用于读取树数据结构中保存的数据的方法和装置与流程
本发明涉及数据库数据处理和分布式数据库管理领域,尤其涉及使用云原生数据库中的近数据处理(near data processing,ndp)读取树数据结构中保存的数据的方法和装置。
背景技术:
1、随着许多公司和政府机构使用的计算机应用、平台或基础设施现在越来越多地放置在云中,对基于云的数据库即服务(database as a service,dbaas)的需求正在迅速增加。随着市场和商业模式的转变,此类dbaas服务由amazontm、microsofttm、googletm、alibabatm、huaweitm和其它云提供商提供。最初,这些提供商使用传统的单片数据库软件提供dbaas服务。换句话说,这些提供商只是使用本地存储或云存储在云中的虚拟机上运行常规版本的数据库系统。虽然实现简单,但这种方法可能无法为客户提供其希望从数据库服务中获得的功能。例如,这种形式的数据库系统不能提供良好的性能和可扩展性,而且可能会产生较高的存储成本。
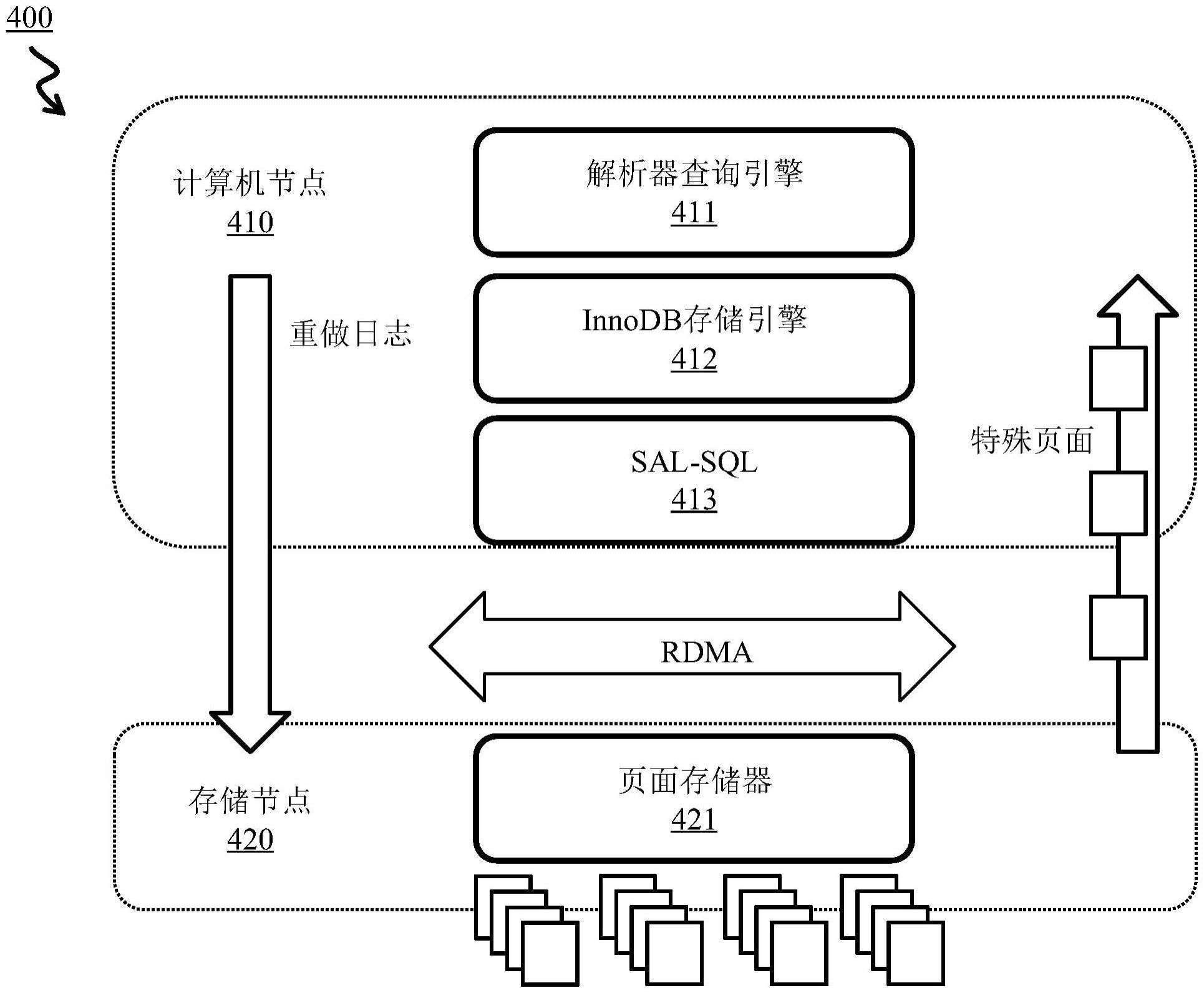
2、图1示出了使用传统数据库架构的典型数据库部署。参考图1,传统数据库架构100包括结构化查询语言(structured query language,sql)主节点110、sql副本120以及存储节点131和132。sql主节点110和sql副本120彼此通信连接。sql主节点110和sql副本120中的每一个分别通过网络140通信连接到存储节点131和132。sql主节点110将日志写入其自己的存储节点131,并将日志传输到sql副本120。sql副本120中的每一个在各自的存储节点132上应用日志。数据库的数据页面将冗余地保存在三个存储节点中,即主存储节点和与副本关联的每个存储节点。假设云中的每个存储节点通常有3个副本,在该数据库架构100中,数据页面将被保存9次,从而造成大量的资源浪费。
3、因此,需要一种不受现有技术的一个或多个限制影响的用于读取数据库中数据的方法和装置。
4、背景技术的目的是揭示申请人认为可能与本发明相关的信息。没有必要承认也不应解释任何上述信息构成与本发明相对的现有技术。
技术实现思路
1、本发明实施例的目的是提供用于使用云原生数据库中的近数据处理(near dataprocessing,ndp)读取树数据结构中保存的数据的方法和装置。根据本发明的实施例,提供了用于响应于使用云原生数据库中的近数据处理(near data processing,ndp)的查询获得一个或多个页面的方法。所述方法包括:接收查询,所述查询包括指示一个或多个所需页面的信息,所述信息还指示所述一个或多个所需页面中的每个所需页面的版本;扫描通用缓冲池以标识所述所需页面中的一个或多个所需页面。在标识所述通用缓冲池中的所述所需页面中的一个或多个所需页面时,所述方法还包括:将经标识的一个或多个所需页面复制到与所述查询关联的专用缓冲池中。在标识所述通用缓冲池中没有其它所需页面时,所述方法还包括:向一个或多个存储节点发送对剩余待标识的所述所需页面中的一个或多个所需页面的请求。所述方法还包括:接收所述一个或多个剩余所需页面;将接收到的一个或多个剩余所需页面复制到所述专用缓冲池中。
2、在一些实施例中,所述方法还包括:在复制所述经标识的一个或多个所需页面之前,将共享锁应用于所述经标识的一个或多个所需页面。在一些实施例中,所述一个或多个所需页面的版本由日志序列号(log sequence number,lsn)定义。在一些实施例中,所述方法还包括:在与所述一个或多个所需页面关联的b+树的根上应用共享锁。在一些实施例中,所述方法还包括:将所述接收到的一个或多个剩余所需页面复制到所述通用缓冲池中。
3、根据本发明的实施例,提供了一种使用云原生数据库中的近数据处理(near dataprocessing,ndp)读取数据树中数据的方法。所述方法包括:以自上而下的方式在所述数据树的根页面和内部页面上应用共享页面锁,直到到达p0,所述p0是指位于紧接在所述数据树的叶级上方的级上的页面;获取期望的日志序列号(log sequence number,lsn),同时保持所述p0上的所述共享页面锁。在获取期望lsn之后,对于每个提取的子页面,所述方法还包括:将页面从缓冲池的空闲列表分配给所述缓冲池的ndp缓存区域,所述ndp缓存区域指定用于特定查询;在将所述页面分配给所述ndp缓存区域时,判断所述子页面是否在所述缓冲池的常规页面区域找到;基于所述确定,将所述子页面固定到在所述ndp缓存区域中分配的所述页面。所述方法还包括:释放所述p0上应用的所述共享页面锁;处理分配给所述ndp缓存区域的所述页面;在处理完成后,将分配给所述ndp缓存区域的所述页面中的每个页面释放回所述缓冲池的所述空闲列表。
4、根据本发明的实施例,提供了一种支持云原生数据库中的近数据处理(near dataprocessing,ndp)的设备。所述设备包括:网络接口,用于从连接到网络的设备接收数据和向连接到网络的设备发送数据;处理器;机器可读存储器,存储机器可执行指令。在所述指令由所述处理器执行时,使所述设备执行上面或本文其它地方定义的一个或多个方法。
5、上面结合本发明的方面描述了实施例,这些实施例可以基于这些方面实现。本领域技术人员将理解,实施例可以结合描述它们的方面来实现,但也可以与该方面的其它实施例一起实现。当实施例相互排斥或彼此不兼容时,本领域技术人员将是显而易见的。一些实施例可以结合一个方面进行描述,但也可以适用于其它方面,这对本领域技术人员来说是显而易见的。
技术特征:
1.一种用于响应于使用云原生数据库中的近数据处理(near data processing,ndp)的查询获得一个或多个页面的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,还包括在复制所述经标识的一个或多个所需页面之前,将共享锁应用于所述经标识的一个或多个所需页面。
3.根据权利要求2所述的方法,其特征在于,还包括在所述经标识的一个或多个所需页面被复制之后,释放所述共享锁。
4.根据权利要求1所述的方法,其特征在于,所述一个或多个所需页面的版本由日志序列号(log sequence number,lsn)定义。
5.根据权利要求4所述的方法,其特征在于,lsn最大值定义最新版本。
6.根据权利要求1所述的方法,其特征在于,还包括在与所述一个或多个所需页面关联的b+树的根上应用共享锁。
7.根据权利要求6所述的方法,其特征在于,还包括释放所述b+树的所述根上的所述共享锁。
8.根据权利要求1所述的方法,其特征在于,还包括将所述接收到的一个或多个剩余所需页面复制到所述通用缓冲池中。
9.一种支持云原生数据库中的近数据处理(near data processing,ndp)的设备,其特征在于,所述设备包括:
10.一种使用云原生数据库中的近数据处理(near data processing,ndp)读取数据树中数据的方法,其特征在于,所述方法包括:
11.根据权利要求10所述的方法,其特征在于,还包括:
12.根据权利要求11所述的方法,其特征在于,所述最后一个子页面在所述ndp缓存区域中,并且所述下一个访问页面是基于使用所述最后一个子页面上的最后一个记录发起的对所述数据树的另一搜索来确定的。
13.根据权利要求11所述的方法,其特征在于,所述最后一个子页面在所述常规页面区域中,所述下一个访问页面是基于所述最后一个子页面的下一个页面标识符(identifier,id)确定的。
14.根据权利要求10所述的方法,其特征在于,所述子页面在所述缓冲池的常规页面区域找到,所述固定所述子页面包括:
15.根据权利要求10所述的方法,其特征在于,所述子页面在所述缓冲池的常规页面区域未找到,所述固定所述子页面包括:
16.根据权利要求15所述的方法,其特征在于,多个子页面通过一个输入/输出(input/output,io)请求被提交到存储节点。
17.根据权利要求10所述的方法,其特征在于,所述期望lsn仅在读取所述p0的所述子页面的时段内有效。
18.根据权利要求10所述的方法,其特征在于,分配给所述ndp缓存区域的所述页面的分配和释放仅在请求所述ndp的所述查询的控制下进行。
19.根据权利要求10所述的方法,其特征在于,所述数据树是b+树。
20.一种支持云原生数据库中的近数据处理(near data processing,ndp)的设备,其特征在于,包括:
技术总结
本发明提供了一种使用云原生数据库中的近数据处理(near data processing,NDP)读取在树数据结构中保存的数据的方法,所述树数据结构例如是B+树。根据实施例,期望LSN将用于主计算节点(例如主SQL节点)上的NDP页面读取。当所述主计算节点(例如主SQL节点)读取常规页面时,将使用所述常规页面的最大期望LSN(例如最新的页面版本号)。实施例使用所述期望LSN和页面锁定的特征,其中,页面的正确版本可以通过与页面关联的所述期望LSN结合页面锁定获得,并且可以实现一致的树结构的所述读取,并实现良好的读/写并发。
技术研发人员:林舒,陈翀
受保护的技术使用者:华为云计算技术有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!