一种基于相似度特征融合的小样本图像分类方法
本发明属于图像分类领域,具体的说是一种基于相似度特征融合的小样本图像分类方法。
背景技术:
1、近年来,卷积神经网络(cnn)已在包括图像分类、分割等大量视觉任务上展现出强大的性能,但是其依赖于大规模标注数据进行训练,而大规模数据的标注需要耗费大量的人力物力成本,这限制了其应用场景。为了解决这一问题,人们提出了小样本学习(fsl)这一任务。其旨在通过有限的训练样本完成对测试样本的分类。
2、目前,在小样本学习(fsl)任务中往往采用预训练的方式。其使用在基础类别上预训练的特征提取器(backbone)直接提取支持类别的样本特征,并使用支持样本的特征训练分类器。训练稳健的特征提取器(backbone)可以有效提升小样本学习(fsl)模型的性能,然而,从零设计、训练并验证一个特征提取器耗时且昂贵。而且由于基础类别与支持类别不相交,在基础类别上预训练的特征提取器(backbone)更倾向于关注它所学习的基础类别样本的纹理和结构信息,导致其忽略了支持样本的细节,其存在着分类性能较弱的问题。
3、为解决上述在少量支持样本上分类性能不足的问题,基于数据生成的方式基于当前的支持样本生成更多的新样本以辅助分类器的优化过程,但是其忽视了基础类别与支持类别间的差异,并且在数据生成过程中引入了额外噪声,反而会对分类器产生误导。
4、基于上述分析,目前如何减少由于基础类别与支持类别、基础样本与支持样本间差异引入的特征表示间的偏差,从而提升分类器对支持类别的响应能力,是小样本学习急需解决的问题。
技术实现思路
1、本发明是为了解决上述现有技术存在的不足之处,提出了一种基于相似性特征融合的小样本图像分类方法,通过直接建模支持样本与基础样本、支持类别与基础类别间的相似性,从而能提升小样本图像分类的准确性。
2、本发明为达到上述发明目的,采用如下技术方案:
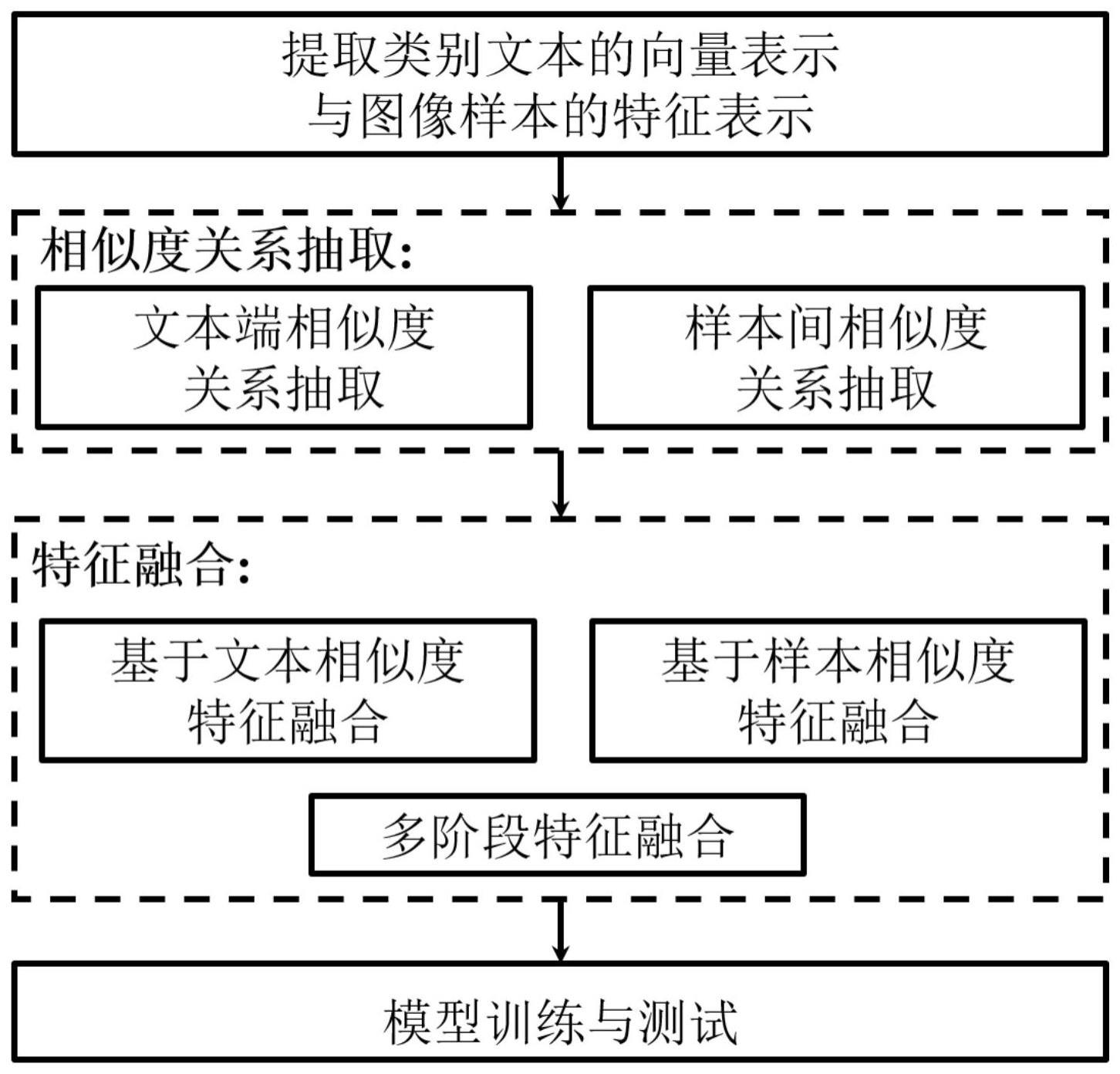
3、本发明一种基于相似度特征融合的小样本图像分类方法的特点是按以下步骤进行:
4、步骤1、输入图像的特征提取:
5、步骤1.1、获取自然图像集合并输入预训练的cnn模型中进行特征提取,得到自然图像的特征表示及其基础类别集合,记为其中,表示第i个自然图像的特征表示,且d表示特征表示的维度,表示第i个自然图像所属的基础类别,且cbase表示自然图像集合的基础类别集合,|cbase|表示自然图像集合的基础类别数量,nbase表示每个基础类别中的自然图像数量;
6、步骤1.2、获取另一图像样本集合并输入所述预训练的cnn模型中进行特征提取,得到图像样本的特征表示及其支持类别集合,记为其中,表示第j个图像样本的特征表示,且表示第j个图像样本所属的支持类别,且cnovel表示图像样本的支持类别集合,且满足cnovel∩cbase=φ,|cnovel|表示图像样本的支持类别数量,nnovel表示每个支持类别中的图像样本数量;
7、步骤2:文本端相似度关系抽取:
8、步骤2.1、使用预训练的词嵌入模型提取基础类别集合cbase中各基础类别的文本信息的向量表示其中,表示第k个基础类别的文本信息的向量表示,t表示向量表示的维度;
9、步骤2.2、使用所述预训练的词嵌入模型提取支持类别集合cnovel中各支持类别的文本信息的向量表示其中,表示第s个支持类别的文本信息的向量表示,
10、步骤2.3、使用式(1)计算第s个支持类别的文本信息的向量表示与第i个基础类别文本信息的向量表示之间的距离并作为第s个支持类别与一个基础类别的文本端相似度关系,从而得到第s个支持类别与所有基础类别之间文本端相似度关系向量
11、
12、式(1)中,表示与的向量内积,与分别表示与的l2范式;
13、步骤3:样本间相似度关系抽取:
14、使用式(2)计算第j个图像样本的特征表示与第i个自然图像的特征表示之间的距离并作为第j个图像样本与一个自然图像间相似度关系,从而得到第j个图像样本与所有自然图像之间的样本相似度关系向量
15、
16、式(2)中,表示与的向量内积,与分别表示与的l2范式;
17、步骤4:基于文本相似度的特征融合,并生成融合后的特征
18、步骤5:基于样本相似度的特征融合,并生成融合后的特征
19、步骤6:多阶段特征融合,并生成融合后的特征
20、步骤7:模型训练与测试:
21、步骤7.1、依据所述特征提取模块,对基础样本集合与支持集合提取图像的特征表示,由所述基于文本相似度的特征融合、基于样本相似度的特征融合与多阶段特征融合构成相似度特征融合模块,对支持样本按照特征融合方式的选择进行特征融合,得到融合后的样本
22、步骤7.2、利用式(3)构建损失函数l;
23、
24、式(3)中,lce表示交叉熵损失,γ表示分类器,λ为特征融合时的调和因子;表示支持样本的类别,且与融合后的样本的类别一致;
25、步骤7.3、利用梯度下降算法训练所述分类器γ,并计算损失函数l,以更新分类器γ的参数,当训练迭代次数达到设定的次数时,停止训练,得到训练后的分类器γ*,用于预测新图像样本的类别。
26、本发明所述的基于相似度特征融合的小样本图像分类方法的特点也在于,所述步骤4包括:
27、步骤4.1、将第j个图像样本的特征表示在vnovel中对应支持类别的文本信息的向量表示记为并提取与基础类别集合cbase中所有基础类别的文本相似度关系rt(j);
28、步骤4.2、从第j个图像样本的特征表示的文本相似度关系rt(j)中选择β个最近距离所对应的基础类别集合,并将β个基础类别集合中所有的自然图像的特征表示作为文本端备选集其中,表示文本端备选集dtextual中第r个自然图像的特征表示并作为备选特征表示;
29、步骤4.3、生成文本端随机向量vt∈rd,且文本端随机向量vt服从0-1均匀分布vt~u(0,1),定义超参数α,且α∈[0,1],依据随机向量vt与超参数α,使用式(4)构建文本端掩码向量mt∈rd;
30、
31、式(4)中,vtt表示文本端随机向量vt中第t个随机值;mtt表示mt中第t个掩码值;
32、步骤4.4、依据所述备选特征表示以及文本端掩码向量mt,使用式(5)对第j个图像样本的特征表示进行特征融合,生成融合后的特征
33、
34、式(5)中,表示向量内积,λ为beta(2,2)分布中随机采样的调和因子。
35、所述步骤5包括:
36、步骤5.1、对于第j个图像样本的特征表示提取与基础类别集合dbase中所有自然图像的特征表示的样本间相似度关系ri(j);
37、步骤5.2、从当前样本的样本间相似度关系ri(j)中选择γ个距离最近的自然图像的特征表示作为样本端备选集dinstance,且其中,表示样本端备选集dinstance中第r个自然图像的特征表示并作为备选特征表示;
38、步骤5.3、生成样本端随机向量vi∈rd,vi服从0-1均匀分布vi~u(0,1),定义超参数α,且α∈[0,1],依据随机向量vi与超参数α,使用式(6)构建样本端掩码向量mi∈rd;
39、
40、式(6)中,vik表示样本端随机向量vi中第k个随机值;mik表示mi中第k个掩码值;
41、步骤5.4、依据所述备选特征表示以及样本端掩码向量mt,使用式(7)对第j个图像样本的特征表示进行特征融合,生成融合后的特征
42、
43、式(7)中,表示向量内积,λ为beta(2,2)分布中随机采样的调和因子。
44、所述步骤6包括:
45、步骤6.1、对于第j个图像样本的特征表示vnovel中对应其支持类别的文本信息的向量表示记为提取与基础类别集合cbase中所有基础类别的文本相似度关系rt(j),并提取与基础类别集合dbase中所有自然图像的特征表示的样本相似度关系ri(j);
46、步骤6.2、从第j个图像样本的特征表示的文本相似度关系rt(j)中选择β个最近距离所对应的基础类别集合,并将β个基础类别集合中所有的自然图像的特征表示作为文本端备选集其中,表示文本端备选集dtextual中第r个自然图像的特征表示;
47、步骤6.3、从文本备选集dtextual中依据样本间相似度关系ri(s)选择γ个距离最近的基础图像样本作为备选集dcandidate,且其中,xfcandidate表示备选集dcandidate中第f个自然图像的特征表示并作为备选特征表示进行特征融合;
48、步骤6.4、生成随机向量v,其中v∈rd,且随机向量v服从0-1均匀分布v~u(0,1),定义超参数α,且α∈[0,1],依据随机向量v与超参数α,使用式(8)构建样本端掩码向量m,其中,m∈rd;
49、
50、步骤6.5、依据所述备选特征表示以及掩码向量m,使用式(9)对第j个图像样本的特征表示进行特征融合,生成融合后的特征
51、
52、式(9)中,表示向量内积,λ为beta(2,2)分布中随机采样的调和因子。
53、本发明一种电子设备,包括存储器以及处理器的特点在于,所述存储器用于存储支持处理器执行所述小样本图像分类方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
54、本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序的特点在于,所述计算机程序被处理器运行时执行所述小样本图像分类方法的步骤。
55、与现有技术相比,本发明的有益效果在于:
56、1、本发明设计了一种基于相似性特征融合的小样本图像分类方法,通过直接建模支持样本与基础样本、支持类别与基础类别间的相似性,解决了使用在基础类别上预训练的特征提取器提取支持类别样本特征时带来的信息丢失、对支持特征细节关注不足的问题。
57、2、本发明同时利用了基础类别与支持类别、基础样本与支持样本间相似性,生成更具判别性、代表性、表达能力强的新样本,相较于传统的基于数据生成的方法,减少了数据生成过程引入的偏差与噪声,充分考虑了基础类别与支持类别间的差异,更好地辅助分类器训练,提升了小样本分类方法的分类准确度。
58、3、本发明通过生成支持特征直接训练分类器,相较于传统的基于特征提取器训练的方案,更加简单高效,大大减弱了由于训练特征提取器带来的复杂的时间成本与昂贵的计算成本,同时弥补了由于类别差异引入的语义偏见,提升了分类准确度。
- 还没有人留言评论。精彩留言会获得点赞!