一种基于深度Q网络改进的多目标进化算法
本发明涉及一种基于深度q网络改进的多目标进化算法,用于解决现有多目标进化算法难以在高维空间中同时维持种群收敛性和多样性的问题。
背景技术:
1、多目标优化问题广泛存在于日常生活和科学研究中,包括路径优化、计算机系统、金融经济学等领域。这些问题是由多个相互冲突和影响的目标组成,通常是非常复杂并且困难的,吸引了越来越多研究人员的注意力。在多目标优化问题中,考虑到是对多个子目标同时优化,并且这些子目标之间是相互冲突的,优化了其中一个子目标必然会导致其他至少一个子目标的性能下降,那么在多目标优化问题中,不存在唯一的最优解,而是存在多个最优解,称为pareto最优解。
2、针对多目标优化问题的求解,出现了多目标进化算法,这是一种模拟生物自然选择与进化的随机搜索算法,适用于求解高度复杂的非线性问题。近些年来,大量基于分解的、基于支配关系的、基于指标的多目标进化算法被提出。然而,在现有的多目标进化算法中,随着目标维数的增加,种群中非支配解的比例增加,导致没有足够的选择压力。此外,现有的多样性维持策略在高维空间中难以维持多样性。为此,从目前的研究状况来说,提出相关的多目标进化算法具有重要意义。
3、深度q网络是神经网络和q-learning的结合,利用神经网络近似模拟q函数,网络输入为当前状态,输出为每个动作对应的q值,根据q值大小选择相应的动作。结合多目标进化算法,设计相应的状态空间、动作空间、奖励模型,在进化过程中训练智能体,从经验池中获取经验进行学习,更新神经网络参数,实现最优的个体选择策略,获取具有较好收敛性和多样性的最终种群。
技术实现思路
1、本发明的目的是为了解决现有多目标进化算法难以在高维空间中同时维持种群收敛性和多样性的问题,提出了一种基于深度q网络改进的多目标进化算法。
2、为了解决上述问题,本发明的构想是:
3、在深度q网络中,结合多目标进化算法,设计相应的状态空间、动作空间、奖励模型,在进化过程中训练智能体,从经验池中获取经验进行学习,更新神经网络参数,实现最优的个体选择策略,获取具有较好收敛性和多样性的最终种群。
4、根据上述的发明构想,本发明采用了如下技术方案:
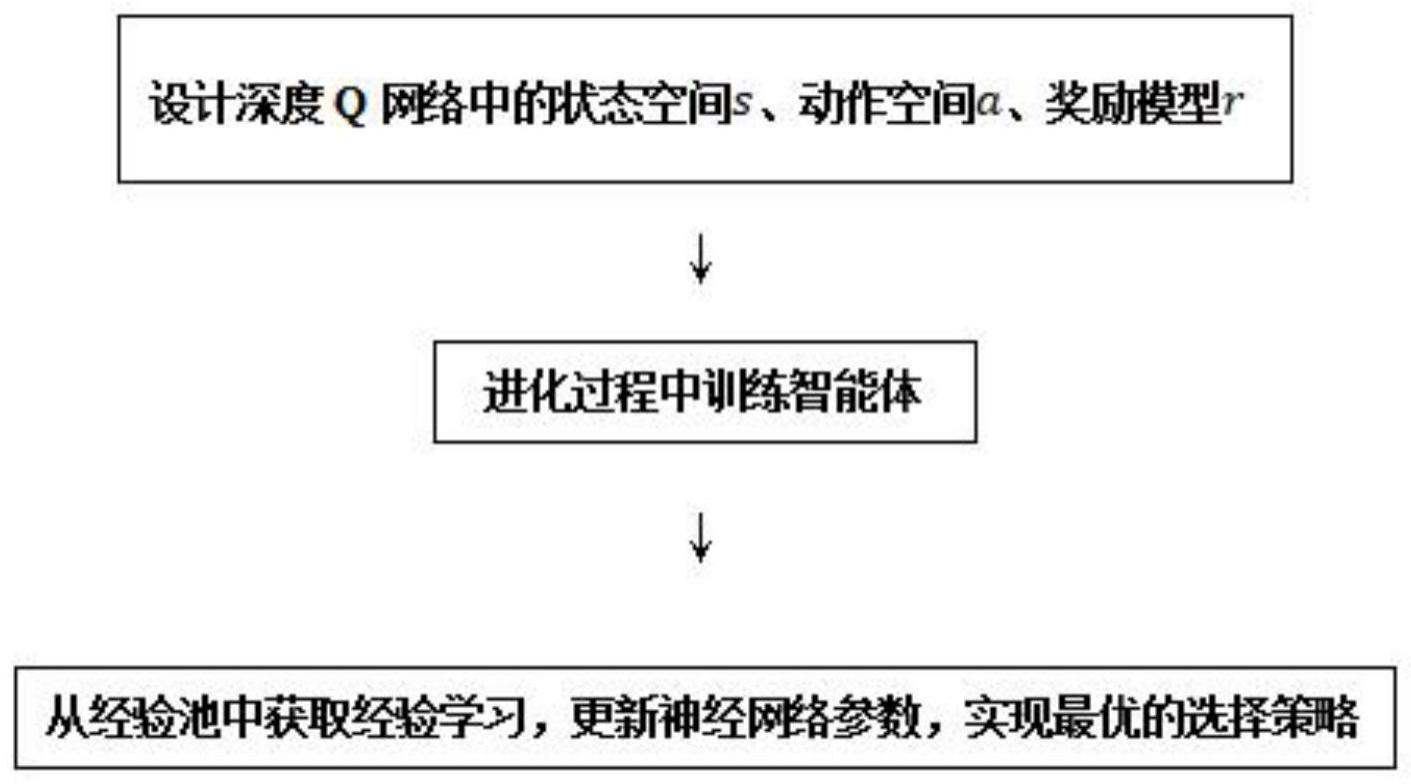
5、一种基于深度q网络改进的多目标进化算法,具体步骤如下:
6、1)设计深度q网络中的状态空间s、动作空间a、奖励模型r;
7、2)进化过程中训练智能体,在每一个时间步骤上,智能体从动作空间中选择一个动作,该动作被传递给种群。更新种群收敛性和多样性的指标来描述状态,同时计算相应的奖励值,将经验(st,at,rt,st+1)存储到经验池中;
8、3)从经验池中获取经验进行学习,更新神经网络参数,实现最优的选择策略。
9、进一步地,所述步骤1)的具体操作步骤为:
10、①、种群收敛性和多样性的衡量指标用于表示种群的当前状态s,进化过程中不同的种群状态构成状态空间;
11、②、候选个体集合映射为动作空间,候选集中的每个个体对应一个动作行为a;
12、③、通过种群的收敛性和多样性来衡量种群的优劣,获得对应的奖励值r。
13、进一步地,所述步骤2)中,使用ε-贪心进行动作的选择,避免只选择同一动作而无法变换。在每一个时间步骤中,有(1-ε)的概率按照q函数来决定动作,有ε的概率随机决定动作。ε会随着时间递减,在探索和利用之间寻求平衡,获取合适的动作。智能体与环境按照某种策略进行交互时,这些历史的状态、动作、奖励等可以作为经验存储到经验池中,用于训练神经网络。在每一个时间步骤上,智能体从动作空间中选择一个动作,更新种群收敛性和多样性指标后,计算相应的奖励值,将经验(st,at,rt,st+1)存储到经验池中。
14、进一步地,所述步骤3)中,使用某种规则从经验池中随机取出一条或多条经验,通常采用批处理的模式来提高训练的稳定性。原有的神经网络称为评估网络,再搭建一个具有相同结构的神经网络称为目标网络。在学习的过程中,只更新评估网络的权重,保证更新权重时针对的目标不会在每次迭代都变化。在完成一定次数的更新后,目标网络的权重更新为评估网络的权重,使得目标网络也得到更新。评估网络和目标网络的设计增加了学习的稳定性。通过智能体与环境进行交互,训练评估网络和目标网络,学习最优的个体选择策略,获得具有较好收敛性和多样性的最终种群。
15、本发明与现有技术比较,具有如下显而易见的突出实质性特点和显著进步:
16、1.本发明方法使用深度q网络来改进多目标进化算法,通过设计状态空间、动作空间、奖励模型,将进化过程中种群的个体选择转化为马尔科夫决策过程,进而使用深度q网络来实现最优的选择策略;
17、2.通过将种群收敛性和多样性设置为观测状态,候选集个体映射为可选动作,在进化过程中训练智能体,从经验池中获取经验进行学习,更新神经网络参数,实现最优的个体选择策略,获取具有较好收敛性和多样性的最终种群。
技术特征:
1.一种基于深度q网络改进的多目标进化算法,其特征在于,具体步骤如下:
2.根据权利要求1所述的基于深度q网络改进的多目标进化算法,其特征在于,所述步骤1)的具体操作步骤为:
3.根据权利要求1所述的基于深度q网络改进的多目标进化算法,其特征在于,所述步骤2)中,使用ε-贪心进行动作的选择,避免只选择同一动作而无法变换;在每一个时间步骤中,有(1-ε)的概率按照q函数来决定动作,有ε的概率随机决定动作。ε会随着时间递减,在探索和利用之间寻求平衡,获取合适的动作;智能体与环境按照某种策略进行交互时,这些历史的状态、动作、奖励等可以作为经验存储到经验池中,用于训练神经网络;在每一个时间步骤上,智能体从动作空间中选择一个动作,更新种群收敛性和多样性指标后,计算相应的奖励值,将经验(st,at,rt,st+1)存储到经验池中。
4.根据权利要求1所述的基于深度q网络改进的多目标进化算法,其特征在于,所述步骤3)中,使用某种规则从经验池中随机取出一条或多条经验,采用批处理的模式来提高训练的稳定性;原有的神经网络称为评估网络,再搭建一个具有相同结构的神经网络称为目标网络;在学习的过程中,只更新评估网络的权重,保证更新权重时针对的目标不会在每次迭代都变化;在完成一定次数的更新后,目标网络的权重更新为评估网络的权重,使得目标网络也得到更新;评估网络和目标网络的设计增加了学习的稳定性;通过智能体与环境进行交互,训练评估网络和目标网络,学习最优的个体选择策略,获得具有较好收敛性和多样性的最终种群。
技术总结
本发明公开了一种基于深度Q网络改进的多目标进化算法。本算法的操作步骤如下:(1)设计深度Q网络中的状态空间s、动作空间a、奖励模型r;(2)进化过程中训练智能体,在每一个时间步骤上,智能体从动作空间中选择一个动作,该动作被传递给种群。更新种群收敛性和多样性的指标来描述状态,同时计算相应的奖励值,将经验(s<subgt;t</subgt;,a<subgt;t</subgt;,r<subgt;t</subgt;,s<subgt;t+1</subgt;)存储到经验池中;(3)从经验池中获取经验进行学习,更新神经网络参数,实现最优的选择策略。本发明在多目标进化算法中引入深度Q网络学习思想,智能体通过与环境进行交互得到行动反馈,利用奖励机制优化个体选择。
技术研发人员:冯国瑞,周雨
受保护的技术使用者:上海大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!