使用空间和时间上的注意力对来自视频序列的对象表示的无监督学习的制作方法
背景技术:
1、本说明书涉及训练机器学习模型来表征视频帧中的对象以及诸如视点之类的全局时变元素。机器学习模型接收输入并基于接收的输入和模型的参数值生成输出,例如预测的输出。
2、神经网络是采用一层或多层非线性单元对接收到的输入来预测输出的机器学习模型。除了输出层之外,一些神经网络还包括一个或多个隐藏层。每个隐藏层的输出被用作网络中下一个层(即下一个隐藏层或输出层)的输入。网络的每一层根据相应组参数的当前值从接收的输入生成输出。
技术实现思路
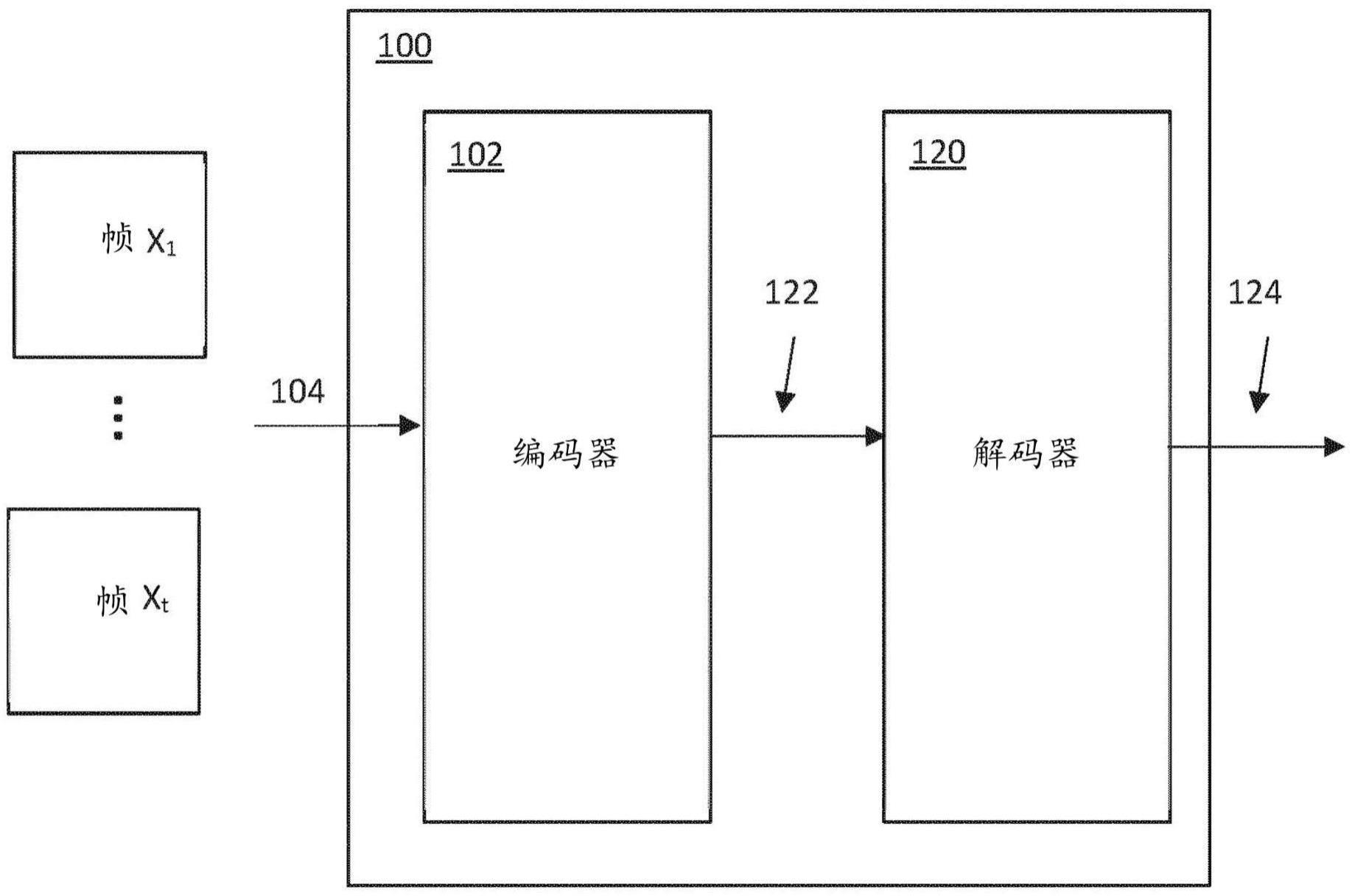
1、本说明书总体上描述了一种系统和方法,其被实现为在一个或多个物理位置的一个或多个计算机上的一个或多个计算机程序,其训练视频对象表示神经网络系统。经训练的系统的编码器部分可以用于确定视频序列中多个不同对象的属性,或者确定视频序列的视点位置,或者这两者。经训练的系统的解码器部分可以用于生成新的视频序列。编码器和解码器可以一起用于修改视频序列。
2、在一个方面,提供了一种训练视频对象表示神经网络系统的计算机实现的方法。视频对象表示神经网络系统包括自注意力神经网络,该自注意力神经网络包括一个或多个自注意力层(例如变换器神经网络层)并且具有多个自注意力神经网络参数,每个自注意力层被配置为在层输入上应用自注意力机制。
3、该方法包括获得包括t个图像帧的序列的视频序列,在一系列时间中的每一个时间处一个图像帧,并且处理每个图像帧以生成t个图像帧中的每一个的一组s个空间编码。该方法由此获得视频序列的s×t个空间编码的组。每个空间编码包括图像帧的相应区域或片(patch)的编码。该视频可以例如从相机或lidar传感器获得,即图像帧可以包括点云。
4、该方法还包括使用注意力神经网络处理s×t个空间编码的组,具体是通过在包括s×t个空间编码的组的层输入上应用自注意力机制,以可选地在进一步的自注意处理步骤之后生成变换的空间编码的组。每个变换的空间编码对应于一个图像帧时间和一个图像帧区域。变换的空间编码的组可以具有相同或不同的分辨率,例如较低的分辨率,即可以有s×t个或更少的变换的空间编码。在实现方式中,在层输入上应用自注意力机制包括在不同图像帧的空间编码上,即在来自一系列时间中的不同时间的图像帧上应用自注意力机制。
5、该方法还包括针对一组对象潜在变量(通常是向量)中的每一个确定用于参数化对象潜在变量的对象潜在分布的一个或多个值,例如分布的平均值或标准偏差(或方差)。这是通过在图像帧的时间上聚合变换的空间编码的组来完成的。该方法还可以通过在图像帧的区域上聚合变换的空间编码的组,针对一组帧潜在变量中的每一个确定用于参数化帧潜在变量的帧潜在分布的一个或多个值。该方法通过从对象潜在变量的对象潜在分布中采样来确定该组对象潜在变量中的每一个的值。该方法还可以通过从帧潜在变量的帧潜在分布中采样来确定该组帧潜在变量中的每一个的值。
6、该方法处理确定的对象潜在变量的值(并且可以处理确定的帧潜在变量的确定的值)以生成解码的图像帧序列。存在许多类型的能够从一组潜在变量生成图像的解码器,并且可以使用这些中的任何一种。稍后描述示例解码器。
7、该方法然后可以包括通过至少调整自注意力神经网络参数的值,以取决于i)t个图像帧的序列和解码的图像帧序列之间的差异的度量,ii)每个对象潜在分布和先验对象潜在分布之间的差异来优化目标函数,来训练系统。在被确定的情况下,可以取决于iii)每个帧潜在分布和先验帧潜在分布之间的差异来优化目标函数。先验对象潜在分布和先验帧潜在分布可以是相同的分布,例如单位高斯。
8、上述方法的实现方式提供了一种经训练的视频对象表示神经网络系统。在一些应用中,一旦被训练,可能只需要系统的编码器部分,即从视频序列输入到被配置为确定对象和(可选地)帧潜在分布的部分的系统部分,可选地包括被配置为从这些分布中采样的部分(在其他实现方式中,可以例如从这些分布的平均值中导出信息)。在一些应用中,一旦经过训练,可能只需要系统的经训练的解码器部分,如后面所述,例如以生成2d或3d图像的视频序列。
9、经训练的系统的实现方式提供该组对象潜在变量中的对象信息。例如,在实现方式中,这些实质上是可以区分的,即,使得不同的对象潜在变量对应于场景中对象的不同变化因素及其属性,诸如大小、颜色、例如在每个维度中的位置,以及运动。类似地,在实现方式中,不同的帧潜在变量可以区分视频序列的帧的不同全局属性,诸如,例如每个维度中的视点位置。稍后描述该方法和系统的更多优点。
10、在实现方式中,每个空间编码包括图像帧的相应区域或“片”的特征图,即视觉特征图。处理图像帧以生成一组空间编码可以使用具有多个特征提取神经网络参数的特征提取神经网络,例如卷积神经网络,来为图像帧的每个区域生成特征图。训练系统可以包括调整特征提取神经网络参数的值。
11、在实现方式中,使用具有多个图像帧解码器神经网络参数的图像帧解码器神经网络来处理确定的对象潜在变量(以及可选的帧潜在变量)的值,以生成解码的图像帧序列。训练系统然后可以包括调整图像帧解码器神经网络参数的值。
12、在一些实现方式中,解码的图像帧序列包括一系列解码的图像帧时间步长中的每一个的图像帧。生成解码的图像帧序列使用图像帧解码器神经网络来针对每个解码的图像帧像素和针对每个解码的图像帧时间步长生成每个对象潜在变量的像素分布的参数。具体地,图像帧解码器神经网络处理确定的对象潜在变量(以及可选的帧潜在变量)的值,以及指定像素位置的信息和指定时间步长的信息,以确定每个对象潜在变量的像素分布(μ)的参数。然后组合每个对象潜在变量的像素分布,以确定组合的像素分布。然后对其进行采样,以确定针对像素和针对时间步长的值。例如,在一个实现方式中,帧潜在变量(用于解码图像帧)与每个对象潜在变量级联,以向图像帧解码器神经网络提供输入,更具体地是一组输入。
13、生成解码的图像帧序列可以包括针对每个像素和针对每个时间步长确定每个对象潜在变量的混合权重。每个对象潜在变量的像素分布然后可以根据相应的混合权重进行组合,可选地被归一化。在这种实现方式中,每个对象潜在变量的每像素混合权重为对应于对象潜在变量的对象提供了软分割掩码,例如以将每个图像帧分割成表示图像帧中不同对象的区域。
14、可以使用图像帧序列和解码的图像帧序列之间的差异的任何合适的度量,例如交叉熵损失、平方误差损失或huber损失。任何合适的度量都可以用于分布之间的差异,例如kl或jensen-shannon散度或分布之间距离的另一种度量。
15、在一些实施方式中,该方法可以包括获得条件输入,该条件输入定义视频序列中的一个或多个对象或一个或多个对象的对象属性,或者定义视点位置或朝向,例如姿态。在训练期间,可以将条件输入提供给自注意力神经网络和图像帧解码器神经网络。以这种方式,可以将该系统训练成例如条件性地根据条件输入来生成视频图像序列,该条件输入定义要被包括在生成的视频图像序列中的对象或对象的属性,或者生成的视频序列的可选地改变的视点。
16、如前所述,自注意力层可以是变换器神经网络层。arxiv:2010.11929中描述了变换器神经网络架构对计算机视觉的应用。
17、在实现方式中,使用注意力神经网络处理s×t个空间编码的组可以包括向定义图像帧的相应区域和图像帧时间的s×t个空间编码中的每个添加位置信息。位置信息可以包括例如位置嵌入,即图像帧区域和时间的嵌入。嵌入可以包括与空间编码维数相同的向量;可以将它添加到相应的空间编码。嵌入可以被学习或是预定义的。
18、在实现方式中,使用注意力神经网络来处理s×t个空间编码的组包括使用一个或多个自注意力层中的一个来处理包括s×t个空间编码的组的层输入,以便为每个空间编码生成查询和键-值对。自注意力机制然后可以用于将例如每个查询应用于例如每个键,更具体地是键-值对,以确定变换的空间编码的组。自注意力可以包括被掩码的自注意力,在这种情况下,不是所有的查询都可以被应用。自注意力机制可以是多头注意力机制。在实现方式中,自注意力神经网络参数包括应用于层输入以生成查询和键-值对的学习的变换的参数。
19、一般来说,注意力机制将查询和一组键-值对映射到输出,其中查询、键和值都是向量。输出被计算为值的加权和,其中分配给每个值的权重由查询与对应键的兼容性函数来计算。应用的确切的自注意力机制取决于注意力神经网络的配置。例如,每个注意力层可以应用点积注意力机制,例如缩放的点积注意力机制。在缩放的点积注意力中,对于给定的查询,注意力层计算该查询与所有键的点积,将每个点积除以缩放因子,例如除以查询和键的维度的平方根,然后对缩放的点积应用softmax函数以获得值的权重。然后,注意力层根据这些权重计算值的加权和。
20、在一些实现方式中,使用注意力神经网络处理s×t个空间编码的组包括将s×t个空间编码的组作为稍后的输入提供给注意力神经网络的第一自注意力层,以生成第一自注意力层输出,以及将第一自注意力层输出提供给注意力神经网络的第二自注意力层,以生成变换的空间编码的组。在实现方式中,这包括将空间编码的数量从s×t个空间编码减少到k×t个空间编码,其中k<s是对象潜在变量的数量。因此,实现方式可以比存在对象潜在更多的特征图,或者相同数量。这种减少可以在第一自注意力层之后或第二自注意力层之后进行,例如通过在(片的平铺的)水平和/或垂直方向上池化,并且可选地归一化。
21、在另一方面,提供了一种计算机实现的视频处理神经网络系统,包括(经训练的)特征提取神经网络,其被配置为接收包括t个图像帧的序列的视频序列,在一系列时间中的每一个时间处一个图像帧,并且处理每个图像帧以生成t个图像帧中的每一个的一组s个空间编码,从而获得视频序列的s×t个空间编码的组。每个空间编码可以包括图像帧的相应区域的编码。
22、计算机实现的视频处理神经网络系统还包括(经训练的)自注意力神经网络,该自注意力神经网络包括一个或多个自注意力层,每个自注意力层被配置为在层输入上应用自注意力机制。在实现方式中,自注意力神经网络被配置为通过在包括s×t个空间编码的组的层输入上应用自注意力机制,使用注意力神经网络来处理s×t个空间编码的组,以生成变换的空间编码的组,每个变换的空间编码对应于一个图像帧时间和一个图像帧区域。在层输入上应用自注意力机制包括在不同图像帧的空间编码上应用自注意力机制。
23、视频处理神经网络系统被配置为通过在图像帧的时间上聚合变换的空间编码的组,为一组对象潜在变量中的每一个确定用于参数化该对象潜在变量的对象潜在分布的一个或多个值,并且可选地通过从该对象潜在变量的对象潜在分布中采样来确定该组对象潜在变量中的每一个的值。
24、视频处理神经网络系统还可以被配置为通过在图像帧的区域上聚合变换的空间编码的组,为一组帧潜在变量中的每一个确定用于参数化该帧潜在变量的帧潜在分布的一个或多个值,并且可选地通过从该帧潜在变量的帧潜在分布中采样来确定该组帧潜在变量中的每一个的值。
25、视频处理神经网络系统还被配置为:i)根据用于参数化对象潜在分布的值,即根据对象潜在变量或根据用于参数化对象潜在分布的值,确定视频序列中描绘的一个或多个对象的一个或多个属性;ii)根据用于参数化帧潜在分布的值,即根据帧潜在变量或根据用于参数化帧潜在分布的值,确定视频序列的视点的位置或朝向;或者两者都有。
26、在另一个方面,提供了一种计算机实现的视频生成神经网络系统,其被配置为通过从对象潜在变量的相应先验对象潜在分布中采样来确定一组对象潜在变量中的每一个的值,(并且可选地通过从帧潜在变量的相应先验帧潜在分布中采样来确定一组帧潜在变量中的每一个的值)。
27、该系统包括(经训练的)图像帧解码器神经网络,用于处理确定的对象潜在变量的值(以及可选地,确定的帧潜在变量的值),以生成视频序列,该视频序列包括在连续时间步长处生成的图像帧的序列。所述图像帧解码器神经网络被配置为,针对每个生成的图像帧的每个像素和针对每个生成的图像帧时间步长,处理确定的对象潜在变量的值(以及可选地,确定的帧潜在变量的值)、指定像素位置的信息和指定时间步长的信息,以针对像素和针对时间步长,确定每个对象潜在变量的像素分布的参数;组合每个对象潜在变量的像素分布,以确定组合的像素分布;并且从组合的像素分布中采样以确定针对像素和针对时间步长的值。
28、可以实现本说明书中描述的主题的特定实施例,以便实现以下优点中的一个或多个。
29、视频对象表示神经网络系统,具体是包括特征提取神经网络和自注意力神经网络的系统的编码器部分,可以处理3d场景的视频序列,并且同时区分和识别,即表征多个对象。即使当视点(例如相机姿态)正在改变而没有被明确给出关于视点或相机姿态的信息时,系统也能够做到这一点。该系统的实现方式可以处理具有许多对象和复杂背景的场景。
30、因此,该系统能够确定表示,即该组对象潜在变量或它们的分布,这是异我中心的(allocentric),这对于许多任务是重要的。例如,不知道视点的系统可以把一个对象离视点的距离和它的大小混起来;该系统的实施例可以克服这个问题。
31、在该系统的实施例中,该组对象潜在变量或它们的分布提供了场景中对象相对于相机姿态的稳定表示。在该系统的实现方式中,这是通过在空间和时间上、跨视频序列的不同图像帧的注意力,结合因子分解的潜在空间来实现的,该因子分解的潜在空间将静态(即基本上不随时间变化的)对象性质从视频序列的全局或动态属性(诸如相机姿态)中分离出来。这也允许系统确定静态对象运动特性,诸如对象轨迹概要。
32、该系统还确定全局的、潜在时变的场景属性的表示,诸如该组帧潜在变量中的视点或它们的分布。确定视点的能力允许系统用于确定例如配备有像机或其他视频捕获设备的移动机械代理的位置。
33、该系统的一些实现方式也具有比一些先前的系统更简单的架构,而先前的系统能力较差。
34、该系统的实现方式还可以用于生成视频序列,例如仿佛来自特定视点的从现有场景起的视频序列,或者包含一个或多个对象的新的或修改的场景的视频序列。这可以通过例如从现有的场景或者通过从先验分布中对它们进行采样,然后将它们提供给视频对象表示神经网络系统,具体是该系统的解码器部分,确定潜在变量的值来完成。这可以用于例如视点内插或外插,或者用于例如当控制诸如机器人之类的机械代理执行任务时的规划。不像可以针对它们先前已经在其上被训练过的特定场景来这样做的一些先前的系统,该系统的实施例可以在不同的场景上训练,然后针对新的、先前未见过的场景来这样做。
35、例如,未训练的或经训练的视频对象表示神经网络系统的编码器可以用在控制代理执行任务的强化学习系统中,以及或代替来自代理在其中操作的环境的图像,以允许强化学习系统更快或更有效地学习。或者未训练的或经训练的视频对象表示神经网络系统的解码器可以被用作基于模型的强化学习系统,以在学习用于控制代理的动作选择策略时预测环境的未来状态。
36、本说明书主题的一个或多个实施例的细节在附图和以下描述中阐述。根据描述、附图和权利要求书,本主题的其他特征、方面和优点将变得明显。
- 还没有人留言评论。精彩留言会获得点赞!