使用图像数据对环境进行建模
本发明涉及用于获得环境的模型的方法和系统,所述模型可例如由机器人装置用来导航和/或与其环境交互。
背景技术:
1、在计算机视觉和机器人领域中,通常需要构建环境的模型,诸如能够使用机器人装置进行导航的三维空间。构建模型允许将真实世界环境映射到虚拟或数字领域,在所述虚拟或数字领域中,环境的表示可由电子装置使用和操纵。例如,可移动机器人装置可需要三维空间的表示,所述表示可使用同时定位和映射(通常称为“slam”)来生成,以允许对其环境进行导航和/或与其环境交互。
2、实时操作slam系统仍然具有挑战性。例如,许多现有系统需要对大型数据集进行离线操作(例如,通宵或连续几天)。希望为真实世界应用程序实时提供3d场景映射。
3、newcombe等人在2011年混合和增强现实国际研讨会(ismar)论文集中发表的论文“kinectfusion:real-time dense surface mapping and tracking”中描述了一种从红、绿、蓝和深度(rgb-d)数据构建场景的方法,其中rgb-d数据的多个帧被配准并融合到三维体素网格中。使用密集的六自由度对齐来跟踪数据帧,然后将其融合到体素网格的体积中。然而,环境的体素网格表示针对每个体素需要大量的内存。此外,针对在所获得的rgb-d数据中不完全可见的环境区域(例如,被遮挡或部分被遮挡的区域),基于体素的表示可能不准确。使用环境的点云表示时会出现类似的问题。
4、b.mildenhall等人在2020年欧洲计算机视觉会议(eccv)上发表的论文“nerf:representing scenes as neural radiance fields for view synthesis”提出了一种通过使用全连接神经网络处理一组具有已知相机位姿的图像来合成复杂场景的视图的方法。然而,所述方法需要大约1-2天来使用大量训练图像进行离线训练,因此不适合实时使用。此外,这篇论文中提出的方法假设已知给定图像的相机位姿,例如,如果图像是在机器人装置穿越其环境时捕获的,则所述相机位姿可能不可用。
5、希望改进对环境的建模。
技术实现思路
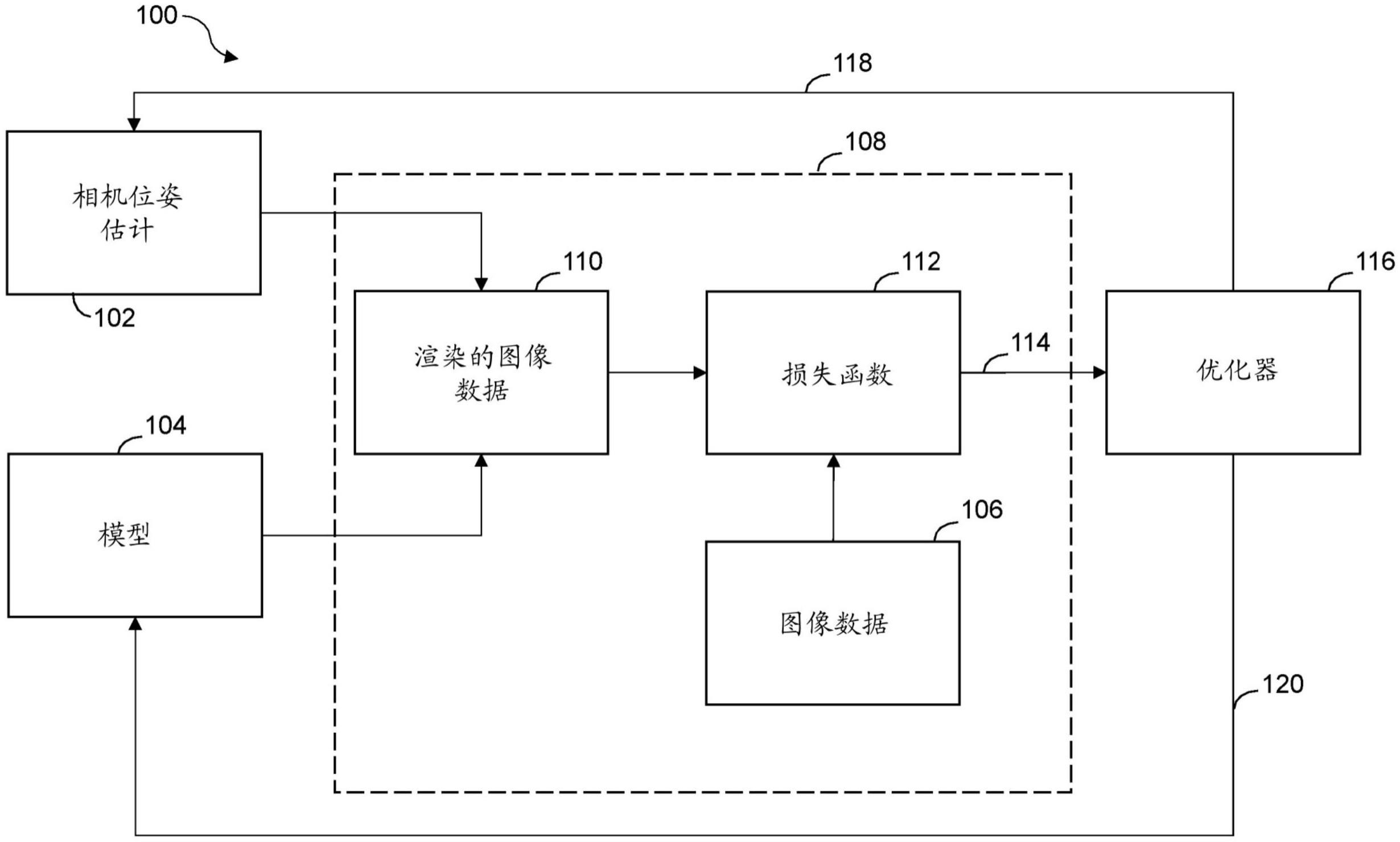
1、根据本公开的第一方面,提供了一种方法,其包括:获得由相机装置捕获的图像数据,图像数据表示对环境的至少一部分的观察;获得与观察相关联的相机位姿估计;基于相机位姿估计和环境的模型生成渲染的图像数据,其中模型用于生成环境的至少一部分的三维表示,其中渲染的图像数据表示与环境的至少一部分相对应的至少一个渲染的图像部分;基于图像数据和渲染的图像数据评估损失函数,从而生成损失;以及基于损失联合优化至少相机位姿估计和模型,从而生成:对相机位姿估计的更新;和对模型的更新。
2、这种方法允许获得环境的准确模型,例如,而无需预先训练或优化模型。例如,可实时优化模型和相机位姿估计,以便以有效的方式为模型和相机位姿估计两者提供自适应改进。
3、在一些示例中,模型是神经网络并且对模型的更新是对神经网络的一组参数的更新。例如,使用神经网络可允许对尚未观察到的环境区域进行预测。
4、在一些示例中,三维表示包括密集三维表示。例如,密集三维表示提供了比其他类型的表示更完整的表示,这在涉及机器人装置与其环境之间的复杂交互的各种任务(诸如机器人导航和抓取)中非常有用。
5、在一些示例中,生成渲染的图像数据包括:使用模型生成三维表示;以及使用三维表示执行渲染过程,其中渲染过程相对于相机位姿估计和模型的一组参数是可区分的。例如,使用可区分的渲染过程允许直接有效地生成用于损失函数的项,从而允许有效地联合优化模型和相机位姿估计。
6、在一些示例中,所述方法包括:评估至少渲染的图像部分相对于相机位姿估计的第一梯度,从而生成第一梯度值;以及评估至少一个渲染的图像部分相对于模型的一组参数的第二梯度,从而生成第二梯度值,其中联合优化相机位姿估计和模型包括使用第一梯度值和第二梯度值应用基于梯度的优化算法。例如,这种方法允许以直接的方式迭代地改进模型的参数和相机位姿估计。
7、在一些示例中,模型被配置来将与环境内的位置相对应的空间坐标映射到:与环境内的位置相关联的光度值;和体积密度值,所述体积密度值用于导出与环境内的位置相关联的深度值。在一些示例中,图像数据包括光度数据,所述光度数据包括至少一个测量的光度图像部分;至少一个渲染的图像部分包括至少一个渲染的光度图像部分;并且损失函数包括基于至少一个测量的光度图像部分和至少一个渲染的光度图像部分的光度误差。在一些示例中,图像数据包括深度数据,所述深度数据包括至少一个测量的深度图像部分;至少一个渲染的图像部分包括至少一个渲染的深度图像部分;并且损失函数包括基于至少一个测量的深度图像部分和至少一个渲染的深度图像部分的几何误差。在这些示例中,在优化程序中可考虑光度和/或几何误差,这例如提高了所获得的优化的模型和相机位姿估计的准确度。
8、在一些示例中,深度数据包括多个测量的深度图像部分,至少一个渲染的图像部分包括多个渲染的深度图像部分,每个渲染的深度图像部分对应于多个测量的深度图像部分中的相应的测量的深度图像部分,几何误差包括多个几何误差项,每个几何误差项对应于多个测量的深度图像部分中的不同的测量的深度图像部分,并且所述方法包括基于以下中的至少一者相对于与多个测量的深度图像部分中的第二测量的深度图像部分相关联的第二几何误差项减少与多个测量的深度图像部分中的第一测量的深度图像部分相关联的第一几何误差项对几何误差的贡献:与多个测量的深度图像部分中的第一测量的深度图像部分相关联的第一不确定性量度,或者与多个测量的深度图像部分中的第二测量的深度图像部分相关联的第二不确定性量度。这种方法允许针对具有更高不确定性的区域(诸如对象边界)减少对几何误差的贡献,这例如降低了几何误差由不确定区域中的值主导的风险。
9、在一些示例中,生成渲染的图像数据包括:应用光线跟踪来识别沿着光线的一组空间坐标,其中光线基于相机位姿估计和至少一个渲染的图像部分的像素的像素坐标来确定;以及使用模型来处理所述一组空间坐标,从而生成一组光度值和一组体积密度值,每一组值与所述一组空间坐标中的相应空间坐标相关联;组合所述一组光度值以生成与像素相关联的像素光度值;以及组合所述一组体积密度值以生成与像素相关联的像素深度值。例如,这种方法允许在选定的空间坐标处对光度值和体积密度值进行采样,这允许比以密集的方式获得这些值时更有效地执行优化。
10、在一些示例中,所述一组空间坐标是第一组空间坐标,所述一组光度值是第一组光度值,所述一组体积密度值是第一组体积密度值,并且应用光线跟踪包括应用光线跟踪来识别沿着光线的第二组空间坐标,其中第二组空间坐标基于概率分布来确定,所述概率分布随第一组体积密度值以及第一组空间坐标中的相邻空间坐标之间的距离而变化,并且所述方法包括:使用模型来处理第二组空间坐标,从而生成第二组光度值和第二组体积密度值;组合第一组光度值和第二组光度值以生成像素光度值;以及组合第一组体积密度值和第二组体积密度值以生成像素深度值。这允许以灵活的方式选择对光度值进行采样的空间位置,例如,以针对包含更大量细节的环境区域对更高密度的点进行采样。
11、在一些示例中,观察是第一观察,相机位姿估计是第一相机位姿估计,并且所述方法包括:在联合优化相机位姿估计和模型之后:获得与在第一观察之后的对环境的第二观察相关联的第二相机位姿估计;以及基于对环境的第二观察和模型优化第二相机位姿估计,从而生成对第二相机位姿估计的更新。通过这种方法,相机位姿估计可例如比模型更频繁地被更新,这可随时间提供准确的相机跟踪。
12、在一些示例中,观察包括第一帧和第二帧,并且渲染的图像数据表示与第一帧相对应的至少一个渲染的图像部分和与第二帧相对应的至少一个渲染的图像部分,相机位姿估计是与第一帧相关联的第一帧相机位姿估计,评估损失函数生成与第一帧相关联的第一损失和与第二帧相关联的第二损失,并且所述方法包括:获得与第二帧相对应的第二帧相机位姿估计,其中基于损失联合优化至少相机位姿估计和模型包括基于第一损失和第二损失联合优化第一帧相机位姿估计、第二帧相机位姿估计和模型,从而生成:对第一帧相机位姿估计的更新;对第二帧相机位姿估计的更新;以及对模型的更新。在这些示例中,可使用多个帧来优化模型和相机位姿估计,与使用单帧相比,这可提高准确度。
13、在一些示例中,图像数据是第一图像数据,观察是对环境的至少第一部分的观察,并且所述方法包括获得由相机装置捕获的第二图像数据,第二图像数据表示对环境的至少第二部分的观察,其中生成渲染的图像数据包括针对环境的第一部分生成渲染的图像数据而不针对环境的第二部分生成渲染的图像数据。换句话说,在这些示例中,用于优化的渲染的图像数据可以是可用图像数据的子集(例如,一帧的像素的子集和/或多个帧的子集),这允许比改为使用所有可用图像数据(例如,每个像素和/或每个帧)时更快地执行联合优化。
14、在一些示例中,图像数据是第一图像数据,观察是对环境的至少第一部分的观察,并且所述方法包括获得由相机装置捕获的第二图像数据,第二图像数据表示对环境的至少第二部分的观察,其中所述方法包括:确定要针对环境的第二部分生成另一个渲染的图像数据,用于进一步联合优化至少相机位姿估计和模型;基于相机位姿估计和模型生成另一个渲染的图像数据,用于进一步联合优化至少相机位姿估计和模型。以这种方式,例如,如果环境的新部分以前没有见过或者包含重要的新信息,则可选择性地确定是否要针对对环境的新部分的观察生成渲染的图像数据,这比不论每个新部分添加了多少信息都使用它来进行联合优化更有效。
15、在一些示例中,确定要针对环境的第二部分生成另一个渲染的图像数据包括确定要基于损失生成另一个渲染的图像数据。例如,损失表明新的观察的信息量有多大:对环境的包含更大量信息的部分(诸如高度详细的部分或模型尚未准确表示的部分)的观察往往具有更高的损失。因此,基于损失执行这种确定允许轻松识别此类观察,因此它们可用于联合优化程序。
16、在一些示例中,确定要针对环境的第二部分生成另一个渲染的图像数据包括:基于损失,针对环境的包括第一部分和第二部分的区域生成损失概率分布;以及基于损失概率分布,选择与第二图像数据相对应的一组像素,针对所述一组像素要生成另一个渲染的图像数据。例如,基于损失概率分布选择所述一组像素允许基于像素可能在更新模型和相机位姿估计时的有用程度(例如,它们与具有大量细节和/或模型未充分表示的环境部分相对应的可能性有多大)来对像素进行采样。
17、在一些示例中,观察包括由相机装置先前捕获的至少一个帧的至少一部分,并且所述方法包括:基于由相机装置先前捕获的多个帧中的相应帧的至少一部分与相应渲染帧的至少一对应部分之间的差异,从所述多个帧中选择至少一个帧,所述相应渲染帧是基于相机位姿估计和模型渲染的。以这种方式,可识别和选择与先前帧不同(例如,表示新的且先前未探索的环境区域)的帧以用于联合优化。与不论帧与先前帧有多相似都使用所有帧相比,这再次提高了联合优化的效率。
18、在一些示例中,观察包括由相机装置捕获的最近的帧的至少一部分。使用最近的帧允许在捕获新帧时重复地更新模型和相机位姿估计,以考虑新的观察。
19、根据本公开的第二方面,提供了一种系统,其包括:图像数据接口,所述图像数据接口用于接收由相机装置捕获的图像数据,图像数据表示对环境的至少一部分的观察;渲染引擎,所述渲染引擎被配置来:获得与观察相关联的相机位姿估计;基于相机位姿估计和环境的模型生成渲染的图像数据,其中模型用于生成环境的至少一部分的三维表示,其中渲染的图像数据表示与环境的至少一部分相对应的至少一个渲染的图像部分;并且基于图像数据和渲染的图像数据评估损失函数,从而生成损失;以及优化器,所述优化器被配置来:基于损失联合优化至少相机位姿估计和模型,从而生成:对相机位姿估计的更新;和对模型的更新。
20、在一些示例中,渲染引擎被配置来:评估至少一个渲染的图像部分相对于相机位姿估计的第一梯度,从而生成第一梯度值;并且评估至少一个渲染的图像部分相对于模型的一组参数的第二梯度,从而生成第二梯度值;并且优化器被配置来:通过使用第一梯度值和第二梯度值应用基于梯度的优化算法来联合优化相机位姿估计和模型。这种方法提供了模型和相机位姿估计的直接优化。
21、在一些示例中,观察是第一观察,相机位姿估计是第一相机位姿估计,并且所述系统包括跟踪系统,所述跟踪系统被配置来在优化器联合优化相机位姿估计和模型之后:获得与在第一观察之后的对环境的第二观察相关联的第二相机位姿估计;并且基于对环境的第二观察和模型优化第二相机位姿估计,从而生成对第二相机位姿估计的更新。以这种方式,跟踪系统可更新由优化器获得的相机位姿估计,以继续改进相机位姿估计,例如与模型相比更频繁地更新相机位姿估计。
22、根据本公开的第三方面,提供了一种机器人装置,其包括:相机装置,所述相机装置被配置来获得表示对环境的至少一部分的观察的图像数据;由本公开的第二方面提供的系统;以及一个或多个致动器,所述一个或多个致动器用于使得机器人装置能够在环境内导航。
23、在一些示例中,系统被配置来控制一个或多个致动器基于模型控制机器人装置在环境内的导航。以这种方式,机器人装置可根据模型在环境内移动,以便在环境内执行精确的任务和运动模式。
24、根据本公开的第四方面,提供了一种包括计算机可执行指令的非暂态计算机可读存储介质,所述计算机可执行指令在由处理器执行时使计算装置执行本文描述的方法中的任一种(单独或彼此组合)。
25、另外的特征将从参考附图进行的以下描述中变得显而易见。
- 还没有人留言评论。精彩留言会获得点赞!