何处理器。在至少一个实施例中,启用cuda的gpu 3494由加利福尼亚州圣克拉拉市的nvidia公司开发。
[0370]
在至少一个实施例中,cuda到hip转换工具3420被配置为将cuda源代码3410转换成功能上相似的hip源代码3430。在至少一个实施例中,hip源代码3430是hip编程语言的人类可读代码的集合。在至少一个实施例中,hip代码是hip编程语言的人类可读代码。在至少一个实施例中,hip编程语言是c++编程语言的扩展,其包括但不限于cuda机制的功能上相似的版本,用于定义设备代码并区分设备代码和主机代码。在至少一个实施例中,hip编程语言可以包括cuda编程语言的功能的子集。在至少一个实施例中,例如,hip编程语言包括但不限于定义全局函数3412的机制,但是这样的hip编程语言可能缺乏对动态并行性的支持,因此,在hip代码中定义的全局函数3412仅可从主机调用。
[0371]
在至少一个实施例中,hip源代码3430包括但不限于任意数量(包括零)的全局函数3412,任意数量(包括零)的设备函数3414,任意数量(包括零)的主机函数3416以及任意数量(包括零)的主机/设备函数3418。在至少一个实施例中,hip源代码3430还可以包括对在hip运行时api 3432中指定的任意数量的函数的任意数量的调用。在一个实施例中,hip运行时api 3432包括但不限于cuda运行时api 3402中包括的函数的子集的功能上相似的版本。在至少一个实施例中,hip源代码3430还可以包括对在任意数量的其他hip api中指定的任意数量的函数的任意数量的调用。在至少一个实施例中,hip api可以是被设计为供
hip代码和/或rocm使用的任何api。在至少一个实施例中,hip api包括但不限于hip运行时api 3432,hip驱动器api,用于任意数量的hip库的api,用于任意数量的rocm库的api等。
[0372]
在至少一个实施例中,cuda到hip转换工具3420将cuda代码中的每个内核调用从cuda语法转换为hip语法,并将cuda代码中的任意数量的其他cuda调用转换为任意数量的其他功能上相似的hip调用。在至少一个实施例中,cuda调用是对在cuda api中指定的函数的调用,并且hip调用是对在hip api中指定的函数的调用。在至少一个实施例中,cuda到hip转换工具3420将对在cuda运行时api 3402中指定的函数的任意数量的调用转换为对在hip运行时api 3432中指定的函数的任意数量的调用。
[0373]
在至少一个实施例中,cuda到hip转换工具3420是被称为hipify-perl的工具,其执行基于文本的转换过程。在至少一个实施例中,cuda到hip转换工具3420是被称为hipify-clang的工具,相对于hipify-perl,其执行更复杂且更鲁棒的转换过程,该过程涉及使用clang(编译器前端)解析cuda代码,然后转换得到的符号。在至少一个实施例中,除了由cuda到hip转换工具3420执行的那些修改之外,将cuda代码正确地转换成hip代码可能还需要修改(例如,手动编辑)。
[0374]
在至少一个实施例中,hip编译器驱动器3440是确定目标设备3446,然后配置与目标设备3446兼容的编译器以编译hip源代码3430的前端。在至少一个实施例中,目标设备3446是针对并行指令处理而优化的处理器。在至少一个实施例中,hip编译器驱动器3440可以以任何技术上可行的方式确定目标设备3446。
[0375]
在至少一个实施例中,如果目标设备3446与cuda兼容(例如,启用cuda的gpu 3494),则hip编译器驱动器3440生成hip/nvcc编译命令3442。在至少一个实施例中并且结合图34b更详细地描述的,hip/nvcc编译命令3442配置cuda编译器3450以使用但不限于hip到cuda转换头和cuda运行时库来编译hip源代码3430。在至少一个实施例中并且响应于hip/nvcc编译命令3442,cuda编译器3450生成主机可执行代码3470(1)和cuda设备可执行代码3484。
[0376]
在至少一个实施例中,如果目标设备3446与cuda不兼容,则hip编译器驱动器3440生成hip/hcc编译命令3444。在至少一个实施例中并且如结合图34c更详细地描述的,hip/hcc编译命令3444配置hcc 3460以使用hcc头和hip/hcc运行时库编译hip源代码3430。在至少一个实施例中并且响应于hip/hcc编译命令3444,hcc 3460生成主机可执行代码3470(2)和hcc设备可执行代码3482。在至少一个实施例中,hcc设备可执行代码3482是hip源代码3430中包含的可在gpu 3492上执行的设备代码的编译版本。在至少一个实施例中,gpu 3492可以是针对并行指令处理而优化的、与cuda不兼容且与hcc兼容的任何处理器。在至少一个实施例中,gpu 3492由加利福尼亚州圣克拉拉市的amd公司开发。在至少一个实施例中,gpu 3492是不启用cuda的gpu 3492。
[0377]
仅出于说明性目的,在图34a中描绘了在至少一个实施例中可以实现为编译cuda源代码3410以在cpu 3490和不同设备上执行的三个不同流程。在至少一个实施例中,直接cuda流程编译cuda源代码3410以在cpu 3490和启用cuda的gpu 3494上执行,而无需将cuda源代码3410转换为hip源代码3430。在至少一个实施例中,间接cuda流程将cuda源代码3410转换为hip源代码3430,然后编译hip源代码3430以在cpu 3490和启用cuda的gpu 3494上执行。在至少一个实施例中,cuda/hcc流程将cuda源代码3410转换为hip源代码3430,然后编
译hip源代码3430以在cpu 3490和gpu 3492上执行。
[0378]
可以通过虚线和一系列气泡注释a1-a3描绘可以在至少一个实施例中实现的直接cuda流程。在至少一个实施例中,并且如气泡注释a1所示,cuda编译器3450接收cuda源代码3410和配置cuda编译器3450以编译cuda源代码3410的cuda编译命令3448。在至少一个实施例中,直接cuda流程中使用的cuda源代码3410是用cuda编程语言编写的,该cuda编程语言基于除c++之外的其他编程语言(例如c,fortran,python,java等)。在至少一个实施例中,并且响应于cuda编译命令3448,cuda编译器3450生成主机可执行代码3470(1)和cuda设备可执行代码3484(用气泡注释a2表示)。在至少一个实施例中并且如用气泡注释a3所示,主机可执行代码3470(1)和cuda设备可执行代码3484可以分别在cpu 3490和启用cuda的gpu 3494上执行。在至少一个实施例中,cuda设备可执行代码3484包括但不限于二进制代码。在至少一个实施例中,cuda设备可执行代码3484包括但不限于ptx代码,并且在运行时被进一步编译成用于特定目标设备的二进制代码。
[0379]
可以通过虚线和一系列气泡注释b1-b6来描述可以在至少一个实施例中实现的间接cuda流程。在至少一个实施例中并且如气泡注释b1所示,cuda到hip转换工具3420接收cuda源代码3410。在至少一个实施例中并且如气泡注释b2所示,cuda到hip转换工具3420将cuda源代码3410转换为hip源代码3430。在至少一个实施例中并如气泡注释b3所示,hip编译器驱动器3440接收hip源代码3430,并确定目标设备3446是否启用了cuda。
[0380]
在至少一个实施例中并且如气泡注释b4所示,hip编译器驱动器3440生成hip/nvcc编译命令3442,并将hip/nvcc编译命令3442和hip源代码3430两者都发送到cuda编译器3450。在至少一个实施例中并且如结合图34b更详细地描述的,hip/nvcc编译命令3442配置cuda编译器3450以使用但不限于hip到cuda转换头和cuda运行时库来编译hip源代码3430。在至少一个实施例中并且响应于hip/nvcc编译命令3442,cuda编译器3450生成主机可执行代码3470(1)和cuda设备可执行代码3484(用气泡注释b5表示)。在至少一个实施例中并且如气泡注释b6所示,主机可执行代码3470(1)和cuda设备可执行代码3484可以分别在cpu 3490和启用cuda的gpu 3494上执行。在至少一个实施例中,cuda设备可执行代码3484包括但不限于二进制代码。在至少一个实施例中,cuda设备可执行代码3484包括但不限于ptx代码,并且在运行时被进一步编译成用于特定目标设备的二进制代码。
[0381]
可以通过实线和一系列气泡注释c1-c6来描述可以在至少一个实施例中实现的cuda/hcc流程。在至少一个实施例中并且如气泡注释c1所示,cuda到hip转换工具3420接收cuda源代码3410。在至少一个实施例中并且如气泡注释c2所示,cuda到hip转换工具3420将cuda源代码3410转换为hip源代码3430。在至少一个实施例中并且如气泡注释c3所示,hip编译器驱动器3440接收hip源代码3430,并确定目标设备3446未启用cuda。
[0382]
在至少一个实施例中,hip编译器驱动器3440生成hip/hcc编译命令3444,并且将hip/hcc编译命令3444和hip源代码3430两者发送到hcc 3460(用气泡注释c4表示)。在至少一个实施例中并且如结合图34c更详细地描述的,hip/hcc编译命令3444配置hcc 3460以使用但不限于hcc头和hip/hcc运行时库编译hip源代码3430。在至少一个实施例中并且响应于hip/hcc编译命令3444,hcc 3460生成主机可执行代码3470(2)和hcc设备可执行代码3482(用气泡注释c5表示)。在至少一个实施例中并且如气泡注释c6所示,主机可执行代码3470(2)和hcc设备可执行代码3482可以分别在cpu 3490和gpu 3492上执行。
[0383]
在至少一个实施例中,在将cuda源代码3410转换为hip源代码3430之后,hip编译器驱动器3440可随后用于生成用于启用cuda的gpu3494或gpu 3492的可执行代码,而无需将cuda重新执行为hip转换工具3420。在至少一个实施例中,cuda到hip转换工具3420将cuda源代码3410转换为hip源代码3430,然后将其存储在存储器中。在至少一个实施例中,hip编译器驱动器3440然后配置hcc 3460以基于hip源代码3430生成主机可执行代码3470(2)和hcc设备可执行代码3482。在至少一个实施例中,hip编译器驱动器3440随后配置cuda编译器3450以基于存储的hip源代码3430生成主机可执行代码3470(1)和cuda设备可执行代码3484。
[0384]
图34b示出了根据至少一个实施例的被配置为使用cpu 3490和启用cuda的gpu 3494来编译和执行图34a的cuda源代码3410的系统3404。在至少一个实施例中,系统3404包括但不限于cuda源代码3410,cuda到hip转换工具3420,hip源代码3430,hip编译器驱动器3440,cuda编译器3450,主机可执行代码3470(1),cuda设备可执行代码3484,cpu 3490和启用cuda的gpu 3494。
[0385]
在至少一个实施例中并且如本文先前结合图34a所描述的,cuda源代码3410包括但不限于任意数量(包括零)的全局函数3412,任意数量(包括零)的设备函数3414,任意数量(包括零)的主机函数3416以及任意数量(包括零)的主机/设备函数3418。在至少一个实施例中,cuda源代码3410还包括但不限于对在任意数量的cuda api中指定的任意数量的函数的任意数量的调用。
[0386]
在至少一个实施例中,cuda到hip转换工具3420将cuda源代码3410转换成hip源代码3430。在至少一个实施例中,cuda到hip转换工具3420将cuda源代码3410中的每个内核调用从cuda语法转换为hip语法,并将cuda源代码3410中任意数量的其他cuda调用转换为任意数量的其他功能上相似的hip调用。
[0387]
在至少一个实施例中,hip编译器驱动器3440确定目标设备3446是启用cuda的,并且生成hip/nvcc编译命令3442。在至少一个实施例中,然后hip编译器驱动器3440经由hip/nvcc编译命令3442配置cuda编译器3450以编译hip源代码3430。在至少一个实施例中,作为配置cuda编译器3450的一部分,hip编译器驱动器3440提供对hip到cuda转换头3452的访问。在至少一个实施例中,hip到cuda转换头3452将任意数量的hip api中指定的任意数量的机制(例如,函数)转换为任意数量的cuda api中指定的任意数量的机制。在至少一个实施例中,cuda编译器3450将hip到cuda转换头3452与对应于cuda运行时api 3402的cuda运行时库3454结合使用,以生成主机可执行代码3470(1)和cuda设备可执行代码3484。在至少一个实施例中,然后可以分别在cpu3490和启用cuda的gpu 3494上执行主机可执行代码3470(1)和cuda设备可执行代码3484。在至少一个实施例中,cuda设备可执行代码3484包括但不限于二进制代码。在至少一个实施例中,cuda设备可执行代码3484包括但不限于ptx代码,并且在运行时被进一步编译成用于特定目标设备的二进制代码。
[0388]
图34c示出了根据至少一个实施例的系统3406,该系统3406被配置为使用cpu 3490和未启用cuda的gpu 3492来编译和执行图34a的cuda源代码3410。在至少一个实施例中,系统3406包括但不限于cuda源代码3410,cuda到hip转换工具3420,hip源代码3430,hip编译器驱动器3440,hcc 3460,主机可执行代码3470(2),hcc设备可执行代码3482,cpu 3490和gpu 3492。
[0389]
在至少一个实施例中,并且如本文先前结合图34a所描述的,cuda源代码3410包括但不限于任意数量(包括零)的全局函数3412,任意数量(包括零)的设备函数3414,任意数量(包括零)的主机函数3416以及任意数量(包括零)的主机/设备函数3418。在至少一个实施例中,cuda源代码3410还包括但不限于对在任意数量的cuda api中指定的任意数量的函数的任意数量的调用。
[0390]
在至少一个实施例中,cuda到hip转换工具3420将cuda源代码3410转换成hip源代码3430。在至少一个实施例中,cuda到hip转换工具3420将cuda源代码3410中的每个内核调用从cuda语法转换为hip语法,并将源代码3410中任意数量的其他cuda调用转换为任意数量的其他功能上相似的hip调用。
[0391]
在至少一个实施例中,hip编译器驱动器3440随后确定目标设备3446不是启用cuda的,并生成hip/hcc编译命令3444。在至少一个实施例中,然后hip编译器驱动器3440配置hcc 3460以执行hip/hcc编译命令3444,从而编译hip源代码3430。在至少一个实施例中,hip/hcc编译命令3444将hcc 3460配置为使用但不限于hip/hcc运行时库3458和hcc头3456来生成主机可执行代码3470(2)和hcc设备可执行代码3482。在至少一个实施例中,hip/hcc运行时库3458对应于hip运行时api 3432。在至少一个实施例中,hcc头3456包括但不限于用于hip和hcc的任意数量和类型的互操作性机制。在至少一个实施例中,主机可执行代码3470(2)和hcc设备可执行代码3482可以分别在cpu 3490和gpu 3492上执行。
[0392]
在至少一个实施例中,利用图34a-34c中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图34a-34c中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0393]
图35示出了根据至少一个实施例的由图34c的cuda到hip转换工具3420转换的示例性内核。在至少一个实施例中,cuda源代码3410将给定内核被设计为解决的总体问题划分为可以使用线程块独立解决的相对粗糙的子问题。在至少一个实施例中,每个线程块包括但不限于任意数量的线程。在至少一个实施例中,每个子问题被划分为相对细小的部分(pieces),这些部分可以由线程块中的线程协作并行地解决。在至少一个实施例中,线程块内的线程可以通过共享存储器共享数据并通过同步执行以协调存储器访问来协作。
[0394]
在至少一个实施例中,cuda源代码3410将与给定内核相关联的线程块组织成线程块的一维、二维或三维网格。在至少一个实施例中,每个线程块包括但不限于任意数量的线程,并且网格包括但不限于任意数量的线程块。
[0395]
在至少一个实施例中,内核是使用“__global__”声明说明符(specifier)定义的设备代码中的函数。在至少一个实施例中,使用cuda内核启动语法3510来指定针对给定内核调用执行内核的网格的尺寸以及相关联的流。在至少一个实施例中,cuda内核启动语法3510被指定为“kernelname《《《gridsize,blocksize,sharedmemorysize,stream》》》(kernelarguments);”。在至少一个实施例中,执行配置语法是“《《《...》》》”构造,其被插入在内核名称(“kernelname”)和内核参数的括号列表(“kernelarguments”)之间。在至少一个实施例中,cuda内核启动语法3510包括但不限于cuda启动函数语法而不是执行配置语法。
[0396]
在至少一个实施例中,“gridsize”是dim3类型的,并且指定网格的尺寸和大小。在至少一个实施例中,类型dim3是cuda定义的结构,其包括但不限于无符号整数x,y和z。在至
少一个实施例中,如果未指定z,则z默认为1。在至少一个实施例中,如果未指定y,则y默认为1。在至少一个实施例中,网格中的线程块的数量等于gridsize.x、gridsize.y和gridsize.z的乘积。在至少一个实施例中,“blocksize”是dim3类型的,并且指定每个线程块的尺寸和大小。在至少一个实施例中,每线程块的线程数等于blocksize.x、blocksize.y和blocksize.z的乘积。在至少一个实施例中,给定执行内核的每个线程唯一的线程id,该线程id可通过内置变量(例如“threadidx”)在内核内访问。
[0397]
在至少一个实施例中,关于cuda内核启动语法3510,“sharedmemorysize”是一可选参数,它指定共享存储器中除静态分配的存储器外,针对给定内核调用为每个线程块动态分配的字节数。在至少一个实施例中并且关于cuda内核启动语法3510,sharedmemorysize默认为零。在至少一个实施例中并且关于cuda内核启动语法3510,“流”是可选的参数,其指定相关联的流并且默认为零以指定默认流。在至少一个实施例中,流是按顺序执行的命令序列(其可能由不同的主机线程发出)。在至少一个实施例中,不同的流可以相对于彼此无序地或同时地执行命令。
[0398]
在至少一个实施例中,cuda源代码3410包括但不限于用于示例性内核“matadd”的内核定义和主函数。在至少一个实施例中,主函数是在主机上执行的主机代码,并且包括但不限于使内核matadd在设备上执行的内核调用。在至少一个实施例中,如图所示,内核matadd将大小为nxn的两个矩阵a和b相加,其中n为正整数,并将结果存储在矩阵c中。在至少一个实施例中,主函数将threadsperblock变量定义为16x16,numblocks变量为n/16x n/16。在至少一个实施例中,然后主函数指定内核调用“matadd《《《numblocks,threadsperblock》》》(a,b,c);”。在至少一个实施例中,并且根据cuda内核启动语法3510,使用尺寸为n/16
×
n/16的线程块网格来执行内核matadd,其中每个线程块的尺寸为16
×
16。在至少一个实施例中,每个线程块包括256个线程,创建具有足够块的网格以使每个矩阵元素具有一个线程,并且该网格中的每个线程执行内核matadd以执行一个逐对的加法。
[0399]
在至少一个实施例中,在将cuda源代码3410转换成hip源代码3430的同时,cuda到hip转换工具3420将cuda源代码3410中的每个内核调用从cuda内核启动语法3510转换成hip内核启动语法3520,并将源代码3410中的任意数量的其他cuda调用转换为任意数量的其他功能上相似的hip调用。在至少一个实施例中,hip内核启动语法3520被指定为“hiplaunchkernelggl(kernelname,gridsize,blocksize,sharedmemorysize,stream,kernelarguments);”。在至少一个实施例中,kernelname,gridsize,blocksize,sharememorysize,stream和kernelarguments中的每一个在hip内核启动语法3520中具有与在cuda内核启动语法3510中(本文先前描述)相同的含义。在至少一个实施例中,参数sharedmemorysize和stream在hip内核启动语法3520中是必需的,而在cuda内核启动语法3510中是可选的。
[0400]
在至少一个实施例中,除了使内核matadd在设备上执行的内核调用之外,图35中描绘的hip源代码3430的一部分与图35中描绘的cuda源代码3410的一部分相同。在至少一个实施例中,在hip源代码3430中定义内核matadd,具有与在cuda源代码3410中定义内核matadd相同的“__global__”声明说明符。在至少一个实施例中,在hip源代码3430中的内核调用是“hiplaunchkernelggl(matadd,numblocks,threadsperblock,0、0,a,b,c);”,而cuda源代码3410中的相应内核调用是“matadd《《《numblocks,threadsperblock》》》(a,b,
c);”。
[0401]
在至少一个实施例中,利用图35中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图35中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0402]
图36更详细地示出了根据至少一个实施例的图34c的未启用cuda的gpu 3492。在至少一个实施例中,gpu 3492由圣塔克拉拉市的amd公司开发。在至少一个实施例中,gpu 3492可以被配置为以高度并行的方式执行计算操作。在至少一个实施例中,gpu 3492被配置为执行图形管线操作,诸如绘制命令、像素操作、几何计算以及与将图像渲染到显示器相关联的其他操作。在至少一个实施例中,gpu 3492被配置为执行与图形无关的操作。在至少一个实施例中,gpu 3492被配置为执行与图形有关的操作和与图形无关的操作两者。在至少一个实施例中,gpu 3492可以被配置为执行hip源代码3430中包括的设备代码。
[0403]
在至少一个实施例中,gpu 3492包括但不限于任意数量的可编程处理单元3620,命令处理器3610,l2高速缓存3622,存储器控制器3670,dma引擎3680(1),系统存储器控制器3682,dma引擎3680(2)和gpu控制器3684。在至少一个实施例中,每个可编程处理单元3620包括但不限于工作负载管理器3630和任意数量的计算单元3640。在至少一个实施例中,命令处理器3610读取来自一个或更多个命令队列(未示出)的命令,并将命令分发给工作负载管理器3630。在至少一个实施例中,对于每个可编程处理单元3620,相关的工作负载管理器3630将工作分发给包括在可编程处理单元3620中的计算单元3640。在至少一个实施例中,每个计算单元3640可以执行任意数量的线程块,但是每个线程块在单个计算单元3640上执行。在至少一个实施例中,工作组是线程块。
[0404]
在至少一个实施例中,每个计算单元3640包括但不限于任意数量的simd单元3650和共享存储器3660。在至少一个实施例中,每个simd单元3650实现simd架构并且被配置为并行执行操作。在至少一个实施例中,每个simd单元3650包括但不限于向量alu 3652和向量寄存器文件3654。在至少一个实施例中,每个simd单元3650执行不同的线程束。在至少一个实施例中,线程束是一组线程(例如16个线程),其中线程束中的每个线程属于单个线程块,并且被配置为基于单个指令集来处理不同的数据集。在至少一个实施例中,可以使用预测来禁用线程束中的一个或更多个线程。在至少一个实施例中,通道是线程。在至少一个实施例中,工作项是线程。在至少一个实施例中,波前是线程束。在至少一个实施例中,线程块中的不同波前可一起同步并经由共享存储器3660进行通信。
[0405]
在至少一个实施例中,可编程处理单元3620被称为“着色引擎”。在至少一个实施例中,除了计算单元3640之外,每个可编程处理单元3620还包括但不限于任意数量的专用图形硬件。在至少一个实施例中,每个可编程处理单元3620包括但不限于任意数量(包括零)的几何处理器,任意数量(包括零)的光栅化器,任意数量(包括零)的渲染后端,工作负载管理器3630和任意数量的计算单元3640。
[0406]
在至少一个实施例中,计算单元3640共享l2高速缓存3622。在至少一个实施例中,l2高速缓存3622被分区。在至少一个实施例中,gpu 3492中的所有计算单元3640可访问gpu存储器3690。在至少一个实施例中,存储器控制器3670和系统存储器控制器3682促进gpu 3492与主机之间的数据传输,并且dma引擎3680(1)使能gpu 3492与此主机之间的异步存储器传输。在至少一个实施例中,存储器控制器3670和gpu控制器3684促进gpu 3492与其他
gpu 3492之间的数据传输,并且dma引擎3680(2)使能gpu 3492与其他gpu 3492之间的异步存储器传输。
[0407]
在至少一个实施例中,gpu 3492包括但不限于任意数量和类型的系统互连,该系统互连促进在gpu 3492内部或外部的任意数量和类型的直接或间接链接的组件之间的数据和控制传输。在至少一个实施例中,gpu 3492包括但不限于耦合到任意数量和类型的外围设备的任意数量和类型的i/o接口(例如,pcie)。在至少一个实施例中,gpu 3492可以包括但不限于任意数量(包括零)的显示引擎和任意数量(包括零)的多媒体引擎。在至少一个实施例中,gpu 3492实现了存储器子系统,该存储器子系统包括但不限于任意数量和类型的存储器控制器(例如,存储器控制器3670和系统存储器控制器3682)以及专用于一个组件或在多个组件之间共享的存储器设备(例如,共享存储器3660)。在至少一个实施例中,gpu 3492实现了高速缓存子系统,该高速缓存子系统包括但不限于一个或更多个高速缓存存储器(例如,l2高速缓存3622),每个高速缓存存储器可以是私有的或在任意数量的组件(例如,simd单元3650,计算单元3640和可编程处理单元3620)之间共享。
[0408]
在至少一个实施例中,利用图36中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图36中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0409]
图37示出了根据至少一个实施例的示例性cuda网格3720的线程如何被映射到图36的不同计算单元3640。在至少一个实施例中,并且仅出于说明目的,网格3720具有bx乘以by乘以1的gridsize(网格大小)和tx乘以ty乘以1的blocksize(块大小)。因此,在至少一个实施例中,网格3720包括但不限于(bx*by)线程块3730,每个线程块3730包括但不限于(tx*ty)线程3740。线程3740在图37中被描绘为弯曲箭头。
[0410]
在至少一个实施例中,网格3720被映射到可编程处理单元3620(1),该可编程处理单元3620(1)包括但不限于计算单元3640(1)-3640(c)。在至少一个实施例中并且如图所示,将(bj*by)线程块3730映射到计算单元3640(1),并且将其余线程块3730映射到计算单元3640(2)。在至少一个实施例中,每个线程块3730可以包括但不限于任意数量的线程束,并且每个线程束被映射到图36的不同的simd单元3650。
[0411]
在至少一个实施例中,给定线程块3730中的线程束可以一起同步并通过关联的计算单元3640中包括的共享存储器3660进行通信。例如并且在至少一个实施例中,线程块3730(bj,1)中的线程束可以一起同步并通过共享存储器3660(1)进行通信。例如并且在至少一个实施例中,线程块3730(bj+1,1)中的线程束可以一起同步并通过共享存储器3660(2)进行通信。
[0412]
在至少一个实施例中,利用图37中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图37中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0413]
图38示出了根据至少一个实施例的如何将现有的cuda代码迁移到数据并行c++代码。数据并行c++(dpc++)可以指单架构专有语言的一种开放的、基于标准的替代方案,其允许开发人员可以跨硬件目标(cpu和加速器,诸如gpu和fpga)重用代码,并且还为特定加速器执行自定义调整。dpc++根据开发人员可能熟悉的iso c++使用类似和/或相同的c和c++构造。dpc++结合了khronos集团(the khronos group)的标准sycl,以支持数据并行性和异
构编程。sycl是指跨平台的抽象层,它建立在opencl的底层概念、可移植性和效率之上,它使异构处理器的代码能够使用标准c++以“单源”风格编写。sycl可以实现单源开发,其中c++模板函数可以包含主机代码和设备代码两者,以构建使用opencl加速的复杂算法,然后在不同类型的数据的整个源代码中重用它们。
[0414]
在至少一个实施例中,使用dpc++编译器来编译可以跨各种硬件目标部署的dpc++源代码。在至少一个实施例中,dpc++编译器用于生成可跨各种硬件目标部署的dpc++应用程序,并且dpc++兼容性工具可用于将cuda应用程序迁移到dpc++中的多平台程序。在至少一个实施例中,dpc++基础工具包包括:dpc++编译器,用于跨各种硬件目标部署应用程序;dpc++库,用于提高cpu、gpu和fpga的生产力和性能;dpc++兼容性工具,用于将cuda应用程序迁移到多平台应用程序;及其任何合适的组合。
[0415]
在至少一个实施例中,dpc++编程模型用于通过使用现代c++特征来表达与称为数据并行c++的编程语言的并行性来简化与编程cpu和加速器有关的一个或更多个方面。dpc++编程语言可用于针对使用单源语言的主机(例如cpu)和加速器(例如gpu或fpga)进行代码重用,并清楚地传达执行和内存依赖性。dpc++代码内的映射可用于将应用程序转换为在最能加速工作负载的硬件或硬件设备集上运行。即使在没有可用加速器的平台上,主机也可用于简化设备代码的开发和调试。
[0416]
在至少一个实施例中,cuda源代码3800作为输入提供给dpc++兼容性工具3802以生成人类可读的dpc++3804。在至少一个实施例中,人类可读的dpc++3804包括由dpc++兼容性工具3802生成的内联注释,其指导开发人员如何和/或在何处修改dpc++代码以完成编码和调整到所需性能3806,从而生成dpc++源代码3808。
[0417]
在至少一个实施例中,cuda源代码3800是或包括cuda编程语言中人类可读源代码的集合。在至少一个实施例中,cuda源代码3800是采用cuda编程语言的人类可读源代码。在至少一个实施例中,cuda编程语言是c++编程语言的扩展,其包括但不限于定义设备代码和区分设备代码和主机代码的机制。在至少一个实施例中,设备代码是源代码,其在编译后可在设备(例如,gpu或fpga)上执行,并且可以包括可在设备的一个或更多个处理器核上执行的一个或更多个可并行工作流。在至少一个实施例中,设备可以是处理器,其针对并行指令处理进行优化,例如启用cuda的gpu、gpu或另一gpgpu等。在至少一个实施例中,主机代码是在编译后可在主机上执行的源代码。在至少一个实施例中,主机代码和设备代码中的一些或全部可以跨cpu和gpu/fpga并行执行。在至少一个实施例中,主机是针对顺序指令处理而优化的处理器,例如cpu。结合图38描述的cuda源代码3800可与本文档中其他地方讨论的内容一致。
[0418]
在至少一个实施例中,dpc++兼容性工具3802指的是用于促进将cuda源代码3800迁移到dpc++源代码3808的可执行工具、程序、应用程序或任何其他合适类型的工具。在至少一个实施例中,dpc++兼容性工具3802是一种基于命令行的代码迁移工具,其可用作dpc++工具包的一部分,用于将现有的cuda源移植到dpc++。在至少一个实施例中,dpc++兼容性工具3802将cuda应用程序的一些或全部源代码从cuda转换为dpc++,并生成至少部分用dpc++编写的结果文件,称为人类可读的dpc++3804。在至少一个实施例中,人类可读的dpc++3804包括由dpc++兼容性工具3802生成的注释,以指示可能需要用户干预的地方。在至少一个实施例中,当cuda源代码3800调用没有类似dpc++api的cuda api时,用户干预是必要的;
需要用户干预的其他示例将在后面更详细地讨论。
[0419]
在至少一个实施例中,用于迁移cuda源代码3800(例如,应用程序或其部分)的工作流包括创建一个或更多个编译数据库文件;使用dpc++兼容性工具3802将cuda迁移到dpc++;完成迁移并验证正确性,从而生成dpc++源代码3808;并使用dpc++编译器编译dpc++源代码3808以生成dpc++应用程序。在至少一个实施例中,兼容性工具提供了一种实用程序,该实用程序截获makefile执行时使用的命令并将它们存储在编译数据库文件中。在至少一个实施例中,文件以json格式存储。在至少一个实施例中,拦截构建命令将makefile命令转换为dpc兼容性命令。
[0420]
在至少一个实施例中,拦截-构建(intercept-build)是一种实用程序脚本,其拦截构建进程以捕获编译选项、宏定义和包括路径,并将该数据写入编译数据库文件。在至少一个实施例中,编译数据库文件是json文件。在至少一个实施例中,dpc++兼容性工具3802解析编译数据库并在迁移输入源时应用选项。在至少一个实施例中,拦截-构建的使用是可选的,但强烈推荐用于基于make或cmake的环境。在至少一个实施例中,迁移数据库包括命令、目录和文件:命令可以包括必要的编译标志;目录可包括到报头文件的路径;文件可包括到cuda文件的路径。
[0421]
在至少一个实施例中,dpc++兼容性工具3802通过尽可能生成dpc++来将用cuda编写的cuda代码(例如,应用程序)迁移到dpc++。在至少一个实施例中,dpc++兼容性工具3802作为工具包的一部分是可用的。在至少一个实施例中,dpc++工具包包括拦截-构建工具。在至少一个实施例中,拦截-构建工具创建编译数据库,该编译数据库捕获编译命令以迁移cuda文件。在至少一个实施例中,dpc++兼容性工具3802使用拦截-构建工具生成的编译数据库将cuda代码迁移到dpc++。在至少一个实施例中,非cuda c++代码和文件被原样迁移。在至少一个实施例中,dpc++兼容性工具3802生成人类可读的dpc++3804,其可以是dpc++代码,如由dpc++兼容性工具3802生成的,不能由dpc++编译器编译并且需要额外的管道来验证未正确迁移的代码部分,并且可能涉及手动干预,例如由开发人员进行干预。在至少一个实施例中,dpc++兼容性工具3802提供嵌入代码中的提示或工具以帮助开发人员手动迁移无法自动迁移的附加代码。在至少一个实施例中,迁移是针对源文件、项目或应用程序的一次性活动。
[0422]
在至少一个实施例中,dpc++兼容性工具3802能够成功地将cuda代码的所有部分迁移到dpc++,并且可以简单地存在用于手动验证和调整所生成的dpc++源代码的性能的可选步骤。在至少一个实施例中,dpc++兼容性工具3802直接生成由dpc++编译器编译的dpc++源代码3808,而不需要或不利用人工干预来修改由dpc++兼容性工具3802生成的dpc++代码。在至少一个实施例中,dpc++兼容性工具生成可编译的dpc++代码,开发人员可以根据性能、可读性、可维护性和其他各种考虑因素或其任何组合选择性地对其进行调整。
[0423]
在至少一个实施例中,至少部分地使用dpc++兼容性工具3802将一个或更多个cuda源文件迁移到dpc++源文件。在至少一个实施例中,cuda源代码包括一个或更多个头(header)文件,该头文件可以包括cuda头文件。在至少一个实施例中,cuda源文件包括可用于打印文本的《cuda.h》头文件和《stdio.h》头文件。在至少一个实施例中,向量加法内核cuda源文件的一部分可以写成或相关于:
[0424]
#include《cuda.h》
[0425]
#include《stdio.h》
[0426]
#define vector_size 256
[0427]
[]global__void vectoraddkernel(float*a,float*b,float*c)
[0428]
{
[0429]
a[threadidx.x]=threadidx.x+1.0f;
[0430]
b[threadidx.x]=threadidx.x+1.0f;
[0431]
c[threadidx.x]=a[threadidx.x]+b[threadidx.x];
[0432]
}
[0433]
int main()
[0434]
{
[0435]
float*d_a,*d_b,*d_c;
[0436]
cudamalloc(&d_a,vector_size*sizeof(float));
[0437]
cudamalloc(&d_b,vector_size*sizeof(float));
[0438]
cudamalloc(&d_c,vector_size*sizeof(float));
[0439]
vectoraddkernel《《《1,vector_size》》》(d_a,d_b,d_c);
[0440]
float result[vector_size]={};
[0441]
cudamemcpy(result,d_c,vector_size*sizeof(float),
[0442]
cudamemcpydevicetohost);
[0443]
cudafree(d_a);
[0444]
cudafree(d_b);
[0445]
cudafree(d_c);
[0446]
for(int i=0;i《vector_size;i++{
[0447]
if(i%16==0){
[0448]
printf("\n");
[0449]
}
[0450]
printf("%f",result[i]);
[0451]
}
[0452]
return 0;
[0453]
}
[0454]
在至少一个实施例中,并结合以上呈现的cuda源文件,dpc++兼容性工具3802解析cuda源代码并且用适当的dpc++和sycl头文件替换头文件。在至少一个实施例中,dpc++头文件包括助手声明。在cuda中,存在线程id的概念,相应地,在dpc++或sycl中,针对每个元素都有本地标识符。
[0455]
在至少一个实施例中,并且与以上呈现的cuda源文件相关,有两个向量a和b,它们被初始化并且向量相加结果作为vectoraddkernel()的一部分被放入向量c中。在至少一个实施例中,作为将cuda代码迁移到dpc++代码的一部分,dpc++兼容性工具3802经由本地id将用于索引工作元素的cuda线程id转换为工作元素的sycl标准寻址。在至少一个实施例中,可以优化由dpc++兼容性工具3802生成的dpc++代码——例如,通过降低nd_item的维度,从而增加存储器和/或处理器利用率。
[0456]
在至少一个实施例中并且结合以上呈现的cuda源文件,存储器分配被迁移。在至少一个实施例中,依赖于诸如平台、设备、上下文和队列之类的sycl概念,将cudamalloc()迁移到设备和上下文被传递到的统一共享存储器sycl调用malloc_device()。在至少一个实施例中,sycl平台可以具有多个设备(例如,主机和gpu设备);设备可具有多个队列,可以向其提交作业;每个设备都可具有上下文;并且上下文可具有多个设备并管理共享内存对象。
[0457]
在至少一个实施例中并结合以上呈现的cuda源文件,main()函数调用(invoke)或调用(call)vectoraddkernel()以将两个向量a和b相加并将结果存储在向量c中。在至少一个实施例中,调用vectoraddkernel()的cuda代码被dpc++代码替换,以将内核提交到命令队列以供执行。在至少一个实施例中,命令组处理程序cgh传递提交到队列的数据、同步和计算,parallel_for被调用用于调用vectoraddkernel()的该工作组中的多个全局元素和多个工作项。
[0458]
在至少一个实施例中并结合以上呈现的cuda源文件,将复制设备存储器和然后向量a、b和c的空闲存储器的cuda调用迁移到对应的dpc++调用。在至少一个实施例中,c++代码(例如,用于打印浮点变量向量的标准iso c++代码)被原样迁移,无需由dpc++兼容性工具3802进行修改。在至少一个实施例中,dpc++兼容性工具3802修改用于内存设置和/或主机调用以在加速设备上执行内核的cuda api。在至少一个实施例中并结合以上呈现的cuda源文件,相应的人类可读dpc++3804(例如,可编译的)被编写为或相关于:
[0459]
#include《cl/sycl.hpp》
[0460]
#include《dpct/dpct.hpp》
[0461]
#define vector_size 256
[0462]
void vectoraddkernel(float*a,float*b,float*c,
[0463]
sycl::nd_item《3》item_ct1)
[0464]
{
[0465]
a[item_ct1.get_local_id(2)]=item_ct1.get_local_id(2)+1.0f;
[0466]
b[item_ct1.get_local_id(2)]=item_ct1.get_local_id(2)+1.0f;
[0467]
c[item_ct1.get_local_id(2)]=
[0468]
a[item_ct1.get_local_id(2)]+b[item_ct1.get_local_id(2)];
[0469]
}
[0470]
int main()
[0471]
{
[0472]
float*d_a,*d_b,*d_c;
[0473]
d_a=(float*)sycl::malloc_device(vector_size*sizeof(float),dpct::get_current_device(),
[0474]
dpct::get_default_context());
[0475]
d_b=(float*)sycl::malloc_device(vector_size*sizeof(float),dpct::get_current_device(),
[0476]
dpct::get_default_context());
[0477]
d_c=(float*)sycl::malloc_device(vector_size*sizeof(float),dpct::get_
current_device(),
[0478]
dpct::get_default_context());
[0479]
dpct::get_default_queue_wait().submit([&](sycl::handler&cgh){
[0480]
cgh.parallel_for(
[0481]
sycl::nd_range《3》(sycl::range《3》(1,1,1)*
[0482]
sycl::range《3》(1,1,vector_size)*
[0483]
sycl::range《3》(1,1,vector_size)),
[0484]
[=](sycl::nd_items《3》item_ct1){
[0485]
vectoraddkernel(d_a,d_b,d_c,item_ct1);
[0486]
});
[0487]
});
[0488]
float result[vector_size]={};
[0489]
dpct::get_default_queue_wait()
[0490]
.memcpy(result,d_c,vector_size*sizeof(float))
[0491]
.wait();
[0492]
sycl::free(d_a,dpct::get_default_context());
[0493]
sycl::free(d_b,dpct::get_default_context());
[0494]
sycl::free(d_c,dpct::get_default_context());
[0495]
for(int i=0;i《vector_size;i++{
[0496]
if(i%16==0){
[0497]
printf("\n");
[0498]
}
[0499]
printf("%f",result[i]);
[0500]
}
[0501]
return 0;
[0502]
}
[0503]
在至少一个实施例中,人类可读的dpc++3804指的是由dpc++兼容性工具3802生成的输出并且可以以一种或另一种方式进行优化。在至少一个实施例中,由dpc++兼容性工具3802生成的人类可读的dpc++3804可以在迁移后由开发人员手动编辑以使其更易于维护、性能或其他考虑。在至少一个实施例中,由dpc++兼容性工具3802生成的dpc++代码(例如公开的dpc++)可以通过为每个malloc_device()调用删除对get_current_device()和/或get_default_context()的重复调用来优化。在至少一个实施例中,上面生成的dpc++代码使用3维nd_range,其可以重构为仅使用单个维度,从而减少内存使用。在至少一个实施例中,开发人员可以手动编辑由dpc++兼容工具3802生成的dpc++代码,用访问器替换统一共享内存的使用。在至少一个实施例中,dpc++兼容性工具3802具有改变其如何将cuda代码迁移到dpc++代码的选项。在至少一个实施例中,dpc++兼容性工具3802是冗长的,因为它使用通用模板将cuda代码迁移到dpc++代码,dpc++代码适用于大量情况。
[0504]
在至少一个实施例中,cuda到dpc++的迁移工作流包括以下步骤:使用拦截-构建脚本准备迁移;使用dpc++兼容性工具3802执行cuda项目到dpc++的迁移;人工审查和编辑
迁移的源文件以确保其完整性和正确性;以及编译最终的dpc++代码以生成dpc++应用程序。在至少一个实施例中,在一种或更多种场景中可能需要人工审查dpc++源代码,包括但不限于:迁移的api不返回错误代码(cuda代码可以返回错误代码,该错误代码随后可以被应用程序使用,但是sycl使用异常来报告错误,因此不会使用错误代码来显露错误);dpc++不支持cuda计算能力相关逻辑;无法删除语句。在至少一个实施例中,dpc++代码需要人工干预的场景可以包括但不限于:错误代码逻辑替换为(*,0)代码或注释掉;等效的dpc++api不可用;cuda计算能力相关逻辑;硬件相关api(clock());缺少特征不受支持的api;执行时间测量逻辑;处理内置向量类型冲突;cublas api的迁移;以及更多。
[0505]
在至少一个实施例中,利用图38中所描绘的一个或更多个系统来执行api以引起图形代码的描述性表示被生成。在至少一个实施例中,利用图38中所描绘的一个或更多个系统来实现一个或更多个系统和/或过程,如结合图1-6所描述的那些。
[0506]
在至少一个实施例中,本文描述的一种或更多种技术利用一个api编程模型。在至少一个实施例中,oneapi编程模型指的是用于与不同计算加速器架构交互的编程模型。在至少一个实施例中,oneapi是指被设计成与各种计算加速器架构交互的应用编程接口(api)。在至少一个实施例中,oneapi编程模型利用dpc++编程语言。在至少一个实施例中,dpc++编程语言是指用于数据并行编程生产力的高级语言。在至少一个实施例中,dpc++编程语言至少部分地基于c和/或c++编程语言。在至少一个实施例中,oneapi编程模型是诸如由加利福尼亚州圣克拉拉市的英特尔公司开发的那些编程模型。
[0507]
在至少一个实施例中,利用oneapi和/或oneapi编程模型来与各种加速器、gpu、处理器、和/或其变体、架构进行交互。在至少一个实施例中,oneapi包括实现各个功能的一组库。在至少一个实施例中,oneapi至少包括至少oneapi dpc++库、oneapi数学内核库、oneapi数据分析库、oneapi深度神经网络库、oneapi集合通信库、oneapi线程构建块库、oneapi视频处理库和/或其变型。
[0508]
在至少一个实施例中,oneapi dpc++库(也称为onedpl)是实现算法和功能以加速dpc++内核编程的库。在至少一个实施例中,onedpl实现一个或更多个标准模板库(stl)功能。在至少一个实施例中,onedpl实现一个或更多个并行stl功能。在至少一个实施例中,onedpl提供一组库类别和函数,诸如并行算法、迭代器、函数对象类、基于范围的api和/或其变型。在至少一个实施例中,onedpl实现c++标准库的一个或更多个类别和/或函数。在至少一个实施例中,onedpl实现一个或更多个随机数生成器函数。
[0509]
在至少一个实施例中,oneapi数学内核库(也称为onemkl)是实现用于各个数学函数和/或运算的各个优化和并行化例程的库。在至少一个实施例中,onemkl实现一个或更多个基本线性代数子程序(blas)和/或线性代数封装(lapack)密集线性代数例程。在至少一个实施例中,onemkl实现一个或更多个稀疏blas线性代数例程。在至少一个实施例中,onemkl实现一个或更多个随机数生成器(rng)。在至少一个实施例中,onemkl实现用于对向量进行数学运算的一个或更多个向量数学(vm)例程。在至少一个实施例中,onemkl实现一个或更多个快速傅里叶变换(fft)函数。
[0510]
在至少一个实施例中,oneapi数据分析库(也称为onedal)是实现各个数据分析应用和分布式计算的库。在至少一个实施例中,onedal以批处理、在线处理和分布式处理模式的计算实现用于数据分析的预处理、变换、分析、建模、验证和决策的各个算法。在至少一个
实施例中,onedal实现各个c++和/或java api以及对一个或更多个数据源的各种连接器。在至少一个实施例中,onedal实现对传统c++接口的dpc++api扩展,并且使得gpu能够用于各种算法。
[0511]
在至少一个实施例中,oneapi深度神经网络库(也被称为onednn)是实现各个深度学习函数的库。在至少一个实施例中,onednn实现各个神经网络、机器学习和深度学习函数、算法和/或其变型。
[0512]
在至少一个实施例中,oneapi集合通信库(也称为oneccl)是实现深度学习和机器学习工作负载的各个应用的库。在至少一个实施例中,在下级通信中间件(诸如消息传递接口(mpi)和libfabrics))上构建oneccl。在至少一个实施例中,oneccl启用一组深度学习特定优化,诸如优先化、持久操作、无序执行和/或其变型。在至少一个实施例中,oneccl实现各个cpu和gpu功能。
[0513]
在至少一个实施例中,oneapi线程构建块库(也被称为onetbb)是实现用于各个应用的各个并行化过程的库。在至少一个实施例中,onetbb被用于主机上的基于任务的共享并行编程。在至少一个实施例中,onetbb实现通用并行算法。在至少一个实施例中,onetbb实现并发容器。在至少一个实施例中,onetbb实现可扩展存储器分配器。在至少一个实施例中,onetbb实现工作窃取任务调度器。在至少一个实施例中,onetbb实现低级别同步原语(primitive)。在至少一个实施例中,onetbb是编译器无关的并且可在各个处理器上使用,例如gpu、ppu、cpu和/或其变型。
[0514]
在至少一个实施例中,oneapi视频处理库(也称为onevpl)是用于在一个或更多个应用中加速视频处理的库。在至少一个实施例中,onevpl实现各个视频解码、编码和处理功能。在至少一个实施例中,onevpl实施用于cpu、gpu和其他加速器上的媒体管线的各个功能。在至少一个实施例中,onevpl实现以媒体为中心和视频分析工作负载的设备发现和选择。在至少一个实施例中,onevpl实现用于零拷贝缓冲区共享的api原语。
[0515]
在至少一个实施例中,oneapi编程模型利用dpc++编程语言。在至少一个实施例中,dpc++编程语言是包括但不限于定义设备代码并且在设备代码和主机代码之间进行区分的cuda机制的功能相似版本的编程语言。在至少一个实施例中,dpc++编程语言可以包括cuda编程语言的功能的子集。在至少一个实施例中,使用dpc++编程语言使用oneapi编程模型来执行一个或更多个cuda编程模型操作。
[0516]
应当注意,虽然本文描述的示例实施例可以涉及cuda编程模型,但本文描述的技术可以与任何合适的编程模型一起使用,诸如hip、oneapi(例如,使用基于oneapi的编程来执行或实现本文公开的方法)、和/或其变型。
[0517]
在至少一个实施例中,以上公开的系统和/或处理器的一个或更多个组件可以与一个或更多个cpu、asic、gpu、fpga或其他硬件、电路或集成电路组件通信,其包括例如用于放大图像的放大器或上采样器、用于将图像融合、混合或添加在一起的图像混合器或图像混合器组件、用于对图像进行采样(例如,作为dsp的一部分)的采样器、被配置为执行放大图像的放大器(例如,从低分辨率图像到高分辨率图像)的神经网络电路、或用于修改或生成图像、帧或视频以调整其分辨率、大小或像素的其他硬件;以上公开的系统和/或处理器的一个或更多个组件可以使用本公开中描述的组件来执行生成或修改图像的方法、操作或指令。
[0518]
可以鉴于以下条款来描述本公开的至少一个实施例:
[0519]
条款1.一种处理器,包括:
[0520]
一个或更多个电路,用于执行应用程序编程接口(api)以使图形代码的描述性表示被生成。
[0521]
条款2.根据条款1所述的处理器,其中所述一个或更多个电路进一步用于至少部分地基于一个或更多个参数值来解析所述图形代码以生成所述描述性表示。
[0522]
条款3.根据条款1或2所述的处理器,其中所述描述性表示是文本表示。
[0523]
条款4.根据条款1-3中任一项所述的处理器,其中所述一个或更多个电路进一步用于在由与所述api相关联的参数值指示的一个或更多个位置中生成所述描述性表示。
[0524]
条款5.根据条款1-4中任一项所述的处理器,其中所述一个或更多个电路进一步用于使一个或更多个图形处理单元(gpu)生成所述描述性表示。
[0525]
条款6.根据条款1-5中任一项所述的处理器,其中所述api是运行时api。
[0526]
条款7.一种系统,包括:
[0527]
一个或更多个计算机,具有一个或更多个处理器,所述一个或更多个处理器用于执行应用程序编程接口(api)以使图形代码的描述性表示被生成。
[0528]
条款8.根据条款7所述的系统,其中所述一个或更多个处理器进一步用于:
[0529]
至少部分地基于一个或更多个参数值获得一个或更多个特征;以及
[0530]
至少部分地基于所述一个或更多个特征生成所述描述性表示。
[0531]
条款9.根据条款7或8所述的系统,其中所述图形代码指示一个或更多个操作以及所述一个或更多个操作之间的依赖关系。
[0532]
条款10.根据条款7-9中任一项所述的系统,其中所述一个或更多个处理器进一步用于获得作为执行api的结果的状态指示。
[0533]
条款11.根据条款7-10中任一项所述的系统,其中所述一个或更多个处理器用于使所述图形代码的所述描述性表示使用一个或更多个并行处理单元(ppu)来生成。
[0534]
条款12.根据条款7-11中任一项所述的系统,其中所述描述性表示是图像表示。
[0535]
条款13.一种机器可读介质,其上存储有一组指令,所述一组指令如果由一个或更多个处理器执行,则使所述一个或更多个处理器至少:
[0536]
执行应用程序编程接口(api)以引起图形代码的描述性表示被生成。
[0537]
条款14.根据条款13所述的机器可读介质,其中所述一组指令进一步包括指令,所述指令如果由所述一个或更多个处理器执行,则使所述一个或更多个处理器生成对所述图形代码的一个或更多个值进行编码的所述描述性表示。
[0538]
条款15.根据条款13或14所述的机器可读介质,其中所述一组指令进一步包括指令,所述指令如果由所述一个或更多个处理器执行,则使所述一个或更多个处理器生成所述图形代码的一组描述性表示。
[0539]
条款16.根据条款13-15中任一项所述的机器可读介质,其中所述一组指令进一步包括指令,所述指令如果由所述一个或更多个处理器执行,则使所述一个或更多个处理器使得一个或更多个中央处理单元(cpu)生成所述图形代码的所述描述性表示。
[0540]
条款17.根据条款13-16中任一项所述的机器可读介质,其中:
[0541]
所述图形代码编码一个或更多个内核;以及
[0542]
所述描述性表示指示与所述一个或更多个内核相关联的信息。
[0543]
条款18.根据条款13-17中任一项所述的机器可读介质,其中所述描述性表示被表示为一个或更多个文件。
[0544]
条款19.一种方法,包括:
[0545]
执行应用程序编程接口(api)以使图形代码的描述性表示被生成。
[0546]
条款20.根据条款19所述的方法,进一步包括:
[0547]
基于与所述api相关联的一个或更多个参数值,从所述图形代码获得一个或更多个值;以及
[0548]
对所述描述性表示中的所述一个或更多个值进行编码。
[0549]
条款21.根据条款19或20所述的方法,其中所述描述性表示至少指示与所述图形代码相关联的拓扑。
[0550]
条款22.根据条款19-21中任一项所述的方法,所述api是驱动程序api。
[0551]
条款23.根据条款19-22中任一项所述的方法,还包括获得与所述api对应的状态的指示。
[0552]
条款24.根据条款19-23中任一项所述的方法,还包括使一个或更多个通用图形处理单元(gpgpu)生成所述图形代码的所述描述性表示。
[0553]
其他变型在本公开的精神内。因此,尽管公开的技术易于进行各种修改和替代构造,但是某些示出的其实施例在附图中示出并且已经在上面进行了详细描述。然而,应理解,无意将公开内容限制为所公开的一种或更多种特定形式,而是相反,其意图是涵盖落入如所附权利要求书所定义的本公开内容的精神和范围内的所有修改、替代构造和等同物。
[0554]
除非另有说明或显然与上下文矛盾,否则在描述所公开的实施例的上下文中(特别是在所附权利要求的上下文中),术语“一”和“一个”和“该”以及类似指代的使用应被解释为涵盖单数和复数,而不是作为术语的定义。除非另有说明,否则术语“包括”、“具有”、“包含”和“含有”应被解释为开放式术语(意味着“包括但不限于”)。术语“连接”(在未经修改时指的是物理连接)应解释为部分或全部包含在内、附接到或连接在一起,即使有某些介入。除非本文另外指出,否则本文中对数值范围的引用仅旨在用作分别指代落入该范围内的每个单独值的简写方法,并且每个单独值都被并入说明书中,就如同其在本文中被单独叙述一样。除非另外指出或与上下文矛盾,否则术语“集”(例如“项目集”)或“子集”的使用应解释为包括一个或更多个成员的非空集合。此外,除非另外指出或与上下文矛盾,否则术语相应集的“子集”不一定表示对应集的适当子集,而是子集和对应集可以相等。
[0555]
除非以其他方式明确指出或与上下文明显矛盾,否则诸如“a,b和c中的至少一个”或“a,b与c中的至少一个”形式的短语之类的连接语在上下文中理解为通常用来表示项目、条款等,其可以是a或b或c,也可以是a和b和c集的任何非空子集。例如,在具有三个成员的集的说明性示例中,连接短语“a,b和c中的至少一个”和“a,b与c中的至少一个”是指以下任意集:{a},{b},{c},{a,b},{a,c},{b,c},{a,b,c}。因此,这种连接语言通常不旨在暗示某些实施例要求存在a中的至少一个,b中的至少一个和c中的至少一个。另外,除非另有说明或与上下文矛盾,否则术语“多个”表示复数的状态(例如,“多个项目”表示多个项目)。多个项目中项目的数量至少为两个,但如果明确指示或通过上下文指示,则可以更多。此外,除非另有说明或从上下文中可以清楚得知,否则短语“基于”是指“至少部分地基于”而不是“仅基于”。
[0556]
除非本文另外指出或与上下文明显矛盾,否则本文描述的过程的操作可以任何合适的顺序执行。在至少一个实施例中,诸如本文所述的那些过程(或其变形和/或其组合)之类的过程在配置有可执行指令的一个或更多个计算机系统的控制下执行,并且被实现为代码(例如,可执行指令,一个或更多个计算机程序或一个或更多个应用程序),该代码通过硬件或其组合在一个或更多个处理器上共同执行。在至少一个实施例中,代码以例如计算机程序的形式存储在计算机可读存储介质上,该计算机程序包括可由一个或更多个处理器执行的多个指令。在至少一个实施例中,计算机可读存储介质是非暂时性计算机可读存储介质,其排除了暂时性信号(例如,传播的瞬态电或电磁传输),但包括非暂时性数据存储电路(例如,缓冲区、高速缓存和队列)。在至少一个实施例中,代码(例如,可执行代码或源代码)被存储在其上存储有可执行指令的一组一个或更多个非暂时性计算机可读存储介质(或用于存储可执行指令的其他存储器)上,该可执行指令在由计算机系统的一个或更多个处理器执行时(例如,作为被执行的结果),使得计算机系统执行本文所述的操作。在至少一个实施例中,一组非暂时性计算机可读存储介质包括多个非暂时性计算机可读存储介质,并且多个非暂时性计算机可读存储介质中的个体非暂时性存储介质中的一个或更多个缺少全部代码,而是多个非暂时性计算机可读存储介质共同存储全部代码。在至少一个实施例中,可执行指令被执行,以使得不同的指令由不同的处理器执行,例如,非暂时性计算机可读存储介质存储指令,并且主中央处理单元(“cpu”)执行一些指令,而图形处理单元(“gpu”)执行其他指令。在至少一个实施例中,计算机系统的不同组件具有单独的处理器,并且不同的处理器执行指令的不同子集。
[0557]
因此,在至少一个实施例中,计算机系统被配置为实现单独地或共同地执行本文所述的过程的操作的一个或更多个服务,并且这样的计算机系统被配置有使能实施操作的适用的硬件和/或软件。此外,实现本公开的至少一个实施例的计算机系统是单个设备,并且在另一实施例中是分布式计算机系统,其包括以不同方式操作的多个设备,使得分布式计算机系统执行本文所述的操作,并且使得单个设备不执行所有操作。
[0558]
本文提供的任何和所有示例或示例性语言(例如,“诸如”)的使用仅旨在更好地阐明本公开的实施例,并且不对公开的范围构成限制,除非另有要求。说明书中的任何语言都不应被解释为表示任何未要求保护的要素对于实践公开内容是必不可少的。
[0559]
本文引用的所有参考文献,包括出版物、专利申请和专利,均通过引用并入本文,其程度就如同每个参考文献被单独且具体地指示为以引用的方式并入本文并且其全部内容在本文中阐述一样。
[0560]
在说明书和权利要求中,可以使用术语“耦合”和“连接”以及它们的派生词。应当理解,这些术语可能不旨在作为彼此的同义词。相反,在特定示例中,“连接”或“耦合”可用于指示两个或更多个元件彼此直接或间接物理或电接触。“耦合”也可能意味着两个或更多个元素彼此不直接接触,但仍彼此协作或交互。
[0561]
除非另有明确说明,否则可以理解,在整个说明书中,诸如“处理”、“计算”、“计算”、“确定”等之类的术语,是指计算机或计算系统或类似的电子计算设备的动作和/或过程,其将计算系统的寄存器和/或存储器中表示为物理量(例如电子)的数据处理和/或转换为类似表示为计算系统的存储器、寄存器或其他此类信息存储、传输或显示设备中的物理
量的其他数据。
[0562]
以类似的方式,术语“处理器”可以指处理来自寄存器和/或存储器的电子数据并将该电子数据转换成可以存储在寄存器和/或存储器中的其他电子数据的任何设备或存储器的一部分。作为非限制性示例,“处理器”可以是cpu或gpu。“计算平台”可以包括一个或更多个处理器。如本文所使用的,“软件”进程可以包括例如随时间执行工作的软件和/或硬件实体,诸如任务、线程和智能代理。同样,每个过程可以指代多个过程,以连续地或间歇地顺序地或并行地执行指令。术语“系统”和“方法”在本文中可以互换使用,只要系统可以体现一种或更多种方法,并且方法可以被认为是系统。
[0563]
在至少一个实施例中,算术逻辑单元是一组组合逻辑电路,其采用一个或更多个输入来产生结果。在至少一个实施例中,处理器使用算术逻辑单元来实现数学运算,诸如加法、减法或乘法。在至少一个实施例中,算术逻辑单元用于实现逻辑运算,诸如逻辑and/or或xor。在至少一个实施例中,算术逻辑单元是无状态的,并且由被布置为形成逻辑门的物理开关组件(诸如半导体晶体管)制成。在至少一个实施例中,算术逻辑单元可以在内部操作为具有相关联的时钟的有状态逻辑电路。在至少一个实施例中,算术逻辑单元可被构造为具有未维持在相关联的寄存器组中的内部状态的异步逻辑电路。在至少一个实施例中,算术逻辑单元被处理器用来组合被存储在处理器的一个或更多个寄存器中的操作数,并产生可以被处理器存储在另一寄存器或存储器位置中的输出。
[0564]
在至少一个实施例中,作为处理由处理器检索的指令的结果,处理器向算术逻辑单元呈现一个或更多个输入或操作数,从而使得算术逻辑单元至少部分地基于提供给算术逻辑单元的输入的指令代码来产生结果。在至少一个实施例中,由处理器提供给alu的指令代码至少部分地基于由处理器执行的指令。在至少一个实施例中,alu中的组合逻辑处理输入并产生输出,该输出被放置在处理器内的总线上。在至少一个实施例中,处理器选择输出总线上的目的地寄存器、存储器位置、输出设备或输出存储位置,使得对处理器进行计时使得将alu产生的结果发送到所需位置。
[0565]
在本文件中,可以参考获得、获取、接收或将模拟或数字数据输入子系统、计算机系统或计算机实现的机器中。可以通过多种方式来完成获得、获取、接收或输入模拟和数字数据的过程,例如通过接收作为函数调用或对应用程序编程接口的调用的参数的数据。在一些实现方式中,可以通过经由串行或并行接口传输数据来完成获得、获取、接收或输入模拟或数字数据的过程。在另一实现方式中,可以通过经由计算机网络将数据从提供实体传输到获取实体来完成获得、获取、接收或输入模拟或数字数据的过程。也可以参考提供、输出、传送、发送或呈现模拟或数字数据。在各种示例中,提供、输出、传送、发送或呈现模拟或数字数据的过程可以通过将数据作为函数调用的输入或输出参数、应用程序编程接口或进程间通信机制的参数进行传输来实现。
[0566]
尽管上面的讨论阐述了所描述的技术的示例实现,但是其他架构可以用于实现所描述的功能,并且旨在落入本公开的范围内。此外,尽管出于讨论的目的在上面定义了具体的职责分配,但是根据情况,可以以不同的方式分配和划分各种功能和职责。
[0567]
此外,尽管已经用特定于结构特征和/或方法动作的语言描述了主题,但是应当理解,所附权利要求书所要求保护的主题不必限于所描述的特定特征或动作。而是,公开了特定的特征和动作作为实现权利要求的示例性形式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1