用于生成音频信号的装置和方法与流程
本发明涉及一种用于生成用于虚拟世界场景对象与现实世界场景对象之间的相互作用的音频信号并且具体地但非排他地用于生成用于增强现实应用的音频信号的装置和方法。
背景技术:
1、近年来,基于视听内容的体验的种类和范围已经大幅增加,其中,不断开发和引入利用和消费此类内容的新服务和方式。特别地,正在开发许多空间和交互式服务、应用和体验,以给予用户更复杂且沉浸式的体验。
2、这样的应用的示例是快速成为主流的虚拟现实(vr)、增强现实(ar)和混合现实(mr)应用,其中,许多解决方案针对消费者市场。许多标准化机构也正在开发许多标准。这种标准化活动正在积极开发用于vr/ar/mr系统的各个方面的标准,包括例如流传输、广播、渲染等。
3、vr应用往往提供对应于用户处于不同世界/环境/场景中的用户体验,而ar(包括混合现实mr)应用往往提供对应于用户处于现实本地环境中但添加了附加信息或虚拟对象或信息的用户体验。因此,vr应用往往提供完全沉浸式的合成生成的世界/场景,而ar应用往往提供叠加用户物理存在的现实场景的部分合成的世界/场景。然而,术语通常可互换使用并且具有高度重叠。在下文中,术语增强现实/ar将用于表示增强现实和混合现实两者(以及有时表示虚拟现实的一些变型)。
4、作为示例,使用手持设备的增强现实的服务和应用已经变得越来越流行,并且软件api(应用编程接口)和工具包(诸如arkit(由apple inc.开发)和arcore(由google inc.开发))已经被引入以支持智能电话和平板电脑上的增强现实应用。在这些应用中,设备的内置相机和其他传感器用于生成环境的实时图像,其中,虚拟图形叠加所呈现的图像。应用可以例如生成具有叠加实况视频的图形对象的实况视频馈送。这样的图形对象可以例如用于定位虚拟对象,使得它们被感知为存在于现实世界场景中。
5、作为另一示例,已经开发了头盔和眼镜,其中,现实世界场景可以通过ar眼镜直接观看,但是这些也能够生成用户在通过眼镜观看时看到的图像。这也可用于呈现被感知为所观看的现实世界场景的一部分的虚拟图像。运动传感器用于跟踪头部移动,并且所呈现的虚拟对象可以对应地适于提供虚拟对象是在现实世界中观看的现实世界对象的印象。
6、这些方法分别被称为直通(pass-through)和透视(see-through),并且两者都可以提供新颖且令人兴奋的用户体验。
7、除了视觉渲染之外,一些ar应用可以提供对应的音频体验。此外,对于视觉体验,已经提出要提供可以对应于虚拟对象的音频。例如,如果虚拟对象是将生成噪声的对象,则可以通过生成的对应声音来补充对象的视觉呈现。在一些情况下,还可以生成反映虚拟对象的动作的声音。
8、通常,通过在适当的时间渲染预先录制的音频片段来将声音生成为默认声音。在一些情况下,声音可以适于反映当前环境,诸如例如通过根据当前环境调整感知混响,或可以例如被处理以被感知为从与现实世界中的虚拟对象的感知位置相对应的位置到达。通常,这种定位可以通过双耳处理来实现,以生成合适的耳机音频输出。
9、然而,尽管在许多实施例中这样的方法可以提供有趣的应用和用户体验,但是常规方法往往是次优的,并且往往难以实施和/或往往提供次优的性能和用户体验。
10、因此,改进的方法将是有利的。特别地,允许改进的操作、增加的灵活性、降低的复杂性、促进的实施、改进的音频体验、改进的音频质量、减少的计算负担、针对混合/增强现实应用的改进的适合性和/或性能、改进的用户沉浸感和/或改进的性能和/或操作的生成音频信号的方法将是有利的。
技术实现思路
1、因此,本发明试图优选地单独地或以任何组合减轻、缓解或者消除上文所提到的缺点中的一个或多个。
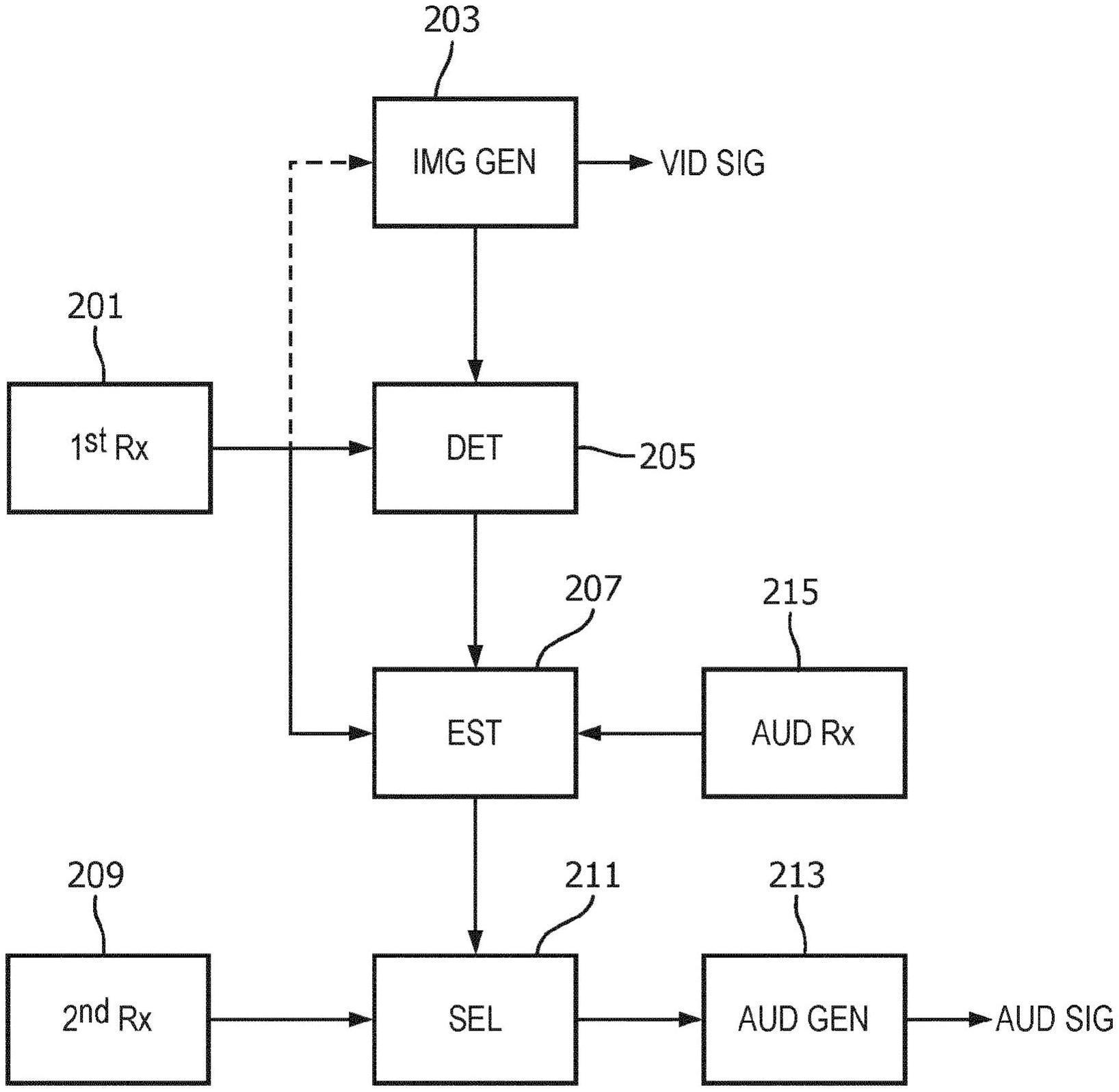
2、根据本发明的一个方面,提供了一种用于生成输出音频信号的装置,所述装置包括:第一接收器,其被布置为从图像传感器接收现实世界场景的实时图像序列,所述实时图像序列包括图像帧的序列,每个图像帧包括视觉图像数据和深度图像数据中的至少一项;第二接收器,其被布置为接收一组音频对象和针对所述一组音频对象中的音频对象的元数据,所述元数据指示所述一组音频对象中的音频对象与材料特性之间的联系;图像生成器,其被布置为生成输出图像序列,所述输出图像序列包括与所述现实世界场景中的虚拟场景对象相对应的图像对象;检测器,其被布置为响应于对所述虚拟场景对象与所述现实世界场景的现实世界场景对象之间的接近度的检测而检测所述虚拟场景对象与所述现实世界场景对象之间的相互作用;估计器,其被布置为响应于所述图像帧的序列的图像数据而确定针对所述现实世界场景对象的材料性质;选择器,其被布置为响应于被联系到所述一组音频对象中的音频对象的所述材料特性和所述材料性质而选择所述一组音频对象中的第一音频对象;以及输出电路,其被布置为生成包括所述第一音频对象的所述输出音频信号。
3、本发明可以在许多实施例中提供改进的用户体验,并且特别地可以在许多实施例中提供改进的且更沉浸式的增强现实体验。在许多实施例中,可以在维持低复杂性和/或实施的同时实现该方法。该方法可以非常适合于ar系统,其中,音频和支持元数据可以由远程服务器提供。该方法可以促进和/或支持其中集中式服务器可以为多个远程客户端提供支持并且可以基本上促进远程客户端的实施的系统。该方法可以支持音频的集中生成和管理以便增强ar应用和体验。
4、音频对象可以是音频剪辑/片段等,并且可以以任何合适的方式表示。在许多实施例中,每个音频对象可以表示时间间隔中的声音。在许多实施例中,对于音频对象中的任何一个,时间间隔可以不超过5秒、10秒或20秒。
5、材料特性可以是现实世界对象的材料特性。
6、输出图像序列可以包括视觉图像。
7、可以在表示现实世界场景的三维坐标系中检测相互作用。相互作用可以是虚拟场景对象与现实世界场景对象之间的接近度/碰撞/接触。
8、该装置可以是增强现实装置。该装置可以是用于为增强现实应用提供输出图像序列和输出音频信号的装置。增强现实应用可以在现实世界场景中呈现虚拟场景对象。
9、根据本发明的可选特征,所述估计器被布置为:确定所述图像帧的序列中的至少一个图像帧中的相互作用图像区域,所述相互作用图像区域是所述至少一个图像帧的发生所述相互作用的图像区域;以及响应于所述相互作用图像区域的图像数据而确定所述场景对象的所述材料性质。
10、这在许多实施例中可以提供特别有效和/或有利的材料性质估计,并且在许多实施例中可以具体地允许更准确的材料性质估计。因此,该方法可以提供改进的用户体验。
11、根据本发明的可选特征,所述第二接收器被布置为从远程服务器接收所述元数据。
12、该方法可以提供特别有效的应用,其中,音频可以被远程地并且可能集中地生成和管理,同时在本地有效地适应于适当的当前条件。
13、根据本发明的可选特征,针对至少一些音频对象的所述元数据包括对所述至少一些音频对象与现实世界场景对象的材料特性之间的联系以及所述至少一些音频对象与虚拟场景对象的材料特性之间的联系的指示;并且其中,所述选择器被布置为响应于联系到所述一组音频对象的现实世界对象的材料特性和材料性质并且响应于联系到所述一组音频对象的虚拟场景对象的材料特性和虚拟场景对象的材料性质而选择所述第一音频对象。
14、在许多实施例中,这可以允许改进的性能,并且可以具体地允许对特定相互作用的改进的调整。通常可以实现更沉浸式的用户体验。
15、根据本发明的可选特征,所述选择器被布置为响应于所述虚拟场景对象的动态性质而选择所述第一音频对象。
16、在许多实施例中,这可以允许改进的性能,并且可以具体地允许对特定相互作用的改进的调整。通常可以实现更沉浸式的用户体验。
17、根据本发明的可选特征,所述检测器被布置为确定所述相互作用的性质,并且所述选择器被布置为响应于所述相互作用的所述性质而选择所述第一音频对象。
18、在许多实施例中,这可以允许改进的性能,并且可以具体地允许对特定相互作用的改进的调整。通常可以实现更沉浸式的用户体验。
19、根据本发明的可选特征,所述相互作用的所述性质是从包括以下各项的组中选择的至少一个性质:所述相互作用的速度;所述虚拟场景对象与所述现实世界场景对象之间的碰撞的力;所述虚拟场景对象与所述现实世界场景对象之间的碰撞的弹性;所述相互作用的持续时间;以及所述虚拟场景对象相对于所述现实世界场景对象的移动的方向。
20、根据本发明的可选特征,所述选择器被布置为响应于所述虚拟对象相对于所述现实世界场景对象的取向而选择所述第一音频对象。
21、在许多实施例中,这可以允许改进的性能,并且可以具体地允许对特定相互作用的改进的调整。通常可以实现更沉浸式的用户体验。
22、根据本发明的可选特征,所述估计器被布置为确定所述现实世界场景对象与多个对象类目中的至少第一类目的匹配指示;以及响应于所述匹配指示和联系到所述对象类目的材料性质而确定材料性质。
23、这可以提供材料性质的特别有利的且通常更低复杂性的确定,然而,其仍然可以具有高准确性。在许多实施例中,归类/分类可以有利地使用神经网络来实现。
24、根据本发明的可选特征,所述装置还包括用于接收在所述现实世界场景中捕获的实时音频的音频信号的音频接收器,并且其中,所述估计器被布置为响应于所述音频信号而确定所述匹配指示。
25、在许多实施例中,这种方法可以显著改进材料性质估计的准确性,从而导致改进的整体性能。
26、根据本发明的可选特征,所述选择器被布置为如果没有检测到满足选择准则的音频对象,则选择所述第一音频对象作为默认音频对象。
27、根据本发明的可选特征,至少一个图像帧包括深度图像数据,并且其中,所述估计器被布置为响应于检测到表示所述现实世界场景对象的所述至少一个图像帧的图像区域的至少一部分具有不超过阈值的深度图像数据的置信度水平而确定所述现实世界场景对象的所述材料性质。
28、在一些实施例中,所述图像帧包括视觉图像数据和深度图像数据,并且所述估计器被布置为响应于对于所述图像区域的至少一部分检测到所述视觉图像数据的亮度超过阈值并且深度图像数据的置信度水平不超过阈值而将所述现实世界场景对象确定为具有金属分量。
29、根据本发明的另一方面,提供了一种生成输出音频信号的方法,所述方法包括:从图像传感器接收现实世界场景的实时图像序列,所述实时图像序列包括图像帧的序列,每个图像帧包括视觉图像数据和深度图像数据中的至少一项;接收一组音频对象和针对所述一组音频对象中的音频对象的元数据,所述元数据指示所述一组音频对象中的音频对象与材料特性之间的联系;生成输出图像序列,所述输出图像序列包括与所述现实世界场景中的虚拟场景对象相对应的图像对象;响应于所述虚拟场景对象与所述现实世界场景的现实世界场景对象之间的接近度的检测而检测所述虚拟场景对象与所述现实世界场景对象之间的相互作用;响应于所述图像帧的序列的图像数据而确定所述现实世界场景对象的材料性质;响应于联系到所述一组音频对象中的音频对象的所述材料特性和所述材料性质而选择所述一组音频对象中的第一音频对象;以及生成包括所述第一音频对象的所述输出音频信号。
30、所述方法可以包括显示所述输出图像序列和/或渲染所述输出音频信号。
31、参考下文描述的(一个或多个)实施例,本发明的这些和其他方面、特征和优点将是显而易见的并且得以阐明。
- 还没有人留言评论。精彩留言会获得点赞!