一种针对工业时序不平衡数据的时间序列数据增强方法
本发明涉及工业领域和机器学习方法,尤其涉及一种采用机器学习方法对工业时序不平衡数据的时间序列数据增强方法。
背景技术:
1、在工业领域,由于异常时序样本的罕见性、保密性、不完整性以及部分数据可解释性差等原因,通常很难获得大量的、可解释的异常数据。因此,如何根据少量的异常时序样本,去进行工业时序数据的异常检测,是相关领域专家研究的热点。现有解决时序数据类不平衡问题的主流方法是利用已有的数据集进行数据增强,丰富原数据的样本数量以及特征数量。已有的典型方案主要为时域频域变换、基于分解、基于机器学习和记忆模型建模等方法。
2、时域频域以及两者混合的方法为基础的方法,主要将异常数据在时域或者频域上进行切片,缩放添加噪声等操作,生成新的异常数据;除了基础方法以外,也有统计模型高级方法,比如专利cn202011564567.3公开了通过拟合时间t的值与之前时间步的值的依赖来描述时序分布,进而通过基础的扰动生成新的时序样本。此外还有基于插值和外推的方法;专利cn202110670088.8中公开了利用样本间的欧几里得距离,采用smote的方式在样本间生成基于欧几里得距离产生的样本等。但是上述方法并不完全适用于工业领域的时序数据,存在以下问题:
3、(1)简单直接的合成数据,容易混淆样本界限,可能使模型对于处于样本界限附近的数据的学习困难;
4、(2)由于工业时序数据大多属于离散型时序数据,异常持续时间较短,而且此类数据整体时间步长较短,因此基础方法比如切片,窗口扰动等,容易破坏时序数据的原始特征;
5、(3)基于统计模型的方法大多具有复杂且众多的参数,需要大量原始数据进行训练,且工业时序异常数据具有很强的随机性,因此该类方法并不适用于工业时序数据集。
技术实现思路
1、发明目的:本发明旨在提供一种解决模型过拟合和泛化能力差问题并提高各种分类器对工业不平衡时序数据的预测效果的时间序列数据增强方法的时间序列数据增强方法。
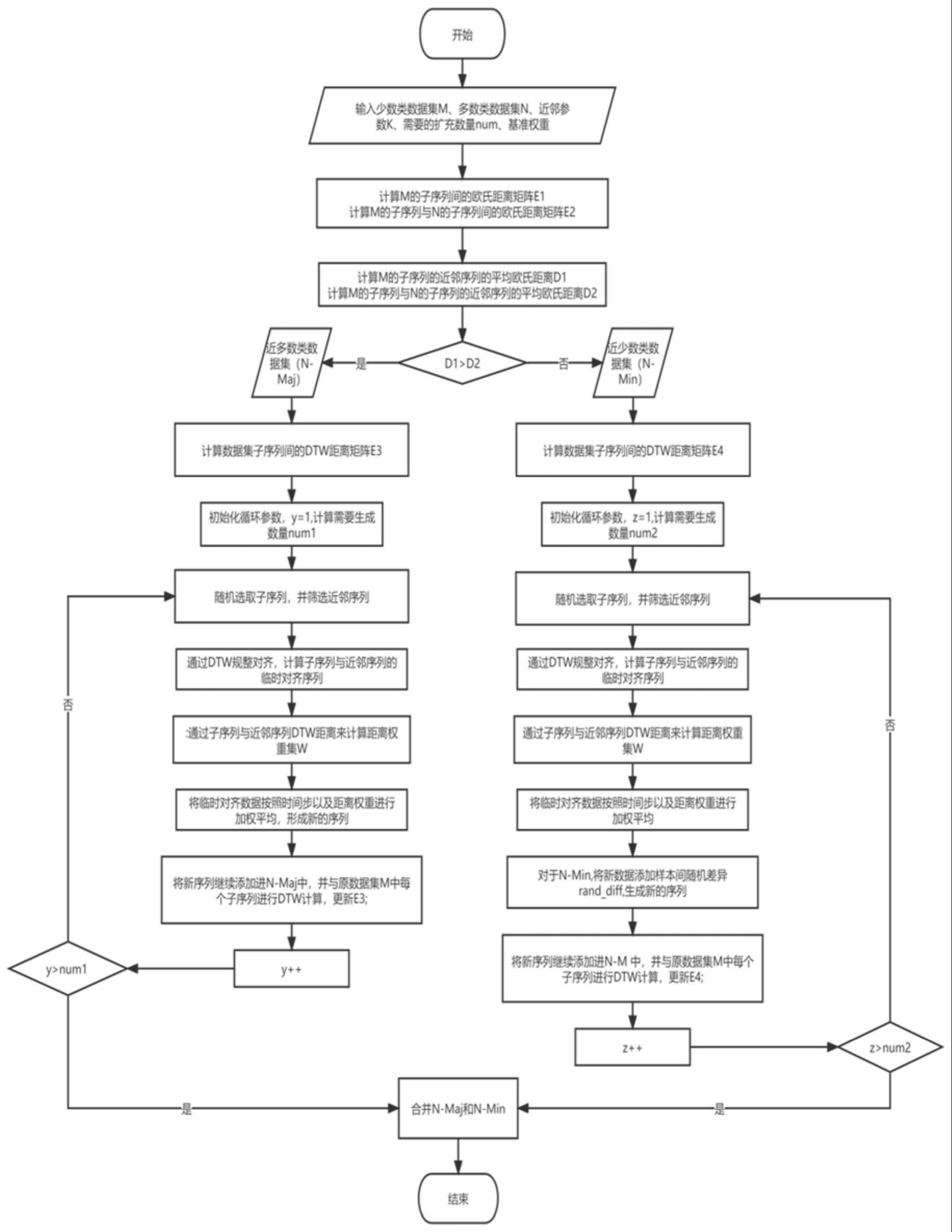
2、技术方案:本发明所述的针对工业不平衡数据的时间序列数据增强方法,步骤如下:
3、s1、将不平衡时序数据集划分为少数类数据集m={m1,m2,...,mm},其中,mi表示第i个子序列;多数类数据集n={n1,n2,...,nn},其中,nj表示第j个子序列;设置近邻样本数量参数k;确定需要生成的样本总数量num;
4、s2、根据平均欧氏距离d1、d2的大小,将m划分为近多数类数据集n-maj,样本数量为n_maj;近少数数据集n-min,样本数量为n-min;
5、s3、计算n-maj的子序列之间的dtw距离,并组成dtw距离矩阵e3;计算n-min的子序列之间的dtw距离,并组成dtw距离矩阵e4;确定n-maj需要生成的序列数量为num1,确定n-min需要生成的数量为num2;
6、s4、随机选取n-maj中的子序列ap,通过e3的对应元素位置,筛选ap的k个近邻子序列,组成近邻序列集p={ap1,ap2,...,apk};
7、s4.1、通过ap和p={ap1,ap2,...,apk}之间的dtw规整对齐,得到临时对齐序列集cp={ap-avg1,ap-avg2,...,ap-avgk};
8、s4.2、根据子序列ap及其近邻序列集cp,确定距离权重集w;
9、s4.3、:按照距离权重集w,对临时对齐序列集cp求取加权平均值,构成新的平均序列ap-avg;
10、s4.4、将新的平均序列ap-avg加入n-maj中,并与n-maj中每个子序列进行dtw计算,更新dtw距离矩阵e3;
11、s4.5、重复步骤s4到s4.4,直到生成num1条新数据;
12、s5、随机选取n-min中的第q个子序列bq,通过e4的对应元素位置,筛选bq的k个近邻子序列,组成近邻序列集q={bq1,bq2,...,bqk};
13、s5.1、通过bq和q={bq1,bq2,...,bqk}之间的dtw规整对齐,得到临时对齐序列集cq={bq-avg1,bq-avg2,...,bq-avgk};
14、s5.2、根据子序列bq及其近邻序列集cq,确定距离权重集w;
15、s5.3、按照距离权重集w,对临时对齐序列集求取加权平均值,构成平均序列bq-avg;
16、s5.4、在bq-avg的每个时间步上添加样本随机差异rand_diff,形成新的序列bq-new;
17、s5.5、将新生成序列bq-new加入n-min中,并与n-min中每个子序列进行dtw计算,同时更新dtw距离矩阵e4和n-min;
18、s5.6、重复步骤s5到s5.5,直到生成num2条新数据;
19、s6、合并n-min和n-maj,组成新的少数类数据集m′,将新的数据集m′与n合并,组成平衡数据集。
20、进一步的,步骤s2中,d1表示子序列mi与少数类数据集m中k个近邻子序列的平均欧氏距离;d2表示子序列mi与多数类数据集n={n1,n2,...,nn}中k个近邻序列的平均欧氏距离;
21、当d1>d2时,子序列mi储存至近多数类数据集n-mai;
22、当d1≤d2时,子序列mi储存至近少数数据集n-min。
23、进一步的,步骤s4、s5中,通过e3、e4对应的元素位置,筛选ap的k个近邻子序列,组成近邻序列集p={ap1,ap2,...,apk}和bq的k个近邻子序列,组成近邻序列集q={bq1,bq2,...,bqk}。
24、进一步的,步骤s4.2中,对子序列ap和近邻序列集p中的子序列进行dtw规整对齐,根据dtw计算过程中求得的最优匹配路径,获得子序列ap和近邻序列集p最优对齐的临时对齐序列集cp={ap-avg1,ap-avg2,...,ap-avgk};通过序列bq和近邻序列集q的dtw最优对齐,得到临时对齐序列集cq={bq-avg1,bq-avg2,...,bq-avgk}。
25、进一步的,步骤s4.3和s5.3中,根据子序列ap与cp在e3中对应的dtw距离,确定权重集;权重集w初始权重为ω0,权重数量为k+1,其和为1,权重集w为:
26、w=[ω0,ω1,ω2,...,ωk]
27、
28、
29、其中,ωj表示权重集中第j个权重,1≤j≤k;ej表示子序列与自身第j条近邻序列dtw距离;fj表示与距离成反比的系数,ρ为配置参数。
30、同理,s5.2中,按根据子序列bq与近邻序列集cq子序列在e4中对应的dtw距离,确定权重集。
31、进一步的,步骤s5.4中,对于由n-min中生成的新序列bq-avg,在其每个时间步的值上添加随机差异rand_diff;其中,每条新序列的随机差异由步骤s5中的子序列bq与近邻序列集q={bq1,bq2,...,bqk}决定,即bq-avg每个时间步上的值需要添加的随机差异,都是由bq=(xq,1,xq,2,...,xq,1)与近邻序列集q={bq1,bq2,...,bqk}中的所有子序列在同一时间步上的平均差异得到,组成长度为t的rand_diff(r):
32、
33、其中,bqi为近邻序列集q={bq1,bq2,...,bqk}的子序列之一。bqi(r)和bq(r)为bqi和bq在不同时间步上的值,1≤r≤t。
34、在bq-avg所有时间步上,添加随机差异,得到bq-new:
35、bq-new(r)=bq-avg(r)+rand_diff(r)。
36、有益效果:本发明与现有技术相比,其显著优点是:本发明与现有技术相比,其显著优点是:1、本发明通过平均欧氏距离,将少数类数据分为近多数类数据集n-maj和近少数类数据集n-min,分别进行数据增强,有效减少数据增强对样本类边界的影响;2、本发明通过dtw对齐计算,建立待增强数据集间的dtw距离矩阵来寻找距离待增强序列的k个近邻序列,将待增强序列与k个近邻序列的dtw对齐,获得临时对齐序列,同时通过基于dtw距离的权重和临时对齐序列进行加权平均生成多样性样本,并且针对近少数类数据集,添加了随机差异,扩增了样本空间,改善了原数据类不平衡的情况,提高模型的泛化能力;3、本发明提高各种分类器对工业不平衡时序数据的预测效果;4、本发明也可用于其他领域的时序数据集,能够有效解决样本数据不足时,模型学习困难的问题。
- 还没有人留言评论。精彩留言会获得点赞!