密集场景中的多目标跟踪方法、系统及电子设备
本发明涉及多目标跟踪,尤其是指一种密集场景中的多目标跟踪方法、系统及电子设备。
背景技术:
1、随着计算机视觉领域的快速发展,多目标跟踪算法的精度也得到了提高。特别是,在普通的行人跟踪场景中,已经取得了相当大的准确性。然而,主流模式在密集的场景中仍有改进的空间。拥挤场景中的多个目标跟踪需要更精细的特征表示,因此需要对现有的网络进行改进,改进后的网络能够在密集场景的多目标跟踪上有较好的性能。
2、多目标跟踪(mot)是计算机视觉中的一个经典任务。它试图在视频中找到帧之间的关系,并用一个边界框和id标记相同的对象。在这一领域的研究中已经有了很多的应用,如自动驾驶、视频分析、人机交互等。近年来,大多数mot算法都采用了一种被称为检测跟踪的方法。这意味着它首先使用一些特定的目标检测算法来获取每一帧中的对象位置,然后使用卡尔曼滤波、匈牙利匹配或其他进展后的方法来匹配两帧之间具有相同id的相同对象。例如,jde、deepsort、关系跟踪和simple跟踪都采用了这种方法。fairmot是这类产品的重要代表。它使用了一个基于中心网络的目标检测网络,这是一种经典的无锚点目标检测算法。此外,它还平行于一个re-id分支。fairmot的多对象跟踪精度(mota)在mot17数据集上达到73.7%,这在提交时是最先进的。
3、然而,fairmot在密集的场景中效果并不是很好。只有61.8%mota在mot20数据集上包含更小的对象。fairmot采用深层聚合(dla)作为骨干,是一种经典的关键点检测网络。由于centernet是一个基于热图的目标检测网络,dla甚至可以比resnet获得更高的结果。在fairmot中,re-id分支与检测分支共享相同的模型来聚合多层特征。结果表明,主干的中间层特征可能不利于re-id。
技术实现思路
1、为此,本发明所要解决的技术问题在于克服现有技术中拥挤场景下多目标跟踪精度不高的问题。
2、为解决上述技术问题,本发明提供了一种密集场景中的多目标跟踪方法,包括:
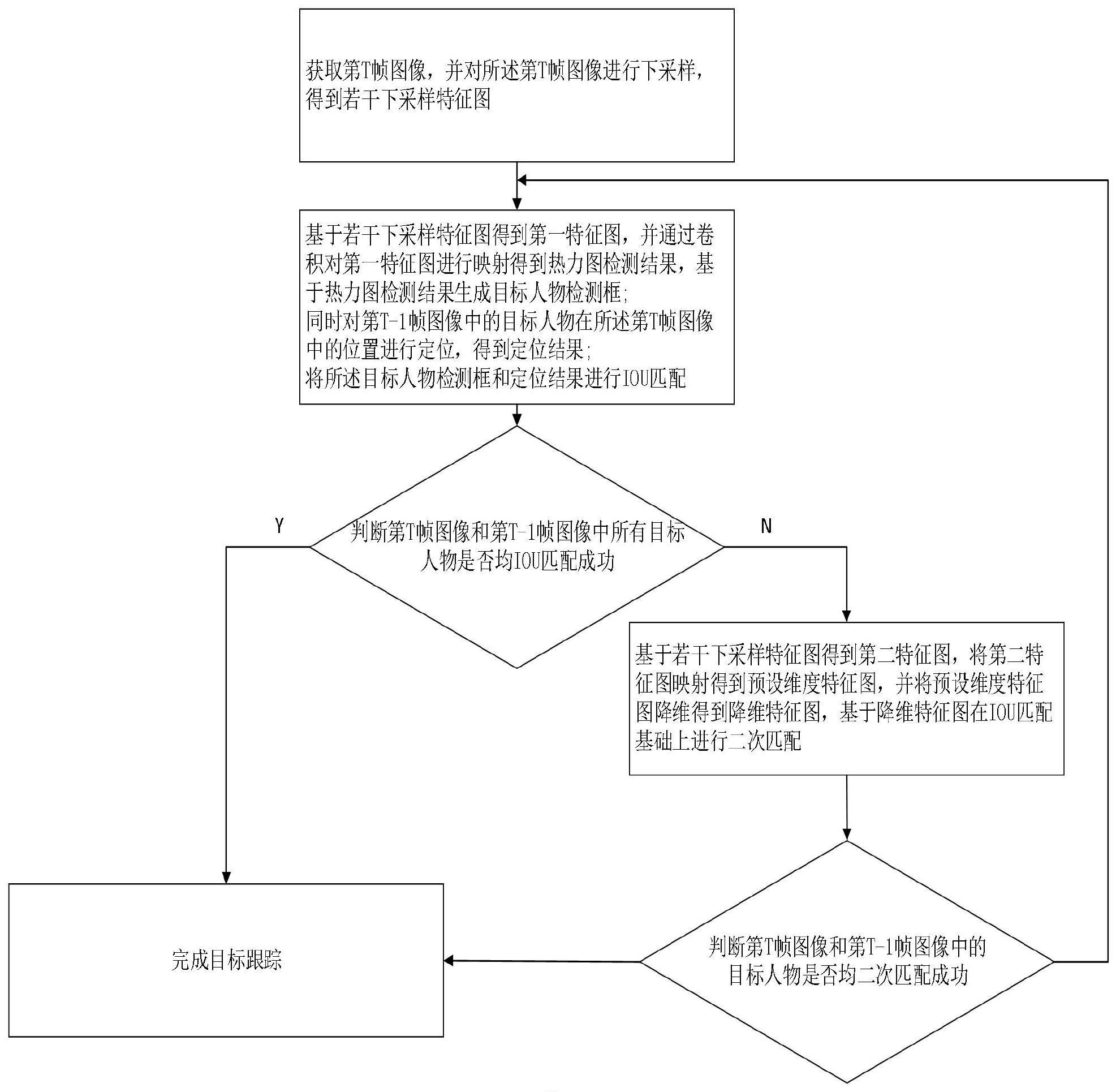
3、步骤s1:获取第t帧图像,并对所述第t帧图像进行下采样,得到若干下采样特征图;
4、步骤s2:将所述若干下采样特征图进行上采样和特征融合,得到第一特征图,并通过卷积对所述第一特征图进行映射得到热力图检测结果;
5、同时对第t-1帧图像中的目标人物在所述第t帧图像中的位置进行定位,得到定位结果,并基于所述热力图检测结果得到目标人物检测框;
6、步骤s3:将所述目标人物检测框和定位结果进行iou匹配,若第t帧图像和第t-1帧图像中所有目标人物均iou匹配成功,则完成目标跟踪;若第t帧图像和第t-1帧图像中存在目标人物iou匹配未成功;执行步骤s4;
7、步骤s4:将所述步骤s1中的若干下采样特征图进行上采样,得到第二特征图,将所述第二特征图映射得到预设维度特征图,并将所述预设维度特征图进行降维,得到降维特征图;
8、步骤s5:将所述降维特征图在iou匹配基础上进行二次匹配,具体为:将所述降维特征图与预存的第t-1帧图像中的目标人物进行匹配,若第t帧图像和第t-1帧图像中iou匹配未成功的目标人物均二次匹配成功,则完成目标跟踪;若第t帧图像和第t-1帧图像中iou匹配未成功的目标人物二次匹配也未成功,则返回至步骤s2,直到所有目标人物均完成匹配。
9、在本发明的一个实施例中,所述步骤s1中的对所述第t帧图像进行下采样,得到若干下采样特征图的方法具体为:通过dla编码器对所述第t帧图像进行下采样,得到若干下采样特征图,其中,所述dla编码器包括若干根和若干类卷积块,所述根用于将类卷积块之间相互相加,所述类卷积块用于改变图像的通道数。
10、在本发明的一个实施例中,所述类卷积块包括依次连接的卷积层、第一层归一化、深度可分离卷积层、第二层归一化、第一多层感知机、gelu激活函数和第二多层感知机,并且所述卷积层和第二多层感知机进行求和;
11、所述卷积层用于改变特征图的信道数;
12、所述第一层归一化和第二层归一化均用于防止过拟合,增加泛化性;
13、所述深度可分离卷积层用于减少参数数量,模拟自注意力操作;
14、所述第一多层感知机和第二多层感知机均用于弥补深度可分离卷积通道间没有交互的问题。
15、在本发明的一个实施例中,所述步骤s2中将所述若干下采样特征图进行上采样和特征融合,得到第一特征图,具体为:将所述若干下采样特征图进行上采样得到若干分辨率不同的上采样特征图,再将若干分辨率不同的上采样特征图进行特征融合,得到第一特征图。
16、在本发明的一个实施例中,所述步骤s2中对第t-1帧图像中的目标人物在所述第t帧图像中的位置进行定位,具体为:通过卡尔曼滤波对第t-1帧图像中的目标人物在所述第t帧图像中的位置进行定位。
17、在本发明的一个实施例中,所述步骤s4中将所述预设维度特征图进行降维,得到降维特征图,具体为:将所述预设维度特征图的长和宽合成一个维度,得到降维特征图。
18、在本发明的一个实施例中,所述步骤s5中将所述降维特征图在iou匹配基础上进行二次匹配,具体为:将所述降维特征图在iou匹配基础上进行匈牙利匹配,所述匈牙利匹配通过计算目标人物之间的余弦距离来实现,若
19、目标人物之间的余弦距离小于预设阈值,则表明目标人物匹配成功;若目标5人物之间的余弦距离大于预设阈值,则表明目标人物匹配未成功。
20、为解决上述技术问题,本发明提供了一种密集场景中的多目标跟踪系统,包括:
21、下采样模块:用于获取第t帧图像,并对所述第t帧图像进行下采样,得到若干下采样特征图;
22、0特征生成与定位模块:用于将所述若干下采样特征图进行上采样和特征
23、融合,得到第一特征图,并通过卷积对所述第一特征图进行映射得到热力图检测结果,并基于所述热力图检测结果得到目标人物检测框;
24、同时用于对第t-1帧图像中的目标人物在所述第t帧图像中的位置进行
25、定位,得到定位结果;
26、5第一匹配模块:用于将所述目标人物检测框和定位结果进行iou匹配,
27、若第t帧图像和第t-1帧图像中所有目标人物均iou匹配成功,则完成目标跟踪;若第t帧图像和第t-1帧图像中存在目标人物iou匹配未成功;执行特征生成模块的过程;
28、特征生成模块:用于将所述若干下采样特征图进行上采样,得到第二特0征图,将所述第二特征图映射得到预设维度特征图,并将所述预设维度特征
29、图进行降维,得到降维特征图;
30、第二匹配模块:用于将所述降维特征图在iou匹配基础上进行二次匹配,具体为:将所述降维特征图与预存的第t-1帧图像中的目标人物进行匹
31、配,若第t帧图像和第t-1帧图像中iou匹配未成功的目标人物均二次匹配5成功,则完成目标跟踪;若第t帧图像和第t-1帧图像中iou匹配未成功的目标人物二次匹配也未成功,则返回至特征生成与定位模块的执行过程,直到所有目标人物均完成匹配。
32、为解决上述技术问题,本发明提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述密集场景中的多目标跟踪方法的步骤。
33、为解决上述技术问题,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述密集场景中的多目标跟踪方法的步骤。
34、本发明的上述技术方案相比现有技术具有以下优点:
35、本发明所述的密集场景中的多目标跟踪方法重新设计了深层聚合编码器(dla编码器),它满足了实时需求,并在密集的场景数据集上有了显著的精度提高;本发明通过两次目标人物的匹配,能尽可能将视频图像帧中的目标进行匹配,确保目标跟踪的有效性;本发明进一步提高了密集场景中目标跟踪的精度,而且加快了模型的收敛速度。
- 还没有人留言评论。精彩留言会获得点赞!