一种面向自动驾驶的单摄像头三维目标检测方法及系统
本发明涉及一种面向自动驾驶的单摄像头三维目标检测方法及系统,属于三维目标检测。
背景技术:
1、三维目标检测一直是自动驾驶中的一个重要问题,它的主要任务是通过计算,识别出车辆的三维位置、车辆尺寸信息和偏航角。
2、在面向自动驾驶的计算机视觉应用场景中,识别车辆三维空间信息的三维目标检测算法至关重要。在三维空间信息中,深度估计是最重要的分支。然而从单摄像头中精确获取目标的深度信息从理论上具有极大的困难,深度预测的不准确是引起性能下降的主要原因。目前的面向自动驾驶的单摄像头三维目标检测方法主要有基于雷达、基于预训练深度和直接回归方法,前两者方法严重依赖额外信息,计算和人工成本较高。近年来,计算机视觉的研究者们提出了许多基于直接回归的方法,大大减少研究成本,提高检测速度。
3、但是,这些方法大多数都是单一深度估计方法,在模型训练时,利用车辆的纹理信息使用神经网络直接估计深度或者利用高度信息通过几何投影公式估计深度,并不能综合利用图像信息。
技术实现思路
1、本发明的目的在于提供一种面向自动驾驶的单摄像头三维目标检测方法及系统,以解决现有方法大多数都是单一深度估计方法并不能综合利用图像信息,预测的不准确的缺陷。
2、一种面向自动驾驶的单摄像头三维目标检测方法,所述方法包括:
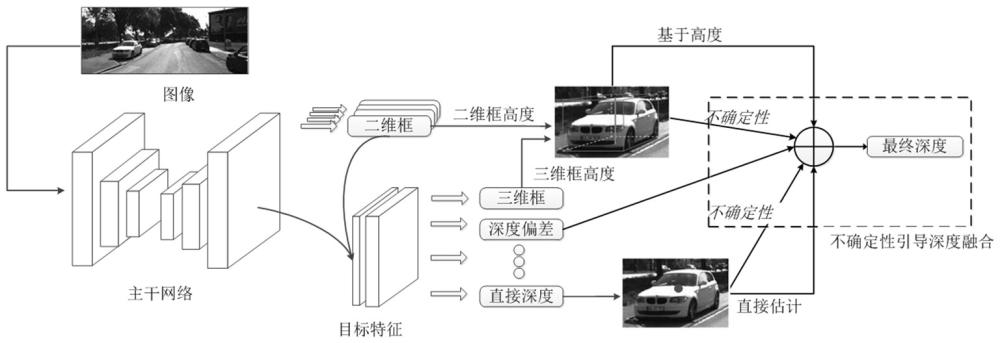
3、将获取的单目图像输入特征提取网络中,输出二维检测结果;
4、对二维检测结果采用roialign方法裁剪出roi特征;
5、将单目图像归一化后的坐标图以通道方式与裁剪出的每个roi特征的地图连接,形成最终的roi特征;
6、根据最终的roi特征预测三维检测信息;
7、将二维检测结果中预测的二维框高度与三维检测信息中预测的三维框高度采用几何投影公式计算出目标深度;
8、将三维检测信息中直接求出的深度以及几何投影公式计算出目标深度,通过不确定性加权融合得到最终的深度;
9、将预测的三维检测信息与加权融合得到最终的深度进行融合,输出目标的预测信息。
10、进一步地,所述二维检测结果包括四个部分:
11、heatmap:预测目标的类别分数和2d框中心的粗坐标;
12、offset_2d:预测3dbounding box中心点投影和2dbounding box中心坐标在降采样后的偏移;
13、size_2d:2d框的高和宽,单位像素;
14、residual_2d:2dbounding box中心坐标降采样以后的残差。
15、进一步地,所述三维检测信息包括:
16、angle:角度预测输出,采用multi-bin策略,分成24个区间,前12个用于分类预测输出,后12个回归预测输出;
17、direct_depth:使用特征提取网络直接预测目标的深度信息,输出两列信息,第一列为深度值,第二列为不确定;
18、offset_3d:3dbounding box中心点投影在下采样后的残差;
19、size_3d:3dbounding box的尺寸信息,实际预测的是尺寸的偏差,将预测的偏差加上数据集中目标的平均尺寸得到预测尺寸;
20、depth_bias:预测深度的偏差值,弥补对截断目标深度预测的偏差。
21、进一步地,所述特征提取网络的损失函数为:
22、;
23、初始设置二维检测部分的权重,三维检测部分;表示为整体损失;表示为各个预测分支的损失。
24、进一步地,将所述三维检测信息中直接求出的深度以及几何投影公式计算出目标深度,通过不确定性加权融合得到最终的深度的方法如下:
25、在最终的roi特征进行直接深度估计:
26、;
27、;
28、其中,是三维信息中的预测分支,用于估计深度以及不确定性;表示直接深度估计结果,是设定参数,表示建模深度估计中的异方差随机不确定性;
29、将服从拉普拉斯分布的三维框高度带入几何投影公式,根据几何投影预测的深度为:
30、;
31、其中,表示焦距,表示二维框高度,服从标准拉普拉斯分布,表示三维框高度,表示尺度参数,表示三维框高度的均值;
32、同时三维检测信息中还预测出服从拉普拉斯分布,的深度偏差,利用拉普拉斯分布的可相加性,得到最终的几何投影预测的深度和不确定性为:
33、,;
34、其中,,,表示深度偏差的方差,表示深度偏差的均值,是基于几何投影的不确定性;表示为基于几何投影的深度;表示为;
35、将roi特征上求出的直接深度和基于几何投影的深度,使用不确定性引导融合起来;权重计算公式:
36、;
37、其中,表示直接深度估计,表示基于几何投影深度估计,表示直接深度估计和基于几何投影的深度估计的不确定性;表示直接深度估计和基于几何投影的深度估计的不确定性的平方和;表示为直接深度估计的不确定性或者基于几何投影深度的不确定性;
38、最终的目标深度和不确定性计算公式:
39、,;
40、因为目标深度也服从拉普拉斯分布,所以目标深度信息的损失函数表达式为:
41、;
42、其中,表示标签真值,表示目标深度,表示不确定性,表示两种深度估计,表示深度估计对应的不确定性。
43、进一步地,所述根据最终的roi特征预测三维检测信息包括:
44、在所述roi特征上进行,经过卷积、组归一化、激活、可适应性平均池化和卷积操作,输出预测的三维检测信息。
45、进一步地,所述特征提取网络包括dla-34主干网络和neck网络,所述dla-34主干网络采用centernet框架,所述dla-34主干网络用于将输出的6层特征图的最后4层特征图输入neck网络,所述neck网络将输入的4层特征图输出一层特征图作为二维检测结果。
46、进一步地,所述目标的预测信息包括三维中心点坐标、尺寸和偏航角。
47、进一步地,所述roi特征只包含对象级特征,不包含背景噪声。
48、本发明第二方面提供了一种面向自动驾驶的单摄像头三维目标检测系统,所述系统包括:
49、特征提取模块,用于获取单目图像输入特征提取网络中,输出二维检测结果;
50、特征裁剪模块,用于对二维检测结果采用roialign方法裁剪出roi特征;
51、归一化模块,用于将单目图像归一化后的坐标图以通道方式与裁剪出的每个roi特征的地图连接,形成最终的roi特征;
52、三维检测模块,用于根据最终的roi特征预测三维检测信息;
53、算法模块,用于将二维检测结果中预测的二维框高度与三维检测信息中预测的三维框高度采用几何投影公式计算出目标深度;
54、不确定性融合模块,用于将所述三维检测信息中直接求出的深度以及几何投影公式计算出目标深度,通过不确定性加权融合得到最终的深度;
55、融合模块,用于将预测的三维检测信息与加权融合得到最终的深度进行融合,输出目标的预测信息。
56、与现有技术相比,本发明所达到的有益效果:
57、1、本发明在通过不确定性引导融合了直接深度估计和基于几何投影深度估计的方法,综合利用了图像的纹理和几何特征,提供更精准的深度估计,具有较好的鲁棒性;
58、2、本发明通过深度融合将更高的权重值分配给深度预测不稳定的分支,这有助于提高整体深度估计的稳定性;
59、3、本发明为了更好的辅助三维检测任务,增加了二维检测任务分支,在每一个通道内进行组归一化,能够保留通道之间的位置信息,有助于在三维目标检测更好地学习空间信息,使用组归一化加速网路训练过程;
60、4、本发明采用两阶段检测,在roi特征上进行进一步检测,比多数单阶段的方法更快,保证了面向自动驾驶单摄像头三维目标检测的实时要求的前提下,检测精度也优于目前各分类的检测方法。
- 还没有人留言评论。精彩留言会获得点赞!