用于人工智能定义网络的系统和方法与流程
本公开总体上涉及人工智能定义的计算机网络。
背景技术:
1、计算机网络传统上利用静态或动态生成的路由表条目来确定数据包路径选择。在诸如bgp(边界网关协议)、eigrp(增强型内部网关路由协议)和ospf(开放最短路径优先)的动态路由协议中,路由表是在路由选择过程之后填充的。路由选择发生在复杂的路由器对等和表或路由交换过程(称为收敛)之后。收敛时间和复杂性随着路由域的大小而增加,这导致拓扑变化时故障恢复延迟和大量计算开销。
2、路由协议通常由人类管理员配置。管理员可以通过汇总、路由度量、权重调整和其他协议特定的调整参数来操纵协议的路由域和性能。协议管理可能容易出错,需要花费大量精力进行路由调整和流量工程以强制执行业务规范或策略。更改路由行为以反映业务规范,诸如对某些流量类型或链路进行优先级排序,是通过简单的匹配、分类、标记或路由优先级标准来执行的。
3、传统网络还受到有限的可观察集空间的限制,路由协议可以利用该空间来确定首选动作。局域网(lan)内的典型路由实现包括经由特定网关地址到未知网络的静态定义的默认路由,以及从路由过程动态生成的路由。动态生成的路由在收敛过程中按优先级排列,以提供主要、次要路径,有时还提供第三路径。通常根据诸如跳数、路径链路速度、路由起源、可靠性或管理距离的基本观察来对可用路由进行优先级排列。当附加的路由可用时,节点分配宝贵的硬件资源和表空间来保存路由和候选路由。这些操作通常使用专用且昂贵的芯片组来执行。
技术实现思路
技术特征:
1.一种经由在一个或多个处理器处执行计算指令来实现的方法,所述方法包括:
2.根据权利要求1所述的方法,其中所述强化学习模型包括深度q元强化学习模型。
3.根据权利要求1或2中任一项所述的方法,其中:
4.根据权利要求3所述的方法,其还包括:
5.根据权利要求1、2、3或4中任一项所述的方法,其中在训练所述路由代理模型的不同情景步骤处以不同部分呈现所述数字孪生网络模拟。
6.根据权利要求1、2、3、4或5中任一项所述的方法,其中所述数字孪生网络模拟的连接速度被设置为所述物理计算机网络的连接速度的可配置的缩小比率。
7.根据权利要求1、2、3、4、5或6中任一项所述的方法,其还包括基于一个或多个流量简档综合生成所述流量。
8.根据权利要求7所述的方法,其中所述一个或多个流量简档中的至少一者包括模糊流量简档。
9.根据权利要求1、2、3、4、5、6、7或8中任一项所述的方法,其还包括存储所述路由代理模型的相应版本、所述物理计算机网络的网络拓扑的相应版本,以及从所述物理计算机网络捕获的流量模式的相应版本作为具有版本控制的相应配置项。
10.根据权利要求1、2、3、4、5、6、7、8或9中任一项所述的方法,其中训练所述数字孪生网络模拟的所述路由代理模型还包括:
11.根据权利要求1、2、3、4、5、6、7、8、9或10中任一项所述的方法,其还包括:
12.根据权利要求1、2、3、4、5、6、7、8、9、10或11中任一项所述的方法,其中针对从不同流量简档生成的流量来训练所述路由代理模型的多个替代版本。
13.根据权利要求1、2、3、4、5、6、7、8、9、10、11或12中任一项所述的方法,其中所述路由代理模型包括机器学习模型,所述机器学习模型包括神经网络模型、随机森林模型或梯度增强模型中的一者或多者。
14.一种系统,其包括:
15.根据权利要求14所述的系统,其中所述强化学习模型包括深度q元强化学习模型。
16.根据权利要求14或15中任一项所述的系统,其中:
17.根据权利要求16所述的系统,其中所述计算指令在所述一个或多个处理器上执行时还执行:
18.根据权利要求14、15、16或17中任一项所述的系统,其中在训练所述路由代理模型的不同情景步骤处以不同部分呈现所述数字孪生网络模拟。
19.根据权利要求14、15、16、17或18中任一项所述的系统,其中所述数字孪生网络模拟的连接速度被设置为所述物理计算机网络的连接速度的可配置的缩小比率。
20.根据权利要求14、15、16、17、18或19中任一项所述的系统,其中所述计算指令在所述一个或多个处理器上执行时还执行:
21.根据权利要求20所述的系统,其中所述一个或多个流量简档中的至少一者包括模糊流量简档。
22.根据权利要求14、15、16、17、18、19、20或21中任一项所述的系统,其中所述计算指令在所述一个或多个处理器上执行时还执行:
23.根据权利要求14、15、16、17、18、19、20、21或22中任一项所述的系统,其中训练所述数字孪生网络模拟的所述路由代理模型还包括:
24.根据权利要求14、15、16、17、18、19、20、21、22或23中任一项所述的系统,其中所述计算指令在所述一个或多个处理器上执行时还执行:
25.根据权利要求14、15、16、17、18、19、20、21、22、23或24中任一项所述的系统,其中针对从不同流量简档生成的流量来训练所述路由代理模型的多个替代版本。
26.根据权利要求14、15、16、17、18、19、20、21、22、23、24或25中任一项所述的系统,其中所述路由代理模型包括机器学习模型,所述机器学习模型包括神经网络模型、随机森林模型或梯度增强模型中的一者或多者。
27.一种经由在一个或多个处理器处执行计算指令来实现的方法,所述方法包括:
28.根据权利要求27所述的方法,其中所述策略设置包括声明性路由策略设置。
29.根据权利要求28所述的方法,其中所述声明性路由策略设置包括网络可靠性设置、网络速度设置、优先级数据类型设置或季节性流量设置中的一者或多者。
30.根据权利要求27、28或29中任一项所述的方法,其中:
31.根据权利要求30所述的方法,其中:
32.根据权利要求30或31中任一项所述的方法,其中:
33.根据权利要求32所述的方法,其中:
34.根据权利要求30、31、32或33中任一项所述的方法,其中:
35.根据权利要求34所述的方法,其中:
36.根据权利要求30、31、32、33、34或35中任一项所述的方法,其中:
37.根据权利要求27、28、29、30、31、32、33、34、35或36中任一项所述的方法,其还包括:
38.根据权利要求37所述的方法,其还包括:
39.一种系统,其包括:
40.根据权利要求39所述的系统,其中所述策略设置包括声明性路由策略设置。
41.根据权利要求40所述的系统,其中所述声明性路由策略设置包括网络可靠性设置、网络速度设置、优先级数据类型设置或季节性流量设置中的一者或多者。
42.根据权利要求39、40或41中任一项所述的系统,其中:
43.根据权利要求42所述的系统,其中:
44.根据权利要求42或43中任一项所述的系统,其中:
45.根据权利要求44所述的系统,其中:
46.根据权利要求42、43、44或45中任一项所述的系统,其中:
47.根据权利要求46中任一项所述的系统,其中:
48.根据权利要求42、43、44、45、46或47中任一项所述的系统,其中:
49.根据权利要求39、40、41、42、43、44、45、46、47或48中任一项所述的系统,其中所述计算指令在所述一个或多个处理器上执行时还执行:
50.根据权利要求49所述的系统,其中所述计算指令在所述一个或多个处理器上执行时还执行:
51.一种经由在一个或多个处理器处执行计算指令来实现的方法,所述方法包括:
52.根据权利要求51所述的方法,其中所述集中式模型中的所述sdn控制服务包括中央监视服务、中央sdn控制器上的中央sdn代理以及到所述物理计算机网络的每个节点的相应管理连接。
53.根据权利要求51所述的方法,其中所述分散式模型中的所述sdn控制服务包括中央监视服务、中央sdn控制器上的中央sdn代理以及与所述物理计算机网络的每个相应分层域相关联的相应sdn子代理,其中所述相应sdn子代理包括到所述相应分层域中的每个节点的相应管理连接。
54.根据权利要求53所述的方法,其还包括:
55.根据权利要求51所述的方法,其中所述分布式模型中的所述sdn控制服务包括中央监视服务和与所述物理计算机网络中的每个节点相关联的相应本地sdn代理。
56.根据权利要求55所述的方法,其还包括:
57.根据权利要求51所述的方法,其中所述混合模型中的所述sdn控制服务包括所述集中式模型、所述分散式模型或所述分布式模型中的两者或更多者的元素。
58.根据权利要求51、52、53、54、55、56或57中任一项所述的方法,其中所述sdn控制服务内的路由是基于由源地址、目的地地址和数据报分类元组定义的流来执行的。
59.根据权利要求51、52、53、54、55、56、57或58中任一项所述的方法,其中使用具有一个或多个流量简档或一个或多个应用简档的所述强化学习模型来训练所述路由代理模型以使用所述强化学习模型的策略对所述物理计算机网络中的流量进行分段,所述策略在以下各项中的至少一者上具有高于预定阈值的负面奖励:预定端点之间的通信或通过预定路径的通信。
60.根据权利要求51、52、53、54、55、56、57、58或59中任一项所述的方法,其还包括:
61.根据权利要求51、52、53、54、55、56、57、58、59或60中任一项所述的方法,其还包括:
62.根据权利要求61所述的方法,其还包括:
63.根据权利要求51、52、53、54、55、56、57、58、59、60、61或62中任一项所述的方法,其中:
64.一种系统,其包括:
65.根据权利要求64所述的系统,其中所述集中式模型中的所述sdn控制服务包括中央监视服务、中央sdn控制器上的中央sdn代理以及到所述物理计算机网络的每个节点的相应管理连接。
66.根据权利要求64所述的系统,其中所述分散式模型中的所述sdn控制服务包括中央监视服务、中央sdn控制器上的中央sdn代理以及与所述物理计算机网络的每个相应分层域相关联的相应sdn子代理,其中所述相应sdn子代理包括到所述相应分层域中的每个节点的相应管理连接。
67.根据权利要求66所述的系统,其中所述计算指令在所述一个或多个处理器上执行时还执行:
68.根据权利要求64所述的系统,其中所述分布式模型中的所述sdn控制服务包括中央监视服务和与所述物理计算机网络中的每个节点相关联的相应本地sdn代理。
69.根据权利要求68所述的系统,其中所述计算指令在所述一个或多个处理器上执行时还执行:
70.根据权利要求64所述的系统,其中所述混合模型中的所述sdn控制服务包括所述集中式模型、所述分散式模型或所述分布式模型中的两者或更多者的元素。
71.根据权利要求64、65、66、67、68、69或70中任一项所述的系统,其中所述sdn控制服务内的路由是基于由源地址、目的地地址和数据报分类元组定义的流来执行的。
72.根据权利要求64、65、66、67、68、69、70或71中任一项所述的系统,其中使用具有一个或多个流量简档或一个或多个应用简档的所述强化学习模型来训练所述路由代理模型以使用所述强化学习模型的策略对所述物理计算机网络中的流量进行分段,所述策略在以下各项中的至少一者上具有高于预定阈值的负面奖励:预定端点之间的通信或通过预定路径的通信。
73.根据权利要求64、65、66、67、68、69、70、71或72中任一项所述的系统,其中所述计算指令在所述一个或多个处理器上执行时还执行:
74.根据权利要求64、65、66、67、68、69、70、71、72或73中任一项所述的系统,其中所述计算指令在所述一个或多个处理器上执行时还执行:
75.根据权利要求74所述的系统,其中所述计算指令在所述一个或多个处理器上执行时还执行:
76.根据权利要求64、65、66、67、68、69、70、71、72、73、74或75中任一项所述的系统,其中:
技术总结
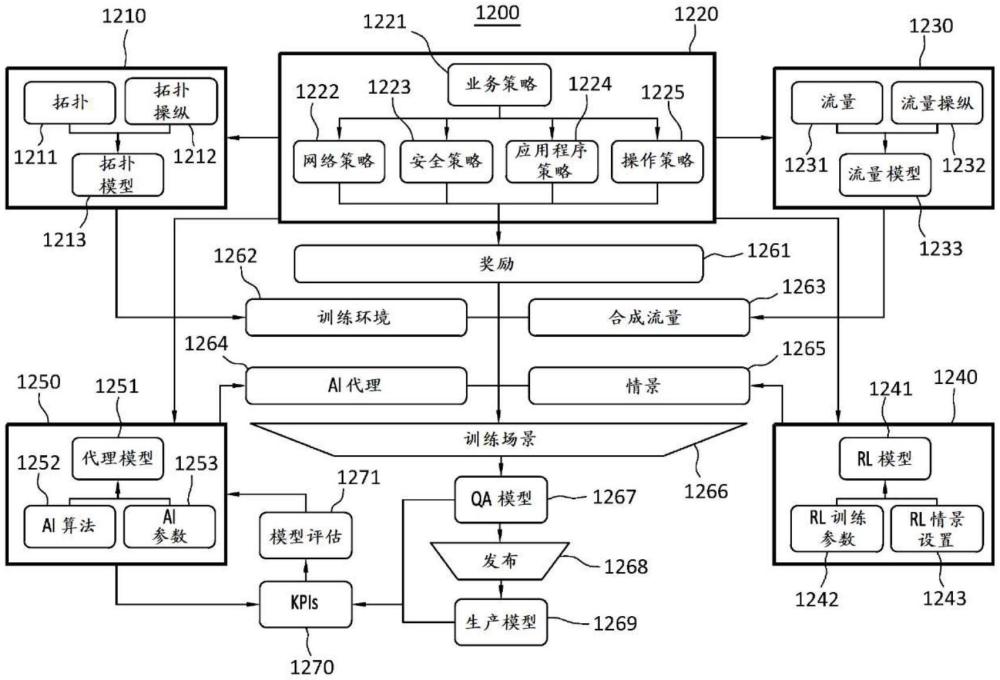
一种系统包括一个或多个处理器以及存储计算指令的一个或多个非暂时性计算机可读介质,所述计算指令在一个或多个处理器上执行时执行某些动作。动作可以包括生成通过软件定义网络(SDN)控制系统控制的物理计算机网络的数字孪生网络模拟。动作还可以包括使用关于流经数字孪生网络模拟的节点的流量的强化学习模型来训练数字孪生网络模拟上的路由代理模型。路由代理模型包括机器学习模型。动作可以另外包括将经过训练的路由代理模型从数字孪生网络模拟部署到物理计算机网络的SDN控制系统。提供了其他实施方案。
技术研发人员:R·德舍纳,M·卡塔拉诺,S·巴德瓦杰,N·布里奇兰,A·夏尔马,X·乌尔里希,N·阿加瓦尔,T·肖赫,R·张,P·S·瓜尔,T·西普雷尔,J·马尔奇,H·斯托尔滕贝格
受保护的技术使用者:环球科技控股有限责任公司
技术研发日:
技术公布日:2024/2/21
- 还没有人留言评论。精彩留言会获得点赞!