一种高带宽利用率的稀疏矩阵向量相乘加速装置
本发明属于计算机体系结构领域。
背景技术:
1、稀疏矩阵向量相乘(spmv,sparse matrix-vector multiplication)被广泛应用于图形计算、机器学习、工业工程等领域。随着互联网时代的发展,spmv任务处理的数据规模增加,从而影响了这些应用的执行时间。因此,加速spmv对于提高这些应用程序的性能至关重要。
2、相比于传统的密集矩阵向量相乘,spmv中的矩阵包含大量的零元素。为了节省存储空间以及数据传输量,压缩存储格式只会存储和传输稀疏矩阵中的非零元素和非零元素在矩阵中的位置信息。基于此存储方式,对于每一个非零元素,spmv根据其列号读取对应的向量元素与之相乘,随后将乘法结果与行号对应的结果向量中的部分和累加得到新的部分和,当所有非零元素计算完后,即可得到最终结果。然而,在稀疏矩阵中,非零元素的分布是随机的,这使得spmv任务执行过程中会引入对向量的随机访问,导致数据访问所需的时间超过浮点计算所需的时间。此外,由于稀疏矩阵压缩存储格式的特点,spmv对向量的访问是间接的,与密集矩阵向量乘法相比,spmv的内存密集型特点更加突出。
3、对于中央处理器(cpu,central processing unit)或者图形处理器(gpu,graphics processing unit),spmv对内存的随机访问容易导致缓存丢失。cpu和gpu的计算吞吐量往往超过可用内存带宽,这与spmv的内存密集型特点相反。因此,cpu和gpu并不是加速spmv的理想平台。而fpga具有较大的存储带宽、可定制的逻辑单元和高性能的浮点单元,是加速spmv的合适平台。
4、因为spmv的执行时间主要取决于片外带宽加载数据的时间,所以带宽利用率(bu,bandwidth utilization)是评价基于fpga的spmv加速器性能的被广泛使用的指标。具体来说,bu是由有效的数据大小和任务执行中的延迟所决定的,因此如何减少数据冗余和任务延迟对于在fpga上实现spmv加速器至关重要。在加速spmv的工作中,通常会对spmv任务进行并行化处理,但是在并行模式下工作时将产生同时多次随机访问,而fpga片上的块随机存取存储器(bram,block random access memory)通常只有两个独立的端口,如何处理这种同时多次随机访问是一项具有挑战性的工作。如果这个问题没有得到很好的解决,通常会导致内存端口冲突或工作负载不平衡,进一步增加spmv任务延迟,最终得到较差的bu。
5、目前针对并行处理时随机访问冲突的问题,主要有三种解决方案。第一种方案使矩阵中的非零元素按照列号在处理元素(pe,processing element)中顺序执行,从而将对输入向量的随机访问转换成顺序访问。但是,这种执行方式在并行模式下容易发生部分和的写后读冲突以及pe间的相互等待,从而导致更长的任务延迟和较差的bu。第二种方案是在存储非零元素的位置信息时,直接用非零元素参与乘法运算时所需的向量元素替换非零元素的列号。在存储稀疏矩阵时,列号是32位整型数据,向量元素是64位双精度浮点数据,因此,在矩阵足够稀疏时,该方案可以取得较好的性能。然而,当矩阵不是那么稀疏时,就无法忽略该方法造成的数据冗余。最后一种方案通过利用现有的fpga片上的大容量bram,将所有向量元素加载到片上存储中。然后,以减少同时访问造成的端口冲突为目的,将非零数据重新排序。但是,该方法受非零数据在矩阵中的分布的限制,不能消除所有的端口冲突,对于一些矩阵反而导致了更差的bu。另外,该方法还存在非零元素重排序算法复杂度较高的问题。总的来说,现有的工作不能很好地处理并行模式下需要同时进行多个随机访问的问题,从而造成更多的数据冗余或更长的延迟。基于以上分析,在尽量少的产生数据冗余的情况下,减少随机访问带来的任务延迟,将对提高spmv任务的bu产生重要作用。
技术实现思路
1、本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
2、为此,本发明的目的在于提出一种高带宽利用率的稀疏矩阵向量相乘加速装置,用于提升spmv任务的带宽利用率。
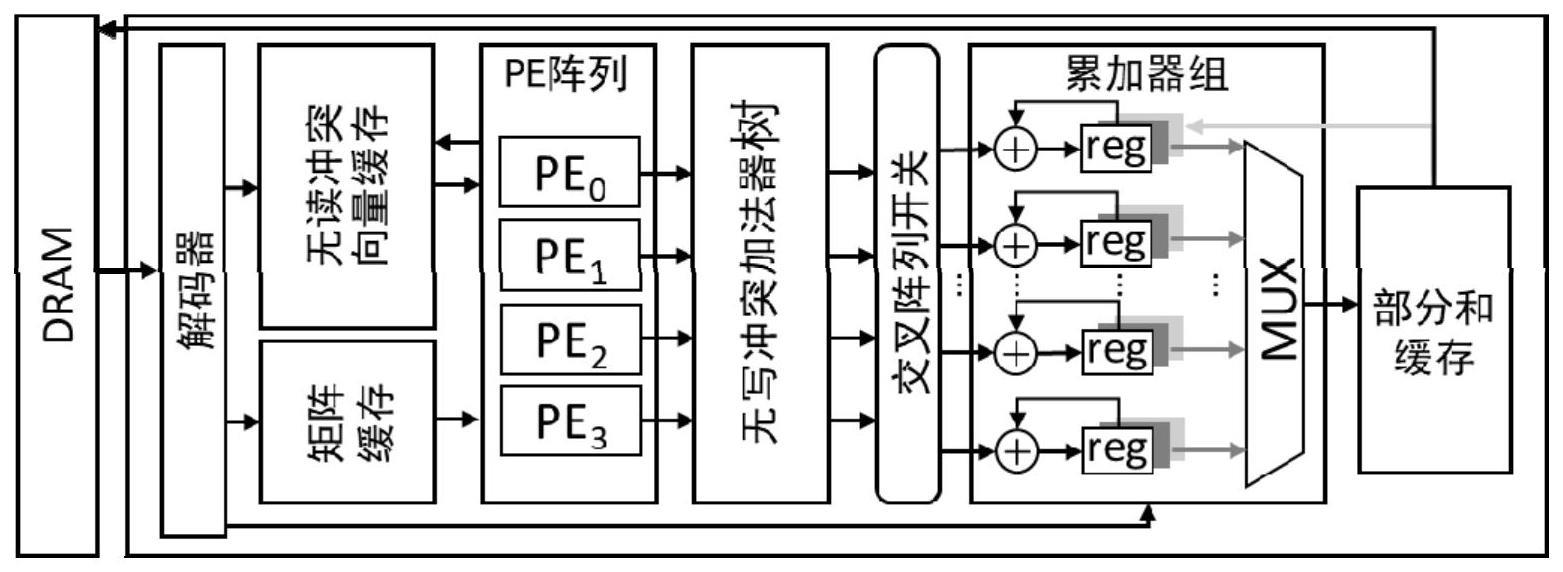
3、为达上述目的,本发明第一方面实施例提出了一种高带宽利用率的稀疏矩阵向量相乘加速装置,包括:解码器、无读冲突的输入向量缓存、计算单元阵列、无写冲突的加法器树、支持乒乓的累加器组、存储部分和及结果向量的缓存;其中,
4、所述解码器用于对预处理后的目标矩阵进行解码,其中,所述解码器将所述目标矩阵中的向量元素解码后传入所述无读冲突的输入向量缓存,将所述目标矩阵中的非零元素解码后传入所述计算单元阵列;
5、所述计算单元阵列用于根据所述非零元素的列号从所述无读冲突的输入向量缓存中读取相应的向量元素,再将所述向量元素和所述非零数据相乘,将得到的相乘结果和所述非零元素的行号传入所述无写冲突的加法器树;
6、所述无写冲突的加法器树用于将所述行号相同的所述相乘结果进行相加,将得到的相加结果传入累加器中;
7、所述支持乒乓的累加器组用于所述相加结果累加。
8、另外,根据本发明上述实施例的一种高带宽利用率的稀疏矩阵向量相乘加速装置还可以具有以下附加的技术特征:
9、进一步地,在本发明的一个实施例中,还包括预处理模块,用于对目标矩阵进行预处理,包括对所述目标矩阵进行纵向划分为多个块,对所述多个块中的每个块进行横向划分为多个批次。
10、进一步地,在本发明的一个实施例中,所述无读冲突的输入向量缓存,还用于:
11、以4个块随机存取存储器bram为一组bram,使用两组bram分别存储所述非零元素和所述非零元素副本;对于所述无读冲突的输入向量缓存中的每一组bram使用两个4对1的多路选择器从所述每一组bram中的4个bram中读取2个非零元素或非零元素副本;其中,所述每一组bram的端口以分时复用的方式工作。
12、进一步地,在本发明的一个实施例中,所述无写冲突的加法器树,还用于:
13、将所述相乘结果和0通过寄存器存储;
14、将所述相乘结果分别发送到4个2选1的多路选择器,所述多路选择器的其他输入为0;
15、将所述4个2选1的多路选择器的读取结果通过两个10级流水的加法器相加,并将所述两个10级流水的加法器的相加结果通过寄存器存储;
16、将所述两个10级流水的加法器的相加结果用另一个10级流水加法器相加,将所述另一个10级流水加法器的相加结果通过寄存器存储;
17、通过一个8选4的交叉阵列开关选择4个寄存器的存储数据作为部分和输出,以消除将所述行号相同的所述相乘结果进行相加产生的写后读冲突。
18、进一步地,在本发明的一个实施例中,所述支持乒乓的累加器组,还用于:
19、在所述目标矩阵的每个批次的数据计算完成后,将得到的累加结果写入所述存储部分和及结果向量的缓存中。
20、进一步地,在本发明的一个实施例中,所述支持乒乓的累加器组,还用于:
21、根据所述累加器组中的独立累加器计算每个批次的数据;
22、通过在所述独立累加器中添加2个额外的寄存器实现批次间的切换,以实现隐藏部分和的加载和存储部分和的开销。
23、本发明实施例提出的高带宽利用率的稀疏矩阵向量相乘加速装置,通过对部分向量进行复制,增加了片上缓存的读写端口,解决了并行模式下端口冲突的问题。并且,通过无冲突加法器树的设计,消除了部分和的写后读冲突,进一步减少spmv任务延迟,得到更高的带宽利用率。
- 还没有人留言评论。精彩留言会获得点赞!