一种道路场景图像的语义分割方法、装置、设备及介质与流程
本发明涉及自动驾驶,具体涉及一种道路场景图像的语义分割方法、装置、设备及介质。
背景技术:
1、图像的语义分割处理在自动驾驶、医疗图像等领域有着广泛应用。图像的语义分割是将图像的每个像素关联到一个类别,并赋予类别标签,各个像素点有且仅有一个类别标签。图像的语义分割实现了根据图像的深层、浅层特征,将具备特征相似性的像素点划分合并为若干个互不相交的区域。
2、在道路场景中,图像语义分割针对可行驶区域,行人,车辆,交通标志等道路元素,进行区域划分,为车辆获取环境感知信息提供支持。某些道路场景类别在图像中所占区域小,模型的关注程度低,导致该类别的分割效果差。
3、因此,提升语义分割模型在小区域分割上的精度,缓解数据样本分布不均衡,保证模型的精确输出,是一个亟待解决的问题。
技术实现思路
1、鉴于以上现有技术的缺点,本发明提供一种道路场景图像的语义分割方法、装置、设备及介质,以解决上述技术问题。
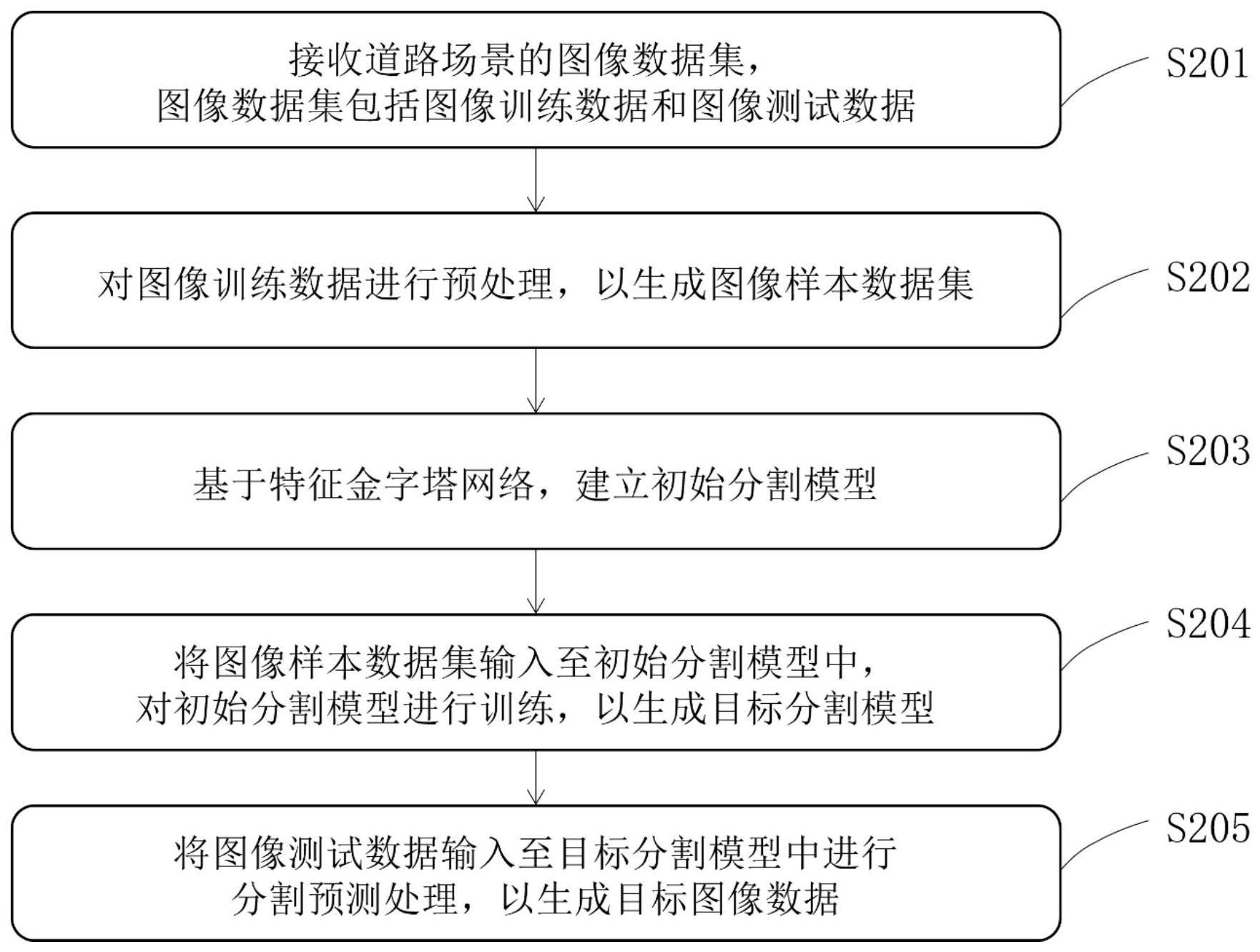
2、本发明提供的一种道路场景图像的语义分割方法,包括
3、接收道路场景的图像数据集,所述图像数据集包括图像训练数据和图像测试数据;
4、对所述图像训练数据进行预处理,以生成图像样本数据集;
5、基于特征金字塔网络,建立初始分割模型;
6、将所述图像样本数据集输入至所述初始分割模型中,对所述初始分割模型进行训练,以生成目标分割模型;以及
7、将所述图像测试数据输入至所述目标分割模型中进行分割预测处理,以生成目标图像数据。
8、于本发明一实施例中,所述将所述图像样本数据集输入至所述初始分割模型中,对所述初始分割模型进行训练的步骤,包括:
9、对所述图像样本数据集中的图像样本进行2倍、4倍、……、2n倍下采样处理,以生成中间数据c2、c4、……、
10、对所述中间数据通过卷积提取特征、双线性插值进行上采样处理,并与所述中间数据相加,以生成特征图
11、按照卷积提取特征、双线性插值进行上采样处理后,并与所述中间数据相加的步骤,对所述特征图进行迭代处理,直至得到特征图o2;以及
12、对所述特征图o2进行双线性差值处理,以生成所述图像样本的特征图。
13、于本发明一实施例中,所述将所述图像样本数据集输入所述初始分割模型进行训练处理,以生成目标分割模型的步骤,包括:
14、对所述初始分割模型进行训练参数设置,所述训练参数包括初始学习率、权重衰减参数、迭代次数、初始预热学习率、预热步数、学习率指数衰减策略以及模型损失函数;以及
15、将所述图像样本数据集输入设置后的所述初始分割模型进行训练处理,以生成目标分割模型。
16、于本发明一实施例中,所述模型损失函数包括类别权重和类别区域权重,所述模型损失函数满足以下公式:
17、loss=weight-category×weight_region×lsoftmax_cross_entropy
18、其中,loss表示模型损失函数,weight_category表示类别权重,weight_region表示类别区域权重,lsoftmax_cross_entropy表示所述初始分割模型的输出经计算得到的损失。
19、于本发明一实施例中,所述类别权重weight-category表征所述图像样本数据集中各类别图像数与图像总数的比值,所述类别权重weight_category满足以下公式:
20、
21、其中,img_num表示所述图像样本数据集中图像总数,a(c)表示所述图像样本数据集中各类别图像数。
22、于本发明一实施例中,所述对所述图像训练数据进行预处理,以生成图像样本数据集的步骤,包括:
23、从所述图像训练数据中抽取图像样本,所述图像样本表征道路场景图片;以及
24、对所述图像样本进行语义标注处理,以生成所述图像样本数据集。
25、于本发明一实施例中,所述将所述图像测试数据输入至所述目标分割模型中进行分割预测处理,以生成目标图像数据的步骤,包括:
26、将所述图像测试数据输入至所述目标分割模型进行预测计算,以生成图像预测数据;以及
27、将所述图像预测数据和所述图像测试数据进行融合处理,以生成所述目标图像数据。
28、本发明还提供一种道路场景图像的语义分割装置,包括:
29、数据接收模块,用于接收道路场景的图像数据集,所述图像数据集包括图像训练数据和图像测试数据;
30、数据预处理模块,用于对所述图像训练数据进行预处理,以生成图像样本数据集;
31、模型构建模块,用于基于特征金字塔网络,建立初始分割模型;
32、模型训练模块,用于将所述图像样本数据集输入至所述初始分割模型中,对所述初始分割模型进行训练,以生成目标分割模型;以及
33、模型测试模块,用于将所述图像测试数据输入至所述目标分割模型中进行分割预测处理,以生成目标图像数据。
34、本发明还提供一种电子设备,包括:
35、一个或多个处理器;
36、存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述电子设备实现如上述中任一项所述的道路场景图像的语义分割方法。
37、本发明还提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序被计算机的处理器执行时,使计算机执行上述中任一项所述的道路场景图像的语义分割方法。
38、综上所述,本发明提供一种道路场景图像的语义分割方法、装置、设备及介质,可用于对道路场景图像的语义分割处理,且本发明对道路场景中小类别和小区域具有较高的分割精度。
39、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
技术特征:
1.一种道路场景图像的语义分割方法,其特征在于,包括:
2.根据权利要求1所述的道路场景图像的语义分割方法,其特征在于,所述将所述图像样本数据集输入至所述初始分割模型中,对所述初始分割模型进行训练的步骤,包括:
3.根据权利要求1所述的道路场景图像的语义分割方法,其特征在于,所述将所述图像样本数据集输入所述初始分割模型进行训练处理,以生成目标分割模型的步骤,包括:
4.根据权利要求3所述的道路场景图像的语义分割方法,其特征在于,所述模型损失函数包括类别权重和类别区域权重,所述模型损失函数满足以下公式:
5.根据权利要求4所述的道路场景图像的语义分割方法,其特征在于,所述类别权重weight_category表征所述图像样本数据集中各类别图像数与图像总数的比值,所述类别权重weight_category满足以下公式:
6.根据权利要求1所述的道路场景图像的语义分割方法,其特征在于,所述对所述图像训练数据进行预处理,以生成图像样本数据集的步骤,包括:
7.根据权利要求1所述的道路场景图像的语义分割方法,其特征在于,所述将所述图像测试数据输入至所述目标分割模型中进行分割预测处理,以生成目标图像数据的步骤,包括:
8.一种道路场景图像的语义分割装置,其特征在于,包括:
9.一种电子设备,其特征在于,所述电子设备包括:
10.一种计算机可读存储介质,其特征在于,其上存储有计算机程序,当所述计算机程序被计算机的处理器执行时,使计算机执行权利要求1至7中任一项所述的道路场景图像的语义分割方法。
技术总结
本发明提供一种道路场景图像的语义分割方法、装置、设备及介质,所述方法包括接收道路场景的图像数据集,所述图像数据集包括图像训练数据和图像测试数据;对所述图像训练数据进行预处理,以生成图像样本数据集;基于特征金字塔网络,建立初始分割模型;将所述图像样本数据集输入至所述初始分割模型中,对所述初始分割模型进行训练,以生成目标分割模型;以及将所述图像测试数据输入至所述目标分割模型中进行分割预测处理,以生成目标图像数据。本发明可实现对道路场景图像的语义分割处理,且本发明对道路场景中小类别和小区域具有很高的分割精度。
技术研发人员:周春宇,吴锐,张琦
受保护的技术使用者:重庆长安汽车股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!