用于图像降噪的噪声重建的制作方法
发明领域本发明涉及计算机视觉,尤其涉及使用深度神经网络,如卷积神经网络(convolutional neural network,cnn)进行图像分析。
背景技术:
1、图像降噪旨在从底层干净图像的噪声观测中估计底层干净图像,是许多数字成像和计算机视觉系统中的重要一步。
2、图1(a)示出了噪声的存在如何影响图像质量。图1(b)示出了通过将图像降噪技术应用于噪声图像而提高图像质量(来自kai zhang、wangmeng zuo、yunjin chen、deyu meng和lei zhang于2017年发表在《ieee图像处理汇刊》的《超越高斯去噪:深度cnn图像去噪的残差学习》(beyond a gaussian denoiser:residual learning of deep cnn for imagedenoising,ieee transactions on image processing,2017))。
3、相机传感器在线性颜色空间中输出raw数据,其中像素测量值与收集的光电子数量成正比。噪声的主要来源是散粒噪声和读取噪声,散粒噪声是一个方差等于信号电平的泊松过程,读取噪声是一个由各种传感器读出效应引起的近似高斯过程。这些效应通过信号相关的高斯分布进行了很好的建模:
4、
5、其中xp是像素p处真实强度yp的噪声测量值。噪声参数σr和σs对于每个图像是固定的,但可以随着传感器增益(iso)的变化而因图像而异。
6、然而,真实图像中的噪声来自各种来源(例如暗电流噪声和热噪声),而且要复杂得多。虽然已较了解raw传感器数据中的噪声,但在rgb域中,捕获和显示之间执行的后处理(如去马赛克、锐化、色调映射和压缩)使得噪声模型更加复杂,这使得图像降噪任务更具挑战。
7、例如,通过考虑相机内图像处理管道,信道无关噪声假设可能不成立。一般来说,真实的噪声模型和相机内图像处理管道是训练基于cnn的真实照片降噪方法的重要方面。
8、传统的单图像降噪算法通常使用数学工具和数学模型(包括偏微分方程、稀疏编码和低秩近似)对图像的特性和这些算法旨在去除的噪声进行分析建模。这些方法中的大多数依赖于非常有限的人类知识或先前关于图像的假设,这限制了这些方法恢复复杂图像结构的能力。相比之下,现代降噪方法通常使用神经网络来学习从噪声图像到无噪图像的映射。深度学习能够表现图像和噪声的复杂属性,但训练这些模型需要大型配对数据集。因此,大多数基于学习的降噪技术依赖于合成的训练数据。近期基准测试表明,在真实的噪声图像上评估时,一些深度学习模型的性能往往劣于传统的手工提取算法。
9、通过堆叠卷积、批归一化、relu层以及采用残差学习的思想,kai zhang、wangmengzuo、yunjin chen、deyu meng和lei zhang于2017年发表在《ieee图像处理汇刊》的《超越高斯去噪:深度cnn图像去噪的残差学习》(beyond a gaussian denoiser:residuallearning of deep cnn for image denoising,ieee transactions on imageprocessing,2017)中所述的dncnn方法实现了比传统最先进的方法高得多的psnr指数。为了追求高精度的降噪结果,已经提出了一些复杂的网络,例如ying tai、jian yang、xiaoming liu和chunyan xu于2017年在国际计算机视觉与模式识别会议中发表的《memnet:一种用于图像恢复的持久性记忆网络》(memnet:a persistent memory networkfor image restoration,cvpr,2017)。
10、生成对抗网络(generative adversarial network,gan)降噪方法包括生成器模块和鉴别器模块,生成器和鉴别器模块通常通过交替梯度下降法优化。生成器从先验分布pz中采样z,例如均匀分布,并尝试对目标分布pd建模。鉴别器d的目的是区分从模型生成的样本和目标(地面真值)分布。
11、mehdi mirza和simon osindero于2014年发表在arxiv预印本arxiv:1411.1784中的《条件生成对抗网络》(conditional generative adversarial nets,arxiv preprintarxiv:1411.1784,2014)中所述的条件gan(conditional gan,cgan)通过为生成器提供额外的标签来扩展公式。生成器g通常采取编码器-解码器网络的形式,其中编码器将标签投影到低维潜在子空间中,解码器执行相反的映射,即从低维子空间到高维子空间。如果s表示条件标签,y表示目标分布中的样本,则对抗损失表示为:
12、
13、通过解决以下最小-最大问题:
14、
15、其中,wg,wd分别表示生成器和鉴别器的参数。为了简化符号,下面的描述中省略了对参数和噪声z的依赖。
16、扩展条件gan方法的一种方法是如g.chrysos等人在2019年在国际表征学习大会上发表的《鲁棒条件生成对抗网络》(robust conditional generative adversarialnetworks,iclr,2019)中所述的鲁棒条件gan(robust conditional gan,rocgan)。在rocgan中,gan有生成器模块和鉴别器模块,生成器模块和鉴别器模块通常通过交替梯度下降方法进行优化。生成器从先验分布(例如均匀分布)中采样,并尝试对目标分布进行建模。鉴别器试图区分从模型生成的样本和目标(地面真值)分布。
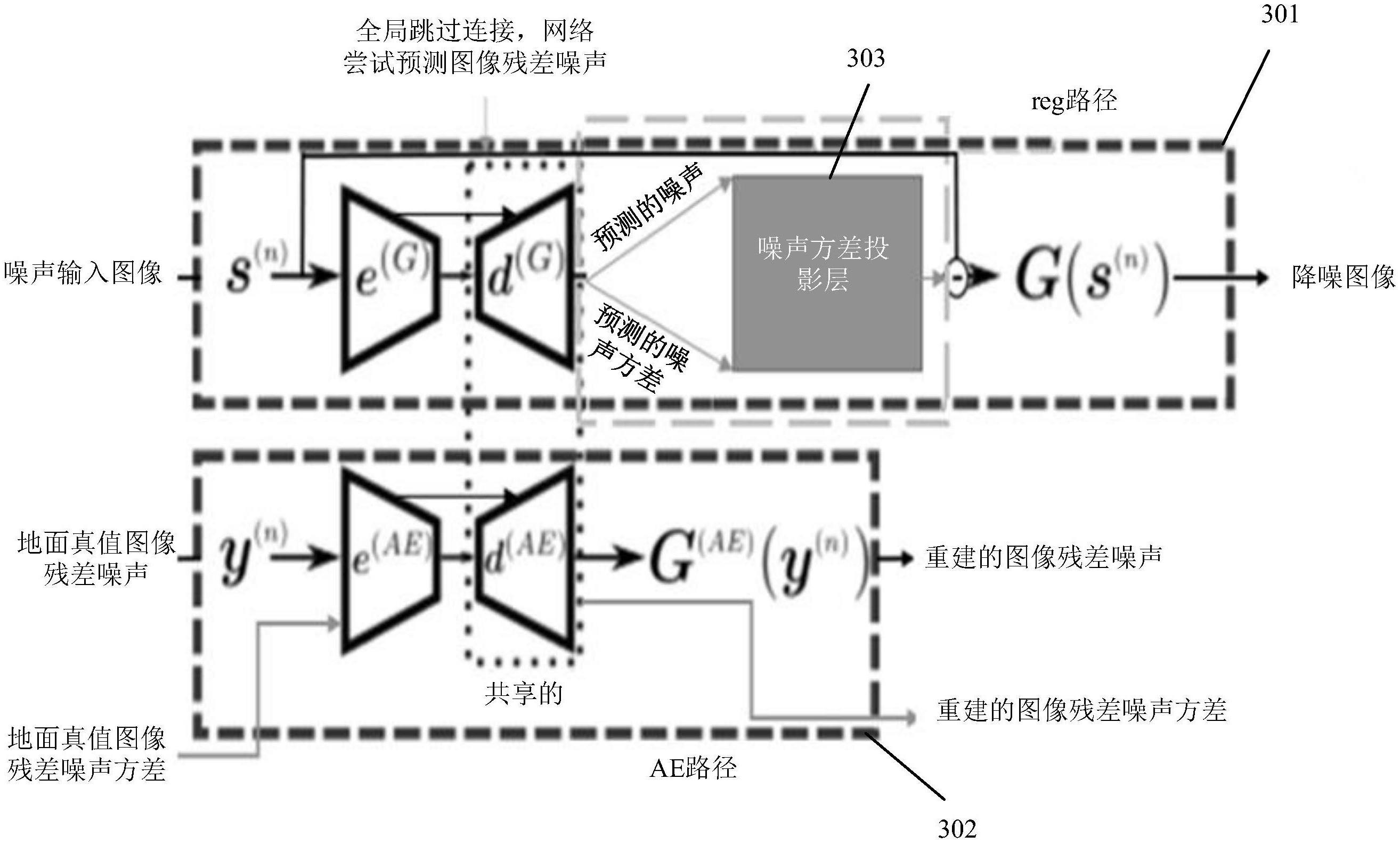
17、在这种方法中,生成器通过无监督路径增强,以鼓励生成器的输出跨越目标流形(manifold),即使在存在大量噪音的情况下。第一路径,称为reg路径,执行与cgan中对应的类似的回归(降噪)。该路径接受来自源域(噪声图像)的样本,并将其映射到目标域(干净图像)。额外的ae路径在目标域中用作自动编码器。
18、在rocgan中,ae路径导致以下损失项:
19、
20、其中fd表示分歧度量(l1损失),上标“ae”为ae路径模块的缩写,“g”为reg路径模块的缩写,g(ae)(y(n))=d(ae)(e(ae)(y(n)))是ae路径的输出。
21、这两个路径具有相同的编码器-解码器网络。通过共享解码器的权重,rocgan促进回归输出跨越目标流形,而不产生任意大的误差。跳过连接可以在rocgan中使用,使更深层能够捕获更抽象的表征,而无需记忆所有信息。较低级别的表征通过快捷方式直接传播到解码器。
22、尽管共享编码器的权重,rocgan迫使两条路径的潜在表征跨越相同的空间。为了进一步减小两个表征在潜在空间中的距离,使用潜在损失项此项最小化编码器输出之间的距离,即两个表征在空间上是接近的(在编码器跨越的子空间中)。
23、潜在损失项由以下公式给出:
24、
25、特征匹配损失使网络能够更快地匹配数据和模型的分布。直觉是,为了将数据的高维分布与reg路径相匹配,它们在低维空间中的投影被鼓励相似。
26、特征匹配损失由以下公式给出:
27、
28、其中,π()从鉴别器的倒数第二层提取特征。
29、跳过连接可以使更深层能够捕获更抽象的表征,而无需记忆所有信息。较低级别的表征通过快捷方式直接传播到解码器,这使得训练更长的路径变得更加困难,即不包括跳过连接的网络。通过最大化更长路径表征捕获的方差,隐式地解决了这一挑战。使用deov损失项,deov损失项惩罚(层的)表征中的相关性,从而隐式地鼓励表征捕获多样化和有用的信息。此损失可以应用于网络中的单层或多层,而对于jth层,此损失定义为:
30、
31、其中diag()计算矩阵的对角线元素,cj是jth层表征的协方差矩阵。当协方差矩阵是对角矩阵时,损失最小化,即最小化隐藏单元的协方差而不限制包括隐藏表征方差的对角线元素带来了成本。
32、通过定义g(s(n))=d(g)(e(g)(s(n)))为reg路径的输出,rocgan的最终损失函数将原始cgan的损失项与ae路径的额外三个项结合在一起:
33、
34、其中λc,λπ,λae,λl,和λd是平衡损失项的超参数。
35、该方法可用于图像降噪,但是为对象相关的图像降噪而设计的。
36、ae路径是一种无监督学习方法,其隐藏层包含输入数据的表征,用于压缩(和解压缩)数据,同时丢失尽可能少的信息。然而,即使存在跳过连接,ae路径也无法重建所有自然场景和模式。换句话说,使用一个自动编码器来定义可以从各种真实复杂对象/场景准确地重建图像模式的非线性流形是不现实的。因此,以前的方法,如rocgan,经常通过引入严重的模糊效果或不自然的图像模式/伪影来产生复杂的图像结构的幻觉。
37、这些方法的大量计算和内存占用也阻碍了它们在硬件受限设备上的应用,如智能手机或消费电子产品。此外,这些方法试图利用图像先验来更好地建模干净图像。考虑到所有自然图像模式的多样性,这是一个非常复杂的问题。
38、i.marras等人在2020年欧洲计算机视觉会议中发表的《重构图像去噪的噪声方差流形》(reconstructing the noise variance manifold for image denoising,eccv2020)中所述的方法使用跨越目标图像信号相关噪声流形的重建噪声执行图像降噪。基于具有两个路径模块和共享的解码器参数的编码器-解码器生成器使用对抗神经网络。第一路径基于残差学习作为生成器执行回归,而生成器通过第二路径增强,第二路径促进生成器从噪声输入中去除跨越目标图像信号相关噪声流形的残差噪声。生成器的示意图如图2所示。reg路径在201处示出,ae路径在202处示出。
39、随着智能手机年销量超过15亿部,现在智能手机拍摄的照片数量远远超过数码单反和傻瓜相机也就不足为奇了。虽然智能手机的流行使其成为一种方便的摄影设备,但由于其相机中的传感器和镜头较小,其图像通常会因较高的噪声水平而退化。这个问题亟需优化图像降噪,特别是在智能手机图像方面。
40、需要开发一种克服这些问题的图像降噪方法。
技术实现思路
1、根据第一方面,提供了一种用于图像降噪的装置,该装置包括处理器,用于:接收由图像传感器捕获的输入图像;执行经过训练的人工智能模型,以:形成输入图像中噪声模式的估计;形成捕获输入图像的图像传感器的至少一个噪声统计量的估计;以及根据至少一个噪声统计量的估计来细化噪声模式的估计;以及通过从输入图像中减去噪声模式的细化估计来形成输出图像。
2、考虑捕获输入图像的传感器的噪声统计量,可以使降噪图像的质量提高。
3、该模型可以用于通过在经过训练的噪声流形上的投影来细化噪声模式的估计。使用这种方法,有意义的图像结构可以通过降噪过程更好地保留,图像质量得到提高。
4、该模型可以用于将噪声模式估计和至少一个噪声统计量的估计投影到同一个经过训练的噪声流形上。这可以使噪声统计量,例如噪声标准差信息,能够用于校正模型最初估计的预测的噪声的统计量。
5、至少一个噪声统计量可以包括图像传感器的噪声方差。网络的噪声方差投影层可以显式地利用噪声标准差信息来校正生成器最初估计的预测的噪声的统计信息。
6、噪声模式的估计可以是空间自适应高斯分布。这可以实现方便地估计噪声估计。
7、该装置可用于接收捕获输入图像的图像传感器的具体图像传感器类型的指示,其中该装置用于提供该指示作为模型的输入。向噪声模型提供捕获图像的传感器的类型指示可以提高图像质量。
8、该装置可以包括具有捕获输入图像的图像传感器的成像设备。该装置可以用于使用成像设备生成输入图像,以及提供具体图像传感器类型的指示作为模型的输入。向噪声模型提供捕获图像的传感器的类型指示可以提高图像质量。
9、该模型可以用于根据图像传感器的噪声参数估计至少一个噪声统计量。噪声参数中的至少一个可以是可学习的。
10、经过训练的人工智能模型可以是神经网络。这可以是一种方便的实现方式。
11、神经网络可以包括具有第一路径和第二路径的编码器-解码器生成器架构。通过第二路径增强生成器可以有助于促进生成器从噪声输入中去除跨越目标图像信号相关噪声流形的残差噪声。
12、第一和第二路径的解码器的权重可以共享。通过共享解码器的权重,rocgan促进回归输出跨越目标流形,而不产生任意大的误差。
13、第一路径可以用于充当执行回归的生成器,并通过第二路径增强,第二路径促进生成器从输入图像中减去噪声模式的细化估计。
14、输入图像可以是rgb图像。输入图像可以是raw图像。这可以使该装置能够用于诸如智能手机的设备中,以去除由此类设备的相机捕获的图像中的噪音。
15、根据第二方面,提供了一种用于图像降噪的方法,该方法包括:接收由图像传感器捕获的输入图像;执行经过训练的人工智能模型,以:形成输入图像中噪声模式的估计;形成捕获输入图像的图像传感器的至少一个噪声统计量的估计;以及根据至少一个噪声统计量的估计细化噪声模式的估计;以及通过从输入图像中减去噪声模式的细化估计来形成输出图像。
16、考虑捕获输入图像的传感器的噪声统计量,可以使降噪图像的质量提高。
17、根据另一方面,提供了一种用于训练模型以对图像执行降噪的方法,该方法包括:接收多个输入图像,每个输入图像由图像传感器捕获;接收多个噪声签名;接收捕获多个输入图像的图像传感器的至少一个噪声统计量;对于多个输入图像中的每一个:
18、(i)选择多个噪声签名中的一个,并将该噪声签名应用于输入图像以形成噪声输入图像;
19、(ii)通过在噪声输入图像上实施模型的候选版本,形成输入图像中的第一噪声估计和捕获输入图像的图像传感器的至少一个噪声统计量的第一估计;
20、(iii)根据至少一个噪声统计量的第一估计,细化第一噪声估计;
21、(iv)通过从噪声输入图像中减去细化的第一噪声估计来形成相应输入图像的估计;
22、(v)通过在相应输入图像、选定的噪声签名和捕获相应输入图像的图像传感器的至少一个噪声统计量上实施模型的候选版本,形成第二估计和至少一个噪声统计量的第二噪声估计;
23、(vi)根据(a)相应输入图像和相应输入图像的估计之间的差异,(b)第二噪声估计和选定噪声签名之间的差异,和(c)至少一个噪声统计量的第二估计和捕获相应输入图像的图像传感器的至少一个噪声统计量之间的差异来调整模型的候选版本。
24、形成步骤(ii)可以在第一路径中执行。形成步骤(v)可以在第二路径中执行。通过第二路径增强图像处理器的生成器促进生成器从噪声输入中去除跨越目标图像信号相关噪声流形的残差噪声。
25、第一和第二路径中的每一个可以包括编码器-解码器网络。第一和第二路径的解码器的权重可以共享。通过共享解码器的权重,rocgan促进回归输出跨越目标流形,而不产生任意大的误差。
26、第一路径和第二路径可以分别基于全卷积网络。这可以是一种方便的实现方式。
27、第二路径可以实施无监督学习方法。无监督学习方法的隐藏层可以包含足够强大的输入数据的表征,用来压缩(和解压)数据,同时尽可能地减少信息损失。
28、第一路径可以包括一个或多个跳过连接。可以例如将编码器的中间层与解码器的相应中间层相连的跳过连接可以强制网络学习与预测的图像噪声和实际图像噪声相对应的特征之间的残差。这可以带来更快的收敛。
29、多个输入图像中的每一个可以是raw图像或rgb图像。这可以使该方法能够用于诸如智能手机的设备中,以去除由此类设备的相机捕获的图像中的噪音。
30、该模型可以是卷积神经网络。这可以是一种方便的实现方式。
31、根据另一方面,提供了一种用于训练模型以对图像执行降噪的设备,该设备具有用于执行上述方法的步骤的处理器。
- 还没有人留言评论。精彩留言会获得点赞!